RoPEMover: Depth-Aware Object Relocation via Positional Embeddings
Pith reviewed 2026-06-26 05:17 UTC · model grok-4.3
The pith
Extending rotary positional embeddings with depth awareness enables geometry-consistent object relocation in single images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
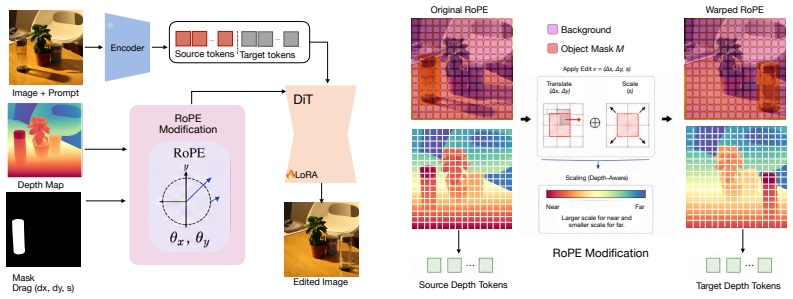
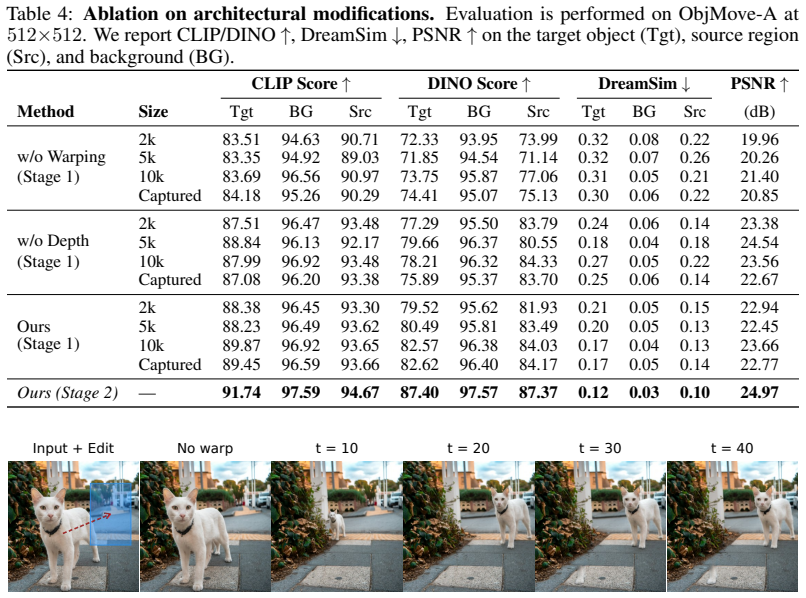
Rotary positional embeddings define a structured spatial field that can be explicitly manipulated to induce controlled motion. We extend 2D RoPE into a depth-aware formulation that encodes 3D spatial structure, enabling consistent object displacement and scene-aware updates.
What carries the argument
depth-aware rotary positional embeddings that encode 3D spatial structure inside diffusion transformers for direct manipulation of object position
If this is right
- Large spatial displacements preserve object identity without retraining the underlying diffusion model.
- Newly revealed image regions receive plausible content that respects the updated scene geometry.
- Scene-dependent effects such as shadows and reflections update automatically to match the new object placement.
- State-of-the-art scores are obtained across all reported evaluation metrics on existing object motion benchmarks.
Where Pith is reading between the lines
- The same depth-aware RoPE manipulation could be applied to other spatial edits such as viewpoint changes or object insertion.
- Because the method relies on positional structure rather than pixel-level synthesis, it may transfer to video or 3D-aware generation tasks with only modest additional supervision.
- The success with mostly synthetic training data suggests that explicit geometric control inside transformers can reduce the need for large real-world paired datasets in editing tasks.
Load-bearing premise
Rotary positional embeddings define a structured spatial field that can be explicitly manipulated via a depth-aware extension to produce controlled, geometry-consistent object motion.
What would settle it
A controlled test on the standard object motion benchmarks in which the depth-aware RoPE manipulation produces inconsistent displacements, broken shadows, or mismatched revealed regions would falsify the central claim.
Figures
















read the original abstract
Moving an object in a single image requires geometry-consistent spatial rearrangement, including handling occlusions, revealing previously unseen regions, and maintaining coherent shadows and reflections. Existing approaches are not well suited to this setting and often fail to preserve such scene-level consistency. We address this problem by introducing a geometry-aware object motion method that operates directly on the positional representations of diffusion transformers. Our key insight is that rotary positional embeddings (RoPE) define a structured spatial field that can be explicitly manipulated to induce controlled motion. We extend 2D RoPE into a depth-aware formulation that encodes 3D spatial structure, enabling consistent object displacement and scene-aware updates. Our model is trained using synthetic data combined with a small set of real images via parameter-efficient fine-tuning. Despite minimal real supervision, it preserves object identity under large spatial displacements, generates plausible content in newly revealed regions, and consistently updates scene-dependent effects such as shadows and illumination. Experimental results on standard object motion benchmarks demonstrate state-of-the-art performance across all evaluation metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoPEMover, a method for depth-aware object relocation in single images that extends 2D rotary positional embeddings (RoPE) into a 3D-aware formulation. It operates directly on the positional representations inside diffusion transformers to enable geometry-consistent object displacement, occlusion handling, and scene-aware updates to effects such as shadows and illumination. The model is trained primarily on synthetic data with parameter-efficient fine-tuning on a small set of real images and is reported to preserve object identity under large displacements while achieving state-of-the-art results on standard object motion benchmarks.
Significance. If the depth-aware RoPE manipulation produces the claimed geometry-consistent motion without introducing new free parameters or circular definitions, the approach could offer an efficient, embedding-centric alternative to explicit 3D reconstruction or heavy supervision for image editing tasks in diffusion models.
major comments (2)
- [Abstract / method description] The abstract asserts that the depth-aware RoPE extension 'encodes 3D spatial structure' and enables 'consistent object displacement,' yet no equations, pseudocode, or derivation of the extension (e.g., how depth is injected into the rotary angles or how the embedding field is updated for relocation) are supplied, leaving the central mechanistic claim untestable.
- [Abstract / experimental results] The claim of 'state-of-the-art performance across all evaluation metrics' on 'standard object motion benchmarks' is presented without any reported numbers, baselines, ablation tables, or metric definitions, which is load-bearing for the experimental validation of the method.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. The full manuscript contains the method derivation and quantitative results; the abstract serves as a concise overview. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / method description] The abstract asserts that the depth-aware RoPE extension 'encodes 3D spatial structure' and enables 'consistent object displacement,' yet no equations, pseudocode, or derivation of the extension (e.g., how depth is injected into the rotary angles or how the embedding field is updated for relocation) are supplied, leaving the central mechanistic claim untestable.
Authors: The full manuscript supplies the equations, pseudocode, and derivation in Section 3, including the precise formulation for injecting depth into the rotary angles and the update rule for the embedding field under relocation. The abstract is length-constrained and therefore omits equations, but the mechanistic claim is fully specified and testable from the paper. We will revise the abstract to add a brief clause referencing the depth-injection mechanism. revision: yes
-
Referee: [Abstract / experimental results] The claim of 'state-of-the-art performance across all evaluation metrics' on 'standard object motion benchmarks' is presented without any reported numbers, baselines, ablation tables, or metric definitions, which is load-bearing for the experimental validation of the method.
Authors: The abstract states the SOTA claim at a summary level, as is conventional. Section 4 of the manuscript provides the supporting tables with concrete metric values, baseline comparisons, ablation results, and explicit metric definitions on the standard benchmarks. We will revise the abstract to include a short parenthetical note on the magnitude of the reported gains. revision: partial
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description present the core contribution as an extension of pre-existing 2D rotary positional embeddings (RoPE) to a depth-aware 3D formulation, with the model trained on synthetic data plus limited real images via parameter-efficient fine-tuning. No equations, fitted parameters, or self-citations are shown that would make any claimed prediction or result equivalent to its inputs by construction. The method is described as operating on and manipulating existing embeddings to achieve geometry-consistent motion, with evaluation on external benchmarks. This leaves the derivation self-contained without reduction to self-definition, fitted-input renaming, or load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Emerging Properties in Self-Supervised Vision Transformers
URL https: //arxiv.org/abs/2104.14294. Xi Chen, Yutong Feng, Mengting Chen, Yiyang Wang, Shilong Zhang, Yu Liu, Yujun Shen, and Heng- shuang Zhao. Zero-shot image editing with reference imitation.Advances in Neural Information Processing Systems, 37:84010–84032, 2024a. Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Z...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
URLhttps://arxiv.org/abs/2306.09344. Ahmet Berke Gökmen, Yi˘git Ekin, Bahri Batuhan Bilecen, and Aysegul Dundar. Ropecraft: Training- free motion transfer with trajectory-guided rope optimization on diffusion transformers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/abs/1612.06890. Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URLhttps://arxiv.org/abs/2506.15742. Jingyi Lu and Kai Han. Inpaint4drag: Repurposing inpainting models for drag-based image editing via bidirectional warping. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18304–18313,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https: //arxiv.org/abs/2103.00020. Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2409.04559. Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details,
-
[8]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
URLhttps://arxiv.org/abs/2507.02546. Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Jian Tong, Haodong Duan, Qipeng Guo, Jiaqi Wang, et al. Videorope: What makes for good video rotary position embedding? InF orty-second International Conference on Machine Learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://arxiv.org/abs/2508.02324. Jay Zhangjie Wu, Xuanchi Ren, Tianchang Shen, Tianshi Cao, Kai He, Yifan Lu, Ruiyuan Gao, Enze Xie, Shiyi Lan, Jose M Alvarez, et al. Chronoedit: Towards temporal reasoning for image editing and world simulation.International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
with the Cycles renderer. All quantities below are expressed in Blender world units; the orthographic camera (ortho_scale=8.0) views a square ground region inside which objects are placed at (x, y)∈ [−3,3] 2, with object radii of 0.35 and 0.70 for small and large primitives, respectively. Each scene contains N∈ {2, . . . ,6} primitives from CLEVR’s catalo...
2025
-
[11]
A.2 Training Details We fine-tune the Qwen-Image-Edit-2511 transformer with rank-16 LoRA adapters injected into the attention projection layers (to_q, to_k, to_v, add_q_proj, add_k_proj, add_v_proj, to_out.0, to_add_out), the MLP projections (img_mlp.net.2, txt_mlp.net.2), and the modulation layers (img_mod.1, txt_mod.1), while keeping the text encoder an...
-
[12]
16 Input + Edit MagicFixup Object Mover FreeFine Inpaint4Drag GeoDiffuser Qwen-Image Ours Figure 9: Additional qualitative comparisons on Object Mover Benchmark A
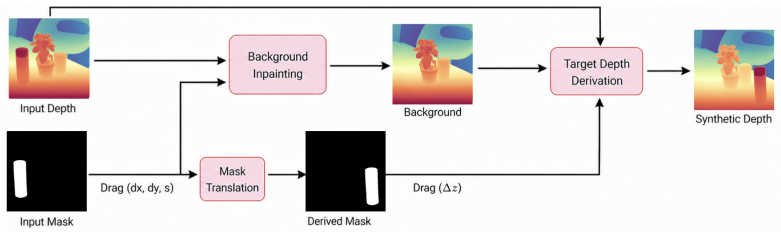
Removing depth conditioning or the second-stage real-data fine- tuning visibly degrades quality, while the full model is consistently best across both benchmarks. 16 Input + Edit MagicFixup Object Mover FreeFine Inpaint4Drag GeoDiffuser Qwen-Image Ours Figure 9: Additional qualitative comparisons on Object Mover Benchmark A. 17 Input + Edit MagicFixup Obj...
2025
-
[13]
Removing depth or the second stage degrades quality; the full model is consistently best
Figure 16: Component ablation across ObjMove-A and ObjMove-B. Removing depth or the second stage degrades quality; the full model is consistently best. 24 Figure 17: Target depth synthesis pipeline. Input + Edit Ours (FLUX.1 Kontext) Input + Edit Ours (FLUX.1 Kontext) Input + Edit Ours (FLUX.1 Kontext) Figure 18: Our method generalizes to other DiT-based ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.