Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
Pith reviewed 2026-06-30 23:48 UTC · model grok-4.3
The pith
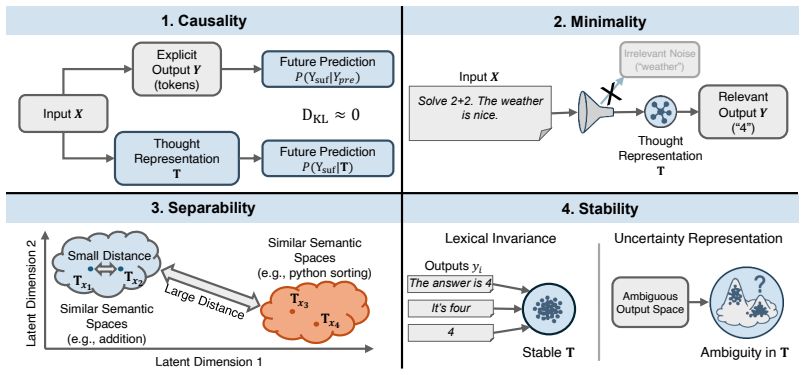
Latent thought representations in LLMs fail to satisfy four axioms of causality, minimality, separability, and stability simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
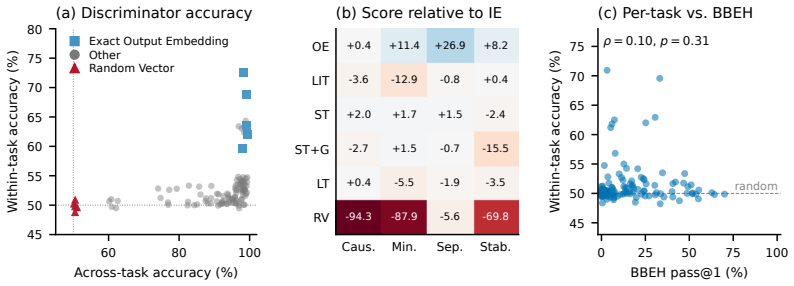
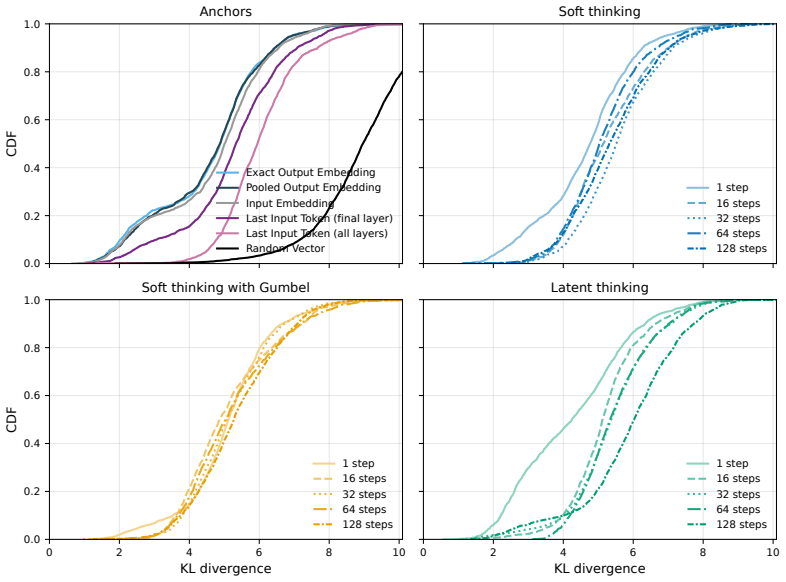
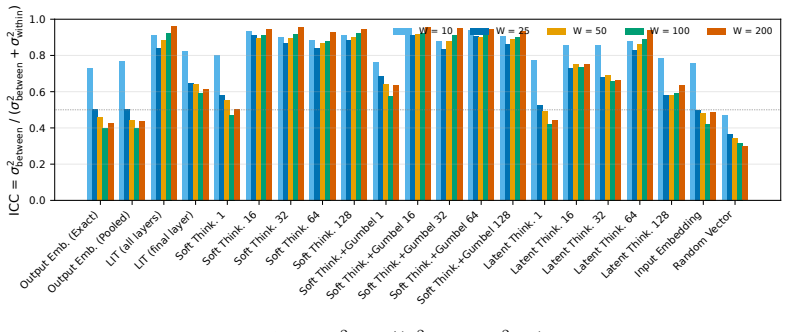
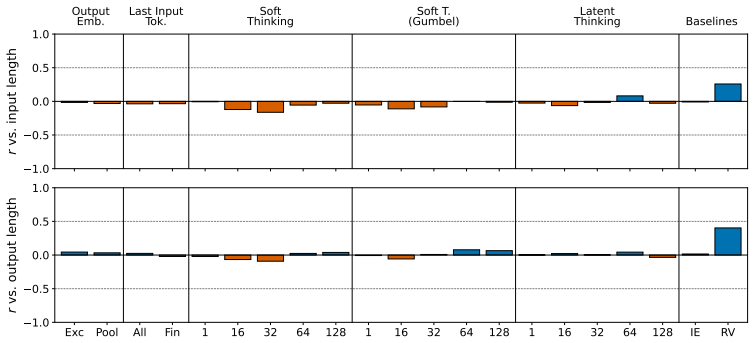
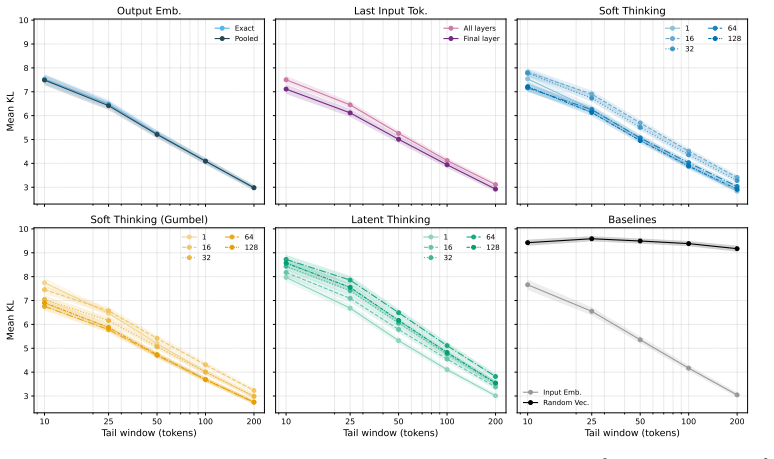
No candidate satisfies all four axioms simultaneously; the representations distinguish task type reliably but cannot distinguish between two questions within the same task, and they encode little information beyond what is already present in the input embedding, with the failure consistent across model families.
What carries the argument
Four functional axioms (Causality, Minimality, Separability, Stability) equipped with quantitative measures computed directly on the latent representation.
Load-bearing premise
The quantitative measures defined for each axiom can be computed directly on the representation and are independent of downstream benchmark scores.
What would settle it
A representation extracted from some LLM that scores high on all four quantitative axiom measures across the tested tasks.
Figures
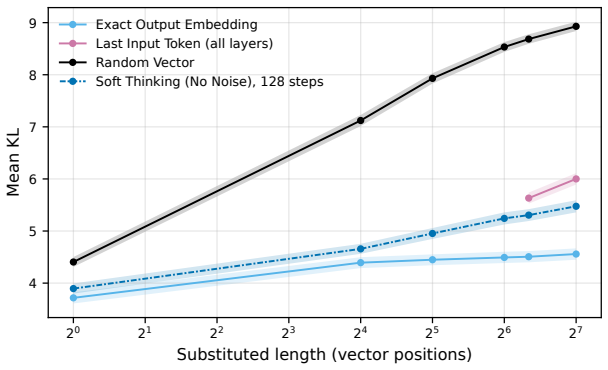
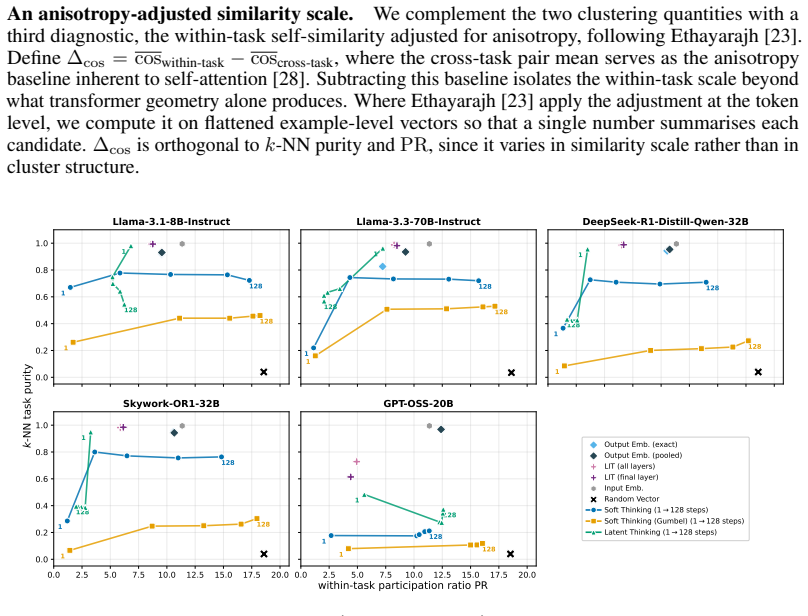
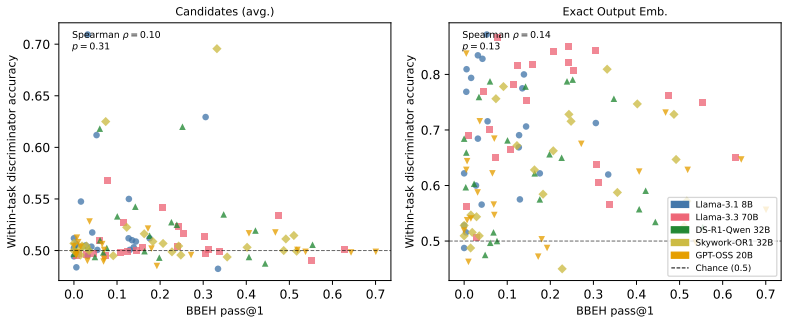
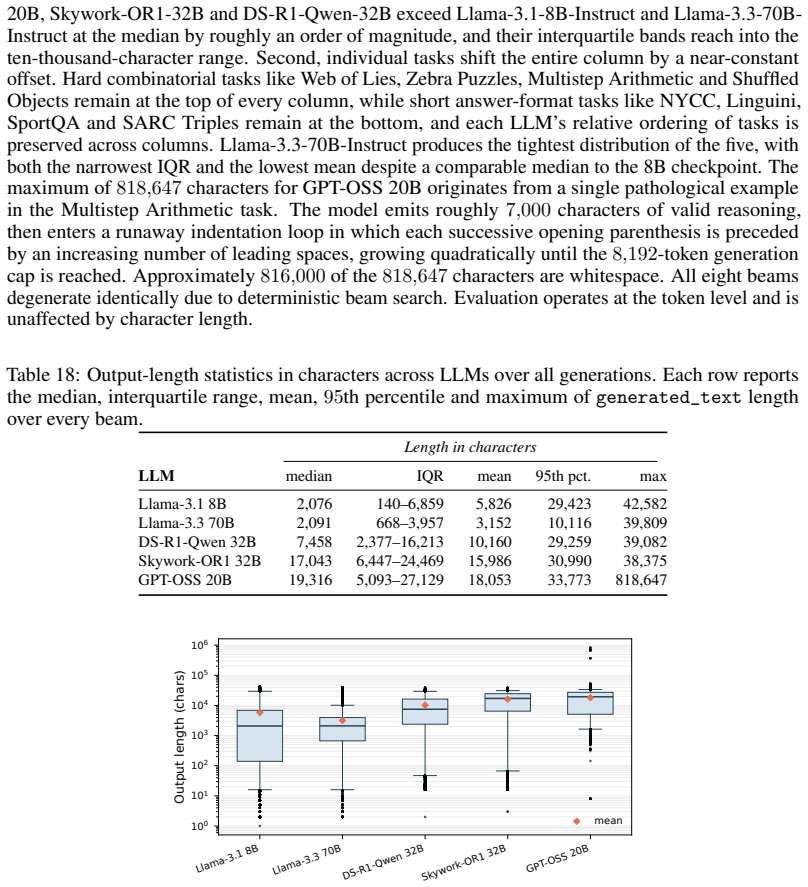
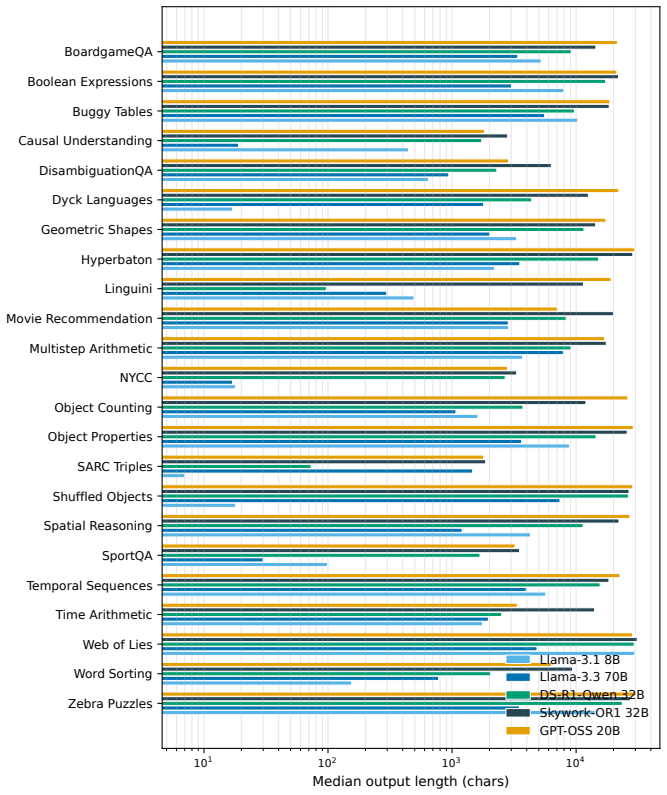
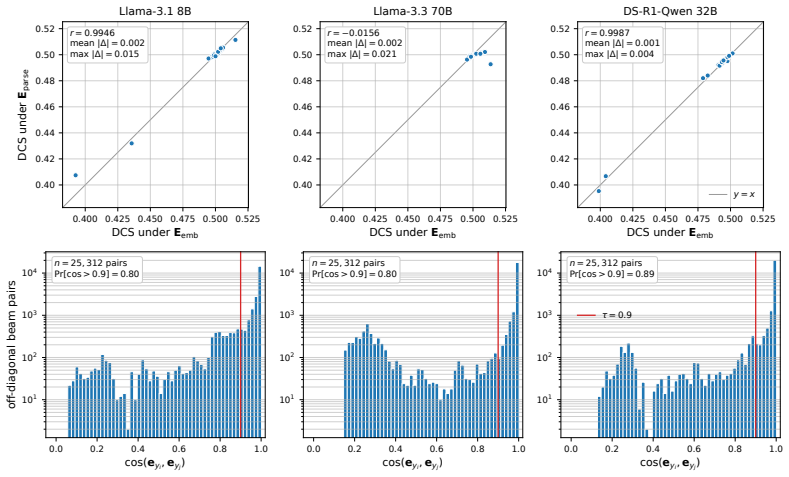
read the original abstract
We introduce an axiomatic evaluation framework for latent thought representations in LLMs, comprising metrics that are independent of downstream benchmark scores and reveal representational failures that benchmark accuracy masks. Existing evaluations conflate representation quality with model capacity. Therefore, failures cannot be attributed to the representation rather than to the model that processes it. We formalize four functional axioms (Causality, Minimality, Separability, and Stability) and define a quantitative measure for each, computed directly on the representation independently of downstream accuracy. We audit open-weight LLMs across 23 reasoning tasks (e.g., Spatial Reasoning, Factual QA). We find that no candidate satisfies all four axioms simultaneously, that the representations distinguish task type reliably but cannot distinguish between two questions within the same task, and that the representations encode little information beyond what is already present in the input embedding. The failure is consistent across dense, reasoning-distilled, and RL-trained model families, indicating that the gap is structural rather than a property of model size or training procedure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an axiomatic evaluation framework for latent thought representations in LLMs, comprising four axioms (Causality, Minimality, Separability, and Stability) with quantitative measures computed directly on the representations and claimed to be independent of downstream benchmark scores. Auditing open-weight LLMs across 23 reasoning tasks, the authors report that no candidate satisfies all four axioms simultaneously, that representations distinguish task type reliably but cannot distinguish between two questions within the same task, and that representations encode little information beyond the input embedding. The failure pattern is consistent across dense, reasoning-distilled, and RL-trained model families, indicating a structural gap.
Significance. If the metrics are verifiably independent of downstream accuracy and the experimental controls are adequate, the work would offer a useful new lens for diagnosing representational limitations that standard benchmarks obscure. The cross-family consistency strengthens the structural-gap interpretation and could usefully redirect attention from scale to representation design.
major comments (2)
- [Abstract and §3 (Axiom Definitions)] The central attribution of failures to the representations (rather than model capacity) rests on the claim that the four quantitative measures are computed directly on the representation and independent of downstream accuracy. Without the explicit extraction procedures, formulas, or controls for Causality, Minimality, Separability, and Stability, it is impossible to confirm this independence; the abstract states the claim but provides no equations or pseudocode.
- [§4 (Experimental Results)] The claim that representations 'distinguish task type reliably but cannot distinguish between two questions within the same task' is load-bearing for the separability axiom and the overall conclusion. Specific tables or figures reporting inter-task vs. intra-task separability scores (with statistical tests) are required to substantiate this distinction.
minor comments (1)
- [Abstract] The abstract lists example tasks ('Spatial Reasoning, Factual QA') but does not enumerate all 23 tasks or provide a reference; a table or appendix listing them would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help clarify the presentation of our axiomatic framework. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and §3 (Axiom Definitions)] The central attribution of failures to the representations (rather than model capacity) rests on the claim that the four quantitative measures are computed directly on the representation and independent of downstream accuracy. Without the explicit extraction procedures, formulas, or controls for Causality, Minimality, Separability, and Stability, it is impossible to confirm this independence; the abstract states the claim but provides no equations.
Authors: Section 3 of the manuscript provides the formal definitions of the four axioms along with the quantitative measures and extraction procedures for each. These measures are designed to be computed solely from the latent representations (e.g., via vector operations and statistical properties) without any dependence on task labels or accuracy metrics. We acknowledge that the abstract does not include equations, as is conventional, but we will revise the manuscript to include a short paragraph in the introduction or a new appendix that explicitly lists the formulas and independence arguments to make this clearer. This will allow readers to verify the independence directly. revision: partial
-
Referee: [§4 (Experimental Results)] The claim that representations 'distinguish task type reliably but cannot distinguish between two questions within the same task' is load-bearing for the separability axiom and the overall conclusion. Specific tables or figures reporting inter-task vs. intra-task separability scores (with statistical tests) are required to substantiate this distinction.
Authors: We agree that more granular evidence is needed for this claim. While §4 reports overall separability results across tasks, the revision will include a new table (or extended figure) that breaks down inter-task separability scores versus intra-task scores for each model family, accompanied by statistical significance tests (e.g., paired t-tests between inter- and intra-task distributions). This will directly support the distinction and strengthen the separability axiom analysis. revision: yes
Circularity Check
Axiom metrics presented as direct computations with no reduction shown
full rationale
The paper defines four axioms (Causality, Minimality, Separability, Stability) and states that quantitative measures for each are computed directly on the representation independently of downstream accuracy. No equations, extraction procedures, or self-citations appear in the provided text that would reduce any measure to a fitted parameter, task performance signal, or prior result by construction. The attribution of failures to the representation itself rests on this direct-computation claim, which is presented without internal circularity. This is the most common honest finding when no load-bearing step reduces to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Metrics for the axioms can be computed directly on the representation independently of downstream accuracy
- domain assumption Failures in the axioms can be attributed to the representation rather than model capacity
Reference graph
Works this paper leans on
-
[1]
A. Afzal, F. Matthes, G. Chechik, and Y . Ziser. Knowing before saying: LLM represen- tations encode information about chain-of-thought success before completion. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Findings of the Association for Computa- tional Linguistics: ACL 2025, pages 12791–12806, Vienna, Austria, July 2025. Association f...
-
[2]
J. Alabi, M. Mosbach, M. Eyal, D. Klakow, and M. Geva. The hidden space of transformer language adapters. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6588–6607, Bangkok, Thailand, Aug. 2024. Association for Computational Linguistic...
-
[3]
Ameisen, J
E. Ameisen, J. Lindsey, A. Pearce, W. Gurnee, N. L. Turner, B. Chen, C. Citro, D. Abra- hams, S. Carter, B. Hosmer, J. Marcus, M. Sklar, A. Templeton, T. Bricken, C. McDougall, H. Cunningham, T. Henighan, A. Jermyn, A. Jones, A. Persic, Z. Qi, T. Ben Thompson, S. Zimmerman, K. Rivoire, T. Conerly, C. Olah, and J. Batson. Circuit Tracing: Reveal- ing Compu...
2025
-
[4]
A. E. Assadi, I. Chung, R. Solomatin, N. Muennighoff, and K. Enevoldsen. HUME: Measuring the human-model performance gap in text embedding tasks. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=rcmfu1ydAf
2026
-
[5]
Y . Babakhin, R. Osmulski, R. Ak, G. Moreira, M. Xu, B. Schifferer, B. Liu, and E. Oldridge. Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross- lingual tasks, 2025. URLhttps://arxiv.org/abs/2511.07025
-
[6]
Bandarkar, B
L. Bandarkar, B. Muller, P. Yuvraj, R. Hou, N. Singhal, H. Lv, and B. Liu. Layer swapping for zero-shot cross-lingual transfer in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=vQhn4wrQ6j
2025
-
[7]
Barak, B
B. Barak, B. L. Edelman, S. Goel, S. Kakade, E. Malach, and C. Zhang. Hidden Progress in Deep Learning: SGD Learns Parities Near the Computa- tional Limit. InAdvances in Neural Information Processing Systems, volume 35,
-
[8]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 884baf65392170763b27c914087bde01-Abstract-Conference.html
2022
-
[9]
Barber and F
D. Barber and F. Agakov. The IM algorithm: a variational approach to information maximization. InProceedings of the 17th International Conference on Neural Information Processing Systems, NIPS’03, pages 201–208, Cambridge, MA, USA, 2003. MIT Press
2003
-
[10]
N. Butt, A. Kwiatkowski, I. Labiad, J. Kempe, and Y . Ollivier. Soft Tokens, Hard Truths. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=9JjKTp8Jmy
2026
-
[11]
Z. Cai, X. Zhu, Y . Dong, Y . He, and S. Arora. T2MLR: Transformer with Temporal Middle- Layer Recurrence. InLIT Workshop @ ICLR 2026, 2026. URL https://openreview.net/ forum?id=fQbk1EQWBO
2026
-
[12]
Emerging Properties in Self-Supervised Vision Transformers
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin. Emerg- ing Properties in Self-Supervised Vision Transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021. URL https://arxiv.org/abs/2104.14294
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [13]
-
[14]
X. Chen, A. Zhao, H. Xia, X. Lu, H. Wang, Y . Chen, W. Zhang, J. Wang, W. Li, and X. Shen. Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning,
- [15]
-
[16]
Chételat, J
D. Chételat, J. Cotnareanu, R. Thompson, Y . Zhang, and M. Coates. InnerThoughts: Dis- entangling Representations and Predictions in Large Language Models. In Y . Li, S. Mandt, S. Agrawal, and E. Khan, editors,Proceedings of The 28th International Conference on Arti- ficial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Research...
2025
-
[17]
Conklin, T
H. Conklin, T. Hosking, T. Yi-Chern, J. D. Cohen, S.-J. Leslie, T. L. Griffiths, M. Bartolo, and S. Goldfarb-Tarrant. Learning is Forgetting; LLM Training As Lossy Compression. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=tvDlQj0GZB
2026
- [18]
-
[19]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
DeepSeek-AI. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645(8081):633–638, 2025. doi: 10.1038/s41586-025-09422-z. URL https://www. nature.com/articles/s41586-025-09422-z
- [20]
-
[21]
Are Latent Reasoning Models Easily Interpretable?
C. Dilgren and S. Wiegreffe. Are Latent Reasoning Models Easily Interpretable? InLIT Workshop @ ICLR 2026, 2026. URLhttps://arxiv.org/abs/2604.04902
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Dragunov, T
N. Dragunov, T. Rahmatullaev, E. Goncharova, A. Kuznetsov, and A. Razzhigaev. SONAR- LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens,
-
[23]
URLhttps://arxiv.org/abs/2508.05305
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
C. Du, K. Fu, B. Wen, Y . Sun, J. Peng, W. Wei, Y . Gao, S. Wang, C. Zhang, J. Li, S. Qiu, L. Chang, and H. He. Human-like object concept representations emerge naturally in mul- timodal large language models.Nature Machine Intelligence, 7(6):860–875, June 2025. ISSN 2522-5839. doi: 10.1038/s42256-025-01049-z. URL http://dx.doi.org/10.1038/ s42256-025-01049-z
-
[25]
P.-A. Duquenne, H. Schwenk, and B. Sagot. SONAR: Sentence-Level Multimodal and Language-Agnostic Representations, 2023. URLhttps://arxiv.org/abs/2308.11466
-
[27]
Fadeeva, M
E. Fadeeva, M. Goloburda, A. Rubashevskii, R. Vashurin, A. Shelmanov, P. Nakov, M. Sachan, and M. Panov. Don’t Throw Away Your Beams: Improving Consistency-based Uncertain- ties in LLMs via Beam Search. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=igcQRiVlgu
2026
-
[28]
Test of time: A benchmark for evaluating llms on temporal reasoning, 2024
B. Fatemi, M. Kazemi, A. Tsitsulin, K. Malkan, J. Yim, J. Palowitch, S. Seo, J. Halcrow, and B. Perozzi. Test of Time: A benchmark for evaluating LLMs on temporal reasoning.arXiv preprint arXiv:2406.09170, 2024
-
[29]
J. Feng, S. Russell, and J. Steinhardt. Monitoring Latent World States in Language Models with Propositional Probes. InThe Thirteenth International Conference on Learning Representations,
-
[30]
URLhttps://openreview.net/forum?id=0yvZm2AjUr. 11
-
[31]
S. Feng, G. Fang, X. Ma, and X. Wang. Efficient reasoning models: A survey.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/ forum?id=sySqlxj8EB
2025
-
[32]
N. Godey, É. de la Clergerie, and B. Sagot. Anisotropy Is Inherent to Self-Attention in Transformers. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL) (Volume 1: Long Papers), pages 35–48, 2024. URL https://arxiv.org/abs/2401.12143
-
[33]
Goyal, Z
S. Goyal, Z. Ji, A. S. Rawat, A. K. Menon, S. Kumar, and V . Nagarajan. Think before you speak: Training language models with pause tokens. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ph04CRkPdC
2024
-
[34]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The Llama 3 Herd of Models, 2024. URL https://arxiv. org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
J. He, J. Liu, C. Y . Liu, R. Yan, C. Wang, P. Cheng, X. Zhang, F. Zhang, J. Xu, W. Shen, S. Li, L. Zeng, T. Wei, C. Cheng, B. An, Y . Liu, and Y . Zhou. Skywork Open Reasoner 1 Technical Report.arXiv preprint arXiv:2505.22312, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
J. He, J. Liu, C. Y . Liu, R. Yan, C. Wang, P. Cheng, X. Zhang, F. Zhang, J. Xu, W. Shen, S. Li, L. Zeng, T. Wei, C. Cheng, Y . Liu, and Y . Zhou. Sky- work Open Reasoner Series. https://capricious-hydrogen-41c.notion.site/ Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680 , 2025. No- tion Blog
2025
-
[38]
Helff, R
L. Helff, R. Härle, W. Stammer, F. Friedrich, M. Brack, A. Wüst, H. Shindo, P. Schramowski, and K. Kersting. Activationreasoning: Logical reasoning in latent activation spaces. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=gGJh5AZTG7
2026
-
[39]
Herrmann, R
V . Herrmann, R. Csordás, and J. Schmidhuber. Measuring In-Context Computation Complexity via Hidden State Prediction. InForty-second International Conference on Machine Learning,
-
[40]
URLhttps://openreview.net/forum?id=X21P8etjWL
-
[41]
J. Hessel, A. Marasovi´c, J. D. Hwang, L. Lee, J. Da, R. Zellers, R. Mankoff, and Y . Choi. Do androids laugh at electric sheep? Humor “understanding” benchmarks from the New Yorker caption contest.arXiv preprint arXiv:2209.06293, 2022
-
[42]
Holtzman, J
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi. The curious case of neural text degeneration. InInternational Conference on Learning Representations, 2020. URL https: //openreview.net/forum?id=rygGQyrFvH
2020
-
[43]
Less is More: Recursive Reasoning with Tiny Networks
A. Jolicoeur-Martineau. Less is More: Recursive Reasoning with Tiny Networks, 2025. URL https://arxiv.org/abs/2510.04871
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Kazemi, Q
M. Kazemi, Q. Yuan, D. Bhatia, N. Kim, X. Xu, V . Imbrasaite, and D. Ramachandran. BoardgameQA: A dataset for natural language reasoning with contradictory information.Ad- vances in Neural Information Processing Systems, 36, 2024
2024
-
[46]
Kazemi, B
M. Kazemi, B. Fatemi, H. Bansal, J. Palowitch, C. Anastasiou, S. V . Mehta, L. K. Jain, V . Agli- etti, D. Jindal, P. Chen, N. Dikkala, G. Tyen, X. Liu, U. Shalit, S. Chiappa, K. Olszewska, Y . Tay, V . Q. Tran, Q. V . Le, and O. Firat. BIG-bench extra hard. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Meet...
-
[47]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/ 2025.acl-long.1285. URLhttps://aclanthology.org/2025.acl-long.1285/. 12
-
[48]
E. Kıcıman, R. Ness, A. Sharma, and C. Tan. Causal reasoning and large language models: Opening a new frontier for causality.arXiv preprint arXiv:2305.00050, 2023
-
[49]
Y . Koishekenov, A. Lipani, and N. Cancedda. Encode, Think, Decode: Scaling test-time reasoning with recursive latent thoughts, 2025. URL https://arxiv.org/abs/2510.07358
-
[50]
L. Kuhn, Y . Gal, and S. Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=VD-AYtP0dve
2023
-
[51]
Y . Li, J. Chen, F. Wu, J. Yu, H. Qi, W. Xuan, H. Zhao, P. Nie, D. Jin, and X. Tang. Learning Multi-step Reasoning via Persistent Latent State Propagation. InLIT Workshop @ ICLR 2026,
2026
-
[52]
URLhttps://openreview.net/forum?id=Dcv4B1UCuW
-
[53]
Z. Li, X. Bai, K. Chen, Y . Li, J. Yang, C. Lin, and M. Zhang. Dynamics Within Latent Chain- of-Thought: An Empirical Study of Causal Structure. InLIT Workshop @ ICLR 2026, 2026. URLhttps://arxiv.org/abs/2602.08783
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
A. Litwin-Kumar, K. D. Harris, R. Axel, H. Sompolinsky, and L. F. Abbott. Optimal Degrees of Synaptic Connectivity.Neuron, 93(5):1153–1164.e7, 2017. doi: 10.1016/j.neuron.2017.01.030
-
[55]
LLMs Encode Their Failures: Predicting Success from Pre-Generation Activations
W. Lugoloobi, T. Foster, W. Bankes, and C. Russell. LLMs Encode Their Failures: Predicting Success from Pre-Generation Activations. InLIT Workshop @ ICLR 2026, 2026. URL https://arxiv.org/abs/2602.09924
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
F. V . Massoli, A. Kuzmin, and A. Behboodi. Reasoning as Compression: Unifying Budget Forcing via the Conditional Information Bottleneck. InThe 1st Workshop on Scaling Post- training for LLMs, 2026. URLhttps://openreview.net/forum?id=98sbP0T8ck
2026
-
[57]
Mondorf and B
P. Mondorf and B. Plank. Beyond accuracy: Evaluating the reasoning behavior of large language models – a survey. InFirst Conference on Language Modeling (COLM), 2024. URL https://openreview.net/forum?id=Lmjgl2n11u
2024
-
[58]
MTEB: Massive Text Embedding Benchmark
N. Muennighoff, N. Tazi, L. Magne, and N. Reimers. MTEB: Massive Text Embedding Benchmark, 2023. URLhttps://arxiv.org/abs/2210.07316
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
A. Nie, Y . Zhang, A. S. Amdekar, C. Piech, T. B. Hashimoto, and T. Gerstenberg. MoCa: Measuring human-language model alignment on causal and moral judgment tasks.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[60]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b Model Card, 2025. URL https://arxiv.org/abs/ 2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
K. Park, Y . J. Choe, and V . Veitch. The Linear Representation Hypothesis and the Geometry of Large Language Models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 39643–39666. PMLR, 2024. URLhttps://proceedings.mlr.press/v235/park24c.html
2024
-
[62]
Enforcing Logical Invariance in Large Language Models via Symmetry Pair Training
Prasanth. Enforcing Logical Invariance in Large Language Models via Symmetry Pair Training. InICLR 2026 Workshop on Logical Reasoning of Large Language Models, 2026. URL https://openreview.net/forum?id=aZFS8rc6Bf
2026
-
[63]
S. Recanatesi, M. Farrell, M. Advani, T. Moore, G. Lajoie, and E. Shea-Brown. Dimensionality compression and expansion in Deep Neural Networks, 2019. URL https://arxiv.org/abs/ 1906.00443
-
[64]
Rizvi-Martel and M
M. Rizvi-Martel and M. Mosbach. The Illusion of Superposition in Latent CoT via Soft Thinking. InLIT Workshop @ ICLR 2026, 2026. URL https://openreview.net/forum? id=FvPx9Nzvnw
2026
- [65]
-
[66]
Salhan, E
S. Salhan, E. Zhou, and P. Buttery. Do Monolingual Language Models Learn Cross-Lingual Universal Conceptual Representations? InICLR 2026 Workshop on Unifying Concept Repre- sentation Learning, 2026. URLhttps://openreview.net/forum?id=frKa6ujOyE
2026
-
[67]
E. Sánchez, B. Alastruey, C. Ropers, P. Stenetorp, M. Artetxe, and M. R. Costa-jussà. Linguini: A benchmark for language-agnostic linguistic reasoning.arXiv preprint arXiv:2409.12126, 2024
- [68]
- [69]
-
[70]
Z. Shen, H. Yan, L. Zhang, Z. Hu, Y . Du, and Y . He. CODI: Compressing chain-of-thought into continuous space via self-distillation. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, Suzhou, China, Nov. 2025. Association for Compu...
-
[71]
D. Sheshanarayana, R. S. Pal, M. Sinha, and T. Dasgupta. Thinking in Latents: Adaptive Anchor Refinement for Implicit Reasoning in LLMs. InLIT Workshop @ ICLR 2026, 2026. URLhttps://arxiv.org/abs/2603.15051
-
[72]
Skean, M
O. Skean, M. R. Arefin, D. Zhao, N. N. Patel, J. Naghiyev, Y . LeCun, and R. Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=WGXb7UdvTX
2025
-
[73]
Sui, Y .-N
Y . Sui, Y .-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu. Stop overthinking: A survey on efficient reasoning for large language models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=HvoG8SxggZ
2025
-
[74]
Q. Sun, M. Pickett, A. K. Nain, and L. Jones. Transformer Layers as Painters. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25219–25227, 2025. doi: 10.1609/aaai.v39i24.34708. URL https://ojs.aaai.org/index.php/AAAI/article/ view/34708
-
[75]
L. team, L. Barrault, P.-A. Duquenne, M. Elbayad, A. Kozhevnikov, B. Alastruey, P. Andrews, M. Coria, G. Couairon, M. R. Costa-jussà, D. Dale, H. Elsahar, K. Heffernan, J. M. Janeiro, T. Tran, C. Ropers, E. Sánchez, R. S. Roman, A. Mourachko, S. Saleem, and H. Schwenk. Large Concept Models: Language Modeling in a Sentence Representation Space, 2024. URL h...
- [76]
-
[77]
W. Wang and F. Reid. Tiny Recursive Reasoning with Mamba-2 Attention Hybrid. InLIT Workshop @ ICLR 2026, 2026. URLhttps://arxiv.org/abs/2602.12078
-
[78]
C. Wendler, V . Veselovsky, G. Monea, and R. West. Do llamas work in english? on the latent language of multilingual transformers. In L.-W. Ku, A. Martins, and V . Srikumar, ed- itors,Proceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 15366–15394, Bangkok, Thailand, Aug. 2024. Associati...
-
[79]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
C. White, S. Dooley, M. Roberts, A. Pal, B. Feuer, S. Jain, R. Shwartz-Ziv, N. Jain, K. Saifullah, S. Naidu, et al. LiveBench: A challenging, contamination-free LLM benchmark.arXiv preprint arXiv:2406.19314, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
J. Wu, J. Lu, Z. Ren, G. Hu, Z. Wu, D. Dai, and H. Wu. LLMs are Single-threaded Reasoners: Demystifying the Working Mechanism of Soft Thinking. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=ASLuOoP78o
2026
-
[81]
Z. Wu, Y . Xiong, S. X. Yu, and D. Lin. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3733–3742, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.