Learning from Annotation Uncertainty: Entropy-Aware Curriculum for Speech Emotion Recognition
Pith reviewed 2026-06-29 00:49 UTC · model grok-4.3
The pith
Distributional targets from annotator votes align speech emotion models more closely with human disagreement than hard consensus labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
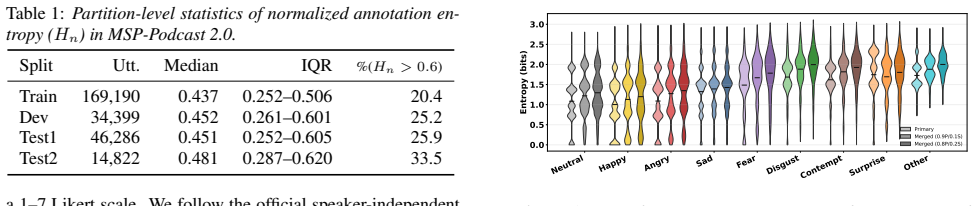
Distributional supervision using primary and merged annotator vote distributions outperforms hard-label training by lowering JSD and KLD to human vote distributions in 9-class SER, while entropy-stratified evaluation shows that distributional targets better represent perceptual uncertainty even though high-entropy utterances stay challenging.
What carries the argument
Distributional targets derived from primary and merged annotator vote distributions, paired with entropy-stratified evaluation of model outputs.
If this is right
- Uncertainty is redistributed across emotion categories rather than confined to a residual class.
- Models can produce outputs whose spread more closely tracks how listeners actually disagree.
- Entropy stratification reveals that gains appear across ambiguity levels but do not eliminate difficulty for the most uncertain utterances.
- Multitask categorical and dimensional prediction benefits when both heads receive soft rather than one-hot targets.
Where Pith is reading between the lines
- The same vote-distribution approach could be tested on other subjective labeling tasks where multiple raters are available.
- Datasets might start reporting full vote histograms as primary supervision rather than derived consensus labels.
- An explicit curriculum that orders batches by increasing entropy could be layered on top of the distributional objective.
Load-bearing premise
Annotator vote distributions faithfully represent true perceptual uncertainty rather than rater noise or bias.
What would settle it
A held-out set of new listener votes on the same utterances where the distributional model exhibits equal or higher JSD/KLD than the hard-label model.
Figures
read the original abstract
Speech emotion recognition (SER) often relies on hard consensus labels that collapse annotator disagreement. We study distribution-based supervision for 9-class SER on MSP-Podcast 2.0 using a WavLM-Base multitask model for categorical emotion and dimensional VAD. Hard-label training is compared with targets from primary and merged primary--secondary annotator vote distributions. Distributional objectives improve alignment with human vote distributions, reducing JSD/KLD relative to hard-label training. Analysis shows that hard supervision partly benefits from assigning ambiguous utterances to the residual Other class, whereas distributional supervision redistributes uncertainty across emotion categories. Entropy-stratified evaluation shows that high-ambiguity utterances remain challenging, but distribution-based supervision better captures perceptual uncertainty. These findings support moving beyond hard labels toward targets that reflect listener disagreement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for 9-class speech emotion recognition on MSP-Podcast 2.0, a WavLM-Base multitask model trained with distributional targets derived from primary and merged annotator vote distributions achieves better alignment with human vote distributions (lower JSD and KLD) than hard-label training. It further argues that hard supervision benefits from routing ambiguous utterances to the residual 'Other' class while distributional supervision redistributes uncertainty, that entropy-stratified evaluation shows high-ambiguity utterances remain challenging but are better handled by distributional methods, and that these results support moving beyond hard consensus labels toward targets that reflect listener disagreement.
Significance. If the quantitative claims hold after proper validation, the work could encourage the SER community to treat annotator disagreement as signal rather than noise, potentially improving model robustness on ambiguous cases. The entropy-aware curriculum angle is a potentially useful framing if it is shown to yield measurable gains on high-entropy subsets.
major comments (2)
- [Abstract] Abstract: the directional claim that 'Distributional objectives improve alignment with human vote distributions, reducing JSD/KLD relative to hard-label training' supplies no numerical values, error bars, dataset splits, or statistical significance tests, rendering the magnitude and reliability of the reported improvement impossible to assess.
- [Abstract] Abstract: the premise that primary and merged annotator vote histograms constitute faithful targets for perceptual uncertainty (as opposed to rater bias, cultural differences, or annotation noise) is load-bearing for the interpretation of the JSD/KLD reductions, yet the manuscript provides no inter-rater reliability statistics, ablation removing obvious bias sources, or comparison against independent perceptual measures to secure this distinction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the directional claim that 'Distributional objectives improve alignment with human vote distributions, reducing JSD/KLD relative to hard-label training' supplies no numerical values, error bars, dataset splits, or statistical significance tests, rendering the magnitude and reliability of the reported improvement impossible to assess.
Authors: We agree that the abstract as written is too high-level and does not allow assessment of effect size or reliability. In the revised manuscript we will replace the directional statement with the concrete JSD and KLD deltas observed on the MSP-Podcast 2.0 test split (including standard deviations across seeds where available) and will reference the exact train/validation/test partitions and any significance testing performed. revision: yes
-
Referee: [Abstract] Abstract: the premise that primary and merged annotator vote histograms constitute faithful targets for perceptual uncertainty (as opposed to rater bias, cultural differences, or annotation noise) is load-bearing for the interpretation of the JSD/KLD reductions, yet the manuscript provides no inter-rater reliability statistics, ablation removing obvious bias sources, or comparison against independent perceptual measures to secure this distinction.
Authors: The current manuscript does not contain inter-rater reliability coefficients, explicit bias ablations, or external perceptual validation. We will add a dedicated limitations paragraph in the revised version that (a) states the assumption that vote histograms primarily reflect perceptual uncertainty, (b) acknowledges possible contributions from rater bias or annotation artifacts, and (c) notes the absence of the requested statistics as a limitation of the present study. No new experiments are feasible without additional data collection. revision: partial
Circularity Check
No circularity: empirical comparison of objectives against external annotations
full rationale
The paper reports an empirical study comparing hard-label vs. distributional training on MSP-Podcast 2.0 with a WavLM-Base model, measuring JSD/KLD alignment to held-out human vote distributions. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. The result is a standard ML ablation that remains falsifiable on independent test data and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in speech emotion recognition (SER) lever- age large self-supervised encoders (SSEs) such as WavLM, Hu- BERT, and wav2vec2, yielding substantial gains in robustness. However, most SER systems still assume that each utterance has a single discrete ground-truth label, despite evidence that emo- tional expressions can support mul...
2026
-
[2]
Learning from Annotation Uncertainty: Entropy-Aware Curriculum for Speech Emotion Recognition
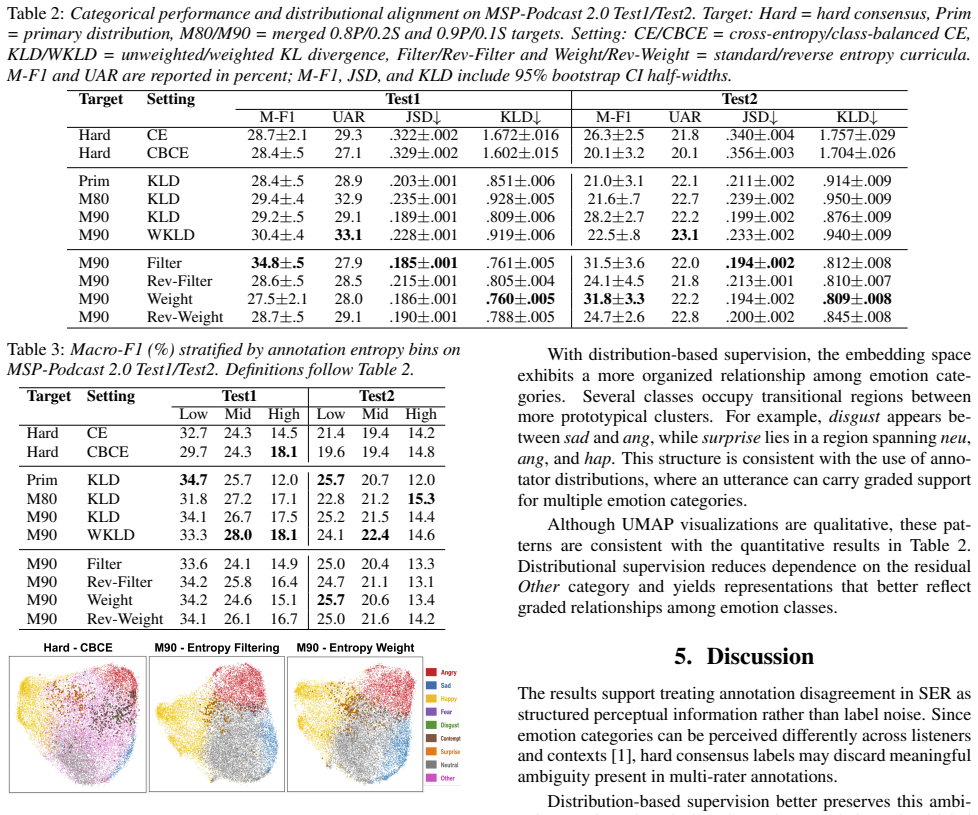
Method 2.1. MSP-Podcast 2.0 Experiments are conducted on MSP-Podcast 2.0, which con- tains 267,905 utterances from 3,641 speakers. Each utterance is annotated by multiple raters (≥5) with a primary categorical emotion label, optional secondary categorical emotion labels, and dimensional activation, valence, and dominance ratings on arXiv:2606.27536v1 [cs....
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Optimization Models are trained with AdamW using separate learning rates for the WavLM backbone (1×10 −5) and task-specific heads (1×10−4)
Experimental Setup 3.1. Optimization Models are trained with AdamW using separate learning rates for the WavLM backbone (1×10 −5) and task-specific heads (1×10−4). A NewBob scheduler is applied independently with improvement threshold 0.0025 and annealing factor 0.9. Train- ing uses batch size 32 with mixed precision for up to 18 epochs, and early stoppin...
-
[4]
Results Table 2 summarizes categorical decision performance and dis- tributional alignment across supervision settings. Relative to hard CE/CBCE training, all distributional objectives consis- tently reduce JSD and KLD on both Test1 and Test2, indicating closer agreement between model predictions and annotator vote distributions. Moreover, the narrow boot...
-
[5]
Since emotion categories can be perceived differently across listeners and contexts [1], hard consensus labels may discard meaningful ambiguity present in multi-rater annotations
Discussion The results support treating annotation disagreement in SER as structured perceptual information rather than label noise. Since emotion categories can be perceived differently across listeners and contexts [1], hard consensus labels may discard meaningful ambiguity present in multi-rater annotations. Distribution-based supervision better preser...
-
[6]
By treating annotation entropy as an utterance-level property, we analyzed model behavior across different levels of perceptual ambiguity
Conclusion We investigated uncertainty-aware supervision for SSL-based SER on MSP-Podcast 2.0. By treating annotation entropy as an utterance-level property, we analyzed model behavior across different levels of perceptual ambiguity. Training with annotator-derived emotion distributions improves alignment with human vote distributions and reduces reliance...
-
[7]
Acknowledgments The authors acknowledge the High Performance Computing at The University of Texas at Dallas (HPC@UTD) for providing the computing resources and support
-
[8]
After using this tool, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the publication
Generative AI Use Disclosure During the preparation of this work, the author(s) used Gen AI tools to review and make corrections. After using this tool, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the publication
-
[9]
Emotional expressions reconsidered: Challenges to infer- ring emotion from human facial movements,
L. F. Barrett, R. Adolphs, S. Marsella, A. M. Martinez, and S. D. Pollak, “Emotional expressions reconsidered: Challenges to infer- ring emotion from human facial movements,”Psychological sci- ence in the public interest, vol. 20, no. 1, pp. 1–68, 2019
2019
-
[10]
Msp-improv: An acted corpus of dyadic interactions to study emotion perception,
C. Busso, S. Parthasarathy, A. Burmania, M. AbdelWahab, N. Sadoughi, and E. M. Provost, “Msp-improv: An acted corpus of dyadic interactions to study emotion perception,”IEEE trans- actions on affective computing, vol. 8, no. 1, pp. 67–80, 2016
2016
-
[11]
seeing the big through the small
C. Busso, R. Lotfian, K. Sridhar, A. N. Salman, W.-C. Lin, L. Goncalves, S. Parthasarathy, A. Reddy Naini, S.-G. Leem, L. Martinez-Lucas, H.-C. Chou, and P. Mote, “The msp-podcast corpus,”arXiv preprint arXiv:2509.09791, 2025. [Online]. Available: https://arxiv.org/abs/2509.09791
-
[12]
Switchboard-affect: Emotion perception labels from conversational speech,
A. Romana, J. Narain, T. D. Tran, A. Davis, J. Fong, R. Rasipuram, and V . Mitra, “Switchboard-affect: Emotion perception labels from conversational speech,”arXiv preprint arXiv:2510.13906, 2025
-
[13]
Predicting categorical emotions by jointly learning primary and secondary emotions through multi- task learning,
R. Lotfian and C. Busso, “Predicting categorical emotions by jointly learning primary and secondary emotions through multi- task learning,” inProceedings of Interspeech, 2018, pp. 3698– 3702
2018
-
[14]
End- to-end label uncertainty modeling in speech emotion recognition using bayesian neural networks and label distribution learning,
N. R. Prabhu, N. Lehmann-Willenbrock, and T. Gerkmann, “End- to-end label uncertainty modeling in speech emotion recognition using bayesian neural networks and label distribution learning,” IEEE Transactions on Affective Computing, vol. 15, no. 2, pp. 579–592, 2023
2023
-
[15]
Generative approach using soft-labels to learn uncertainty in predicting emotional attributes,
K. Sridhar, W.-C. Lin, and C. Busso, “Generative approach using soft-labels to learn uncertainty in predicting emotional attributes,” inInternational Conference on Affective Computing and Intelli- gent Interaction (ACII 2021), 2021
2021
-
[16]
Learning annotation consensus for con- tinuous emotion recognition,
I. Shoer and E. Erzin, “Learning annotation consensus for con- tinuous emotion recognition,”arXiv preprint arXiv:2505.21196, 2025
-
[18]
Embracing ambiguity and subjectivity using the all-inclusive aggregation rule for evaluating multi-label speech emotion recognition systems,
H.-C. Chou, H. Wu, L. Goncalves, S.-G. Leem, A. Salman, C. Busso, H.-y. Lee, and C.-C. Lee, “Embracing ambiguity and subjectivity using the all-inclusive aggregation rule for evaluating multi-label speech emotion recognition systems,” inProc. Inter- speech, 2024
2024
-
[19]
Embracing ambiguity and subjectivity using the all-inclusive aggregation rule for evaluating multi-label speech emotion recognition systems,
H.-C. Chou, H. Wu, L. Goncalves, S.-G. Leem, A. Salman, C. Busso, and H. yi Lee, “Embracing ambiguity and subjectivity using the all-inclusive aggregation rule for evaluating multi-label speech emotion recognition systems,” inIEEE Spoken Language Technology Workshop (SLT), 2024
2024
-
[20]
Beyond single emotion: Multi-label ap- proach to conversational emotion recognition,
Y . Kang and Y .-S. Cho, “Beyond single emotion: Multi-label ap- proach to conversational emotion recognition,” inProceedings of the AAAI Conference on Artificial Intelligence, 2025, pp. 24 321– 24 329
2025
-
[21]
Extending speech emotion recogni- tion systems to non-prototypical emotions using mixed-emotion model,
P. Kumawat and A. Routray, “Extending speech emotion recogni- tion systems to non-prototypical emotions using mixed-emotion model,”Expert Systems with Applications, vol. 260, p. 125358, 2025
2025
-
[22]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Wang, Z. Chen, J. Li, Y . Qian, and F. Wei, “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Se- lected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[23]
Learning more from mixed emotions: A label refinement method for emotion recogni- tion in conversations,
J. Wen, G. Tu, R. Li, D. Jiang, and W. Zhu, “Learning more from mixed emotions: A label refinement method for emotion recogni- tion in conversations,”Transactions of the Association for Com- putational Linguistics, vol. 11, pp. 1485–1499, 2023
2023
-
[24]
V . Mitra, A. Romana, D. T. Tran, and E. Azemi, “Modeling speech emotion with label variance and analyzing performance across speakers and unseen acoustic conditions,”I Can’t Believe It’s Not Better Workshop @ ICLR, 2025, arXiv:2503.22711
-
[25]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,” The Annals of Mathematical Statistics, vol. 22, no. 1, pp. 79–86, 1951
1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.