Understanding Cross-Rig Generalization in Automotive Perception: a Multi-Rig Benchmark and Rig Variation Metrics
Pith reviewed 2026-06-29 01:46 UTC · model grok-4.3
The pith
Geometric rig differences cause performance shifts in autonomous driving perception, with Rig Contrastive Distance ranking transfer difficulty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a simulation benchmark with fixed scene content but varied camera rigs, the authors find that geometric observation differences alone drive substantial cross-rig performance changes in representative perception architectures. Rig Contrastive Distance, derived from rig calibration metadata, serves as a reliable proxy for ranking the difficulty of model transfer between different sensor configurations.
What carries the argument
Rig Contrastive Distance, a metric that quantifies geometric discrepancy between camera rigs based on calibration data.
If this is right
- Models trained on one rig can have their transfer performance to another rig estimated using the contrastive distance without additional experiments.
- The benchmark enables controlled studies of geometric domain gaps separate from appearance or scene changes.
- Vehicle fleets with varying rigs may require rig-specific adaptations or metric-guided model selection.
- Rig Variance can help assess how robust a single rig's perception setup is internally.
Where Pith is reading between the lines
- Real vehicle manufacturers could use the metric to design rigs that minimize transfer issues across a fleet.
- Extending the metric to other sensor types like radar or LiDAR could address similar generalization problems.
- Testing the correlation in physical hardware swaps would strengthen the evidence beyond simulation.
Load-bearing premise
The CARLA simulation renders identical scenes across rigs without introducing any non-geometric artifacts that affect perception model performance.
What would settle it
Observing no correlation between Rig Contrastive Distance and actual performance shifts when testing on real vehicles with swapped camera rigs would falsify the claim.
Figures

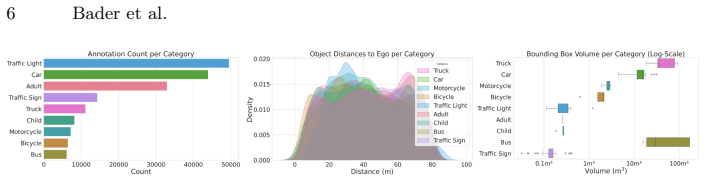
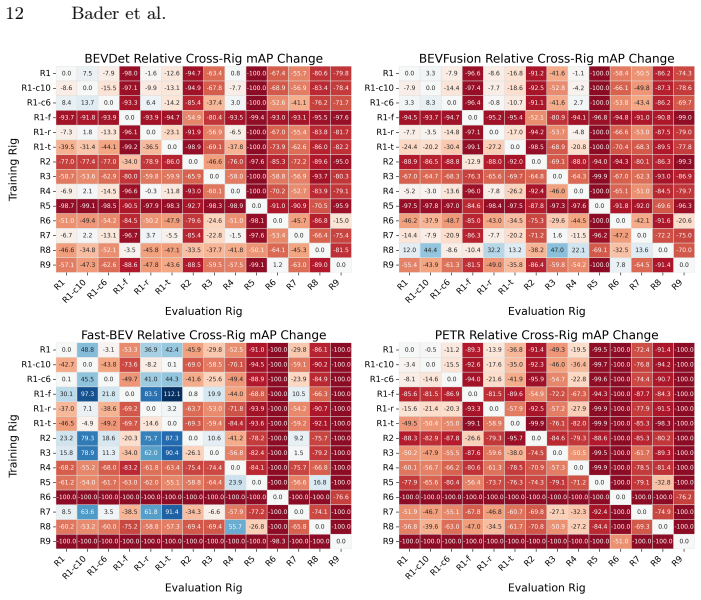
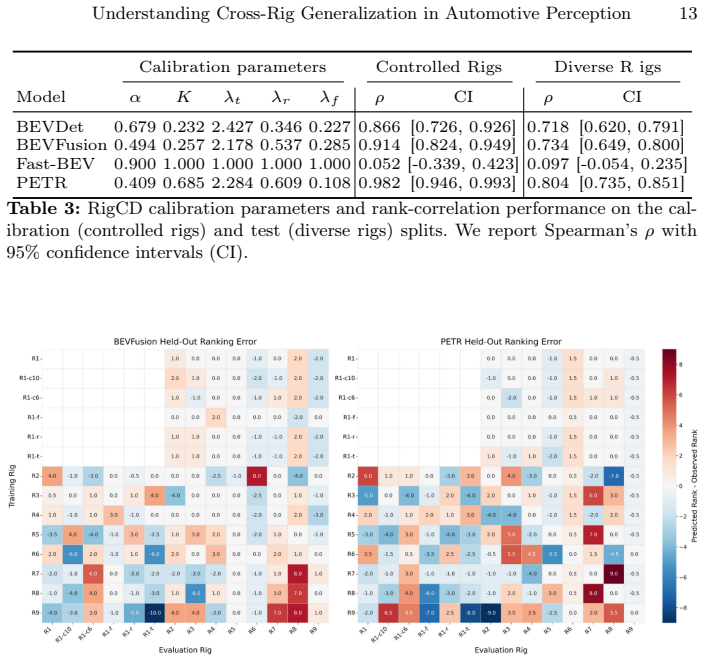
read the original abstract
Camera-based perception systems for autonomous driving are typically developed and evaluated using fixed sensor rigs, while real-world vehicle fleets exhibit substantial variation in camera placement, orientation, field of view, and camera count. This mismatch introduces a cross-rig domain gap in which only the geometric observation process changes. To study this effect under controlled conditions, we introduce Plentiful CARLA Camera Rigs, a benchmark that renders identical driving scenes under 14 systematically designed camera rigs. This setup enables direct analysis of cross-rig generalization without confounding changes in scene content or appearance. Using the benchmark, we analyze cross-rig transfer behavior of representative multi-view perception architectures and observe substantial performance shifts induced by geometric rig variation. To facilitate structured analysis, we further introduce two calibration-based descriptors derived from rig metadata: Rig Variance, capturing internal rig diversity, and Rig Contrastive Distance, measuring geometric discrepancy between rigs. Our experiments show that geometric rig differences strongly correlate with relative cross-rig performance shifts and that Rig Contrastive Distance provides a reliable proxy for ranking transfer difficulty between sensor rigs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Plentiful CARLA Camera Rigs benchmark, which renders identical driving scenes across 14 systematically varied camera rigs in CARLA to isolate geometric observation differences (placement, orientation, FOV, count). It proposes two metadata-derived descriptors—Rig Variance (internal rig diversity) and Rig Contrastive Distance (inter-rig geometric discrepancy)—and claims that these metrics strongly correlate with relative cross-rig performance shifts of multi-view perception models and that Rig Contrastive Distance reliably ranks transfer difficulty.
Significance. If the reported correlations hold after controlling for simulation artifacts and the metrics prove predictive on held-out rigs, the benchmark and descriptors would offer a practical, calibration-based framework for anticipating and mitigating geometric domain gaps in automotive perception without requiring new data collection.
major comments (2)
- [Abstract / §3 (benchmark)] Abstract and benchmark description: the central claim that 'rendering identical driving scenes under different rigs isolates purely geometric observation effects without confounding changes in scene content or appearance' is load-bearing for all subsequent correlation results, yet no pixel-wise, feature-space, or rendering-equivalence controls (e.g., across varying intrinsics/extrinsics) are described to rule out CARLA pipeline artifacts such as texture sampling, projection, or anti-aliasing differences.
- [§5 (experiments)] Experiments section: the assertions of 'strong correlation' between Rig Contrastive Distance and relative performance shifts, and that the metric 'provides a reliable proxy for ranking transfer difficulty,' require explicit quantitative support (Pearson/Spearman coefficients, p-values, baseline comparisons against random or appearance-based distances) that is not visible in the abstract and must be verified with statistical tests and ablation controls.
minor comments (2)
- [§4 (metrics)] Clarify the exact definitions and formulas for Rig Variance and Rig Contrastive Distance (currently described only at high level as 'derived from rig metadata') so readers can reproduce the descriptors from the 14 rig configurations.
- [§5 (experiments)] Specify the exact multi-view perception architectures evaluated and the precise cross-rig transfer protocol (e.g., which rigs are used for training vs. testing) to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments and commit to revisions that directly address the identified gaps.
read point-by-point responses
-
Referee: [Abstract / §3 (benchmark)] Abstract and benchmark description: the central claim that 'rendering identical driving scenes under different rigs isolates purely geometric observation effects without confounding changes in scene content or appearance' is load-bearing for all subsequent correlation results, yet no pixel-wise, feature-space, or rendering-equivalence controls (e.g., across varying intrinsics/extrinsics) are described to rule out CARLA pipeline artifacts such as texture sampling, projection, or anti-aliasing differences.
Authors: We agree that the isolation claim is central and that explicit verification is needed. The current manuscript relies on CARLA's deterministic scene rendering but does not report quantitative equivalence checks. In revision we will add a dedicated subsection in §3 with pixel-level metrics (SSIM, PSNR) and feature-space cosine similarity computed on the same scene across rigs, plus a brief discussion of how intrinsics/extrinsics changes affect projection without introducing appearance artifacts. revision: yes
-
Referee: [§5 (experiments)] Experiments section: the assertions of 'strong correlation' between Rig Contrastive Distance and relative performance shifts, and that the metric 'provides a reliable proxy for ranking transfer difficulty,' require explicit quantitative support (Pearson/Spearman coefficients, p-values, baseline comparisons against random or appearance-based distances) that is not visible in the abstract and must be verified with statistical tests and ablation controls.
Authors: The manuscript shows correlation plots but indeed omits the requested coefficients and baselines. We will augment §5 with Pearson and Spearman coefficients (plus p-values) for Rig Contrastive Distance versus performance deltas, and add two ablation baselines: (i) random rig-pair distances and (ii) an appearance-based distance computed from rendered image statistics. These will be reported in a new table and discussed with respect to ranking reliability. revision: yes
Circularity Check
No circularity: metrics defined from independent rig metadata and empirically correlated with performance
full rationale
The paper defines Rig Variance and Rig Contrastive Distance as calibration-based descriptors computed directly from rig metadata (placement, orientation, FOV, count). These descriptors are then correlated against observed cross-rig performance shifts from the CARLA benchmark experiments. No equations or text indicate that the descriptors are fitted to, derived from, or constructed as functions of the performance numbers they later rank or correlate against. The central claim is an empirical observation of correlation rather than a derivation that reduces to its inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CARLA rendering isolates geometric camera effects without confounding appearance or content changes
invented entities (2)
-
Rig Variance
no independent evidence
-
Rig Contrastive Distance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bader, T.A., Eberhardt, T.D., Sohn, T.S., Stork, W., et al.: Toward a universal perception layer: A survey on sensor-agnostic advanced driver assistance systems. Inf. Fusion136(2026).https://doi.org/10.1016/j.inffus.2026.104543
-
[2]
In: IEEE Conf
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 11621–11631 (2020)
2020
-
[3]
Contributors, M.: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.https://github.com/open- mmlab/mmdetection3d (2020)
2020
-
[4]
IEEE Access12, 96797–96820 (2024)
Dalal, A., Hagen, D., Robbersmyr, K.G., Knausgård, K.M.: Gaussian splatting: 3d reconstruction and novel view synthesis: A review. IEEE Access12, 96797–96820 (2024)
2024
-
[5]
In: Proc
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V.: CARLA: An open urban driving simulator. In: Proc. Conf. Robot Learn. pp. 1–16 (2017)
2017
-
[6]
In: Proc
Embacher, F., Holtz, D., Uhrig, J., Cordts, M., Enzweiler, M.: Neural Rendering for Sensor Adaptation in 3D Object Detection. In: Proc. IEEE Intell. Veh. Symp. pp. 1400–1407 (2025)
2025
-
[7]
IEEE Trans
Gamage, D., et al.: Evaluating sensor configurations for autonomous driving: A perception-entropy-based framework. IEEE Trans. Intell. Veh. (2025)
2025
-
[8]
In: IEEE Conf
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 770–778 (2016)
2016
-
[9]
In: IEEE Conf
Hu, C., et al.: Investigating the impact of multi-lidar placement on 3d object detec- tion for autonomous driving. In: IEEE Conf. Comput. Vis. Pattern Recog. (2022)
2022
-
[10]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Huang, J., Huang, G., Zhu, Z., Ye, Y., Du, D.: Bevdet: High-performance multi- camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Huang, J., Ye, Y., Liang, Z., Shan, Y., Du, D.: Detecting as labeling: Rethinking lidar-camera fusion in 3d object detection. In: Eur. Conf. Comput. Vis. pp. 439–455 (2024)
2024
-
[12]
In: Proc
Indu, S., Srivastava, S., Sharma, V.: Optimal camera placement and orientation of a multi-camera system for self driving cars. In: Proc. Int. Conf. Vis., Image Signal Process. pp. 1–5 (2020)
2020
-
[13]
Klinghoffer, T., Philion, J., Chen, W., Litany, O., Gojcic, Z., Joo, J., Raskar, R., Fidler, S., Alvarez, J.M.: Towards viewpoint robustness in bird’s eye view segmentation. In: Int. Conf. Comput. Vis. pp. 8515–8524 (2023)
2023
-
[14]
Li, S., Kachana, P., Chidananda, P., Nair, S., Furukawa, Y., Brown, M.: Rig3r: Rig- aware conditioning and discovery for 3d reconstruction. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[15]
IEEE Trans
Li, Y., Huang, B., Chen, Z., Cui, Y., Liang, F., Shen, M., Liu, F., Xie, E., Sheng, L., Ouyang, W., et al.: Fast-bev: A fast and strong bird’s-eye view perception baseline. IEEE Trans. Pattern Anal. Mach. Intell.46(12), 8665–8679 (2024)
2024
-
[16]
IEEE Trans
Li, Y., Liu, Z.: Information entropy-based viewpoint planning for 3-d object recon- struction. IEEE Trans. Robot.21(3), 324–337 (2005)
2005
-
[17]
In: Proc
Li, Y., et al.: Influence of camera–lidar configuration on 3d object detection for autonomous driving. In: Proc. IEEE Int. Conf. Robot. Autom. (2024)
2024
-
[18]
IEEE Trans
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bevformer: learningbird’s-eye-viewrepresentationfromlidar-cameraviaspatiotemporaltrans- formers. IEEE Trans. Pattern Anal. Mach. Intell. (2024) Understanding Cross-Rig Generalization in Automotive Perception 17
2024
-
[19]
Liang, T., Xie, H., Yu, K., Xia, Z., Lin, Z., Wang, Y., Tang, T., Wang, B., Tang, Z.: Bevfusion: A simple and robust lidar-camera fusion framework. Adv. Neural Inform. Process. Syst.35, 10421–10434 (2022)
2022
-
[20]
IEEE Trans
Liu, M., Yurtsever, E., Fossaert, J., Zhou, X., Zimmer, W., Cui, Y., Zagar, B.L., Knoll, A.C.: A survey on autonomous driving datasets: Statistics, annotation qual- ity, and a future outlook. IEEE Trans. Intell. Veh.9(11), 7138–7164 (2024)
2024
-
[21]
Liu, Y., Wang, T., Zhang, X., Sun, J.: Petr: Position embedding transformation for multi-view 3d object detection. In: Eur. Conf. Comput. Vis. pp. 531–548 (2022)
2022
-
[22]
Liu, Y., Yan, J., Jia, F., Li, S., Gao, A., Wang, T., Zhang, X.: Petrv2: A unified framework for 3d perception from multi-camera images. In: Int. Conf. Comput. Vis. pp. 3262–3272 (2023)
2023
-
[23]
In: Proc
Liu, Y., et al.: Where should we place lidars on the autonomous vehicle? an optimal design approach. In: Proc. IEEE Int. Conf. Robot. Autom. (2022)
2022
-
[24]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
In: IEEE Conf
Ma, X., et al.: Perception entropy for evaluating multi-sensor configurations in autonomous driving. In: IEEE Conf. Comput. Vis. Pattern Recog. (2024)
2024
-
[26]
Mao, J., Shi, S., Wang, X., Li, H.: 3d object detection for autonomous driving: A comprehensive survey. Int. J. Comput. Vis.131(8), 1909–1963 (2023)
1909
-
[27]
NVIDIA, Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., Chattopadhyay, P., Chen, M., Chen, Y., Chen, Y., Cheng, S., Cui, Y., Diamond, J., Ding, Y., Fan, J., Fan, L., Feng, L., Ferroni, F., Fidler, S., Fu, X., Gao, R., Ge, Y., Gu, J., Gupta, A., Gururani, S., El Hanafi, I., Hassani, A., Hao, Z., Huffman...
2025
-
[28]
NVIDIA, Cao, Y., de Lutio, R., Fidler, S., Cobo, G.G., Gojcic, Z., Igl, M., Ivanovic, B., Karkus, P., Esturo, J.M., Pavone, M., Smith, A., Tanimura, E., Tyszkiewicz, M., Watson, M., Wu, Q., Zhang, L.: Alpasim: A modular, lightweight, and data- driven research simulator for autonomous driving (2025),https://github.com/ NVlabs/alpasim
2025
-
[29]
NVIDIA Corporation: Physicalai autonomous vehicles dataset (2025),https:// huggingface.co/datasets/nvidia/PhysicalAI-Autonomous-Vehicles
2025
-
[30]
Paulin, G., Ivasic-Kos, M.: Review and analysis of synthetic dataset generation methods and techniques for application in computer vision. Artif. Intell. Rev. 56(9), 9221–9265 (2023)
2023
-
[31]
Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Eur. Conf. Comput. Vis. pp. 194–210 (2020)
2020
-
[32]
arXiv preprint arXiv:2105.06896 (2021)
Reichert, H., Lang, L., Rösch, K., Bogdoll, D., Doll, K., Sick, B., Reuss, H.C., Stiller, C., Zöllner, J.M.: Towards Sensor Data Abstraction of Autonomous Vehicle Perception Systems. arXiv preprint arXiv:2105.06896 (2021)
-
[33]
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: Eur. Conf. Comput. Vis. pp. 256–274 (2024) 18 Bader et al
2024
-
[34]
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., et al.: Scalability in perception for autonomous driving: Waymo open dataset. In: Int. Conf. Comput. Vis. pp. 2446–2454 (2020)
2020
-
[35]
Vázquez, P.P., et al.: Viewpoint selection using viewpoint entropy. Comput. Graph. Forum22(4), 689–700 (2003)
2003
-
[36]
In: Comput
Vázquez, P.P., Feixas, M., Sbert, M., Heidrich, W.: Automatic view selection us- ing viewpoint entropy and its application to image-based modelling. In: Comput. Graph. Forum. vol. 22, pp. 689–700 (2003)
2003
-
[37]
In: Proc
Wakabayashi, K., Yukawa, C., Oda, T., Barolli, L.: A camera placement system for motion analysis and object recognition: System assessment by simulations and an experiment. In: Proc. Int. Conf. Innovative Mobile Internet Services Ubiquitous Comput. pp. 27–38 (2024)
2024
-
[38]
In: Proc
Wang, H., Yao, K., Pottie, G., Estrin, D.: Entropy-based sensor selection heuristic for target localization. In: Proc. Int. Symp. Inf. Process. Sensor Netw. pp. 36–45 (2004)
2004
-
[39]
In: IEEE Conf
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Vi- sual geometry grounded transformer. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5294–5306 (2025)
2025
-
[40]
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Int. Conf. Comput. Vis. pp. 20697–20709 (2024)
2024
-
[41]
In: Proc
Wang, Y., Guizilini, V.C., Zhang, T., Wang, Y., Zhao, H., Solomon, J.: Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Proc. Conf. Robot Learn. pp. 180–191 (2022)
2022
-
[42]
Yang, C., Chen, Y., Tian, H., Tao, C., Zhu, X., Zhang, Z., Huang, G., Li, H., Qiao, Y., Lu, L., et al.: Bevformer v2: Adapting modern image backbones to bird’s- eye-view recognition via perspective supervision. In: Int. Conf. Comput. Vis. pp. 17830–17839 (2023)
2023
-
[43]
In: IEEE Conf
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21924–21935 (2025)
2025
-
[44]
IEEE Conf
Yin, T., Zhou, X., Krähenbühl, P.: Center-based 3d object detection and tracking. IEEE Conf. Comput. Vis. Pattern Recog. (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.