PEBS: Per-rater Empirical-Bayes Shrinkage for RLHF Reward-Model Calibration
Pith reviewed 2026-06-29 01:23 UTC · model grok-4.3
The pith
PEBS shrinks per-rater affine calibrators toward the population mean in closed form, cutting held-out RMSE by 8.58 percent on PRISM reward ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
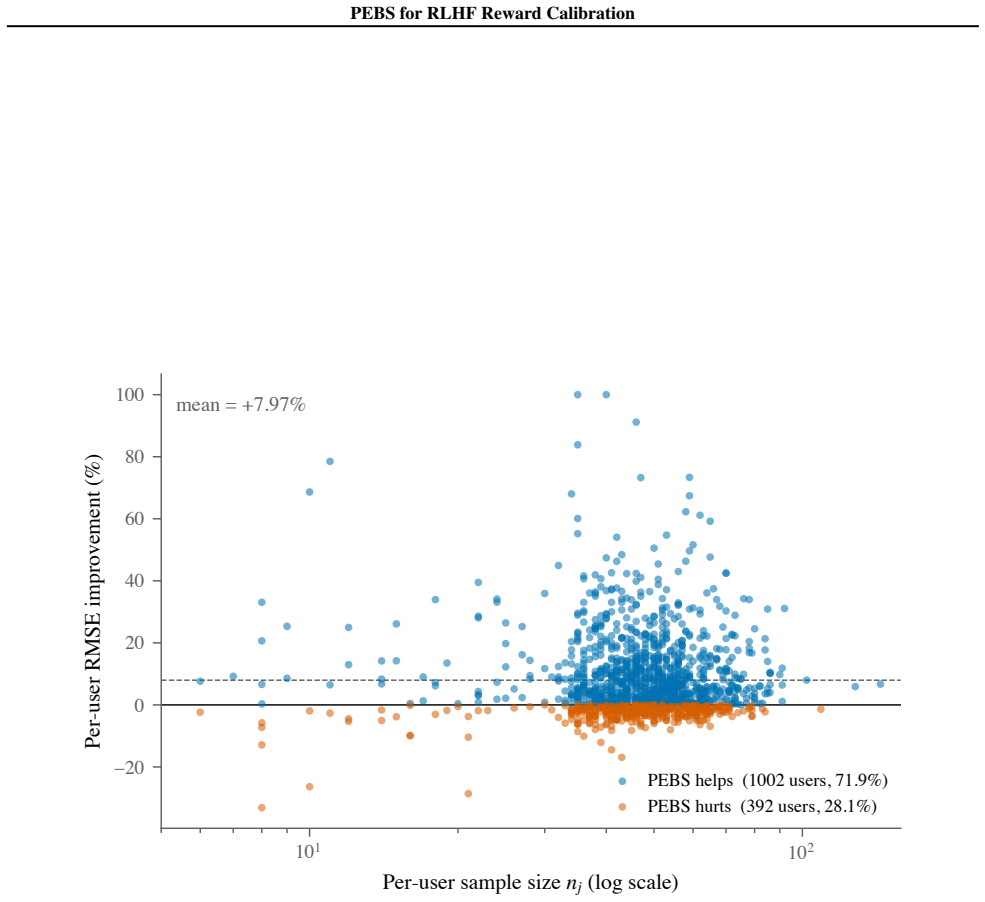
PEBS is a per-rater empirical-Bayes shrinkage estimator that fits affine calibrators on held-out slices of each annotator's ratings and shrinks them toward the population mean without retraining the reward model. On the PRISM dataset it reduces within-user held-out RMSE by 8.58 percent relative to the pooled population-slope baseline; the same procedure yields a 9.66 percent RMSE reduction on PluriHarms harm ratings using a Qwen-2.5 base model.
What carries the argument
per-rater empirical-Bayes shrinkage applied to affine calibration maps
If this is right
- Inference-time rating calibration becomes annotator-specific while the base reward model stays fixed.
- No additional training or gradient steps are required beyond the original reward-model fit.
- The same shrinkage procedure can be applied to other rating tasks that use affine maps, such as harm scoring.
- Population-level calibration remains available as the shrinkage target when per-rater data are scarce.
Where Pith is reading between the lines
- The method could be extended to non-affine calibrators if a parametric form is chosen that still admits closed-form shrinkage.
- In production RLHF pipelines the per-rator maps could be updated incrementally as new ratings arrive without refitting the base model.
- If annotator identities are unavailable at inference, the population mean serves as a natural fallback.
Load-bearing premise
A held-out slice of each annotator's ratings exists and is representative enough to fit stable per-rater affine calibrators before shrinkage.
What would settle it
Run the method on a dataset where each annotator has too few ratings for a stable held-out fit; if RMSE improvement disappears or reverses, the per-rater calibration step is not adding value.
Figures


read the original abstract
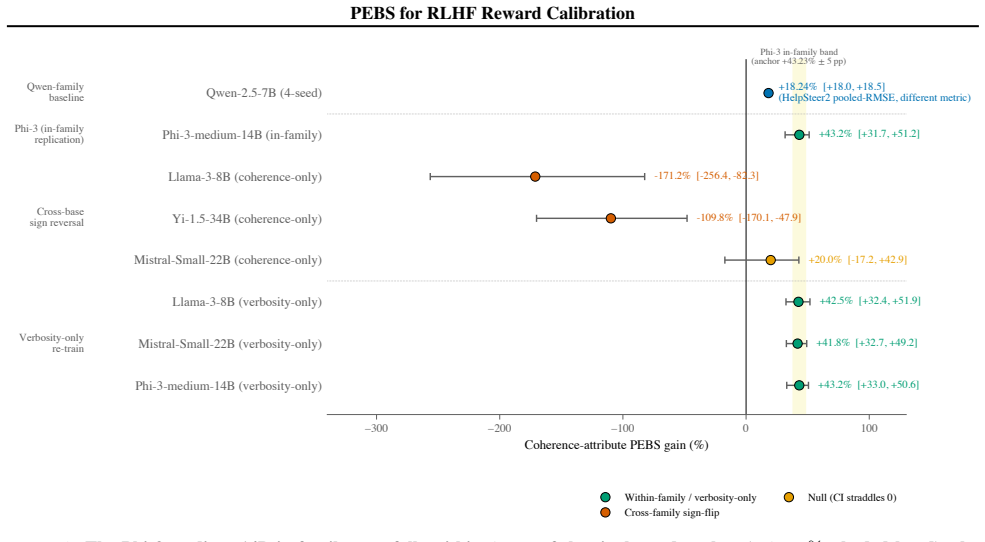
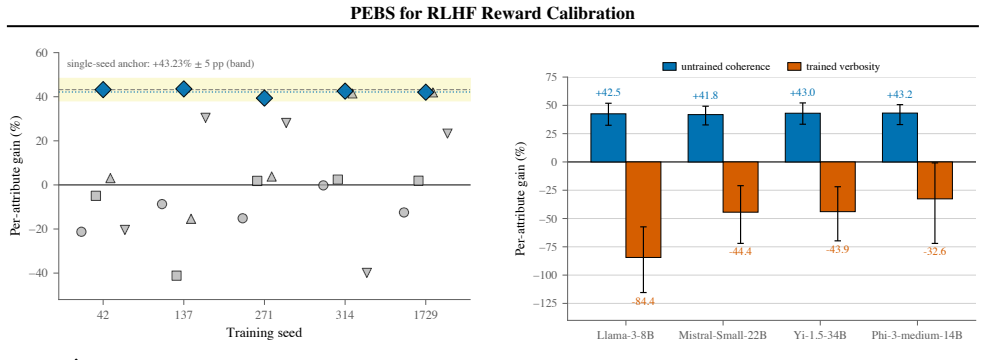
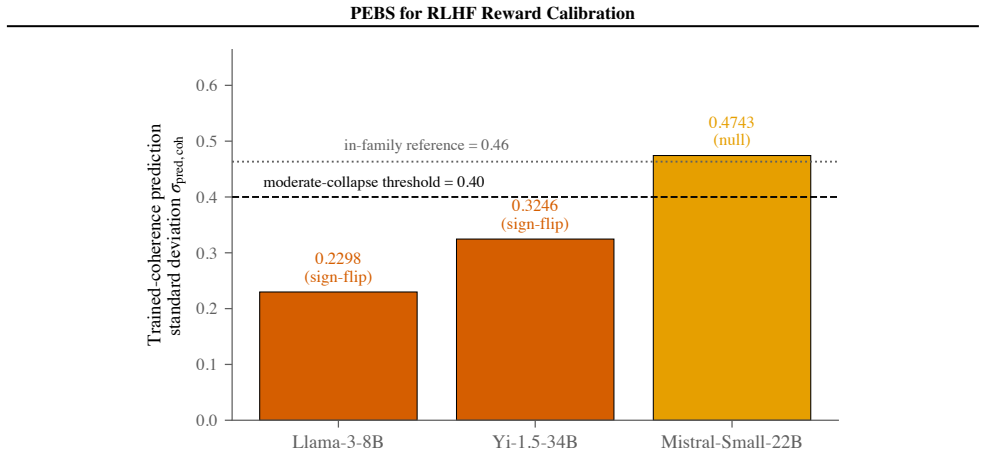
Reward models for Reinforcement Learning from Human Feedback (RLHF) pool preferences across thousands of annotators and fit one global affine calibrator, collapsing raters with systematically different rating-scale offsets and slopes into a single average-rater fit that does not match any individual annotator. PEBS is a per-rater empirical-Bayes shrinkage estimator: it fits per-rater affine calibrators on a held-out slice of each annotator's ratings and applies Morris-James-Stein empirical-Bayes shrinkage toward the population mean, in closed form and without retraining the reward model. On PRISM, PEBS reduces within-user held-out RMSE by 8.58% over the pooled population-slope baseline. The procedure replicates on PluriHarms harm ratings (Qwen-2.5 base, in-family) with a +9.66% RMSE reduction over the same population-slope baseline. PEBS is a closed-form post-hoc estimator for annotator-specific affine calibration in RLHF reward modeling; it leaves the reward base model unchanged and estimates only the rater-level map used at inference time for new ratings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PEBS, a closed-form per-rater empirical-Bayes shrinkage estimator for affine calibration of RLHF reward models. It fits per-rater intercept and slope on a held-out slice of each annotator's ratings, shrinks these toward the population mean via Morris-James-Stein, and applies the resulting rater-specific map at inference without retraining the base reward model. On PRISM it reports an 8.58% within-user held-out RMSE reduction over a pooled population-slope baseline; the result replicates on PluriHarms harm ratings (Qwen-2.5) with a 9.66% reduction.
Significance. If the per-rater estimates prove stable, PEBS supplies a lightweight, post-hoc calibration step that directly addresses annotator heterogeneity while leaving the underlying reward model unchanged. The closed-form nature and replication on two distinct datasets (PRISM and PluriHarms) are concrete strengths that would make the method easy to adopt.
major comments (2)
- [Abstract] Abstract: the reported 8.58% and 9.66% RMSE reductions rest on the assumption that a held-out slice exists for each annotator that is large enough to yield stable per-rater affine fits before shrinkage; no per-annotator rating counts, minimum thresholds, or slice-size statistics are supplied, leaving the central empirical claim unverifiable.
- [Abstract] Abstract and evaluation description: the RMSE improvements are stated without error bars, standard errors, or any statistical test, so it is impossible to determine whether the observed gains exceed sampling variability in the within-user held-out slices.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on verifiability and statistical reporting. We address each major comment below and will revise the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 8.58% and 9.66% RMSE reductions rest on the assumption that a held-out slice exists for each annotator that is large enough to yield stable per-rater affine fits before shrinkage; no per-annotator rating counts, minimum thresholds, or slice-size statistics are supplied, leaving the central empirical claim unverifiable.
Authors: We agree that the absence of per-annotator rating statistics limits verifiability of the empirical claims. In the revised manuscript we will add a dedicated subsection (or appendix table) reporting the distribution of ratings per annotator (mean, median, min, max, and quartiles), the minimum rating count threshold used for inclusion, and the exact sizes of the held-out slices employed for fitting the per-rater affine calibrators on both PRISM and PluriHarms. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: the RMSE improvements are stated without error bars, standard errors, or any statistical test, so it is impossible to determine whether the observed gains exceed sampling variability in the within-user held-out slices.
Authors: We acknowledge that the reported RMSE reductions lack measures of uncertainty or formal significance tests. In revision we will augment the abstract and evaluation sections with standard errors obtained via bootstrap resampling over annotators (or via repeated random held-out splits), and we will report the results of a paired statistical test (e.g., Wilcoxon signed-rank or t-test on per-annotator RMSE differences) to assess whether the observed improvements are statistically distinguishable from zero. revision: yes
Circularity Check
No significant circularity; estimator independent of reported metric
full rationale
The paper defines PEBS as a closed-form post-hoc procedure that fits per-rater affine calibrators on held-out slices then applies standard Morris-James-Stein shrinkage toward the population mean. The reported within-user held-out RMSE reductions are evaluated on data separate from the fitting slices, and the shrinkage formulas are taken from classical empirical-Bayes results rather than tuned to the target RMSE numbers. No self-citations, ansatzes, or uniqueness theorems from the authors are invoked as load-bearing steps, and the derivation does not reduce any claimed prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rater differences in RLHF preferences are adequately modeled by per-rater affine transformations of a shared reward model output.
Reference graph
Works this paper leans on
-
[1]
arXiv:2407.17387. Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[2]
Coste, T., Anwar, U., Kirk, R., and Krueger, D
PMLR 235; arXiv:2404.10271. Coste, T., Anwar, U., Kirk, R., and Krueger, D. Reward model ensembles help mitigate overoptimization. InInternational Conference on Learning Representations (ICLR),
-
[3]
Ghafouri, B., Choi, E. C., Dey, P., and Ferrara, E. Measuring human preferences in RLHF is a social science problem. arXiv preprint arXiv:2604.03238,
-
[4]
EBPO: Empirical bayes shrinkage for stabilizing group-relative policy optimization
Han, K., Zhou, Y ., Gao, M., Zhou, G., Li, S., Kumar, A., Fan, X., Li, W., and Zhang, L. EBPO: Empirical bayes shrinkage for stabilizing group-relative policy optimization. arXiv preprint arXiv:2602.05165,
-
[5]
arXiv:2404.16019. Kobalczyk, K. and van der Schaar, M. Preference learning for AI alignment: A causal perspective. InInternational Conference on Machine Learning (ICML),
-
[6]
arXiv:2506.05967. K¨opf, A., Kilcher, Y ., von R¨utte, D., Anagnostidis, S., Tam, Z.-R., Stevens, K., Barhoum, A., Duc, N. M., Stanley, O., Nagyfi, R., ES, S., Suri, S., Glushkov, D., Dantuluri, A., Maguire, A., Schuhmann, C., Nguyen, H., and Mattick, A. OpenAs- sistant conversations – democratizing large language model alignment. InAdvances in Neural Inf...
-
[7]
arXiv:2304.07327. Kou, S. C. and Yang, J. J. Optimal shrinkage estimation in heteroscedastic hierarchical linear models. InBig and Com- plex Data Analysis, Contributions to Statistics, pp. 249–284. Springer,
-
[8]
doi: 10.1007/978-3-319-41573-4
-
[9]
Li, J.-J., Mire, J., Fleisig, E., Pyatkin, V ., Collins, A., Sap, M., and Levine, S. PluriHarms: Benchmarking the full spectrum of hu- man judgments on AI harm.arXiv preprint arXiv:2601.08951,
-
[10]
Y ., Zeng, L., Liu, J., Yan, R., He, J., Wang, C., Yan, S., Liu, Y ., and Zhou, Y
Liu, C. Y ., Zeng, L., Liu, J., Yan, R., He, J., Wang, C., Yan, S., Liu, Y ., and Zhou, Y . Skywork-reward: Bag of tricks for reward modeling in LLMs.arXiv preprint arXiv:2410.18451,
-
[11]
Liu, P., Lu, J., and Sun, W. W. Uncertainty quantification for large language model reward learning under heterogeneous human feedback.arXiv preprint arXiv:2512.03208,
-
[12]
Personalized RewardBench: Evaluating reward models with human aligned personalization
Ma, Q., Gao, D., Cai, R., Zhao, B., Zhou, H., Zhang, J., and Zhao, Z. Personalized RewardBench: Evaluating reward models with human aligned personalization. arXiv preprint arXiv:2604.07343,
-
[13]
A., Ha- jishirzi, H., and Lambert, N
9 PEBS for RLHF Reward Calibration Malik, S., Pyatkin, V ., Land, S., Morrison, J., Smith, N. A., Ha- jishirzi, H., and Lambert, N. RewardBench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937,
-
[14]
Miranda, L. J. V ., Wang, Y ., Elazar, Y ., Kumar, S., Pyatkin, V ., Brahman, F., Smith, N. A., Hajishirzi, H., and Dasigi, P. Hy- brid preferences: Learning to route instances for human vs. AI feedback.arXiv preprint arXiv:2410.19133,
-
[15]
The reward model selection crisis in personal- ized alignment
Rezk, F., Pan, Y ., Foo, C.-S., Xu, X., Chen, N., Gouk, H., and Hospedales, T. The reward model selection crisis in personal- ized alignment. arXiv preprint arXiv:2512.23067,
-
[16]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[17]
Value kaleidoscope: Engaging AI with plural- istic human values, rights, and duties
Sorensen, T., Jiang, L., Hwang, J., Levine, S., Pyatkin, V ., West, P., Dziri, N., Lu, X., Rao, K., Bhagavatula, C., Sap, M., Tasioulas, J., and Choi, Y . Value kaleidoscope: Engaging AI with plural- istic human values, rights, and duties. InAAAI Conference on Artificial Intelligence, 2024a. arXiv:2309.00779. Sorensen, T., Moore, J., Fisher, J., Gordon, M...
-
[18]
Wang, Z., Dong, Y ., Delalleau, O., Zeng, J., Shen, G., Egert, D., Zhang, J
URL https:// github.com/huggingface/trl. Wang, Z., Dong, Y ., Delalleau, O., Zeng, J., Shen, G., Egert, D., Zhang, J. J., Sreedhar, M. N., and Kuchaiev, O. HelpSteer2: Open-source dataset for training top-performing reward models. arXiv preprint arXiv:2406.08673,
-
[19]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y ., Wan, Y ....
-
[20]
Zhang, L. H., Milli, S., Jusko, K., Smith, J., Amos, B., Bouaziz, W., Revel, M., Kussman, J., Sheynin, Y ., Titus, L., Radharapu, B., Yu, J., Sarma, V ., Rose, K., and Nickel, M. Cultivating pluralism in algorithmic monoculture: The community alignment dataset. arXiv preprint arXiv:2507.09650,
-
[21]
10 PEBS for RLHF Reward Calibration A
Oral; arXiv:2602.12116. 10 PEBS for RLHF Reward Calibration A. Proof of Theorem 1 (oracle inequality) We prove Theorem 1 in four steps: (i) a mean-squared error bound for the truncated Morris MoM estimator ˆτ2, (ii) a second- order Taylor expansion with Lagrange remainder around the oracle, (iii) aggregation across raters using the independence delivered ...
arXiv 1983
-
[22]
The off-event excess risk is therefore at most max(1, M)τ 2 per rater. For the probability, ˜τ2 −τ 2 is a centred Gaussian quadratic form whose coefficient vector satisfies ∥λ∥∞ ≤σ 2 max/(J−1)and∥λ∥ 2 2 ≤σ 4 max/(J−1), so the Hanson–Wright inequality gives P(E c) =P |˜τ2 −τ 2|> τ 2/2 ≤2 exp −c2 J−1 (1 +M) 2 for an absolute constant c2 >0 (the exponent is ...
2012
-
[23]
Bootstrap CIs are 95% BCa (Efron,
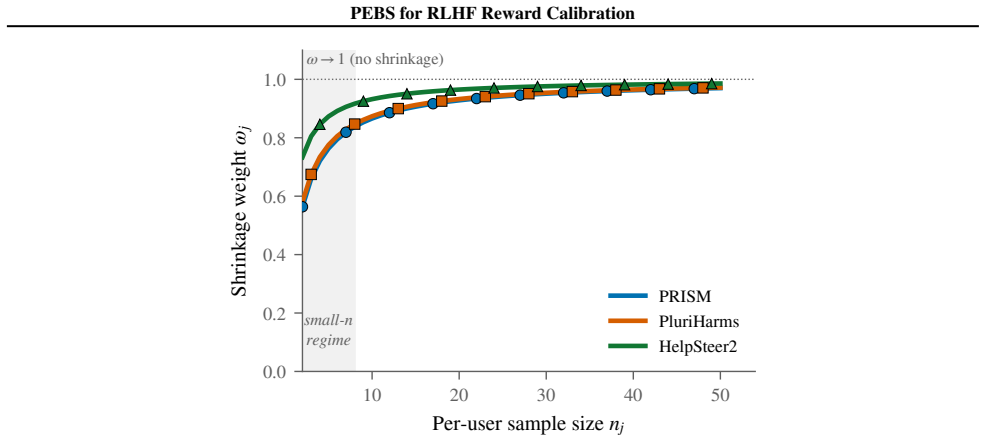
LoRA r=32, α=16, lr 10−4, bf16, 1,500 steps, centered-rewards regularizer (Eisenstein et al., 2024), pair accuracy CI [62.74,65.29] , ≈75 min H100 80 GB. Bootstrap CIs are 95% BCa (Efron,
2024
-
[24]
Methods whose published protocols optimise a different objective, metric, or feature space are cited in related work but are not reproduced as direct scalar-RMSE comparison rows here, since the protocol mismatch makes the resulting numbers incomparable. D. Dataset cards This appendix expands the corpora used in §3.4 (the three within-scope continuous-rati...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.