Beyond Points: Spherical Distributional Part Prototypes for Interpretable Classification
Pith reviewed 2026-07-01 06:20 UTC · model grok-4.3
The pith
vMFProto replaces point prototypes with von Mises-Fisher distributions on the hypersphere to capture intra-class part variability and deliver more consistent, stable explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
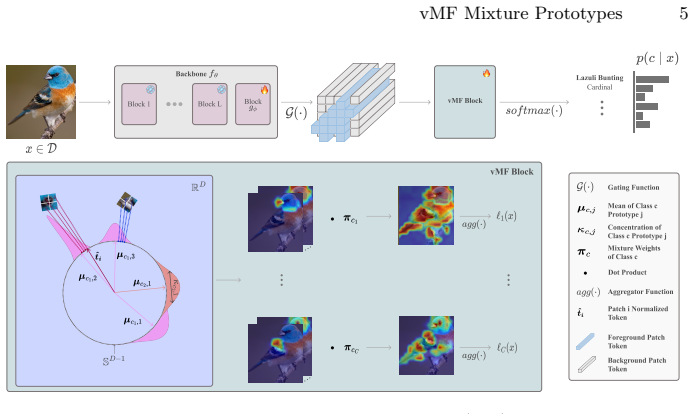
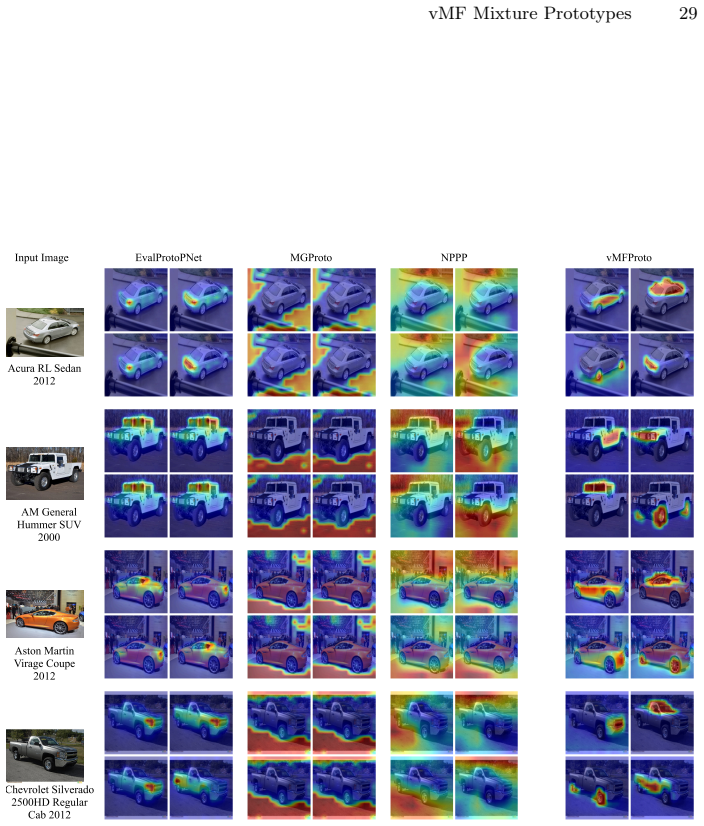
vMFProto models each class as a mixture of von Mises-Fisher components on the hypersphere, lets every prototype learn its own concentration parameter to encode part-specific variability, and obtains structured patch-to-prototype assignments through entropic optimal transport; a two-stage training procedure first performs OT-driven discovery and then performs end-to-end refinement with patch-level distillation and distribution-aware diversity regularization, producing state-of-the-art explanation quality together with competitive accuracy on the three evaluated fine-grained datasets.
What carries the argument
Mixture of von Mises-Fisher distributions with per-prototype concentration parameters plus entropic optimal transport for structured assignments.
Load-bearing premise
Intra-class variability around each semantic part can be summarized by a single scalar concentration per von Mises-Fisher prototype without needing orientation parameters or higher-order statistics.
What would settle it
Re-train the identical architecture on the same three datasets after replacing the von Mises-Fisher components with isotropic or fixed-concentration alternatives and measure whether the reported gains in consistency, stability, and distinctiveness disappear.
Figures
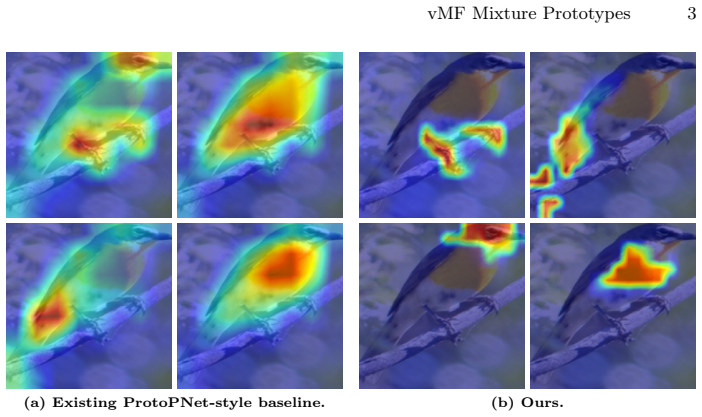
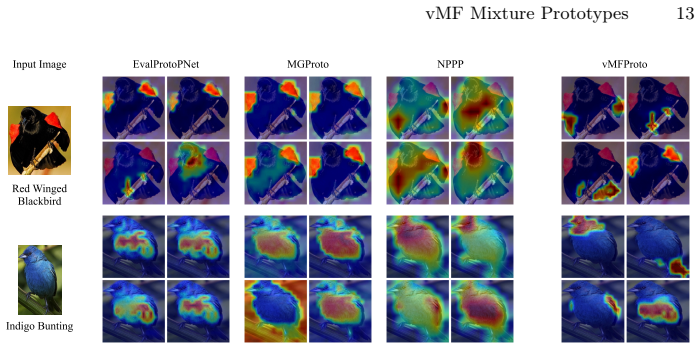

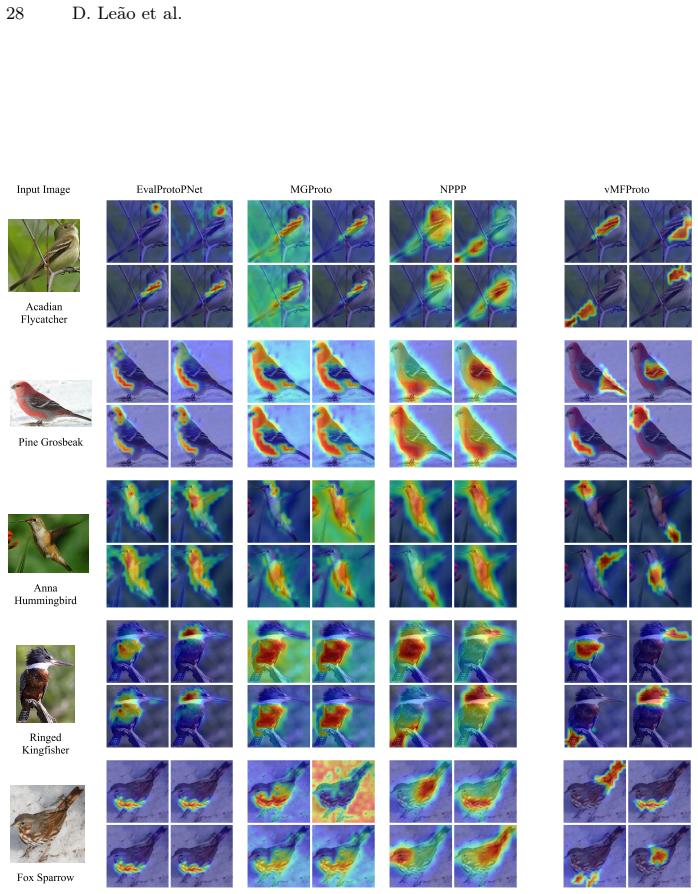

read the original abstract
Prototype-based neural networks aim to provide intrinsic interpretability by grounding predictions in a small set of part prototypes. However, modern vision backbones typically operate in normalized, directional embedding spaces where each semantic part exhibits substantial intra-class variability. As a result, point prototypes often become redundant or unstable, hurting both explanation quality and robustness. We propose vMFProto, a distributional part-prototype framework that models each class as a mixture of von Mises-Fisher components on the hypersphere. Each prototype learns its own concentration, capturing part-specific variability, and we use entropic optimal transport (OT) to obtain structured patch-to-prototype assignments. A two-stage training schedule performs OT-driven prototype discovery followed by end-to-end refinement with patch-level distillation and distribution-aware diversity regularization. Experiments on CUB-200-2011, Stanford Dogs, and Stanford Cars with frozen DINO backbones show that vMFProto achieves state-of-the-art explanation quality (consistency, stability, and distinctiveness) with competitive accuracy. Qualitative results confirm that vMFProto yields localized, non-redundant part evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces vMFProto, a prototype-based classification method that replaces point prototypes with von Mises-Fisher distributional prototypes on the unit hypersphere to model intra-class part variability in normalized DINO embeddings. Each prototype has a learned concentration parameter, assignments are obtained via entropic optimal transport, and training proceeds in two stages (OT-driven discovery followed by end-to-end refinement with patch distillation and diversity regularization). On CUB-200-2011, Stanford Dogs, and Stanford Cars the method is claimed to deliver state-of-the-art explanation quality (consistency, stability, distinctiveness) while maintaining competitive accuracy with frozen backbones.
Significance. If the empirical claims are substantiated with proper controls, the work would offer a principled extension of prototype interpretability to modern directional embedding spaces, potentially reducing redundancy and improving stability of explanations in fine-grained recognition tasks.
major comments (2)
- [Abstract] Abstract: the central claim of state-of-the-art explanation quality (consistency, stability, and distinctiveness) is presented without any quantitative definition of those three metrics, without reported error bars, and without ablation of the per-prototype concentration or entropic OT components; these omissions are load-bearing because the abstract itself states that the performance follows from the new modeling choices.
- [Abstract] Abstract: the premise that point prototypes become redundant or unstable is asserted as motivation, yet no quantitative comparison (e.g., redundancy or stability scores for point vs. distributional prototypes) is supplied to support that the two-stage schedule actually resolves the issue.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the abstract. We address each point below and will revise the abstract to improve clarity and support for the claims while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of state-of-the-art explanation quality (consistency, stability, and distinctiveness) is presented without any quantitative definition of those three metrics, without reported error bars, and without ablation of the per-prototype concentration or entropic OT components; these omissions are load-bearing because the abstract itself states that the performance follows from the new modeling choices.
Authors: We agree the abstract would benefit from tighter linkage to the supporting material. The three metrics receive quantitative definitions in Section 3.2 (consistency as mean intra-class prototype activation correlation, stability as assignment variance under augmentations, distinctiveness as minimum inter-prototype angular distance). Tables 2–4 report means with standard errors over five random seeds, and Section 4.3 contains the requested ablations isolating concentration learning and the entropic OT assignment. We will revise the abstract to add a short parenthetical clause (“see Sec. 3.2 and 4.3 for definitions, ablations, and error bars”) so the central claim is explicitly grounded without exceeding length limits. revision: yes
-
Referee: [Abstract] Abstract: the premise that point prototypes become redundant or unstable is asserted as motivation, yet no quantitative comparison (e.g., redundancy or stability scores for point vs. distributional prototypes) is supplied to support that the two-stage schedule actually resolves the issue.
Authors: The abstract states the motivation qualitatively, but the manuscript supplies the requested quantitative comparison in Section 4.2 and Table 1: point-prototype baselines exhibit higher average pairwise cosine similarity (redundancy) and higher assignment variance under perturbation (instability) than vMFProto; the two-stage schedule further reduces both quantities. We will insert a brief clause in the abstract (“quantitative comparisons in Sec. 4.2 confirm reduced redundancy and improved stability”) to make the motivation self-supporting. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces vMFProto as a new distributional prototype framework using per-prototype von Mises-Fisher concentrations and entropic OT assignments within a two-stage training schedule on frozen DINO embeddings. Claims of SOTA explanation quality and competitive accuracy are presented as direct empirical outcomes from experiments on CUB-200-2011, Stanford Dogs, and Stanford Cars. No equations, definitions, or load-bearing steps in the provided text reduce these results to quantities defined by the fitted concentrations, OT costs, or prior self-citations; the central construction remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-prototype concentration
- OT regularization strength
axioms (2)
- domain assumption von Mises-Fisher distributions are appropriate models for directional data on the unit hypersphere
- domain assumption entropic optimal transport yields structured, non-redundant assignments between patches and prototypes
Reference graph
Works this paper leans on
-
[1]
Bafghi, R.A., Harilal, N., Monteleoni, C., Raissi, M.: Parameter efficient fine- tuningofself-supervisedvitswithoutcatastrophicforgetting.In:Proceedingsofthe IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3679– 3684 (2024)
2024
-
[2]
Banerjee, A., Dhillon, I.S., Ghosh, J., Sra, S.: Clustering on the unit hypersphere using von Mises-Fisher distributions. J. Mach. Learn. Res.6, 1345–1382 (2005), https://www.jmlr.org/papers/v6/banerjee05a.html
2005
-
[3]
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Int. Conf. Comput. Vis. pp. 9650–9660 (2021),https://arxiv.org/abs/2104.14294
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Chen, C., Li, O., Tao, C., Barnett, A.J., Su, J., Rudin, C.: This looks like that: Deep learning for interpretable image recognition. In: Adv. Neural Inform. Process. Syst. (2019),https://proceedings.neurips.cc/paper/2019/hash/ adf7ee2dcf142b0e11888e72b43fcb75-Abstract.html
2019
-
[5]
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: Int. Conf. Mach. Learn. pp. 1597– 1607 (2020),https://arxiv.org/abs/2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. In: Adv. Neural Inform. Process. Syst. (2013),https://proceedings.neurips.cc/ paper/2013/hash/af21d0c97db2e27e13572cbf59eb343d-Abstract.html
2013
-
[7]
In: IEEE Conf
Donnelly, J., Barnett, A.J., Chen, C.: Deformable ProtoPNet: An interpretable image classifier using deformable prototypes. In: IEEE Conf. Comput. Vis. Pat- tern Recog. pp. 10265–10275 (2022),https://openaccess.thecvf.com/content/ CVPR2022 / html / Donnelly _ Deformable _ ProtoPNet _ An _ Interpretable _ Image _ Classifier_Using_Deformable_Prototypes_CVPR...
2022
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.: An image is worth 16x16 words: Transformers for image recogni- tion at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Huang, Q., Xue, M., Huang, W., Zhang, H., Song, J., Jing, Y., Song, M.: Evalu- ation and improvement of interpretability for self-explainable part-prototype net- works. In: Int. Conf. Comput. Vis. pp. 2011–2020 (2023),https://openaccess. thecvf.com/content/ICCV2023/html/Huang_Evaluation_and_Improvement_of_ Interpretability_ for _ Self - Explainable _ Part...
2011
-
[10]
In: First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition
Khosla, A., Jayadevaprakash, N., Yao, B., Fei-Fei, L.: Novel dataset for fine-grained image categorization. In: First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO (June 2011),http://vision.stanford.edu/aditya86/ImageNetDogs/
2011
-
[11]
In: ICCV Workshops (2013),https://openaccess
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine-grained categorization. In: ICCV Workshops (2013),https://openaccess. thecvf . com / content _ iccv _ workshops _ 2013 / W19 / html / Krause _ 3D _ Object _ Representations_2013_ICCV_paper.html
2013
-
[12]
In: IEEE Conf
Nauta, M., van Bree, R., Seifert, C.: Neural prototype trees for interpretable fine-grained image recognition. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 14933–14943 (2021),https://openaccess.thecvf.com/content/CVPR2021/html/ Nauta _ Neural _ Prototype _ Trees _ for _ Interpretable _ Fine - Grained _ Image _ Recognition_CVPR_2021_paper.html
2021
-
[13]
In: IEEE Conf
Nauta, M., Schlötterer, J., van Keulen, M., Seifert, C.: PIP-Net: Patch-based intu- itive prototypes for interpretable image classification. In: IEEE Conf. Comput. 16 D. Leão et al. Vis. Pattern Recog. pp. 2744–2753 (2023),https://openaccess.thecvf.com/ content/CVPR2023/html/Nauta_PIP-Net_Patch-Based_Intuitive_Prototypes_ for_Interpretable_Image_Classific...
2023
-
[14]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,Howes,R.,Huang,P.Y.,Li,S.W.,Misra,I.,Rabbat,M.,Sharma,V.,Synnaeve, G., Xu, H., Jegou, H., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual features without supervision....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Foundations and Trends in Machine Learning11(5–6), 355–607 (2019), https://optimaltransport.github.io/pdf/ComputationalOT.pdf
Peyré, G., Cuturi, M.: Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning11(5–6), 355–607 (2019), https://optimaltransport.github.io/pdf/ComputationalOT.pdf
2019
-
[16]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Int. Conf. Mach. Learn. (2021),https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [17]
-
[18]
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual explanations from deep networks via gradient-based localization. In: Int. Conf. Comput. Vis. (2017),https://openaccess.thecvf.com/content_iccv_ 2017/html/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.html
2017
-
[19]
In: Brit
Siméoni, O., Puy, G., Vo, H.V., Roburin, S., Gidaris, S., Bursuc, A., Pérez, P., Marlet, R., Ponce, J.: LOST: Localizing objects with self-supervised transformers and no labels. In: Brit. Mach. Vis. Conf. (2021),https://arxiv.org/abs/2109. 14279
2021
-
[20]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., et al.: DINOv3. arXiv:2508.10104 (2025).https://doi.org/10.48550/arXiv.2508.10104,https: //arxiv.org/abs/2508.10104
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2025
-
[21]
Ukai, Y., Hirakawa, T., Yamashita, T., Fujiyoshi, H.: This looks like it rather than that: ProtoKNN for similarity-based classifiers. In: Int. Conf. Learn. Represent. (2023),https://openreview.net/forum?id=lh-HRYxuoRr
2023
-
[22]
Wah,C.,Branson,S.,Welinder,P.,Perona,P.,Belongie,S.:Thecaltech-ucsdbirds- 200-2011 dataset. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011),https://www.vision.caltech.edu/datasets/cub_200_2011/
2011
-
[23]
Wang, C., Chen, Y., Liu, F., Liu, Y., McCarthy, D.J., Frazer, H., Carneiro, G.: Mixture of Gaussian-distributed prototypes with generative modelling for inter- pretable and trustworthy image recognition. IEEE Trans. Pattern Anal. Mach. Intell.47(8), 6974–6989 (2025),https://arxiv.org/abs/2312.00092
-
[24]
Wang, J., Liu, H., Wang, X., Jing, L.: Interpretable image recognition by constructing transparent embedding space. In: Int. Conf. Comput. Vis. pp. 895–904 (2021),https: / /openaccess. thecvf. com /content /ICCV2021/ html / Wang _ Interpretable _ Image _ Recognition _ by _ Constructing _ Transparent _ Embedding_Space_ICCV_2021_paper.html
2021
-
[25]
In: IJCAI
Xue, M., Huang, Q., Zhang, H., Hu, J., Song, J., Song, M., Jin, C.: Protop- former: Concentrating on prototypical parts in vision transformers for interpretable image recognition. In: IJCAI. pp. 1516–1524 (2024),https://www.ijcai.org/ proceedings/2024/168 vMF Mixture Prototypes 17
2024
-
[26]
Zhu, Z., Fan, L., Pagnucco, M., Song, Y.: Interpretable image classification via non- parametric part prototype learning. In: IEEE Conf. Comput. Vis. Pattern Recog. (2025),https : / / openaccess . thecvf . com / content / CVPR2025 / papers / Zhu _ Interpretable_Image_Classification_via_Non-parametric_Part_Prototype_ Learning_CVPR_2025_paper.pdf 18 D. Leão...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.