Ko-WideSearch: A Korean Breadth-Search Benchmark for Exhaustive Set Enumeration by Web Agents
Pith reviewed 2026-06-29 01:19 UTC · model grok-4.3
The pith
Web agents recover sets but fail to fill most rows in exhaustive tables on a new Korean benchmark
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
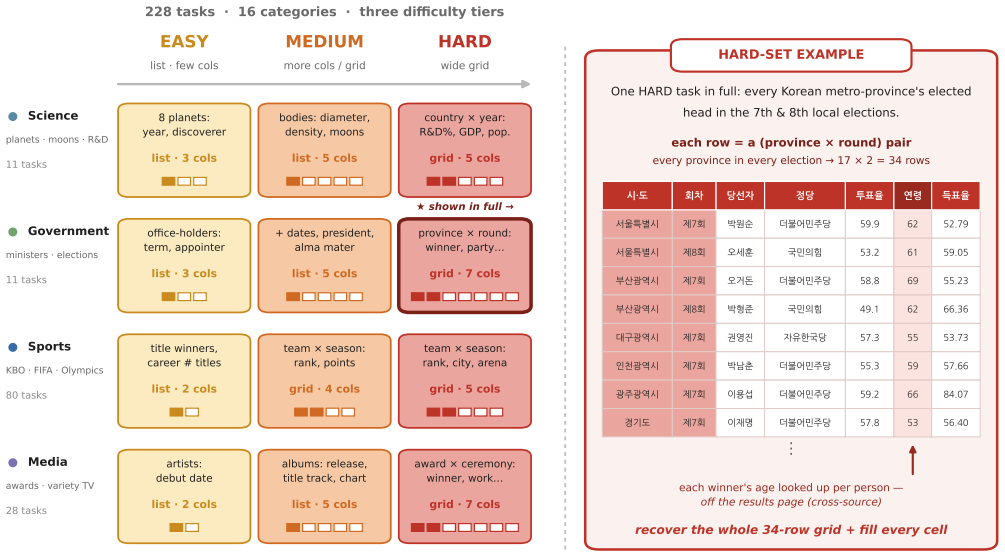
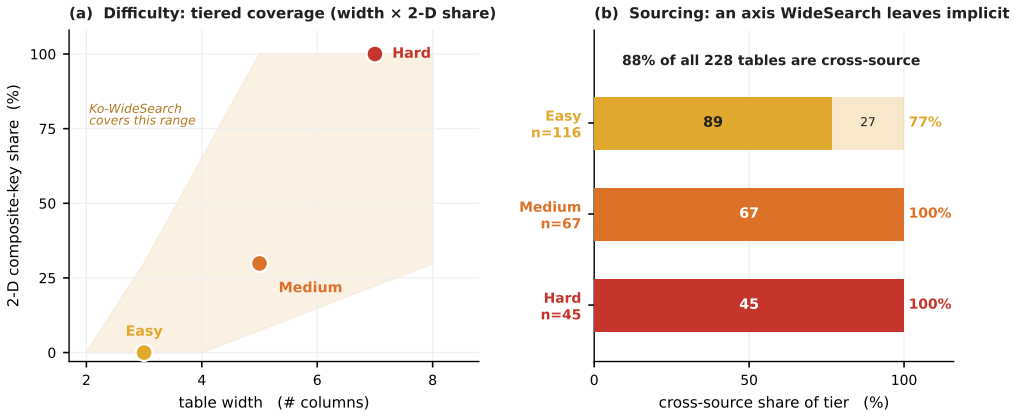
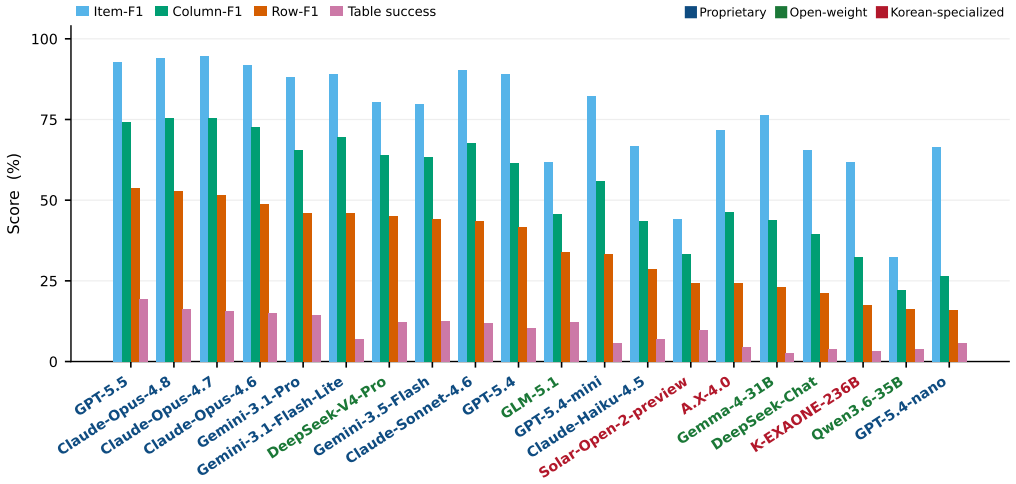
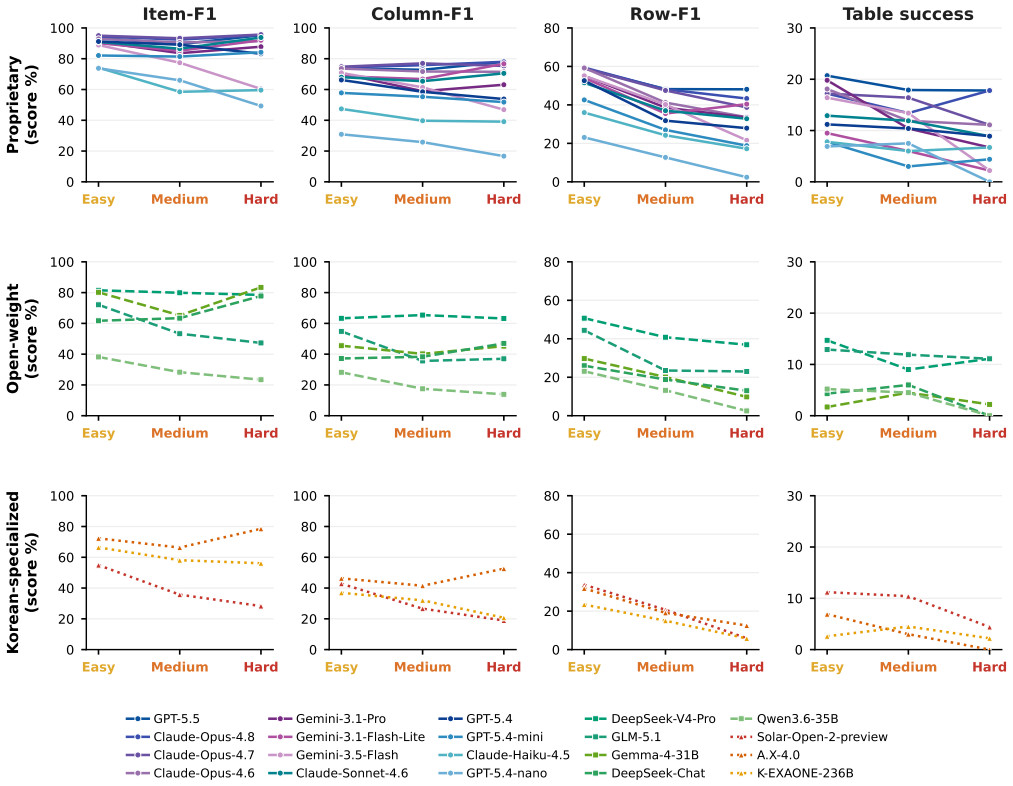
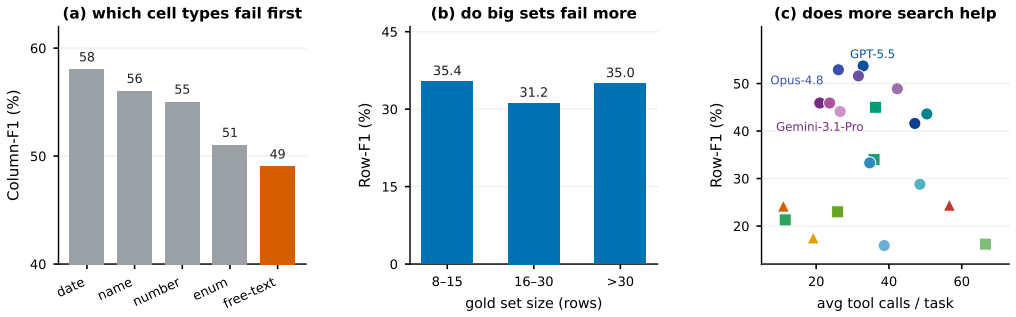
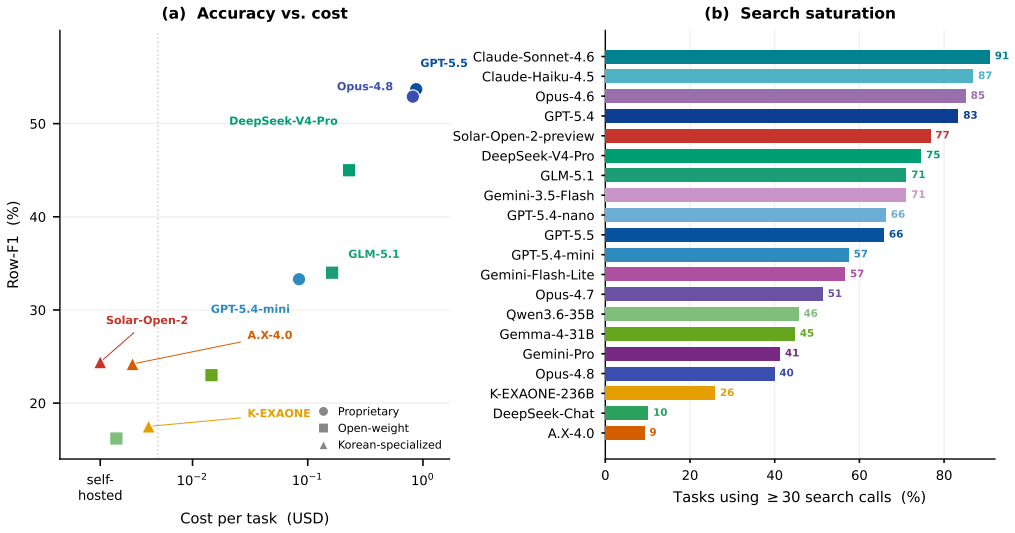
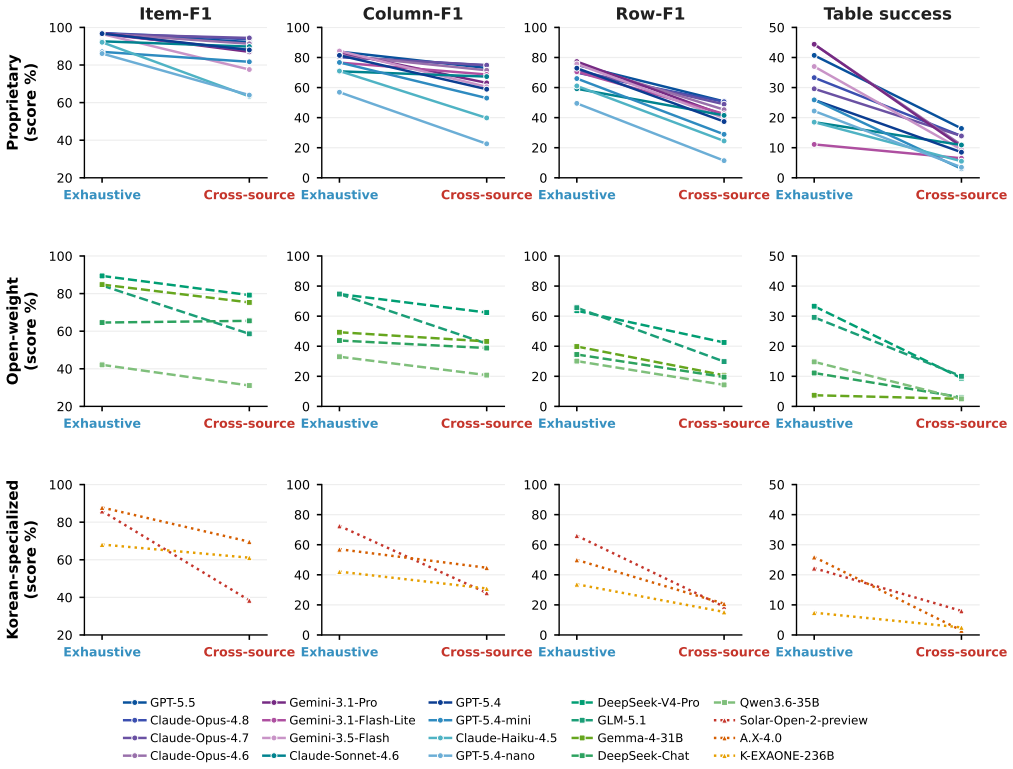
Ko-WideSearch shows that web agents recover set membership but not the rows of the associated attribute table. Across 228 tables the gap appears as Item-F1 of 92.8 against Row-F1 of 53.7; accuracy falls steadily as table width and composite-key complexity increase from 0 percent to 100 percent cross-product membership, and neither additional search nor higher spend narrows the gap. The dominant error is locating the correct value, not formatting it once found.
What carries the argument
The Ko-WideSearch benchmark and its automated synthesize-and-verify pipeline that produces complete gold tables for set-parent entities and grades answers with a shared normalization-aware comparator using Item-, Column-, and Row-F1.
If this is right
- Agents achieve high Item-F1 but substantially lower Row-F1 on the same tasks.
- Accuracy declines steadily as table width and 2-D composite key complexity increase.
- Extra search effort or higher spend produces no measurable improvement on these breadth tasks.
- Open-ended free-text cells fail far more often than cells with standard formats such as dates or names.
Where Pith is reading between the lines
- Future agent designs may need explicit mechanisms for systematic cross-source verification to close the set-versus-row gap.
- The Korean-language setting could expose language-specific enumeration difficulties that English-only benchmarks miss.
- The same structural knobs could be applied to other languages or domains to test whether the observed failure pattern generalizes.
Load-bearing premise
The automated synthesize-and-verify pipeline produces gold sets that are both complete and every cell correct.
What would settle it
A manual audit that finds missing members or incorrect cells in a sample of the generated gold tables would show the benchmark cannot be trusted.
Figures

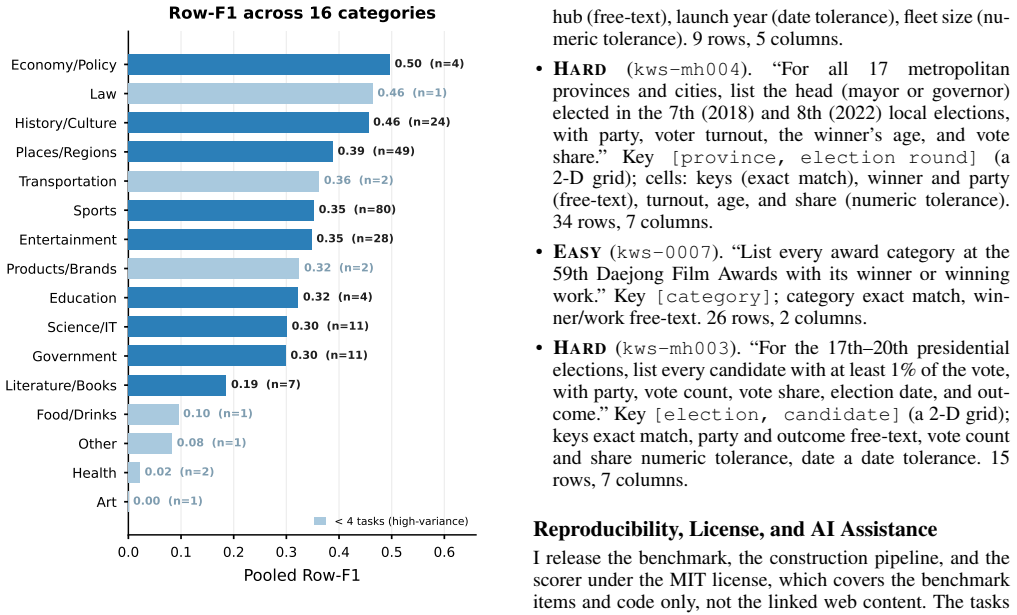
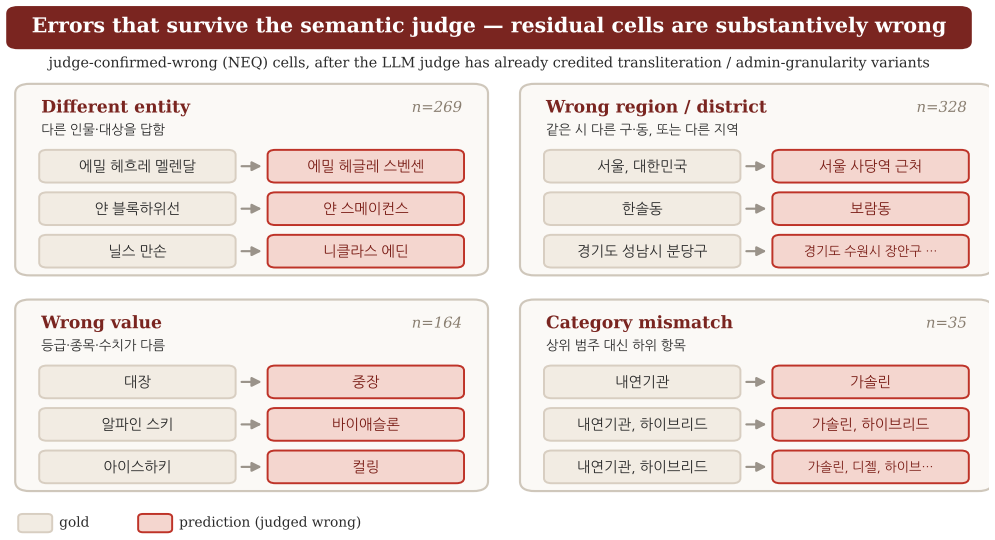
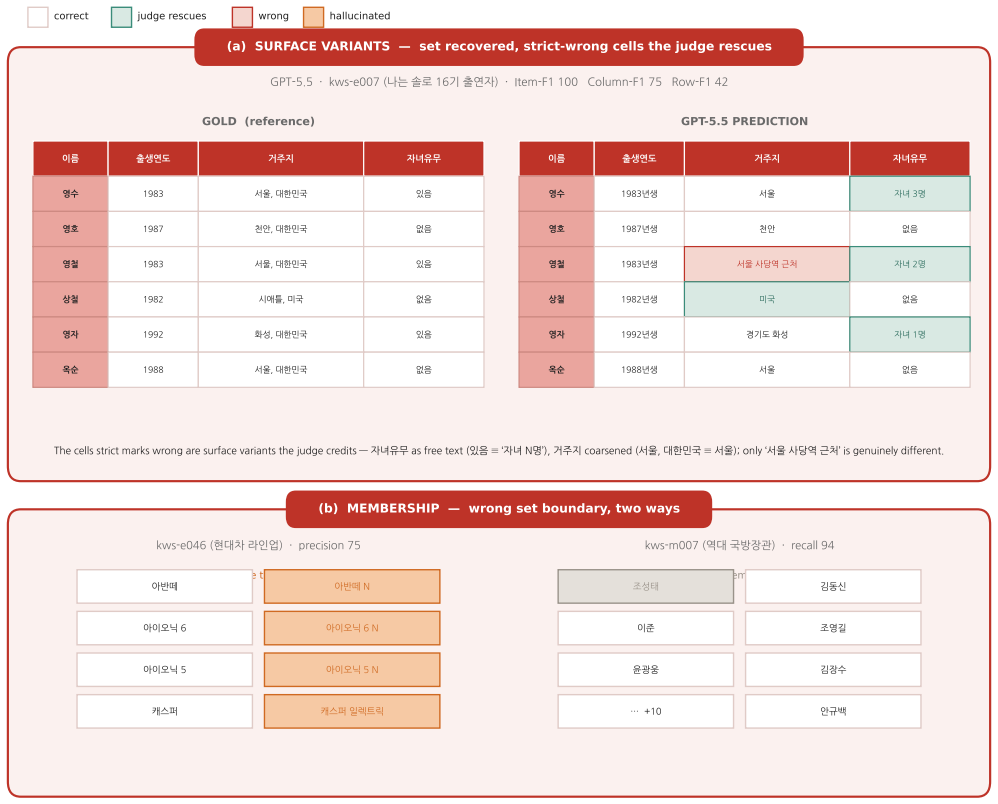
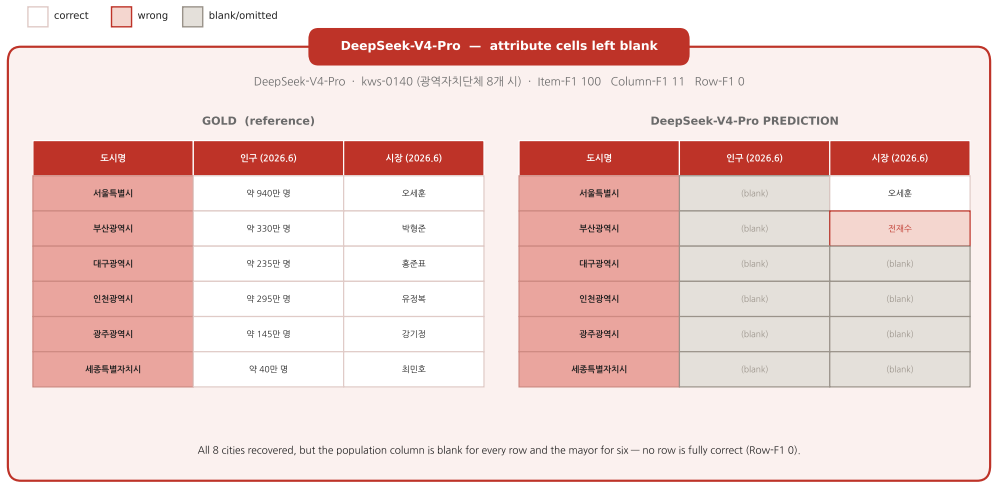

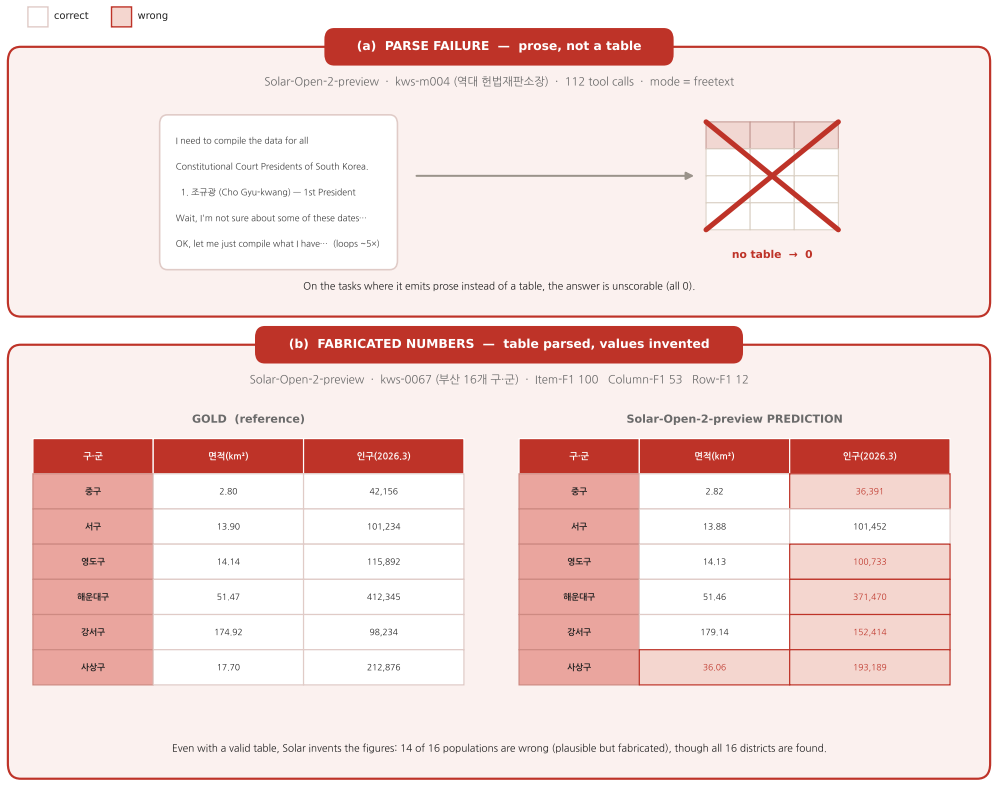

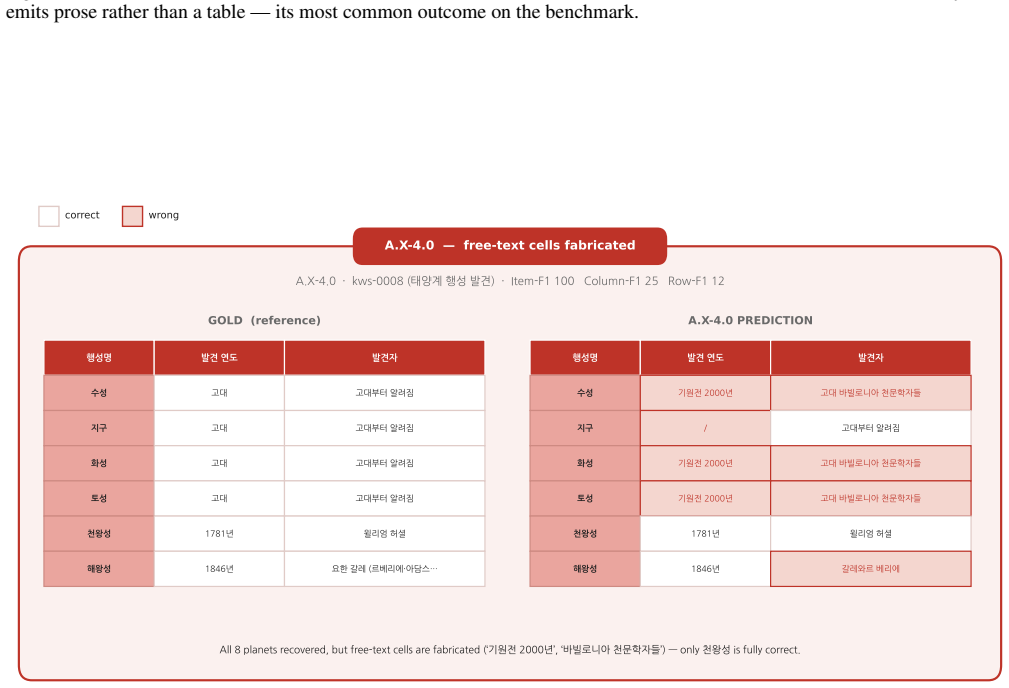
read the original abstract
Web-agent benchmarks overwhelmingly measure depth -- pinning one obscure answer behind a chain of constraints -- while breadth, exhaustively enumerating a closed set and filling each item's attributes, is barely evaluated, especially outside English. Breadth is also hard to build: certifying that a gold set is complete and every cell correct is far costlier than checking a single answer. I introduce \textsc{Ko-WideSearch}, a Korean breadth-search benchmark built by an automated synthesize-and-verify pipeline. Each task names a set-parent entity -- a TV season, a dynasty, a league, an administrative region, an election -- and asks for its full membership plus a per-item attribute table, graded by Item-, Column-, and Row-F1. It spans 228 tables over 190 entities and sixteen categories across three difficulty tiers, set by two structural knobs I dial independently -- table width and a 2-D composite key -- so cross-product membership climbs from 0\% to 100\% across the tiers. A single normalization-aware comparator is shared between gold construction and grading, so stable date and count columns are not over-dropped on formatting alone. Across twenty web agents, the failure is consistent: agents recover the set but not the rows (e.g.\ Item-F1 92.8 against Row-F1 53.7), accuracy falls steadily as the knobs harden, and neither more search nor more spend closes the gap. Broken down by cell, the hard part is finding the right value, not formatting it: open-ended free-text cells fail most, while cells with a standard answer such as a date or a name usually come out right.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ko-WideSearch, a Korean-language benchmark for web-agent breadth search consisting of 228 tables over 190 entities in 16 categories. Tasks require exhaustive enumeration of a set-parent entity plus per-item attribute tables, graded by Item-F1, Column-F1, and Row-F1. Gold tables are produced by an automated synthesize-and-verify pipeline that shares a normalization-aware comparator with the evaluation metric. Two independent structural knobs (table width and 2-D composite-key cardinality) create three difficulty tiers. Evaluation of 20 web agents shows high Item-F1 (92.8) but low Row-F1 (53.7), monotonic degradation with knob settings, and no recovery from increased search budget or spend; the dominant failure mode is value retrieval rather than formatting.
Significance. If the gold tables are verifiably complete and cell-correct, the benchmark would usefully document a systematic limitation of current web agents on exhaustive multi-row collection tasks outside English and would supply controllable structural difficulty axes for future work. The shared normalization comparator is a methodological strength that prevents spurious penalties on stable columns.
major comments (1)
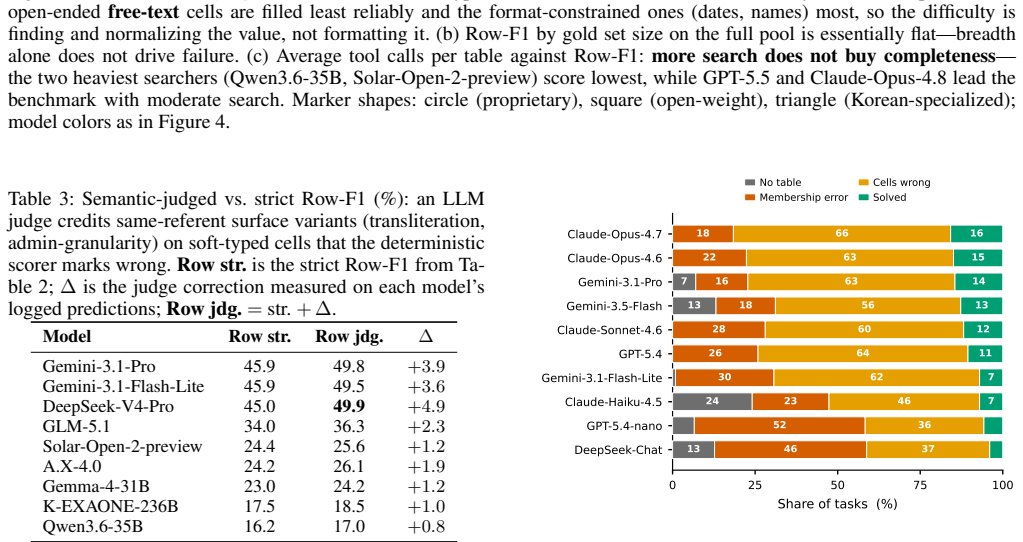
- [Abstract] Abstract (pipeline description): the central claim that agents recover sets but not rows (Item-F1 92.8 vs Row-F1 53.7) is interpretable only if the 228 gold tables are both complete and every cell correct. The automated synthesize-and-verify pipeline is described only at the level of a “normalization-aware comparator”; no human audit rate, no estimated error rate on the final gold, and no ablation of F1 sensitivity to plausible gold errors (especially free-text columns) are supplied. Because Row-F1 penalizes any cell mismatch, modest gold errors concentrated in open-ended cells would directly reproduce the reported gap without any agent failure.
minor comments (2)
- [Abstract] Abstract: the phrase “sixteen categories across three difficulty tiers” is stated without enumeration or cross-reference; a short table or list in the methods section would improve traceability.
- [Abstract] Abstract: the two structural knobs are introduced as “table width and a 2-D composite key” but their exact operationalization (e.g., how composite-key cardinality is counted) is not defined at first mention; a brief parenthetical or forward reference would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the gold-table validation. The concern is valid: without explicit human-audit statistics or sensitivity analysis, readers cannot independently confirm that the reported Item-F1 / Row-F1 gap reflects agent limitations rather than undetected gold errors. We will address this directly in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (pipeline description): the central claim that agents recover sets but not rows (Item-F1 92.8 vs Row-F1 53.7) is interpretable only if the 228 gold tables are both complete and every cell correct. The automated synthesize-and-verify pipeline is described only at the level of a “normalization-aware comparator”; no human audit rate, no estimated error rate on the final gold, and no ablation of F1 sensitivity to plausible gold errors (especially free-text columns) are supplied. Because Row-F1 penalizes any cell mismatch, modest gold errors concentrated in open-ended cells would directly reproduce the reported gap without any agent failure.
Authors: We agree that the interpretability of the central claim rests on the reliability of the gold tables. The current manuscript describes the pipeline only at the level of the shared normalization-aware comparator. In the revised version we will (1) expand the Methods section with a detailed account of the synthesize-and-verify steps, (2) report the human audit rate and any inter-annotator agreement figures obtained during verification, (3) provide an estimated upper bound on residual error rates (particularly for free-text columns), and (4) include a sensitivity ablation that injects controlled plausible errors into the gold tables and measures the resulting change in Item-F1, Column-F1, and Row-F1. These additions will allow readers to quantify how much of the observed gap could plausibly be explained by gold-table noise. revision: yes
Circularity Check
No circularity: benchmark construction with external measurements
full rationale
The paper constructs a Korean web-agent benchmark via an automated synthesize-and-verify pipeline and reports Item-F1/Row-F1 gaps across agents. No derivation chain, equations, fitted parameters, or self-citations are present; the central claims rest on external agent runs and the pipeline's output, which the paper itself flags as costly to certify. This matches the default case of a self-contained benchmark paper with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The synthesize-and-verify pipeline produces complete and cell-correct gold tables for all 190 entities
Reference graph
Works this paper leans on
-
[1]
J.; Wolfson, T.; Rubin, O.; Yoran, O.; Herzig, J.; and Berant, J
Amouyal, S. J.; Wolfson, T.; Rubin, O.; Yoran, O.; Herzig, J.; and Berant, J. 2023. QAMPARI: An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs. arXiv:2205.12665
-
[2]
Asai, A.; Wu, Z.; Wang, Y.; Sil, A.; and Hajishirzi, H. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. ICLR
2024
-
[3]
CAIS; and Scale AI. 2025. Humanity's Last Exam. arXiv:2501.14249
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Chen, W.; Zha, H.; Chen, Z.; Xiong, W.; Wang, H.; and Wang, W. Y. 2020. HybridQA: A Dataset of Multi-Hop Question Answering over Tabular and Textual Data. EMNLP Findings
2020
-
[5]
Chen, W.; Wang, H.; Chen, J.; Zhang, Y.; Wang, H.; Li, S.; Zhou, X.; and Wang, W. Y. 2020. TabFact: A Large-scale Dataset for Table-based Fact Verification. ICLR
2020
-
[6]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Deng, X.; Gu, Y.; Zheng, B.; Chen, S.; Stevens, S.; Wang, B.; Sun, H.; and Su, Y. 2023. Mind2Web: Towards a Generalist Agent for the Web. NeurIPS
2023
-
[8]
Ding, N.; Chen, Y.; Xu, B.; Qin, Y.; Zheng, Z.; Hu, S.; Liu, Z.; Sun, M.; and Zhou, B. 2023. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. EMNLP
2023
-
[9]
Dong, Y.; Jiang, X.; Liu, H.; Jin, Z.; Gu, B.; Yang, M.; and Li, G. 2024. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for LLMs. ACL Findings
2024
-
[10]
Gemini Team. 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Golchin, S.; and Surdeanu, M. 2024. Time Travel in LLMs: Tracing Data Contamination in Large Language Models. ICLR
2024
-
[12]
He, H.; Yao, W.; Ma, K.; Yu, W.; Dai, Y.; Zhang, H.; Lan, Z.; and Yu, D. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. ACL
2024
-
[13]
Ho, X.; Duong Nguyen, A.-K.; Sugawara, S.; and Aizawa, A. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. COLING
2020
- [14]
-
[15]
S.; and Davis, E
Jang, M.; Kim, D.; Kwon, D. S.; and Davis, E. 2022. KoBEST: Korean Balanced Evaluation of Significant Tasks. COLING
2022
-
[16]
Jin, J.; Kim, J.; Lee, N.; Yoo, H.; Oh, A.; and Lee, H. 2024. KoBBQ: Korean Bias Benchmark for Question Answering. TACL
2024
-
[17]
Joshi, M.; Choi, E.; Weld, D.; and Zettlemoyer, L. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. ACL
2017
- [18]
-
[19]
H.; Park, S.; Kim, S.; Kim, S.; Seo, D.; Lee, H.; Jeong, M.; Lee, S.; Kim, M.; Ko, S
Kim, B.; Kim, H.; Lee, S.-W.; Lee, G.; Kwak, D.; Jeon, D. H.; Park, S.; Kim, S.; Kim, S.; Seo, D.; Lee, H.; Jeong, M.; Lee, S.; Kim, M.; Ko, S. H.; Kim, S.; Park, T.; Kim, J.; Kang, S.; Ryu, N.-H.; Yoo, K. M.; Chang, M.; Suh, S.; In, S.; Park, J.; Kim, K.; Kim, H.; Jeong, J.; Yeo, Y. G.; Ham, D.; Park, D.; Lee, M. Y.; Kang, J.; Kang, I.; Ha, J.-W.; Park, ...
2021
-
[20]
Kim, E.; Suk, J.; Oh, P.; Yoo, H.; Thorne, J.; and Oh, A. 2024. CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean. LREC-COLING
2024
-
[21]
Kim, S.; Kim, D.; Park, C.; Lee, W.; Song, W.; Kim, Y.; Kim, H.; Kim, Y.; Lee, H.; Kim, J.; Ahn, C.; Yang, S.; Lee, S.; Park, H.; Gim, G.; Cha, M.; Lee, H.; and Kim, S. 2024. SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling. NAACL
2024
- [22]
-
[23]
M.; Uszkoreit, J.; Le, Q.; and Petrov, S
Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; Toutanova, K.; Jones, L.; Kelcey, M.; Chang, M.-W.; Dai, A. M.; Uszkoreit, J.; Le, Q.; and Petrov, S. 2019. Natural Questions: A Benchmark for Question Answering Research. TACL
2019
-
[24]
Lee, N.; Yoon, D.; Son, G.; Kim, G.; Ko, D.; Park, J.; Yoo, H.; Cho, J.; Park, J.; Lee, C.; Jang, K.; Kim, J.; Kim, E.; Cho, W.; and Kim, S. 2026. K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts. arXiv:2606.02404
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt\
Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; K\" u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt\" a schel, T.; Riedel, S.; and Kiela, D. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS
2020
- [26]
-
[27]
Li, X.; Dong, G.; Jin, J.; Zhang, Y.; Zhou, Y.; Zhu, Y.; Zhang, P.; and Dou, Z. 2025. Search-o1: Agentic Search-Enhanced Large Reasoning Models. arXiv:2501.05366
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
-
[29]
Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; and Zhu, C. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. EMNLP
2023
-
[30]
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; Zhang, S.; Deng, X.; Zeng, A.; Du, Z.; Zhang, C.; Shen, S.; Zhang, T.; Su, Y.; Sun, H.; Huang, M.; Dong, Y.; and Tang, J. 2024. AgentBench: Evaluating LLMs as Agents. ICLR
2024
-
[31]
Llama Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Mialon, G.; Fourrier, C.; Swift, C.; Wolf, T.; LeCun, Y.; and Scialom, T. 2023. GAIA: A Benchmark for General AI Assistants. arXiv:2311.12983
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Mukherjee, S.; Mitra, A.; Jawahar, G.; Agarwal, S.; Palangi, H.; and Awadallah, A. 2023. Orca: Progressive Learning from Complex Explanation Traces of GPT-4. arXiv:2306.02707
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Nakano, R.; Hilton, J.; Balaji, S.; Wu, J.; Ouyang, L.; Kim, C.; Hesse, C.; Jain, S.; Kosaraju, V.; Saunders, W.; Jiang, X.; Cobbe, K.; Eloundou, T.; Krueger, G.; Button, K.; Knight, M.; Chess, B.; and Schulman, J. 2021. WebGPT: Browser-assisted Question-answering with Human Feedback. arXiv:2112.09332
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
V.; Verma, N.; Zhang, R.; Kry\' s ci\' n ski, W.; Schoelkopf, H.; Kong, R.; Tang, X.; Mutuma, M.; Rosand, B.; Trindade, I.; Bandaru, R.; Cunningham, J.; Xiong, C.; and Radev, D
Nan, L.; Hsieh, C.; Mao, Z.; Lin, X. V.; Verma, N.; Zhang, R.; Kry\' s ci\' n ski, W.; Schoelkopf, H.; Kong, R.; Tang, X.; Mutuma, M.; Rosand, B.; Trindade, I.; Bandaru, R.; Cunningham, J.; Xiong, C.; and Radev, D. 2022. FeTaQA: Free-form Table Question Answering. TACL
2022
-
[36]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Oren, Y.; Meister, N.; Chatterji, N.; Ladhak, F.; and Hashimoto, T. B. 2024. Proving Test Set Contamination in Black Box Language Models. ICLR
2024
-
[38]
Park, S.; Moon, J.; Kim, S.; Cho, W. I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T.; Lee, J.; Oh, J.; Lyu, S.; Jeong, Y.; Lee, I.; Seo, S.; Lee, D.; Kim, H.; Lee, M.; Jang, S.; Do, S.; Kim, S.; Lim, K.; Lee, J.; Park, K.; Shin, J.; Kim, S.; Park, L.; Oh, A.; Ha, J.-W.; and Cho, K. 2021. KLUE: Korean Language Understanding Evaluation. arXiv:2105.09680
-
[39]
Pasupat, P.; and Liang, P. 2015. Compositional Semantic Parsing on Semi-Structured Tables. ACL
2015
-
[40]
G.; Zhang, T.; Wang, X.; and Gonzalez, J
Patil, S. G.; Zhang, T.; Wang, X.; and Gonzalez, J. E. 2024. Gorilla: Large Language Model Connected with Massive APIs. NeurIPS
2024
-
[41]
Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; Zhao, S.; Hong, L.; Tian, R.; Xie, R.; Zhou, J.; Gerstein, M.; Li, D.; Liu, Z.; and Sun, M. 2024. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. ICLR
2024
-
[42]
Qwen Team. 2024. Qwen2.5 Technical Report. arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
H.; Singh, S.; Maheshwary, R.; Altomare, M.; Haggag, M
Romanou, A.; Foroutan, N.; Sotnikova, A.; Chen, Z.; Nelaturu, S. H.; Singh, S.; Maheshwary, R.; Altomare, M.; Haggag, M. A.; A, S.; Amayuelas, A.; Amirudin, A. H.; Aryabumi, V.; Boiko, D.; Chang, M.; Chim, J.; Cohen, G.; Dalmia, A. K.; Diress, A.; Duwal, S.; Dzenhaliou, D.; Erazo Florez, D. F.; Farestam, F.; Imperial, J. M.; Islam, S. B.; Isotalo, P.; Jab...
2025
-
[44]
Sainz, O.; Campos, J.; Garc\' i a-Ferrero, I.; Etxaniz, J.; Lopez de Lacalle, O.; and Agirre, E. 2023. NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for each Benchmark. EMNLP Findings
2023
-
[45]
Schick, T.; Dwivedi-Yu, J.; Dess\` i , R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; and Scialom, T. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. NeurIPS
2023
-
[46]
C.; Yeom, J
Son, G.; Lee, H.; Kim, S.; Kim, H.; Lee, J. C.; Yeom, J. W.; Jung, J.; Kim, J. W.; and Kim, S. 2024. HAE-RAE Bench: Evaluation of Korean Knowledge in Language Models. LREC-COLING
2024
-
[47]
M.; and Biderman, S
Son, G.; Lee, H.; Kim, S.; Kim, S.; Muennighoff, N.; Choi, T.; Park, C.; Yoo, K. M.; and Biderman, S. 2025. KMMLU: Measuring Massive Multitask Language Understanding in Korean. NAACL
2025
-
[48]
arXiv preprint arXiv:2602.12413 , year=
Spiesberger, A.; Vazquez, J. J.; Pochinkov, N.; Gaven c iak, T.; Grietzer, P.; Leech, G.; and Schoots, N. 2026. Soft Contamination Means Benchmarks Test Shallow Generalization. arXiv:2602.12413
-
[49]
Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A. 2022. MuSiQue: Multihop Questions via Single-hop Question Composition. TACL
2022
-
[50]
Vu, T.; Iyyer, M.; Wang, X.; Constant, N.; Wei, J.; Wei, J.; Tar, C.; Sung, Y.-H.; Zhou, D.; Le, Q.; and Luong, T. 2024. FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation. ACL Findings
2024
-
[51]
A.; Khashabi, D.; and Hajishirzi, H
Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N. A.; Khashabi, D.; and Hajishirzi, H. 2023. Self-Instruct: Aligning Language Models with Self-Generated Instructions. ACL
2023
-
[52]
Measuring short-form factuality in large language models
Wei, J.; Karina, N.; Chung, H. W.; Jiao, Y. J.; Papay, S.; Glaese, A.; Schulman, J.; and Fedus, W. 2024. Measuring Short-form Factuality in Large Language Models. arXiv:2411.04368
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Wei, J.; Sun, Z.; Papay, S.; McKinney, S.; Han, J.; Fulford, I.; Chung, H. W.; Passos, A. T.; Fedus, W.; and Glaese, A. 2025. BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents. arXiv:2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [54]
- [55]
-
[56]
Xu, Z.; Jiang, F.; Niu, L.; Deng, Y.; Poovendran, R.; Choi, Y.; and Lin, B. Y. 2024. Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing. arXiv:2406.08464
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Xu, C.; Sun, Q.; Zheng, K.; Geng, X.; Zhao, P.; Feng, J.; Tao, C.; Lin, Q.; and Jiang, D. 2024. WizardLM: Empowering Large Pre-trained Language Models to Follow Complex Instructions. ICLR
2024
-
[58]
Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.; Salakhutdinov, R.; and Manning, C. D. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. EMNLP
2018
-
[59]
Yao, S.; Chen, H.; Yang, J.; and Narasimhan, K. 2022. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. NeurIPS
2022
-
[60]
Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; and Cao, Y. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR
2023
-
[61]
J.; Malaviya, C.; Bogin, B.; Press, O.; and Berant, J
Yoran, O.; Amouyal, S. J.; Malaviya, C.; Bogin, B.; Press, O.; and Berant, J. 2024. AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks? EMNLP
2024
-
[62]
P.; Zhang, H.; Gonzalez, J
Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E. P.; Zhang, H.; Gonzalez, J. E.; and Stoica, I. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS
2023
-
[63]
F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; Alon, U.; and Neubig, G
Zhou, S.; Xu, F. F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; Alon, U.; and Neubig, G. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. ICLR
2024
-
[64]
Zhou, P.; Leon, B.; Ying, X.; Zhang, C.; Shao, Y.; Ye, Q.; Chong, D.; Jin, Z.; Xie, C.; Cao, M.; Gu, Y.; Hong, S.; Ren, J.; Chen, J.; Liu, C.; and Hua, Y. 2025. BrowseComp-ZH: Benchmarking Web Browsing Ability of LLMs in Chinese. arXiv:2504.19314
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.