Global Explanations for Multivariate Time Series Forecasting Models via K-Order Markov Approximations
Pith reviewed 2026-06-29 01:16 UTC · model grok-4.3
The pith
KARMA explains time series forecasting models by building K-order Markov surrogates that recover their learned temporal dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
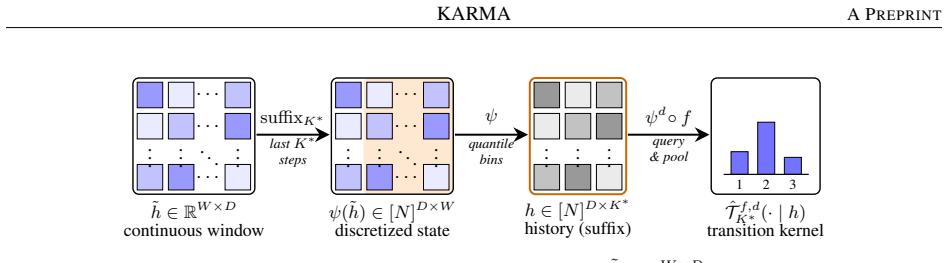
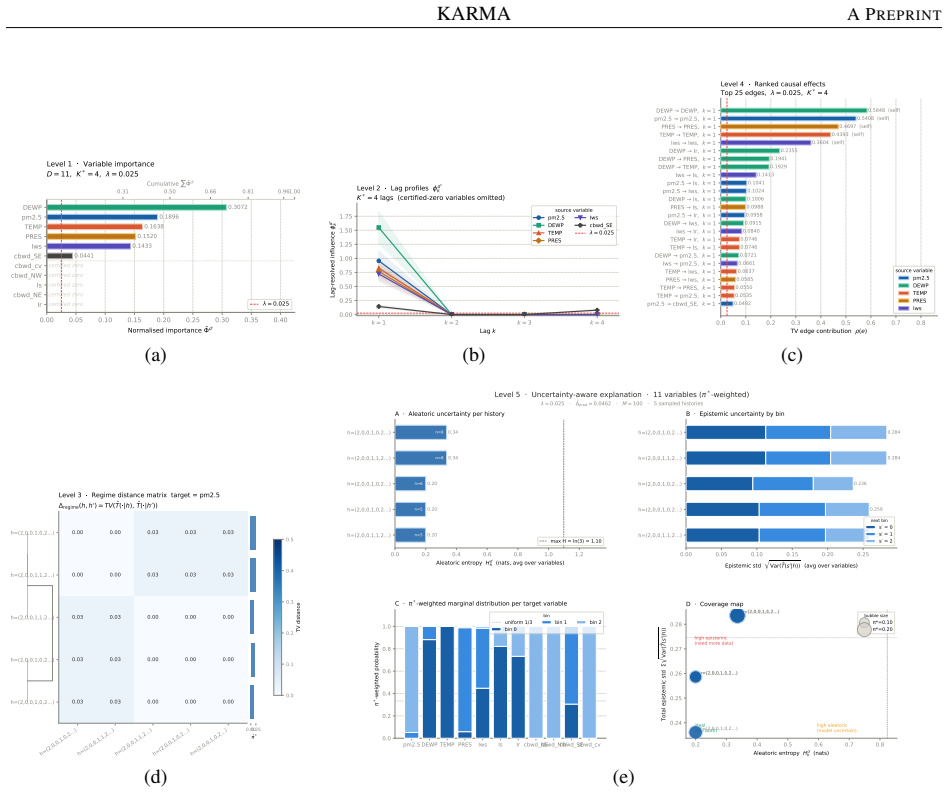
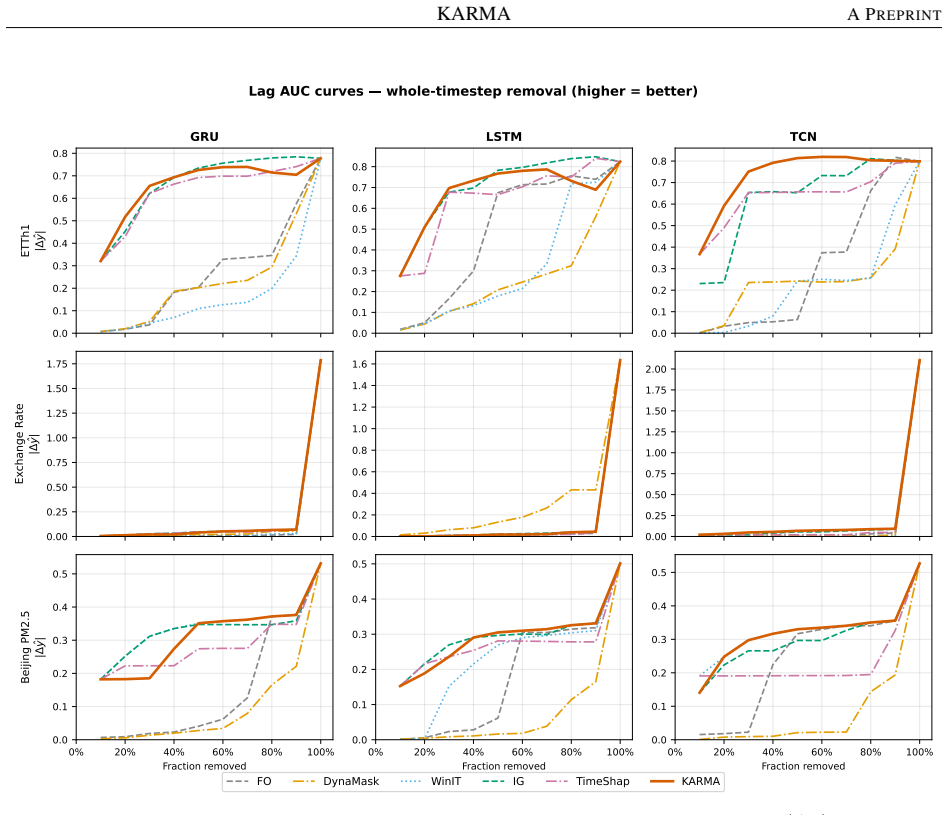
KARMA constructs a Markov surrogate model that captures the temporal dependencies learned by the time-series predictor. The approach identifies the minimal history length K that is predictively sufficient for the model, estimates the best-fitting K-order Markov transition kernel from the discretized history space, and derives a five-level global explanation hierarchy from the kernel. On complex synthetic data with known true causal edges, the method recovers the causal structure learned by the model and identifies temporal dependencies better than established attribution methods such as TimeSHAP.
What carries the argument
The K-order Markov transition kernel estimated from the discretized history space, which serves as the surrogate that encodes the temporal dependencies of the original forecasting model.
If this is right
- The fitted kernel recovers the causal structure that the original model learned on synthetic data with known edges.
- KARMA identifies temporal dependencies more accurately than TimeSHAP on the same synthetic benchmarks.
- A five-level global explanation hierarchy can be read directly from the Markov transition kernel.
- The same pipeline produces usable explanations on real multivariate series such as Beijing PM 2.5 weather observations.
Where Pith is reading between the lines
- The discretization step required to build the kernel may make explanations sensitive to the choice of bins; testing robustness across bin widths would be a direct next measurement.
- Because the surrogate is itself a probabilistic model, it could be used to generate synthetic trajectories that preserve the explanations' causal claims.
- The minimal-K selection procedure might be adapted to detect non-stationarity by tracking how K changes across data windows.
Load-bearing premise
That the best-fitting K-order Markov transition kernel estimated from the discretized history space faithfully approximates the temporal dependencies learned by the original multivariate forecasting model.
What would settle it
A controlled experiment on synthetic data with known causal edges in which the edges recovered by KARMA from the fitted kernel differ from those the model actually learned, or in which KARMA's temporal-dependency rankings fall below those of TimeSHAP.
Figures

read the original abstract
While many explainable AI (XAI) methods have been proposed, most are not designed for time-series forecasting models and often rely on the implicit assumption that timestamp features are independent. This assumption ignores the fundamental property of temporal dependence and can lead to explanations that violate the sequential and causal structure of the data. We introduce \textsc{KARMA}, a method for explaining time-series predictors by constructing a Markov surrogate model that captures the temporal dependencies learned by the predictor. Our approach revolves around three main aspects: identifying the minimal history length $K$ that is predictively sufficient for the model, estimating the best-fitting $K$-order Markov transition kernel from the discretized history space, and a five-level global explanation hierarchy that can be derived from the Markov transition kernel, which we illustrate using real-world weather data (Beijing PM 2.5). We also certify using complex synthetic data with known true causal edges that KARMA (i) recovers the data causal structure as learned by the model via a controlled experiment and (ii) identifies temporal dependencies better than established attribution methods such as TimeSHAP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KARMA, a global explanation method for multivariate time-series forecasting models. It constructs a K-order Markov surrogate by (i) identifying the minimal history length K that is predictively sufficient, (ii) estimating the best-fitting transition kernel after discretizing the history space, and (iii) deriving a five-level explanation hierarchy from the kernel. The central empirical claim is that, on complex synthetic data with known causal edges, KARMA recovers the causal structure learned by the model and identifies temporal dependencies better than TimeSHAP; the method is also illustrated on Beijing PM 2.5 weather data.
Significance. If the Markov surrogate is shown to faithfully reproduce the original model's input-output behavior, the approach would supply a principled, model-agnostic route to global explanations that respect temporal dependence, addressing a documented limitation of many existing XAI techniques for time series. The provision of a controlled synthetic experiment with externally known causal edges is a positive feature that could support falsifiable claims.
major comments (2)
- [Abstract] Abstract (paragraph on the three main aspects and the certification claim): the controlled synthetic experiment is described only as recovering 'the data causal structure as learned by the model,' but supplies no quantitative metrics, error bars, or explicit comparison of the surrogate's forecasts versus the original model's outputs on held-out inputs. This leaves the load-bearing assumption—that the fitted K-order kernel approximates the model's learned mapping—unverified.
- [Abstract] Abstract (synthetic-data certification paragraph): the experiment verifies recovery of data-generating causal edges but does not demonstrate that the discretized Markov kernel's predictions coincide with the original forecasting model's predictions on the same raw histories. Because discretization bins continuous observations and the kernel optimizes marginal transition probabilities rather than matching the model's (possibly non-Markovian) function, the link between surrogate and model remains unestablished; this directly affects the claim that KARMA explains the model rather than the data.
minor comments (1)
- [Abstract] The abstract asserts superiority over TimeSHAP without reporting any numerical scores, statistical tests, or experimental protocol details; these should be supplied in the main text with precise definitions of the metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the abstract. We agree that greater quantitative detail and clarification of the surrogate-to-model link are warranted. We address each major comment below and will revise the abstract in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on the three main aspects and the certification claim): the controlled synthetic experiment is described only as recovering 'the data causal structure as learned by the model,' but supplies no quantitative metrics, error bars, or explicit comparison of the surrogate's forecasts versus the original model's outputs on held-out inputs. This leaves the load-bearing assumption—that the fitted K-order kernel approximates the model's learned mapping—unverified.
Authors: We agree that the abstract would be strengthened by including quantitative metrics, error bars, and any available fidelity comparisons. The experimental section of the manuscript reports metrics on causal-edge recovery and comparisons against TimeSHAP; we will revise the abstract to summarize these results concisely, including key performance numbers with uncertainty estimates. revision: yes
-
Referee: [Abstract] Abstract (synthetic-data certification paragraph): the experiment verifies recovery of data-generating causal edges but does not demonstrate that the discretized Markov kernel's predictions coincide with the original forecasting model's predictions on the same raw histories. Because discretization bins continuous observations and the kernel optimizes marginal transition probabilities rather than matching the model's (possibly non-Markovian) function, the link between surrogate and model remains unestablished; this directly affects the claim that KARMA explains the model rather than the data.
Authors: The minimal history length K is chosen by testing the forecasting model's own predictive performance; once K is fixed, additional history yields no improvement, indicating that the model has effectively learned a K-order dependence on the given data. The transition kernel is then estimated on the discretized histories to capture exactly those conditional distributions. We acknowledge that the abstract does not explicitly report held-out prediction agreement between the kernel and the original model, and that discretization is an approximation step. We will revise the abstract to articulate this selection procedure more clearly and will add a direct fidelity comparison (surrogate vs. model forecasts) if it can be computed from the existing experimental setup. revision: partial
Circularity Check
No significant circularity; external synthetic validation with known causal edges
full rationale
The paper's central certification step uses complex synthetic data with externally known true causal edges to verify recovery of causal structure as learned by the model. This constitutes independent benchmarking rather than a reduction of claims to quantities defined by the method's own fitted K-order Markov kernel or discretization. No self-definitional, fitted-input-called-prediction, or self-citation load-bearing patterns are identifiable from the abstract and description. The approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- minimal history length K
axioms (1)
- domain assumption A K-order Markov process on discretized histories can serve as a faithful surrogate for the learned temporal dependencies of the forecasting model.
Reference graph
Works this paper leans on
-
[1]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
2014
-
[2]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
2014
-
[3]
arXiv preprint arXiv:1804.09028 , year=
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
-
[4]
Bento and P
J. Bento and P. Saleiro and A. F. Cruz and M. A. T. Figueiredo and P. Bizarro , title =. Proceedings of KDD , year =
-
[5]
Cont , title =
R. Cont , title =. Quantitative Finance , volume =
-
[6]
Craven and J
M. Craven and J. Shavlik , title =. Proceedings of NeurIPS , year =
-
[7]
I. Csisz. The Consistency of the. Annals of Statistics , volume =
-
[8]
Clayton Rooke and Jonathan Smith and Kin Kwan Leung and Maksims Volkovs and Saba Zuberi , title =. CoRR , volume =. 2021 , url =. 2107.14317 , timestamp =
arXiv 2021
-
[9]
C. W. J. Granger , title =. Econometrica , volume =
-
[10]
Jain and B
S. Jain and B. C. Wallace , title =. Proceedings of NAACL , year =
-
[11]
S. M. Lundberg and S. I. Lee , title =. Proceedings of NeurIPS , year =
-
[12]
Nauta and others , title =
M. Nauta and others , title =. ACM Computing Surveys , volume =
-
[13]
Pamfil and others , title =
R. Pamfil and others , title =. Proceedings of AISTATS , year =
-
[14]
M. T. Ribeiro and S. Singh and C. Guestrin , title =. Proceedings of KDD , year =
-
[15]
Runge , title =
J. Runge , title =. Chaos , volume =
-
[16]
, title =
Tsybakov, Alexandre B. , title =. 2009 , doi =
2009
-
[17]
, title =
Pinsker, Mark S. , title =
-
[18]
Contrastive Counterfactual Visual Explanations With Overdetermination , journal =
Adam White and Kwun Ho Ngan and James Phelan and Saman Sadeghi Afgeh and Kevin Ryan and Constantino Carlos Reyes. Contrastive Counterfactual Visual Explanations With Overdetermination , journal =. 2021 , url =. 2106.14556 , timestamp =
arXiv 2021
-
[19]
W. C. Salmon , title =
-
[20]
Spirtes and C
P. Spirtes and C. Glymour and R. Scheines , title =
-
[21]
Annals of Mathematical Statistics , volume =
Dvoretzky, Aryeh and Kiefer, Jack and Wolfowitz, Jacob , title =. Annals of Mathematical Statistics , volume =. 1956 , doi =
1956
-
[22]
2025 , eprint=
Large Language Models as Markov Chains , author=. 2025 , eprint=
2025
-
[23]
Jagirdar, Hussain and Talwadker, Rukma and Pareek, Aditya and Agrawal, Pulkit and Mukherjee, Tridib , year=. Explainable and Interpretable Forecasts on Non-Smooth Multivariate Time Series for Responsible Gameplay , url=. doi:10.1145/3637528.3671657 , booktitle=
-
[24]
Q-MiniSAM2: A Quantization-based Benchmark for Resource-Efficient Video Segmentation , url=
Ren, Xuanxuan and Li, Xiangyu and Wei, Kun and Yang, Xu and Yang, Yanhua , year=. Q-MiniSAM2: A Quantization-based Benchmark for Resource-Efficient Video Segmentation , url=. doi:10.24963/ijcai.2024/204 , booktitle=
-
[25]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
1985
-
[26]
Proceedings of the 40th International Conference on Machine Learning , series =
Joseph Enguehard , title =. Proceedings of the 40th International Conference on Machine Learning , series =
-
[27]
Proceedings of the 38th International Conference on Machine Learning , series =
Jonathan Crabbé and Mihaela van der Schaar , title =. Proceedings of the 38th International Conference on Machine Learning , series =
-
[28]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
2001
-
[29]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[30]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
-
[31]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
2002
-
[32]
Levesque
Hector J. Levesque. Foundations of a functional approach to knowledge representation. Artificial Intelligence. 1984
1984
-
[33]
Levesque
Hector J. Levesque. A logic of implicit and explicit belief. Proceedings of the Fourth National Conference on Artificial Intelligence. 1984
1984
-
[34]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
2000
-
[35]
International Conference on Learning Representations (ICLR) Workshop , year =
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , author =. International Conference on Learning Representations (ICLR) Workshop , year =
-
[36]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages =
Axiomatic Attribution for Deep Networks , author =. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages =
-
[37]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization , author =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
-
[38]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages =
Learning Important Features Through Propagating Activation Differences , author =. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages =
-
[39]
PLOS ONE , volume =
On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation , author =. PLOS ONE , volume =
-
[40]
arXiv preprint arXiv:1706.03825 , year =
SmoothGrad: Removing Noise by Adding Noise , author =. arXiv preprint arXiv:1706.03825 , year =
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Benchmarking Deep Learning Interpretability in Time Series Predictions , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
What Went Wrong and When? Instance-Wise Feature Importance for Time-Series Black-Box Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[43]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Temporal Dependencies in Feature Importance for Time Series Prediction , author =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[44]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Explaining Time Series via Contrastive and Locally Sparse Perturbations , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Encoding Time-Series Explanations through Self-Supervised Model Behavior Consistency , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[46]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP) , pages =
Attention is not not Explanation , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP) , pages =
2019
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=
Assessing Beijing's PM2.5 pollution: severity, weather impact, APEC and winter heating , author=. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2015 , publisher=
2015
-
[49]
Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Modeling long-and short-term temporal patterns with deep neural networks , author=. Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[50]
International Journal of Forecasting , volume =
Temporal Fusion Transformers for Interpretable Multi-Horizon Time Series Forecasting , author =. International Journal of Forecasting , volume =
-
[51]
arXiv preprint arXiv:1705.08498 , year =
Clinical Intervention Prediction and Understanding using Deep Networks , author =. arXiv preprint arXiv:1705.08498 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.