CBD: API-Only LLM Black-Box Unlearning through Controlled Behavioral Divergence
Pith reviewed 2026-06-29 04:44 UTC · model grok-4.3
The pith
CBD enables API-only black-box LLM unlearning by routing prompts with behavioral divergence scores from a Fisher-matrix discriminative basis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
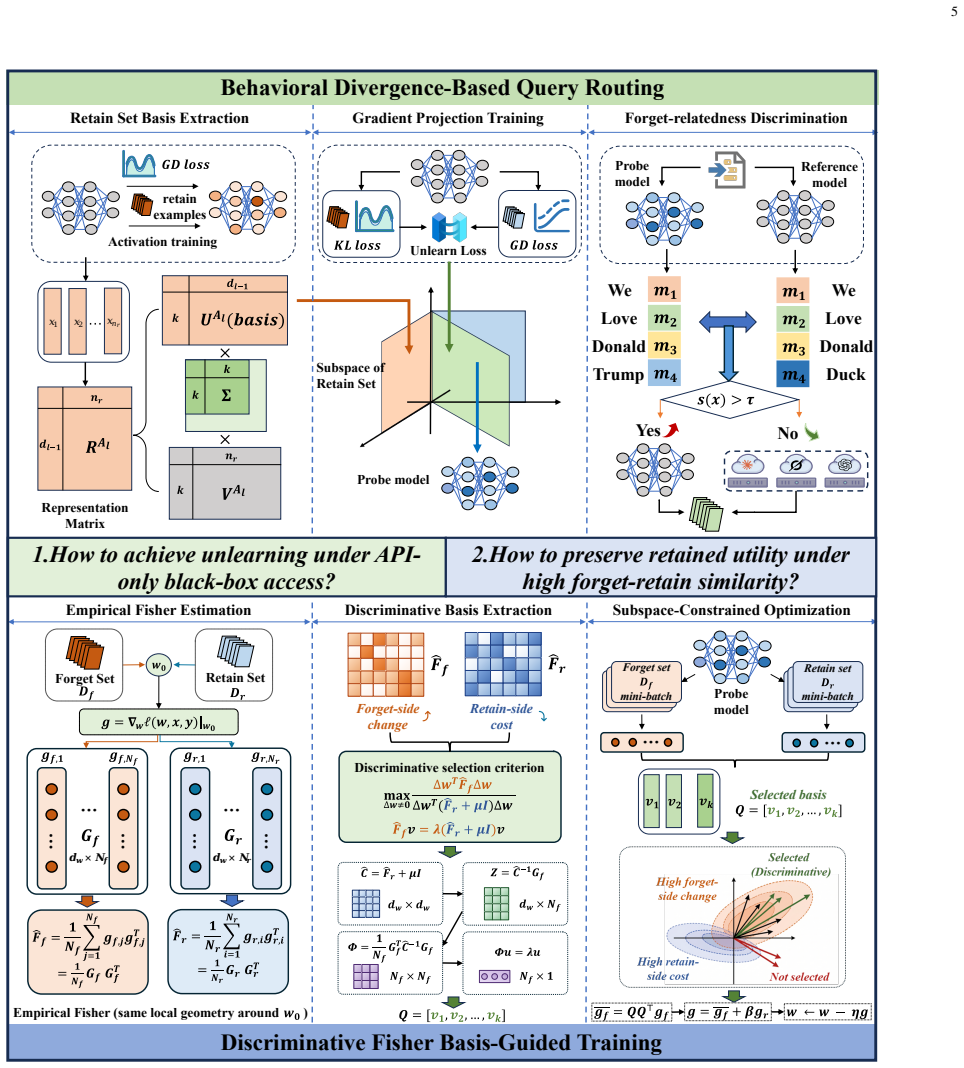
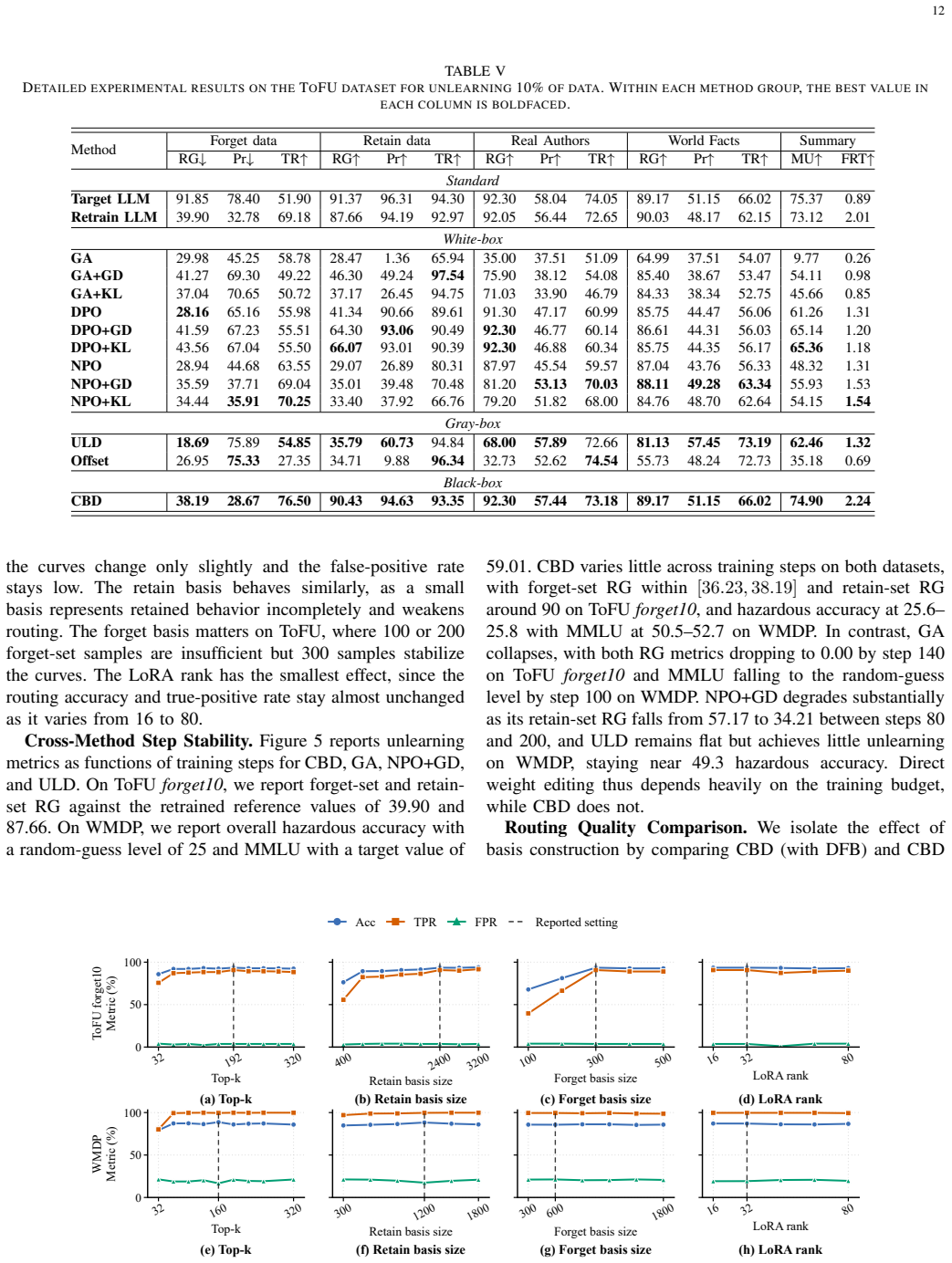
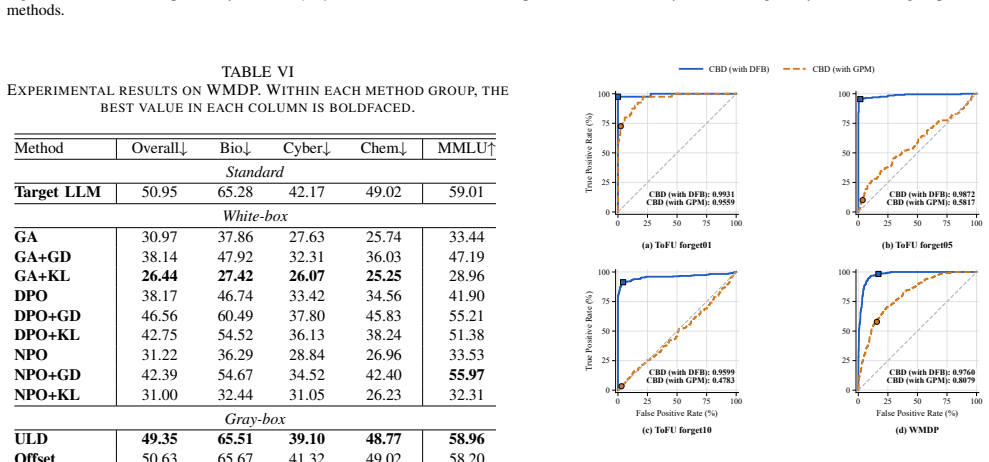
CBD uses two auxiliary models to produce controlled behavioral divergence between retained inputs and unlearning targets, derives an unlearning relevance score from that divergence, and routes related prompts away from the target LLM. When retained and target data are highly similar, it constructs a discriminative basis by estimating empirical Fisher matrices from API outputs and solving a regularized generalized eigenvalue problem to direct the signal toward target-specific information rather than shared structures. This yields performance approaching the retrained reference on the forget set while achieving 74.90 utility on ToFU forget10 (15 percent above the second-best baseline) and 25.6
What carries the argument
The discriminative basis obtained by estimating empirical Fisher matrices from API outputs and solving a regularized generalized eigenvalue problem; it isolates target-specific information within the behavioral divergence signal.
If this is right
- Approaches retrained reference performance on the forget set of ToFU forget10.
- Raises model utility to 74.90 on ToFU forget10, exceeding the second-best baseline by about 15 percent.
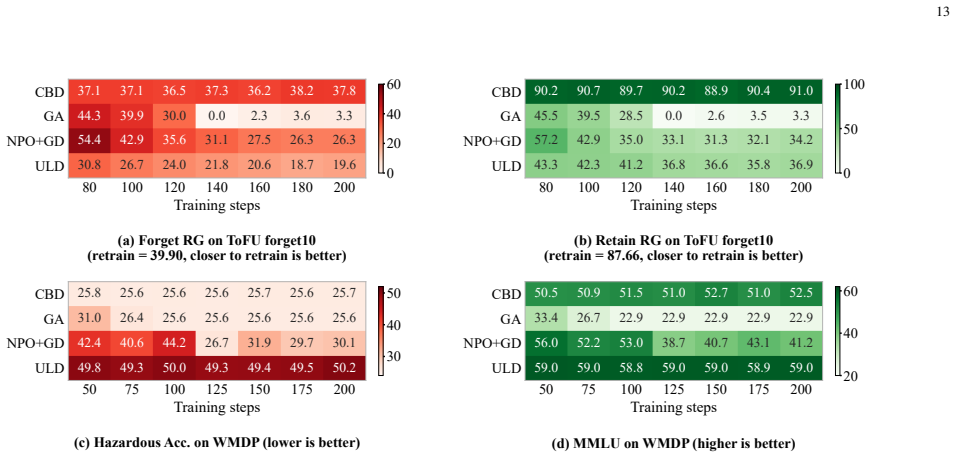
- Lowers hazardous knowledge accuracy to 25.68 on WMDP, near random guessing levels.
- Preserves MMLU accuracy at 52.67 during unlearning on WMDP.
- Shows little performance variation across settings compared with prior baselines.
Where Pith is reading between the lines
- The routing mechanism could allow removal of specific data influences from commercial LLM APIs without any provider-side cooperation or model access.
- The same Fisher-matrix basis construction might transfer to black-box unlearning tasks in non-language domains such as vision models.
- Further tests on data distributions with greater semantic overlap than ToFU or WMDP would clarify the practical boundary of the discrimination step.
- Edge-device scenarios that collect user data for later unlearning could adopt the auxiliary-model divergence step without needing local model copies.
Load-bearing premise
That estimating empirical Fisher matrices from API outputs and solving the regularized generalized eigenvalue problem produces a basis that isolates target-specific information rather than shared prompt structures when retained and unlearning data are highly similar.
What would settle it
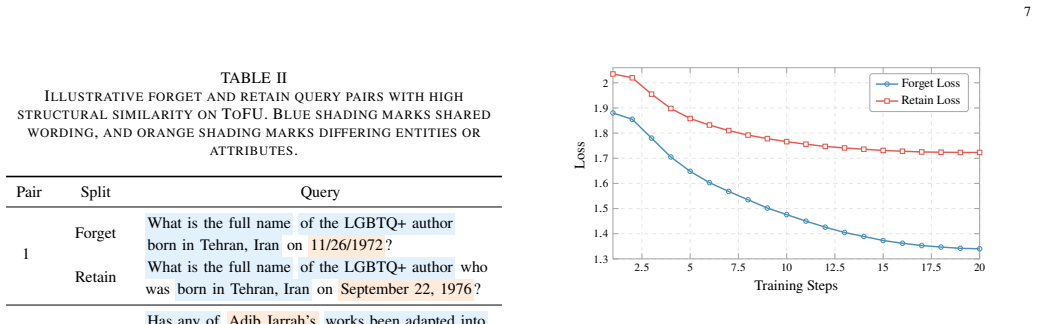
On a dataset with highly overlapping semantics between retained and target data, the method fails to bring forget-set metrics close to the retrained reference or drops retained utility below the second-best baseline.
Figures

read the original abstract
Edge devices increasingly invoke large language models (LLMs) through API services for context aware edge intelligence, while edge generated data may be collected to improve LLMs and may introduce sensitive, copyrighted, harmful, or outdated information into model behavior. Machine unlearning offers a practical way to remove the influence of undesired data without retraining LLMs. However, existing methods still face two gaps. The first is API only black box access, where target model parameters and internal logits are unavailable. The second is how to preserve retained utility when unlearning target data and retained data share highly similar prompt structures or semantic patterns. To address these challenges, we propose Controlled Behavioral Divergence (CBD), an API only black box unlearning framework. CBD uses two auxiliary models to create controlled behavioral divergence between retained inputs and unlearning target inputs, converts this divergence into an unlearning relevance score, and routes unlearning related prompts away from the target LLM. To improve discrimination accuracy under high similarity between target and retained data, CBD constructs a gradient statistics based discriminative basis by estimating empirical Fisher matrices and solving a regularized generalized eigenvalue problem, guiding the unlearning signal toward target specific information rather than shared prompt structures. Compared with eleven white box and gray box unlearning baselines, CBD achieves a better unlearning utility trade off and its performance varies little across settings. On ToFU forget10, CBD approaches the retrained reference on the forget set while raising model utility to 74.90, about 15% above the second best baseline. On WMDP, it lowers hazardous knowledge accuracy to 25.68, near random guessing, while preserving MMLU accuracy of 52.67. Code is at https://github.com/DGL-codes/CBD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CBD, an API-only black-box unlearning framework for LLMs. It uses two auxiliary models to induce controlled behavioral divergence between retained and target inputs, converts the divergence into an unlearning relevance score, and routes prompts away from the target model. To handle high similarity between retained and unlearning data, it constructs a discriminative basis by estimating empirical Fisher matrices from API outputs and solving a regularized generalized eigenvalue problem. Evaluations on ToFU forget10 report utility of 74.90 (approaching retrained reference, ~15% above second-best baseline) and on WMDP report hazardous knowledge accuracy of 25.68 with MMLU accuracy of 52.67, outperforming eleven baselines.
Significance. If the central claim holds—that the Fisher-based discriminative basis reliably isolates target-specific signals even under high prompt similarity—this would address a practical gap in black-box unlearning for API-accessed LLMs on edge devices. The open code repository is a clear strength for reproducibility.
major comments (2)
- [Method (discriminative basis construction)] Method section on discriminative basis: the construction via empirical Fisher matrices from API outputs followed by the regularized generalized eigenvalue problem supplies no derivation, bound, or orthogonality argument showing that the leading directions are dominated by target-specific components rather than shared prompt structures. This is load-bearing for the discrimination accuracy claim under the high-similarity regime of ToFU.
- [Experiments (ToFU and WMDP evaluations)] Experimental results (ToFU forget10 and WMDP tables): the headline numbers (utility 74.90; hazardous accuracy 25.68) rest on the unverified conversion of divergence scores and the eigenvalue routing step; without details on how the regularized problem is solved or any post-hoc parameter choices, internal consistency of the reported gains cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the acronym ToFU is used without expansion or reference on first appearance.
- [Experiments] The list of eleven baselines would benefit from an explicit table or appendix entry for each method and its access type (white/gray-box).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the theoretical and implementation details of CBD. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and derivations.
read point-by-point responses
-
Referee: Method section on discriminative basis: the construction via empirical Fisher matrices from API outputs followed by the regularized generalized eigenvalue problem supplies no derivation, bound, or orthogonality argument showing that the leading directions are dominated by target-specific components rather than shared prompt structures. This is load-bearing for the discrimination accuracy claim under the high-similarity regime of ToFU.
Authors: We agree that the manuscript would benefit from a formal derivation. In the revision, we will add an appendix deriving the regularized generalized eigenvalue problem, including a decomposition of the Fisher matrices into target-specific and shared components, along with an orthogonality argument showing that the leading directions prioritize target signals under high prompt similarity. This will directly support the discrimination claims for ToFU. revision: yes
-
Referee: Experimental results (ToFU forget10 and WMDP tables): the headline numbers (utility 74.90; hazardous accuracy 25.68) rest on the unverified conversion of divergence scores and the eigenvalue routing step; without details on how the regularized problem is solved or any post-hoc parameter choices, internal consistency of the reported gains cannot be assessed.
Authors: We concur that additional implementation details are necessary for assessing reproducibility. The revised manuscript will include: (i) the specific solver and algorithm used for the regularized generalized eigenvalue problem, (ii) the procedure for selecting the regularization parameter, (iii) pseudocode for converting divergence scores to routing decisions, and (iv) any post-hoc parameter choices. These additions will allow verification of the reported results. revision: yes
Circularity Check
No circularity detected in claimed method or results
full rationale
The paper describes an empirical framework (CBD) that estimates Fisher matrices from API outputs and solves a regularized generalized eigenvalue problem to build a discriminative basis. No equations, derivations, or performance claims are shown to reduce by construction to fitted inputs, self-citations, or renamed known results. Reported metrics (e.g., ToFU utility 74.90, WMDP hazardous accuracy 25.68) are presented as experimental outcomes versus baselines, with no load-bearing self-citation chains or self-definitional steps in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter in generalized eigenvalue problem
axioms (1)
- domain assumption Empirical Fisher matrices estimated from API-accessible outputs approximate the information needed to isolate target-specific gradients.
Reference graph
Works this paper leans on
-
[1]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Communications Surveys & Tutorials, vol. 27, pp. 3820–3860, 2025
2025
-
[2]
Extracting training data from large language models,
N. Carliniet al., “Extracting training data from large language models,” in30th USENIX security symposium (USENIX Security 21), 2021, pp. 2633–2650
2021
-
[3]
Machine unlearning of pre-trained large language models,
J. Yaoet al., “Machine unlearning of pre-trained large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 8403– 8419
2024
-
[4]
Rethinking machine unlearning for large language models,
S. Liuet al., “Rethinking machine unlearning for large language models,”Nature Machine Intelligence, vol. 7, pp. 181–194, 2025
2025
-
[5]
Large language model unlearning,
Y . Yao, X. Xu, and Y . Liu, “Large language model unlearning,”Advances in Neural Information Processing Systems, vol. 37, pp. 105 425–105 475, 2024
2024
-
[6]
Negative preference optimization: From catastrophic collapse to effective unlearning,
R. Zhang, L. Lin, Y . Bai, and S. Mei, “Negative preference optimization: From catastrophic collapse to effective unlearning,” inProceedings of the First Conference on Language Modeling, 2024
2024
-
[7]
Reversing the forget-retain objectives: An efficient LLM unlearning framework from logit difference,
J. Jiet al., “Reversing the forget-retain objectives: An efficient LLM unlearning framework from logit difference,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 12 581–12 611, 2024
2024
-
[8]
Offset unlearning for large language models,
J. Y . Huanget al., “Offset unlearning for large language models,” Transactions on Machine Learning Research, 2025
2025
-
[9]
Gradient projection memory for continual learning,
G. Saha, I. Garg, and K. Roy, “Gradient projection memory for continual learning,” inInternational Conference on Learning Representations, 2021, pp. 944–961
2021
-
[10]
Machine unlearning,
L. Bourtouleet al., “Machine unlearning,” in2021 IEEE symposium on security and privacy (SP), 2021, pp. 141–159
2021
-
[11]
Knowledge unlearning for mitigating privacy risks in language models,
J. Janget al., “Knowledge unlearning for mitigating privacy risks in language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 14 389–14 408
2023
-
[12]
Unlearn what you want to forget: Efficient unlearning for LLMs,
J. Chen and D. Yang, “Unlearn what you want to forget: Efficient unlearning for LLMs,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 12 041– 12 052
2023
-
[13]
Can sensitive information be deleted from LLMs? objectives for defending against extraction attacks,
V . Patil, P. Hase, and M. Bansal, “Can sensitive information be deleted from LLMs? objectives for defending against extraction attacks,” in International Conference on Learning Representations, 2024
2024
-
[14]
To forget or not? towards practical knowledge unlearning for large language models,
B. Tianet al., “To forget or not? towards practical knowledge unlearning for large language models,” inFindings of the Association for Compu- tational Linguistics: EMNLP 2024, 2024, pp. 1524–1537
2024
-
[15]
Simplicity prevails: Rethinking negative preference optimization for LLM unlearning,
C. Fanet al., “Simplicity prevails: Rethinking negative preference optimization for LLM unlearning,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[16]
SOUL: Unlocking the power of second-order optimization for LLM unlearning,
J. Jiaet al., “SOUL: Unlocking the power of second-order optimization for LLM unlearning,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 4276– 4292
2024
-
[17]
W AGLE: Strategic weight attribution for effective and modular unlearning in large language models,
J. Jia, J. Liu, Y . Zhang, P. Ram, N. Baracaldo, and S. Liu, “W AGLE: Strategic weight attribution for effective and modular unlearning in large language models,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[18]
Unilogit: Robust machine unlearning for LLMs using uniform-target self-distillation,
S. Vasilev, C. Herold, B. Liao, S. H. Hashemi, S. Khadivi, and C. Monz, “Unilogit: Robust machine unlearning for LLMs using uniform-target self-distillation,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 22 453–22 472
2025
-
[19]
A general framework to enhance fine-tuning-based LLM unlearning,
J. Renet al., “A general framework to enhance fine-tuning-based LLM unlearning,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 18 464–18 476
2025
-
[20]
On large language model continual unlearning,
C. Gao, L. Wang, K. Ding, C. Weng, X. Wang, and Q. Zhu, “On large language model continual unlearning,” inInternational Conference on Learning Representations, 2025
2025
-
[21]
Avoiding copyright infringement via large language model unlearning,
G. Dou, Z. Liu, Q. Lyu, K. Ding, and E. Wong, “Avoiding copyright infringement via large language model unlearning,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 5191–5215
2025
-
[22]
From evasion to concealment: Stealthy knowledge un- learning for LLMs,
T. Guet al., “From evasion to concealment: Stealthy knowledge un- learning for LLMs,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 10 261–10 279
2025
-
[23]
Not every token needs forgetting: Selective unlearning balancing forgetting and utility in large language models,
Y . Wan, A. Ramakrishna, K.-W. Chang, V . Cevher, and R. Gupta, “Not every token needs forgetting: Selective unlearning balancing forgetting and utility in large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 1827–1835
2025
-
[24]
Reveal and release: Iterative LLM unlearning with self-generated data,
L. Xie, X. Teng, S. Ke, H. Wen, and S. Wan, “Reveal and release: Iterative LLM unlearning with self-generated data,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 23 887–23 899
2025
-
[25]
Rectifying belief space via unlearn- ing to harness LLMs’ reasoning,
A. Niwa, M. Kaneko, and K. Inui, “Rectifying belief space via unlearn- ing to harness LLMs’ reasoning,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 25 060–25 075
2025
-
[26]
In-context unlearning: Language models as few-shot unlearners,
M. Pawelczyk, S. Neel, and H. Lakkaraju, “In-context unlearning: Language models as few-shot unlearners,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235, 2024, pp. 40 034–40 050
2024
-
[27]
Answer when needed, forget when not: Language models pretend to forget via in-context knowledge unlearning,
S. Takashiro, T. Kojima, A. Gambardella, Q. Cao, Y . Iwasawa, and Y . Matsuo, “Answer when needed, forget when not: Language models pretend to forget via in-context knowledge unlearning,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 24 872–24 885
2025
-
[28]
Soft prompting for unlearning in large language models,
K. Bhaila, M.-H. Van, and X. Wu, “Soft prompting for unlearning in large language models,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 4046–4056
2025
-
[29]
Large language model unlearning via embedding-corrupted prompts,
C. Y . Liu, Y . Wang, J. Flanigan, and Y . Liu, “Large language model unlearning via embedding-corrupted prompts,”Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[30]
Fast exact unlearning for in-context learning data for LLMs,
A. I. Muresanu, A. Thudi, M. R. Zhang, and N. Papernot, “Fast exact unlearning for in-context learning data for LLMs,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 45 272–45 288
2025
-
[31]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in Neural Information Processing Systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[32]
Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models,
A. Kassem, O. Mahmoud, and S. Saad, “Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4360– 4379
2023
-
[33]
LLM unlearning via loss adjustment with only forget data,
Y . Wanget al., “LLM unlearning via loss adjustment with only forget data,” inInternational Conference on Learning Representations, 2025
2025
-
[34]
LoRA: Low-rank adaptation of large language models,
E. J. Huet al., “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[35]
New insights and perspectives on the natural gradient method,
J. Martens, “New insights and perspectives on the natural gradient method,”Journal of Machine Learning Research, vol. 21, no. 146, pp. 1–76, 2020
2020
-
[36]
TOFU: A task of fictitious unlearning for LLMs,
P. Maini, Z. Feng, A. Schwarzschild, Z. C. Lipton, and J. Z. Kolter, “TOFU: A task of fictitious unlearning for LLMs,” inFirst Conference on Language Modeling, 2024
2024
-
[37]
The WMDP benchmark: Measuring and reducing ma- licious use with unlearning,
N. Liet al., “The WMDP benchmark: Measuring and reducing ma- licious use with unlearning,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235, 2024, pp. 28 525–28 550
2024
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvronet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Measuring massive multitask language understand- ing,
D. Hendryckset al., “Measuring massive multitask language understand- ing,” inInternational Conference on Learning Representations, 2021
2021
-
[40]
Zephyr: Direct Distillation of LM Alignment
L. Tunstallet al., “Zephyr: Direct distillation of LM alignment,”arXiv preprint arXiv:2310.16944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
TinyLlama: An Open-Source Small Language Model
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,”arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Erasing without remembering: Implicit knowledge forgetting in large language models,
H. Wanget al., “Erasing without remembering: Implicit knowledge forgetting in large language models,”arXiv preprint arXiv:2502.19982, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.