Mitigating LLM-based p-Hacking by Preregistering for the Next LLM
Pith reviewed 2026-06-29 04:59 UTC · model grok-4.3
The pith
Preregistering LLM analysis for the first eligible future model blocks p-hacking transfer in 73 percent of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
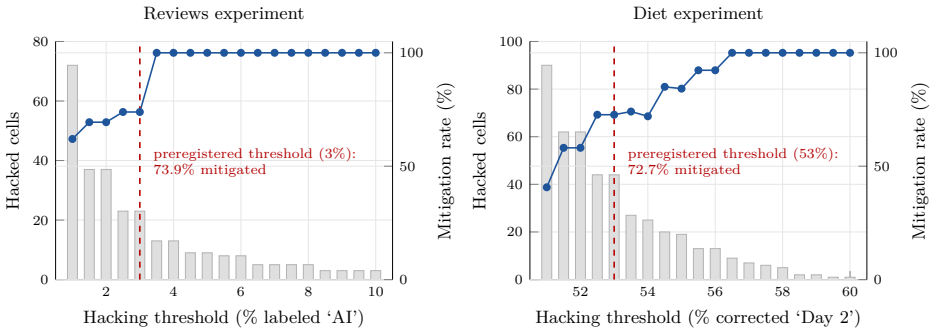
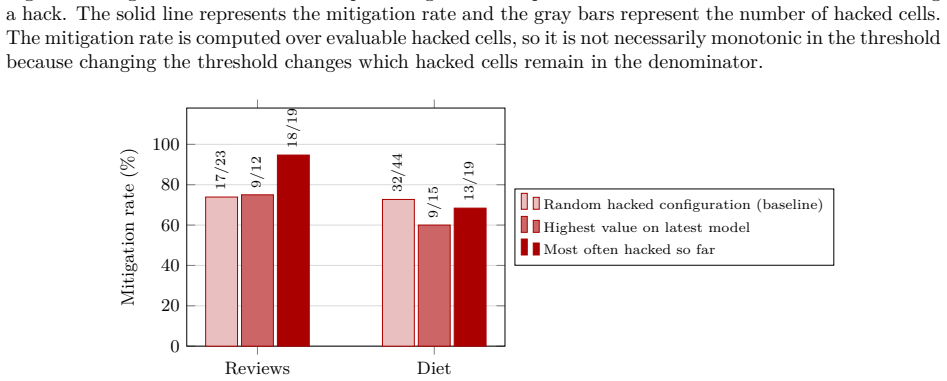
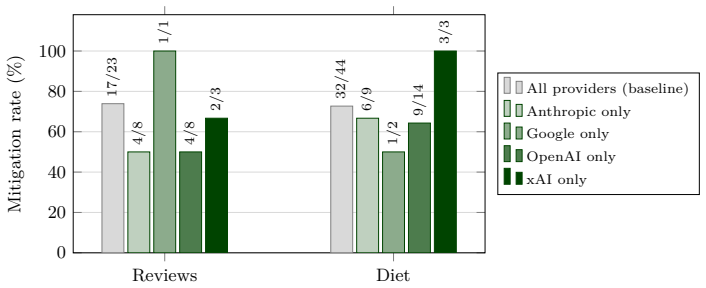
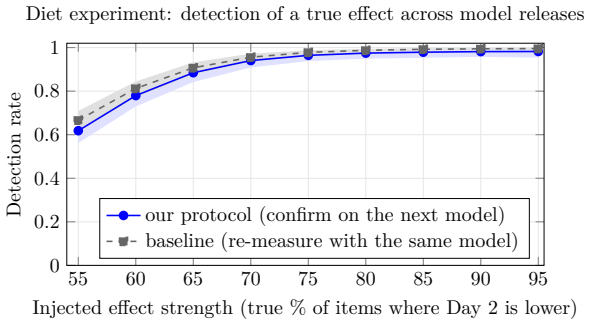
The protocol of preregistering the experiment and eligible models, then executing on the first eligible LLM released afterward, blocks successful transfer of p-hacks in 73.9 percent and 72.7 percent of cases across 20 models from four providers and 11 LLM-analysis configurations in two tasks with known true values. In the authors' own preregistered experiment, six of the seven configurations that hacked the prior model failed to produce the same result on the first eligible model released later.
What carries the argument
The preregistration protocol that commits to running the analysis on the first eligible unreleased LLM after the registration date.
If this is right
- Researchers can complete exploratory work on existing models yet still produce confirmatory results on a model that could not have been tuned against.
- The approach applies directly to any LLM task that feeds into hypothesis tests, such as data annotation or classification.
- Mitigation strength holds across multiple stress tests including changes in the number of listed eligible models.
- The same logic extends to any setting where the test system is released after the analysis plan is fixed.
Where Pith is reading between the lines
- The method may generalize to other fast-updating AI systems where new versions appear regularly.
- Adoption could encourage more labs to maintain lists of eligible future models as part of standard preregistration templates.
- Longer gaps between model releases might increase or decrease transfer rates depending on how much architectures change.
Load-bearing premise
Configurations that produce incorrect results on one model will frequently fail to produce the same incorrect results on the next subsequently released model.
What would settle it
Release of a new LLM on which most p-hacking configurations from the immediately prior model succeed in generating the same incorrect statistical results.
Figures
read the original abstract
Large language models (LLMs) are increasingly used to generate, classify, and annotate data whose outputs feed downstream hypothesis tests. However, LLM-based research is easy to p-hack: a researcher can tune the prompts, decoding parameters, or output format until a desired result is reached. We propose a protocol to mitigate p-hacking in LLM-based research: preregistering the experiment and eligible models, and then running it on the first eligible LLM that is released after the preregistration. The researcher finalizes the procedure on current models, preregisters the analysis plan together with a set of eligible future models, and runs the confirmatory analysis on the first eligible model released afterward. Because this model does not exist at commitment time, it cannot be hacked against; furthermore, configurations that hack one model frequently do not transfer to the next. We evaluate the protocol on two tasks whose true values are known. Across 20 models from four providers and 11 LLM-analysis configurations, the protocol would have blocked successful transfer of the p-hack in 73.9% and 72.7% of cases in the two tasks. Additional analyses reveal that mitigation remains substantial under several stress tests. Finally, putting money where our mouth is, we followed our own protocol and preregistered our experiment. The preregistered experiment confirmed the protocol's effectiveness: out of the 7 configurations that hacked the prior model, the hacking failed to carry over in 6 configurations on the first eligible model released afterward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a protocol to mitigate p-hacking when using LLMs for data generation or annotation in hypothesis testing: researchers finalize and preregister an analysis plan plus a list of eligible future models, then execute on the first eligible model released after preregistration. It evaluates the approach on two tasks with known ground truth using 20 models from four providers and 11 analysis configurations, reporting that the protocol blocks p-hack transfer in 73.9% and 72.7% of cases. A self-preregistered confirmatory experiment is included, in which hacking failed to carry over in 6 of 7 configurations on the next eligible model. Additional stress tests are mentioned as supporting substantial mitigation.
Significance. If the non-transfer finding generalizes, the protocol provides a concrete, low-overhead safeguard for the growing use of LLMs in empirical research pipelines. The authors receive credit for self-applying the protocol via preregistration and for grounding the evaluation in tasks with verifiable ground truth, which enables direct measurement of transfer failure. This could usefully inform practices in NLP and computational social science.
major comments (2)
- [Abstract] Abstract (evaluation paragraph): the reported 73.9% and 72.7% block rates, and the central claim that 'configurations that hack one model frequently do not transfer to the next,' are obtained exclusively on tasks whose true values are known, permitting explicit optimization toward error; the manuscript provides no evidence on transfer rates when researchers tune for statistical significance without a known correct label, which is the typical p-hacking scenario and may involve higher transfer due to shared model families or training data.
- [Abstract] Abstract (evaluation paragraph): no information is given on the criteria used to select the 11 LLM-analysis configurations or the eligible-model lists; without this, it is difficult to judge whether the reported rates reflect a representative sample or were influenced by post-hoc choices.
minor comments (1)
- [Abstract] The abstract could briefly note the two specific tasks used for evaluation to allow readers to assess their representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's potential contribution. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): the reported 73.9% and 72.7% block rates, and the central claim that 'configurations that hack one model frequently do not transfer to the next,' are obtained exclusively on tasks whose true values are known, permitting explicit optimization toward error; the manuscript provides no evidence on transfer rates when researchers tune for statistical significance without a known correct label, which is the typical p-hacking scenario and may involve higher transfer due to shared model families or training data.
Authors: We agree that the reported block rates are measured on tasks with known ground truth, which enables direct identification of configurations that produce incorrect results (i.e., successful p-hacks). This design choice was necessary to quantify transfer failure precisely; without ground truth it is impossible to distinguish a hacked result from a correct one. The protocol itself does not require ground truth at application time—the preregistration simply commits to an unseen future model. We acknowledge that transfer rates could differ when researchers optimize solely for statistical significance, potentially due to shared model families. We will revise the manuscript to explicitly discuss this as a limitation of the current evaluation and to clarify that the self-preregistered confirmatory experiment provides an initial real-world check under the protocol. No new experiments are feasible within the current scope, but the limitation will be stated clearly. revision: partial
-
Referee: [Abstract] Abstract (evaluation paragraph): no information is given on the criteria used to select the 11 LLM-analysis configurations or the eligible-model lists; without this, it is difficult to judge whether the reported rates reflect a representative sample or were influenced by post-hoc choices.
Authors: The 11 configurations were selected to cover a range of prompt styles, decoding parameters, and output formats commonly used in LLM-based annotation and generation pipelines, while the eligible-model lists were constructed from publicly announced release timelines of major providers at the time of each preregistration. We will add a dedicated subsection in the methods (and a corresponding note in the abstract) that details these selection criteria, including the rationale for including both open and closed models and the exact eligibility rules applied. This will allow readers to assess representativeness directly. revision: yes
Circularity Check
No significant circularity; empirical transfer rates are independent observations
full rationale
The paper's central claim rests on empirical measurement of p-hack non-transfer across historical model pairs (73.9%/72.7% block rates) plus a forward preregistered confirmation (6/7 failures to carry over). These are direct observations on distinct models and tasks, not reductions of the result to its own inputs by definition, fitted-parameter renaming, or self-citation chains. The protocol's logic (preregister then run on first future eligible model) is justified by the observed non-transfer without any step that equates the output to the measurement procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Configurations that produce incorrect results on one LLM frequently fail to produce the same incorrect results on the next released model
Reference graph
Works this paper leans on
-
[1]
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, and Libby Hemphill. Prompt design matters for computational social science tasks but in unpredictable ways.arXiv preprint arXiv:2406.11980,
-
[2]
Joachim Baumann, Paul Röttger, Aleksandra Urman, Alexander Wendsjö, Flor Miriam Plaza-del Arco, Johannes B. Gruber, and Dirk Hovy. Large language model hacking: Quantifying the hidden risks of using LLMs for text annotation.arXiv preprint arXiv:2509.08825,
-
[3]
Naoki Egami, Musashi Hinck, Brandon Stewart, and Hanying Wei
URLhttps://www.npr.org/sections/thesalt/2018/09/26/651849441/ cornell-food-researchers-downfall-raises-larger-questions-for-science. Naoki Egami, Musashi Hinck, Brandon Stewart, and Hanying Wei. Using imperfect surrogates for down- stream inference: Design-based supervised learning for social science applications of large language models. Advances in Neur...
2018
-
[4]
Hey ChatGPT, write me a fictional paper: these LLMs are willing to commit academic fraud.Nature, 651(8105):286–287, 2026a
Elizabeth Gibney. Hey ChatGPT, write me a fictional paper: these LLMs are willing to commit academic fraud.Nature, 651(8105):286–287, 2026a. Elizabeth Gibney. Major conference catches illicit AI use—and rejects hundreds of papers.Nature, 652: 281–282, 2026b. Kristina Gligorić, Tijana Zrnic, Cinoo Lee, Emmanuel Candes, and Dan Jurafsky. Can unconfident LLM...
2025
-
[5]
Alexander Goldberg, Ihsan Ullah, Thanh Gia Hieu Khuong, Benedictus Kent Rachmat, Zhen Xu, Isabelle Guyon, and Nihar B Shah. Usefulness of LLMs as an author checklist assistant for scientific papers: NeurIPS’24 experiment.arXiv preprint arXiv:2411.03417,
-
[6]
Luke Guerdan, Justin Whitehouse, Kimberly Truong, Kenneth Holstein, and Zhiwei Steven Wu. Doubly-robust LLM-as-a-judge: Externally valid estimation with imperfect personas.arXiv preprint arXiv:2509.22957,
-
[7]
Flaw or artifact? rethinking prompt sensitivity in evaluating LLMs
16 Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. Flaw or artifact? rethinking prompt sensitivity in evaluating LLMs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19900–19910,
2025
-
[8]
Jessica Hullman, David Broska, Huaman Sun, and Aaron Shaw. This human study did not involve human subjects: Validating LLM simulations as behavioral evidence.arXiv preprint arXiv:2602.15785,
-
[9]
Finetuning LLMs for human behavior prediction in social science experiments
Akaash Kolluri, Shengguang Wu, Joon Sung Park, and Michael S Bernstein. Finetuning LLMs for human behavior prediction in social science experiments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30084–30099,
2025
- [10]
-
[11]
ICLR papers and reviews data 2018–2023
Juanjo Montero. ICLR papers and reviews data 2018–2023. Kaggle,
2018
-
[12]
Peer review and paper meta- data for ICLR 2018–2023
URLhttps://www.kaggle.com/ datasets/juanjomontero/iclr-papers-and-reviews-data-2018-2023. Peer review and paper meta- data for ICLR 2018–2023. Marcus R Munafò, Brian A Nosek, Dorothy VM Bishop, Katherine S Button, Christopher D Chambers, Nathalie Percie du Sert, Uri Simonsohn, Eric-Jan Wagenmakers, Jennifer J Ware, and John PA Ioannidis. A manifesto for r...
2018
-
[13]
Towards LLMs robustness to changes in prompt format styles
Lilian Ngweta, Kiran Kate, Jason Tsay, and Yara Rizk. Towards LLMs robustness to changes in prompt format styles. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop), pages 529–537,
2025
-
[14]
The effect of sampling temperature on problem solving in large language models
Matthew Renze. The effect of sampling temperature on problem solving in large language models. In Findings of the association for computational linguistics: EMNLP 2024, pages 7346–7356,
2024
-
[15]
Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent Laboratory: Using LLM Agents as Research Assistants. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Find- ings of the Association for Computational Linguistics: EMNLP 2025, p...
2025
-
[16]
Language Model Fine-Tuning on Scaled Survey Data for Predicting Distributions of Public Opinions
Joseph Suh, Erfan Jahanparast, Suhong Moon, Minwoo Kang, and Serina Chang. Language model fine-tuning on scaled survey data for predicting distributions of public opinions.arXiv preprint arXiv:2502.16761,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
An empirical study of LLM reasoning ability under strict output length constraint
Yi Sun, Han Wang, Jiaqiang Li, Jiacheng Liu, Xiangyu Li, Hao Wen, Yizhen Yuan, Huiwen Zheng, Yan Liang, Yuanchun Li, et al. An empirical study of LLM reasoning ability under strict output length constraint. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7663–7682,
2025
-
[18]
Beyond checklist approaches to ethics in design
Richmond Y Wong, Karen Boyd, Jake Metcalf, and Katie Shilton. Beyond checklist approaches to ethics in design. InCompanion Publication of the 2020 Conference on Computer Supported Cooperative Work and Social Computing, pages 511–517,
2020
-
[19]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Stop Drawing Scientific Claims from LLM Social Simulations Without Robustness Audits
Jinyi Ye, Lei Cao, Ding Chen, and Emilio Ferrara. Stop drawing scientific claims from LLM social simulations without robustness audits.arXiv preprint arXiv:2605.18890,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.