ToE: A Hierarchical and Explainable Claim Verification Framework with Dynamic Multi-source Evidence Retrieval and Aggregation
Pith reviewed 2026-06-29 05:01 UTC · model grok-4.3
The pith
Tree of Evidence improves claim verification by modeling claims as expanding argument trees that use reinforcement learning to retrieve and aggregate multi-source evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ToE models each claim as a dynamically expanding argument tree that integrates a reinforcement learning-driven multi-source retrieval agent, an evidence evaluation agent, and an argument tree aggregation algorithm; the system iteratively decomposes claims, retrieves relevant evidence, and verifies them through an explainable evidence chain, with a formal error bound that guarantees the learned retrieval policy converges to a neighborhood of the information-theoretically optimal policy.
What carries the argument
The dynamically expanding argument tree together with its reinforcement learning retrieval agent and aggregation algorithm, which together produce the explainable evidence chain.
If this is right
- Verification accuracy rises on both clean and adversarially manipulated inputs across multiple datasets and backbone models.
- The output includes an explicit evidence chain that traces how each sub-claim was supported or refuted.
- The retrieval policy is accompanied by a proven error bound relative to the optimal policy.
- The same architecture can be attached to different large language models without retraining the core agents.
Where Pith is reading between the lines
- If the tree decomposition reliably captures logical dependencies, the same structure could be reused for multi-hop question answering beyond fact-checking.
- The convergence guarantee on the retrieval policy implies that similar learned agents might stabilize evidence gathering in other retrieval-augmented generation pipelines.
- Because gains are largest on poisoned data, the framework may reduce the effectiveness of generative engine optimization attacks that target standard search rankings.
Load-bearing premise
The reinforcement learning agent can decompose claims and collect evidence across sources without systematic bias or gaps that would invalidate the final aggregation.
What would settle it
If experiments on the same poisoned-input test sets show accuracy gains below 4 percentage points or none at all when the RL retrieval agent is replaced by a non-adaptive baseline, the performance claims would be falsified.
Figures

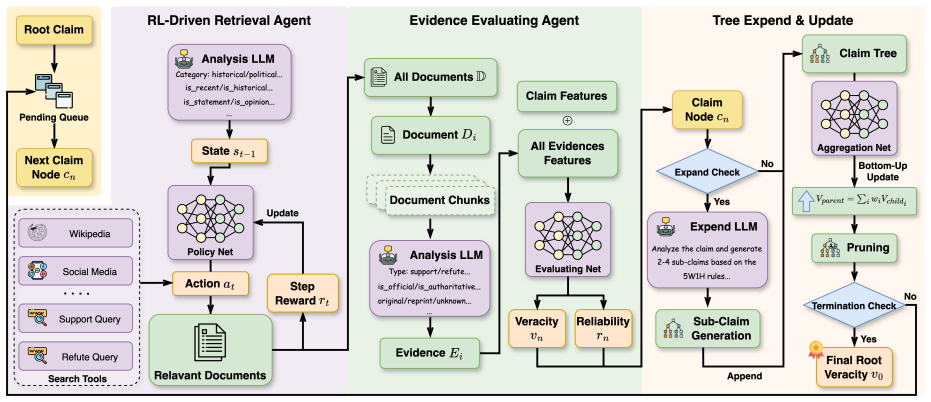
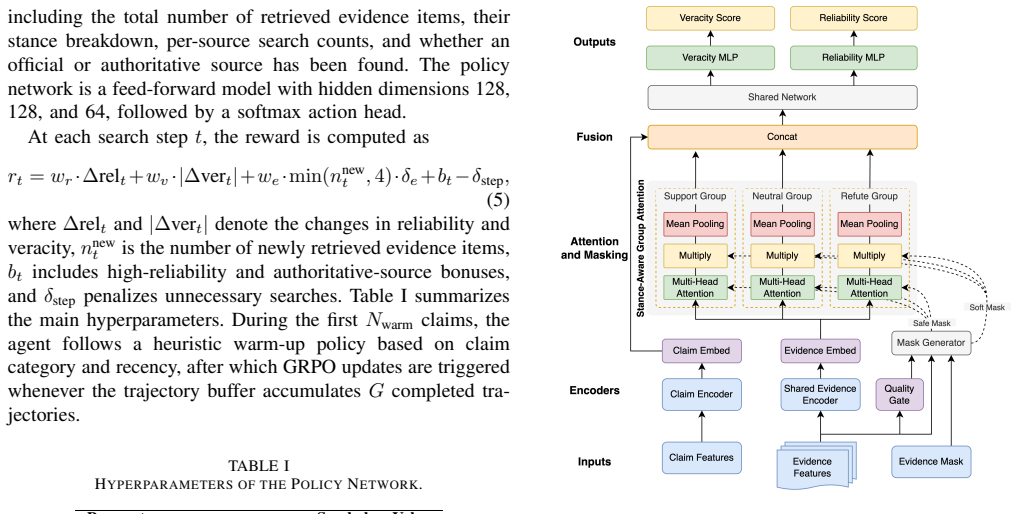


read the original abstract
The rapid spread of fake news poses increasing threats to information ecosystems, especially as AI-generated misinformation under Generative Engine Optimization (GEO) poisoning allows adversarially crafted content to be systematically surfaced by retrieval systems, contaminating LLM reasoning. In this paper, we propose Tree of Evidence (ToE), a hierarchical evidence reasoning framework for automated fact-checking that models each claim as a dynamically expanding argument tree. ToE integrates a reinforcement learning-driven multi-source retrieval agent, an evidence evaluation agent, and an argument tree aggregation algorithm to iteratively decompose, retrieve, and verify claims through an explainable evidence chain. We further provide a theoretical analysis of the retrieval process, deriving a formal error bound that guarantees the learned policy converges to a neighborhood of the information-theoretically optimal policy. Experiments across multiple datasets and backbone LLMs demonstrate that ToE achieves improvements ranging from 4 to 24 percentage points over competitive baselines, with particularly pronounced gains on adversarially poisoned inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tree of Evidence (ToE), a hierarchical claim verification framework that represents each claim as a dynamically expanding argument tree. It integrates an RL-driven multi-source retrieval agent, an evidence evaluation agent, and an aggregation algorithm to decompose claims, retrieve evidence from multiple sources, and produce explainable verification. The authors derive a formal error bound showing that the learned retrieval policy converges to a neighborhood of the information-theoretically optimal policy. Experiments across multiple datasets and backbone LLMs are reported to yield 4–24 percentage point gains over baselines, with larger improvements on adversarially poisoned (GEO) inputs.
Significance. If the experimental gains and the error bound are rigorously established, the work would be significant for automated fact-checking under generative-engine-optimization attacks. The hierarchical, explainable tree structure combined with RL-driven dynamic retrieval addresses a timely problem in misinformation detection and could influence both practical systems and theoretical analyses of retrieval-augmented verification.
major comments (2)
- [Abstract] Abstract: the claim of 4–24 percentage point improvements is presented without any experimental protocol, baseline definitions, statistical tests, dataset details, or ablation results, rendering it impossible to determine whether the numbers support the central performance claim.
- [Abstract] Abstract: the formal error bound is asserted to guarantee convergence of the RL retrieval policy to a neighborhood of the information-theoretically optimal policy, yet no derivation, assumptions on reward stationarity, or handling of non-stationary/adversarial evidence distributions under GEO poisoning are supplied; without these it cannot be verified whether the bound remains meaningful or reduces to a tautology when evidence chains can be systematically biased or omitted.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We will revise the abstract to provide additional context for the reported results and to reference the relevant sections containing the theoretical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 4–24 percentage point improvements is presented without any experimental protocol, baseline definitions, statistical tests, dataset details, or ablation results, rendering it impossible to determine whether the numbers support the central performance claim.
Authors: We agree that the abstract would benefit from additional context to support the performance claims. In the revised version we will update the abstract to briefly note the datasets employed (including GEO-poisoned variants), the primary baselines considered, and that the reported gains were obtained consistently across multiple backbone LLMs. Full experimental protocols, baseline definitions, statistical tests, dataset details, and ablation studies are provided in Section 4; the abstract revision will point readers to that section. revision: yes
-
Referee: [Abstract] Abstract: the formal error bound is asserted to guarantee convergence of the RL retrieval policy to a neighborhood of the information-theoretically optimal policy, yet no derivation, assumptions on reward stationarity, or handling of non-stationary/adversarial evidence distributions under GEO poisoning are supplied; without these it cannot be verified whether the bound remains meaningful or reduces to a tautology when evidence chains can be systematically biased or omitted.
Authors: The derivation of the error bound, the assumptions on the reward function (including stationarity conditions), and the analysis of convergence under adversarial evidence distributions are supplied in Section 3, with the complete proof in Appendix A. The bound is formulated to hold in a neighborhood of the optimum precisely to accommodate systematic bias or omission in evidence chains, such as those arising from GEO poisoning. We will revise the abstract to include an explicit reference to Section 3 so that readers can locate the full derivation and assumptions. revision: yes
Circularity Check
No circularity: theoretical bound and empirical gains presented as independent
full rationale
The abstract claims a derived formal error bound guaranteeing RL policy convergence to a neighborhood of the information-theoretically optimal policy, alongside 4-24pp empirical gains. No equations, self-citations, fitted parameters renamed as predictions, or ansatzes are quoted or visible in the provided text that would reduce the bound to its inputs by construction. The derivation chain is therefore treated as self-contained; the bound is asserted as an independent theoretical result rather than a tautology or self-referential fit. No load-bearing self-citation or renaming of known results is exhibited.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL retrieval policy parameters
axioms (1)
- domain assumption An information-theoretically optimal retrieval policy exists for the claim verification task
invented entities (2)
-
Argument tree
no independent evidence
-
Multi-source retrieval agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[4]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Infor- mation Processing Systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[5]
Poisoning retrieval corpora by injecting adversarial passages,
Z. Zhong, Z. Huang, A. Wettig, and D. Chen, “Poisoning re- trieval corpora by injecting adversarial passages,”arXiv preprint arXiv:2310.19156, 2023. 8 TABLE III ABLATION STUDY OF THE SEARCH TOOL SPACE. Metrics Overall Acc. Acc. (TRUE) Acc. (FALSE) Acc. (UNCERTAIN) A vg. Steps Full Tool Space (All Actions) 80.0% 91.6% 75.0% 66.7% 5.4 w/o Academic (ArXiv) 7...
-
[6]
W. Zou, R. Geng, B. Wang, and J. Jia, “Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models,”arXiv preprint arXiv:2402.07867, 2024
-
[7]
Combating knowledge corruption in agent systems: A byzantine- tolerant secure collaborative rag framework,
Z. Wang, D. He, Z. Zhang, Y . Liu, J. Liu, Z. Zeng, Z. Qin, Z. Li, X. Li, H. Yao, J. An, Y . Liu, Y . Li, Q. Sun, X. Liu, and L. Zhu, “Combating knowledge corruption in agent systems: A byzantine- tolerant secure collaborative rag framework,” inProceedings of the ACM Web Conference 2026, ser. WWW ’26. ACM, 2026
2026
-
[8]
Geo: Generative engine optimization,
P. Aggarwal, V . Murahari, T. Rajpurohit, A. Kalyan, K. Narasimhan, and A. Deshpande, “Geo: Generative engine optimization,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 5–16
2024
-
[9]
A survey of fake news: Fundamental the- ories, detection methods, and opportunities,
X. Zhou and R. Zafarani, “A survey of fake news: Fundamental the- ories, detection methods, and opportunities,”ACM Computing Surveys (CSUR), vol. 53, no. 5, pp. 1–40, 2020
2020
-
[10]
Teller: A trustworthy framework for explainable, generalizable and controllable fake news detection,
H. Liu, W. Wang, H. Li, and H. Li, “Teller: A trustworthy framework for explainable, generalizable and controllable fake news detection,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 15 556–15 583
2024
-
[11]
Fighting fire with fire: The dual role of llms in crafting and detecting elusive disinformation,
J. Lucas, A. Uchendu, M. Yamashita, J. Lee, S. Rohatgi, and D. Lee, “Fighting fire with fire: The dual role of llms in crafting and detecting elusive disinformation,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 14 279– 14 305
2023
-
[12]
G. Li, W. Lu, W. Zhang, D. Lian, K. Lu, R. Mao, K. Shu, and H. Liao, “Re-search for the truth: Multi-round retrieval-augmented large language models are strong fake news detectors,”arXiv preprint arXiv:2403.09747, 2024
-
[13]
Afacta: Assisting the annotation of factual claim detection with reliable llm annotators,
J. Ni, M. Shi, D. Stammbach, M. Sachan, E. Ash, and M. Leippold, “Afacta: Assisting the annotation of factual claim detection with reliable llm annotators,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1890–1912
2024
-
[14]
Fakegpt: fake news generation, explanation and detection of large language models,
Y . Huang and L. Sun, “Fakegpt: fake news generation, explanation and detection of large language models,”arXiv preprint arXiv:2310.05046, 2023
-
[15]
Robust fake news detection using large language models under adversarial sentiment attacks,
S. Tahmasebi, E. M ¨uller-Budack, and R. Ewerth, “Robust fake news detection using large language models under adversarial sentiment attacks,”arXiv preprint arXiv:2601.15277, 2026
-
[16]
Planning and acting in partially observable stochastic domains,
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and acting in partially observable stochastic domains,”Artificial intelligence, vol. 101, no. 1-2, pp. 99–134, 1998
1998
-
[17]
Similar: Sub- modular information measures based active learning in realistic scenar- ios,
S. Kothawade, N. Beck, K. Killamsetty, and R. Iyer, “Similar: Sub- modular information measures based active learning in realistic scenar- ios,”Advances in Neural Information Processing Systems, vol. 34, pp. 18 685–18 697, 2021
2021
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
“liar, liar pants on fire
W. Y . Wang, ““liar, liar pants on fire”: A new benchmark dataset for fake news detection,” inProceedings of the 55th annual meeting of the association for computational linguistics (volume 2: short papers), 2017, pp. 422–426
2017
-
[20]
Politifact fact check dataset,
R. Misra, “Politifact fact check dataset,” 09 2022
2022
-
[21]
Check-covid: Fact-checking covid-19 news claims with scientific evidence,
G. Wang, K. Harwood, L. Chillrud, A. Ananthram, M. Subbiah, and K. McKeown, “Check-covid: Fact-checking covid-19 news claims with scientific evidence,” inFindings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 14 114–14 127
2023
-
[22]
Deepseek-v3.2: Pushing the frontier of open large lan- guage models,
DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large lan- guage models,” 2025
2025
-
[23]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b & gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.