KG2Cypher: Data-Centric Pipeline for Building Enterprise Text-to-Cypher Systems
Pith reviewed 2026-06-29 04:44 UTC · model grok-4.3
The pith
KG2Cypher pipeline generates validated Text-Cypher pairs from knowledge graphs to train accurate text-to-Cypher models for enterprise use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
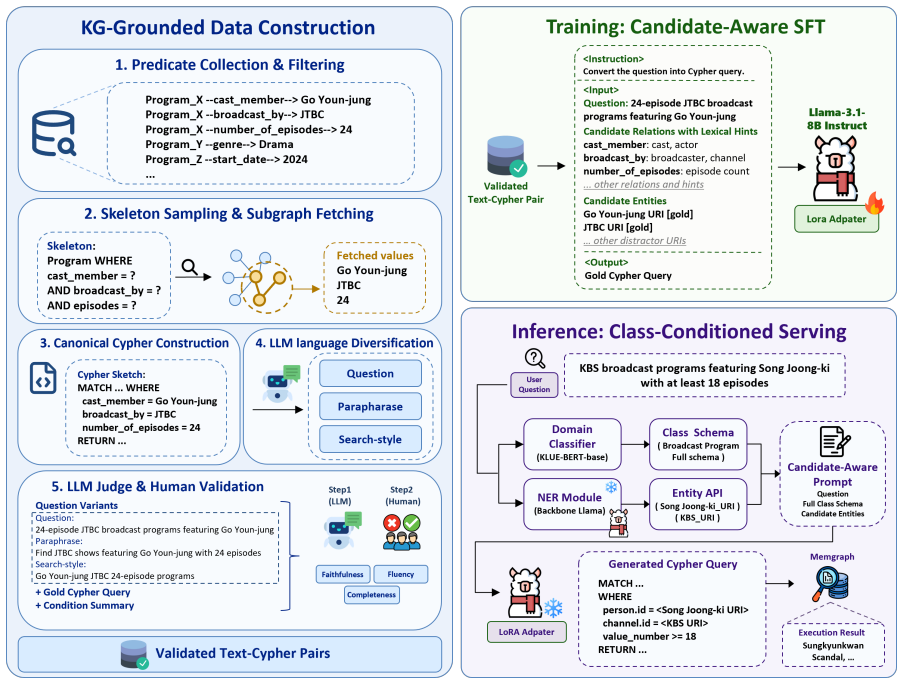
KG2Cypher constructs an executable Cypher query from observed graph facts and uses LLMs to generate its associated natural-language question. The resulting Text-Cypher pairs are validated with an LLM judge and human validation, and are converted into candidate-aware SFT data. The trained generator is served with class-conditioned schema prompting, entity retrieval, and LoRA-based inference, achieving 95.2% exact match, 99.9% execution rate, and 0.964 execution-result F1 in an 11-class setting.
What carries the argument
The data-centric pipeline that generates Text-Cypher pairs by deriving Cypher from graph facts and reverse-generating questions with LLMs, followed by validation and LoRA SFT training.
If this is right
- LoRA SFT raises execution-result F1 from 0.806 to 0.950 on broadcast-program queries.
- Execution-result F1 improves from 0.70 to 0.92 on company queries.
- In 11-class setting, achieves 95.2% exact match and 99.9% execution rate.
- The system handles short search-style queries and schema paraphrases in Korean enterprise settings.
Where Pith is reading between the lines
- This could lower the barrier for companies to deploy natural language query interfaces on their internal graphs.
- The validation step might be adaptable to other structured query languages like SQL.
- Scaling the pipeline could enable zero-shot or few-shot adaptations to new graph schemas.
Load-bearing premise
The LLM judge combined with human validation produces sufficiently unbiased Text-Cypher pairs that training improves real execution performance rather than fitting to validation artifacts.
What would settle it
Evaluating the trained model on a new enterprise graph with unseen query classes or different schema structures and measuring if execution-result F1 drops significantly below 0.9.
Figures
read the original abstract
Enterprise Knowledge Graphs (KGs) are increasingly used for internal search, analytics, and question answering, but building natural-language interfaces for private enterprise graphs remains costly. We present KG2Cypher, a data-centric pipeline for building enterprise text-to-Cypher systems from existing KGs. KG2Cypher first constructs an executable Cypher query from observed graph facts and then uses LLMs to generate its associated natural-language question. The resulting Text-Cypher pairs are validated with an LLM judge and human validation, and are converted into candidate-aware SFT data. The trained generator is served with class-conditioned schema prompting, entity retrieval, and LoRA-based inference. We evaluate KG2Cypher in Korean enterprise settings, where short search-style queries and schema paraphrases make language grounding difficult. LoRA SFT improves execution-result F1 from 0.806 to 0.950 on broadcast-program queries and from 0.70 to 0.92 on company queries. In an 11-class setting, KG2Cypher achieves 95.2% exact match, 99.9% execution rate, and 0.964 execution-result F1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents KG2Cypher, a data-centric pipeline that constructs executable Cypher queries from observed enterprise KG facts, generates corresponding natural-language questions via LLMs, validates the resulting Text-Cypher pairs with an LLM judge plus human review, and uses the filtered pairs for class-conditioned LoRA SFT. The trained model is deployed with schema prompting and entity retrieval. On Korean enterprise broadcast-program and company queries, LoRA SFT raises execution-result F1 from 0.806 to 0.950 and from 0.70 to 0.92 respectively; in an 11-class setting the system reports 95.2% exact match, 99.9% execution rate, and 0.964 execution-result F1.
Significance. If the reported gains prove robust to the validation process, the work offers a practical, low-annotation route to text-to-Cypher systems for private KGs, directly addressing the cost barrier noted in the abstract. The emphasis on execution-result metrics rather than surface match and the concrete before-and-after numbers constitute a strength; the absence of error bars or ablations, however, leaves the magnitude of improvement difficult to interpret.
major comments (3)
- [Pipeline description / validation step] The validation subsection (described in the pipeline overview) provides no prompt template, decision threshold, or inter-annotator agreement statistics for the LLM judge. Because the central claim is that LoRA SFT on judge-filtered pairs produces the observed F1 lifts (0.806→0.950 and 0.70→0.92), the lack of these quantities makes it impossible to rule out that the model is fitting to judge-specific artifacts rather than improving Cypher generation.
- [Experiments / results tables] Experiments section reports aggregate F1 and exact-match figures but contains no ablation that isolates the contribution of the LLM-judge filter versus the human-validation step, nor any error bars or statistical significance tests on the before-and-after deltas. These omissions are load-bearing for the claim that the pipeline reliably improves execution accuracy.
- [Evaluation setup] No analysis is given of whether the test queries share the same synthetic generation process as the training pairs; if they do, the high execution rate (99.9%) and F1 (0.964) could be explained by distributional overlap rather than generalization.
minor comments (2)
- [Abstract and §4] The abstract and results tables use “execution-result F1” without an explicit definition or reference to the precise matching criterion (e.g., whether partial result overlap is credited).
- [Figures 2–3 and Table 2] Figure captions and table footnotes do not indicate the number of human validators or the exact protocol used for the final human-validation pass.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation details, experimental reporting, and evaluation setup. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Pipeline description / validation step] The validation subsection (described in the pipeline overview) provides no prompt template, decision threshold, or inter-annotator agreement statistics for the LLM judge. Because the central claim is that LoRA SFT on judge-filtered pairs produces the observed F1 lifts (0.806→0.950 and 0.70→0.92), the lack of these quantities makes it impossible to rule out that the model is fitting to judge-specific artifacts rather than improving Cypher generation.
Authors: We will add the LLM judge prompt template and decision threshold to the revised manuscript (in the validation subsection or an appendix) to support reproducibility. The training data additionally underwent a human validation step after the LLM judge, which we will emphasize as a safeguard against potential judge-specific artifacts. We did not compute inter-annotator agreement for the LLM judge and will acknowledge this as a limitation. revision: yes
-
Referee: [Experiments / results tables] Experiments section reports aggregate F1 and exact-match figures but contains no ablation that isolates the contribution of the LLM-judge filter versus the human-validation step, nor any error bars or statistical significance tests on the before-and-after deltas. These omissions are load-bearing for the claim that the pipeline reliably improves execution accuracy.
Authors: We will add error bars by reporting means and standard deviations from multiple training runs with different random seeds. A dedicated ablation isolating the LLM-judge filter from the subsequent human-validation step is not feasible within the revision timeline due to computational constraints; we will explicitly note this limitation and the role of the combined validation process in the revised text. revision: partial
-
Referee: [Evaluation setup] No analysis is given of whether the test queries share the same synthetic generation process as the training pairs; if they do, the high execution rate (99.9%) and F1 (0.964) could be explained by distributional overlap rather than generalization.
Authors: The test queries were collected from real enterprise user logs and are independent of the synthetic generation process used to create the training pairs. We will add an explicit statement and brief description of the test-query collection process in the evaluation setup section to clarify the absence of distributional overlap. revision: yes
Circularity Check
Empirical pipeline with held-out execution metrics shows no circularity
full rationale
The paper presents a data-centric pipeline for generating Text-Cypher pairs via synthesis, LLM question generation, LLM-judge filtering, and human validation, followed by LoRA SFT and evaluation. All reported metrics (execution-result F1, exact match, execution rate) are computed on held-out queries against actual Cypher execution results on the enterprise KG. No equations, derivations, or self-citations are invoked that reduce any claimed result to a fitted parameter or prior self-result by construction. The evaluation is externally grounded in execution outcomes rather than internal consistency with the generation process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate natural-language questions from Cypher queries and judge pair quality with sufficient reliability for downstream training
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing: Industry Track, pages 1890–1905, Suzhou, China
Mind the query: A benchmark dataset towards Text2Cypher task. InProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing: Industry Track, pages 1890–1905, Suzhou, China. Association for Computational Linguistics. Mohnish Dubey, Debayan Banerjee, Abdelrahman Ab- delkawi, and Jens Lehmann
2025
-
[2]
InThe Semantic Web – ISWC 2019, pages 69–78
Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia. InThe Semantic Web – ISWC 2019, pages 69–78. Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor
2019
-
[3]
InProceedings of the 2018 International Conference on Management of Data, pages 1433–1445
Cypher: An evolving query language for property graphs. InProceedings of the 2018 International Conference on Management of Data, pages 1433–1445. Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou
2018
-
[4]
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8753–8772
Beyond seen data: Improving KBQA generalization through schema-guided logical form generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8753–8772. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaug...
2025
-
[5]
The llama 3 herd of models. Preprint, arXiv:2407.21783. Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InProceedings of the Web Con- ference 2021, WWW ’21, page 3477–3488
Beyond i.i.d.: Three levels of generalization for question answering on knowledge bases. InProceedings of the Web Con- ference 2021, WWW ’21, page 3477–3488. ACM. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
2021
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models.Preprint, arXiv:2106.09685. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gon- zalez, Hao Zhang, and Ion Stoica
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Text2Cypher: Bridging natural language and graph databases
Text2cypher: Bridg- ing natural language and graph databases.Preprint, arXiv:2412.10064. Makbule Gulcin Ozsoy and William Tai
-
[9]
Text2cypher across languages: Evaluating and fine- tuning llms.arXiv preprint arXiv:2506.21445, arXiv:2506.21445. Sungjoon Park, Jihyung Moon, Sungdong Kim, Won Ik Cho, Jiyoon Han, Jangwon Park, Chisung Song, Jun- seong Kim, Yongsook Song, Taehwan Oh, Joohong Lee, Juhyun Oh, Sungwon Lyu, Younghoon Jeong, Inkwon Lee, Sangwoo Seo, Dongjun Lee, Hyunwoo Kim, ...
-
[10]
Klue: Korean language understanding evaluation.Preprint, arXiv:2105.09680. Torsten Scholak, Nathan Schucher, and Dzmitry Bah- danau
-
[11]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Picard: Parsing incrementally for constrained auto-regressive decoding from language models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Aman Tiwari, Shiva Krishna Reddy Malay, Vikas Yadav, Masoud Hashemi, and Sathwik Tejaswi Madhusud- han
2021
-
[12]
Auto-cypher: Improving llms on cypher generation via llm-supervised generation-verification framework.Preprint, arXiv:2412.12612. Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson
-
[13]
InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic pars- ing and text-to-sql task. InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph ...
2018
-
[14]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Judg- ing llm-as-a-judge with mt-bench and chatbot arena. Preprint, arXiv:2306.05685. Victor Zhong, Caiming Xiong, and Richard Socher
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing
Seq2sql: Generating structured queries from natural language using reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. A LLM Judge Metric Validation We use synthetic failure simulations to check why the calibration gate uses MAE, adjacent agreement, and catch rate together. Each simulation con...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.