Phase structure of the Random Language Model
Pith reviewed 2026-06-29 01:57 UTC · model grok-4.3
The pith
The random language model maps to the random energy model and exhibits a hierarchy of phase transitions in a double-scaling limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
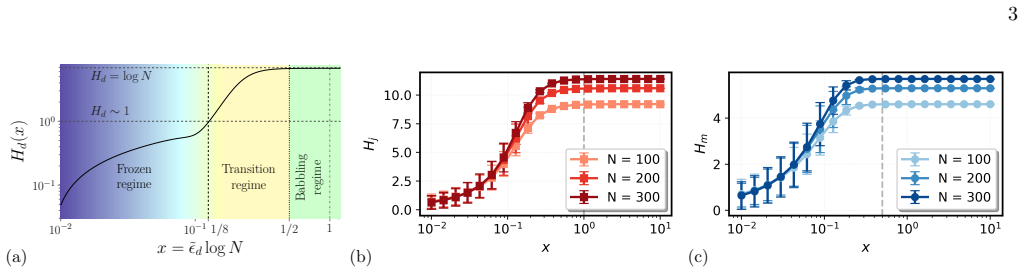
In the double-scaling limit where the rescaled temperature x equals the grammar temperature times the logarithm of the number of hidden symbols, the random language model is equivalent to the random energy model. This equivalence produces a sequence of transitions: symbol correlations set in at one value of x, marginal distributions over symbols cease to be uniform at a second value, and rule usage freezes into a glassy phase at a third value. A semi-annealed calculation then yields explicit scaling forms for rule frequencies, entropy, and energy.
What carries the argument
The identification of the random language model with the random energy model inside the double-scaling limit x = ε̃_d log N.
If this is right
- Symbol correlations appear once x exceeds the first critical value.
- Single-symbol marginals become non-uniform past the second critical value.
- Rule selection enters a glassy phase beyond the third critical value.
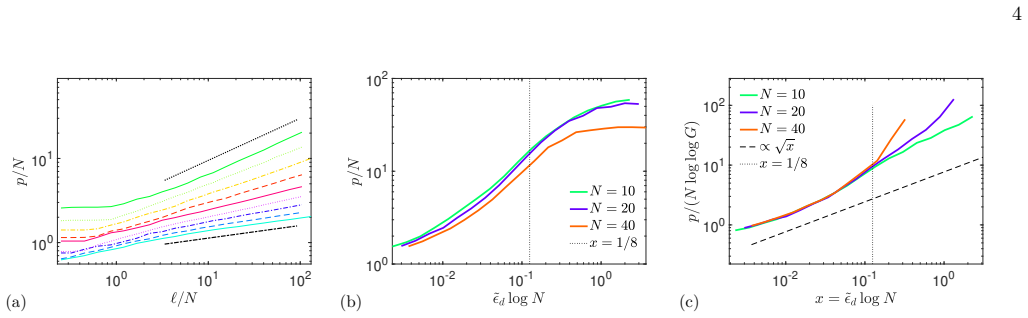
- Rule usage, entropy, and energy obey explicit scaling laws that reproduce Heaps' law and context-length scaling.
Where Pith is reading between the lines
- The same scaling construction could be applied to other ensembles of generative grammars to locate their own transition points.
- Spin-glass techniques already used for the random energy model become directly available for analyzing grammar-based language models.
- The glassy freezing of rules supplies a candidate mechanism for the abrupt changes in output structure sometimes observed when model size or training temperature is varied.
Load-bearing premise
The random language model becomes exactly equivalent to the random energy model once the grammar temperature and hidden-symbol count are scaled together at fixed product.
What would settle it
Numerical sampling of the random language model at large but finite N and correspondingly small ε̃_d, with x held constant, that fails to show the predicted sequence of changes in symbol correlations or rule freezing.
Figures

read the original abstract
Context-free grammars are minimal models of hierarchical structure in human language, generating structured text from recursive production rules. The Random Language Model (RLM) [De Giuli, PRL 2019], an ensemble of such grammars with random rule weights, exhibits a cross-over from gibberish-like output to structured text as a function of a "temperature", but the location and nature of this transition remained unclear. Here, we show that the RLM exhibits a hierarchy of phase transitions in a double-scaling limit where the grammar temperature $\tilde{\epsilon}_d \to 0$ and the number of hidden symbols $N \to \infty$ at fixed $x = \tilde{\epsilon}_d \log N$. By identifying the relation between RLM and the Random Energy Model, we identify a series of transitions where correlations between symbols emerge, single-symbol marginals become non-uniform, and rule use freezes in a glassy phase. A semi-annealed approximation yields nontrivial scaling laws for rule usage, entropy, and energy, consistent with Heaps' law and context-length scaling observed in large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Random Language Model (RLM) of random context-free grammars exhibits a hierarchy of phase transitions in the double-scaling limit ε̃_d → 0, N → ∞ at fixed x = ε̃_d log N. By mapping the RLM onto the Random Energy Model (REM), it identifies successive transitions at which symbol correlations emerge, single-symbol marginals become non-uniform, and rule usage freezes into a glassy phase. A semi-annealed approximation is used to derive scaling laws for rule usage, entropy, and energy that are stated to be consistent with Heaps' law and context-length scaling in large language models.
Significance. If the RLM-REM mapping is rigorously controlled, the work supplies an analytic statistical-mechanics account of the crossover from unstructured to structured output in random grammars and links it to observable scaling laws in language models. The explicit use of the REM reference frame and the semi-annealed approximation constitute a clear technical strength when the limit is shown to eliminate grammar-specific correlations.
major comments (1)
- [Abstract and the section deriving the relation to the REM] The RLM-REM identification in the double-scaling limit x = ε̃_d log N is the load-bearing step for the entire hierarchy of transitions. The manuscript must demonstrate explicitly (with controlled error bounds) that the effective energy distribution over rule configurations becomes Gaussian and uncorrelated at leading order, with all sub-leading grammar-specific correlations vanishing as ε̃_d → 0 at fixed x; otherwise the sequence of transitions read off from the REM does not apply to the RLM.
minor comments (1)
- Notation for the scaled temperature variable (ε̃_d versus ε_d) should be made uniform throughout the text and equations.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the central role of the RLM-REM mapping. We respond to the single major comment below and indicate the revisions we will undertake.
read point-by-point responses
-
Referee: [Abstract and the section deriving the relation to the REM] The RLM-REM identification in the double-scaling limit x = ε̃_d log N is the load-bearing step for the entire hierarchy of transitions. The manuscript must demonstrate explicitly (with controlled error bounds) that the effective energy distribution over rule configurations becomes Gaussian and uncorrelated at leading order, with all sub-leading grammar-specific correlations vanishing as ε̃_d → 0 at fixed x; otherwise the sequence of transitions read off from the REM does not apply to the RLM.
Authors: We agree that explicit control of the mapping is required for the hierarchy of transitions to be applicable. The manuscript derives the effective energy by averaging over the random rule weights in the double-scaling limit and invokes the central-limit theorem for the sum of many independent contributions, yielding a Gaussian distribution at leading order with variance proportional to log N. Grammar-specific correlations appear only at O(ε̃_d) and are therefore suppressed at fixed x. To meet the request for controlled error bounds we will revise the derivation section to include an explicit cumulant expansion, showing that all non-Gaussian cumulants and residual correlations are o(1) as ε̃_d → 0 with x held fixed. This addition will be placed immediately after the statement of the mapping and will not alter the subsequent phase-structure analysis. revision: yes
Circularity Check
No significant circularity; RLM-REM mapping presented as identification, not tautological reduction.
full rationale
The abstract and context describe an identification of RLM with REM in the double-scaling limit x=ε̃_d log N as the basis for reading off transitions. This is framed as a derived relation rather than a definitional equivalence or self-citation chain. The semi-annealed approximation is explicitly labeled as such and yields scaling laws presented as consistent with external observations (Heaps' law), not fitted to the target results. No equations or steps in the provided text reduce predictions to inputs by construction, and the central claim retains independent content from the REM reference frame. No load-bearing self-citations or ansatz smuggling are quoted.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling variable x = ε̃_d log N
axioms (1)
- domain assumption The Random Language Model can be mapped onto the Random Energy Model in the double-scaling limit.
Reference graph
Works this paper leans on
-
[1]
applying a rulea→bcwith parentaand childrenb(left) andc(right)
logN 2 +ℓlogT, whereℓis the number of leaves ofTand Tis the number of observable symbols in the grammar. applying a rulea→bcwith parentaand childrenb(left) andc(right). The weakest structure such a factor can generate is a correlation between its two children while each child’s marginal remains uniform. By holding the message reach- ingffrom above uniform...
-
[2]
Estensione del numero di dottorati di ricerca e dottorati innovativi per la Pubblica Amministrazione e il patrimonio culturale
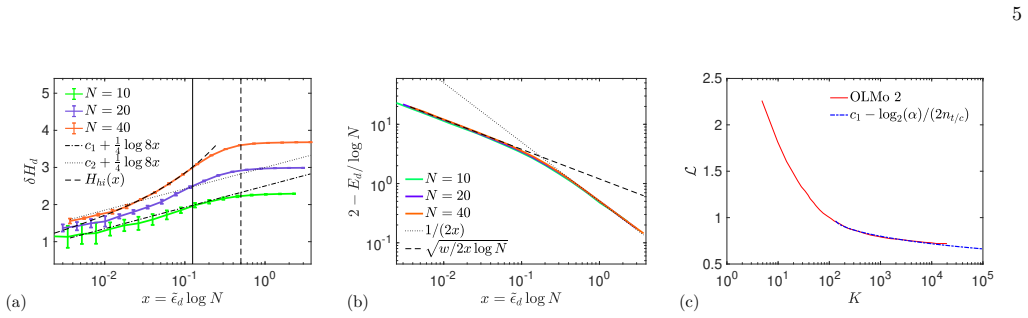
We predict a loga- rithmic behavior at smallxwith prefactor 1/4, verified in fig. 4a (dash-dotted and dotted lines), and a steepening asx→1/8 − (dashed line), also captured by theory; for 5 10-2 10-1 100 1 2 3 4 5 10-2 10-1 100 10-1 100 101 100 101 102 103 104 105 0.5 1 1.5 2 2.5 (a) (b) (c) FIG. 4. Entropy, energy, and code length. (a) Entropy rate in th...
2020
-
[3]
De Giuli, Phys
E. De Giuli, Phys. Rev. Lett.122, 128301 (2019)
2019
-
[4]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[5]
De Giuli, Journal of Physics A: Mathematical and The- oretical52, 504001 (2019)
E. De Giuli, Journal of Physics A: Mathematical and The- oretical52, 504001 (2019)
2019
-
[6]
De Giuli, Journal of Physics A: Mathematical and The- oretical55, 489501 (2022)
E. De Giuli, Journal of Physics A: Mathematical and The- oretical55, 489501 (2022)
2022
-
[7]
Nakaishi and K
K. Nakaishi and K. Hukushima, Physical Review Re- search4, 023156 (2022)
2022
-
[8]
Lalegani and E
F. Lalegani and E. De Giuli, Physical Review E109, 054313 (2024)
2024
-
[9]
H. W. Lin and M. Tegmark, Entropy19, 299 (2017)
2017
-
[10]
Cagnetta, L
F. Cagnetta, L. Petrini, U. M. Tomasini, A. Favero, and M. Wyart, Physical Review X14, 031001 (2024)
2024
-
[11]
Cagnetta and M
F. Cagnetta and M. Wyart, Advances in Neural Informa- tion Processing Systems37, 83119 (2024)
2024
-
[12]
J. Garnier-Brun, M. M´ ezard, E. Moscato, and L. Sagli- etti, arXiv preprint arXiv:2408.15138 (2024)
-
[13]
F. Cagnetta, A. Ravent´ os, S. Ganguli, and M. Wyart, arXiv preprint arXiv:2602.07488 (2026)
-
[14]
Chomsky,Syntactic structures(Walter de Gruyter, Berlin, 2002)
N. Chomsky,Syntactic structures(Walter de Gruyter, Berlin, 2002)
2002
-
[15]
Chomsky,Aspects of the Theory of Syntax, Vol
N. Chomsky,Aspects of the Theory of Syntax, Vol. 11 (MIT press, Cambridge, 2014)
2014
-
[16]
J. E. Hopcroft, R. Motwani, and J. D. Ullman,Intro- duction to automata theory, languages, and computation, 3rd ed. (Pearson, Boston, Ma, 2007)
2007
-
[17]
Derrida, Physical Review Letters45, 79 (1980)
B. Derrida, Physical Review Letters45, 79 (1980)
1980
-
[18]
Derrida, Phys
B. Derrida, Phys. Rev. B24, 2613 (1981)
1981
-
[19]
H. S. Heaps,Information retrieval: Computational and theoretical aspects(Academic Press, Inc., 1978)
1978
-
[20]
C. Scheibner, L. M. Smith, and W. Bialek, arXiv preprint arXiv:2512.24969 (2025)
-
[21]
Scaling limit of the Random Language Model,
E. De Giuli, “Scaling limit of the Random Language Model,” (2026)
2026
-
[22]
M´ ezard and A
M. M´ ezard and A. Montanari,Information, physics, and computation(Oxford University Press, 2009)
2009
-
[23]
M´ ezard, G
M. M´ ezard, G. Parisi, and R. Zecchina, Science297, 812 (2002)
2002
-
[24]
Braunstein, M
A. Braunstein, M. M´ ezard, and R. Zecchina, Random Structures & Algorithms27, 201 (2005)
2005
-
[25]
Braunstein and R
A. Braunstein and R. Zecchina, Physical review letters 96, 030201 (2006)
2006
-
[26]
Zdeborov´ a and F
L. Zdeborov´ a and F. Krzkala, Physical Review E—Statistical, Nonlinear, and Soft Matter Physics76, 031131 (2007)
2007
-
[27]
Decelle, F
A. Decelle, F. Krzakala, C. Moore, and L. Zdeborov´ a, Physical Review Letters107, 065701 (2011)
2011
-
[28]
Krzakala, M
F. Krzakala, M. M´ ezard, F. Sausset, Y. Sun, and L. Zde- borov´ a, Physical Review X2, 021005 (2012)
2012
-
[29]
Zdeborov´ a and F
L. Zdeborov´ a and F. Krzakala, Advances in Physics65, 453 (2016)
2016
-
[30]
Ben Arous, L
G. Ben Arous, L. V. Bogachev, and S. A. Molchanov, Probability theory and related fields132, 579 (2005)
2005
-
[31]
J. M. Kosterlitz and D. J. Thouless, Journal of Physics C: Solid State Physics6, 1181 (1973)
1973
-
[32]
Kosterlitz, Journal of Physics C: Solid State Physics7, 1046 (1974)
J. Kosterlitz, Journal of Physics C: Solid State Physics7, 1046 (1974)
1974
-
[33]
A. M. Petersen, J. N. Tenenbaum, S. Havlin, H. E. Stan- ley, and M. Perc, Scientific reports2, 943 (2012)
2012
-
[34]
G. K. Zipf,The psycho-biology of language: An introduc- tion to dynamic philology(Routledge, Milton Park, 2013)
2013
-
[35]
Ferrer i Cancho and R
R. Ferrer i Cancho and R. V. Sol´ e, Journal of Quantitative Linguistics8, 165 (2001)
2001
-
[36]
Corominas-Murtra and R
B. Corominas-Murtra and R. V. Sol´ e, Physical Review E 82, 011102 (2010)
2010
-
[37]
Corral, G
A. Corral, G. Boleda, and R. Ferrer-i Cancho, PloS one 10, e0129031 (2015)
2015
-
[38]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y. Gu, S. Huang, and M. Jordan, arXiv preprint arXiv:2501.00656 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Nakaishi and K
K. Nakaishi and K. Hukushima, Physical Review Re- search6, 033216 (2024)
2024
-
[40]
Y. Toji, J. Takahashi, V. Roychowdhury, and H. Miya- hara, Physical Review E113, 015305 (2026)
2026
-
[41]
T. M. Cover and J. A. Thomas,Elements of information theory(John Wiley & Sons, 1999)
1999
-
[42]
Entropy Estimates from Insufficient Samplings
P. Grassberger, arXiv preprint physics/0307138 (2003)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[43]
Sch¨ urmann and P
T. Sch¨ urmann and P. Grassberger, Chaos: An Interdisci- plinary Journal of Nonlinear Science6, 414 (1996). END MA TTER Combinatorics:Here we outline the combinatorics of patterns; for a complete treatment, including surface terms, see [19]. First choose the symbols used by the pbranching rules; this gives N 3 p ∼N 3p/p! ifN 3 ≫p. Then distribute these ac...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.