Second-Order KKT Guarantees for Bregman ADMM in Nonconvex and Non-Lipschitz Optimization
Pith reviewed 2026-06-29 02:29 UTC · model grok-4.3
The pith
Bregman ADMM iterates from random initialization converge to strict saddles with probability zero under two-sided relative smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On an invariant open state-space domain, one iteration of Bregman ADMM defines a smooth primal-dual fixed-point map whose strict-saddle KKT points are unstable fixed points; consequently, from random initialization the iterates converge to a strict saddle with probability zero. Combined with existing first-order convergence results, this yields almost-sure second-order stationarity of limiting KKT points.
What carries the argument
The smooth primal-dual fixed-point map realized by one Bregman ADMM iteration, whose instability at strict saddles follows from a determinant reduction that uses Bregman-specific symmetrization and scaling together with null-space cancellation on the star graph.
If this is right
- Limiting KKT points satisfy second-order stationarity with probability one.
- The same conclusion holds for the multi-block star-consensus formulation of distributed optimization.
- The guarantees apply to polynomial objectives in matrix and tensor models that lack a global Lipschitz constant.
Where Pith is reading between the lines
- The instability technique may extend to other Bregman proximal splitting schemes outside the ADMM setting.
- Empirical frequency of saddle avoidance on large tensor-factorization instances would provide a practical check on the measure-zero result.
- The relative-smoothness condition suggests analogous second-order results for other non-Lipschitz nonconvex problems in signal processing.
Load-bearing premise
An invariant open state-space domain exists on which a single Bregman ADMM step produces a smooth primal-dual fixed-point map.
What would settle it
Numerical runs from many independent random initial points that reach a strict-saddle KKT point with positive frequency would contradict the probability-zero claim.
Figures
read the original abstract
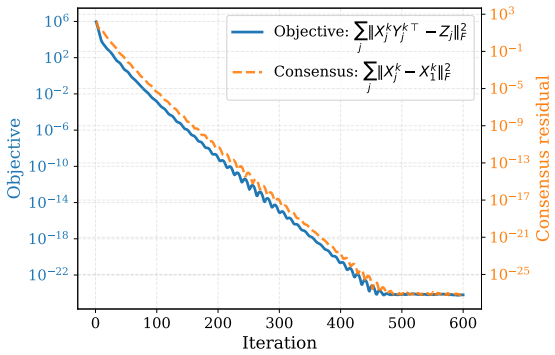
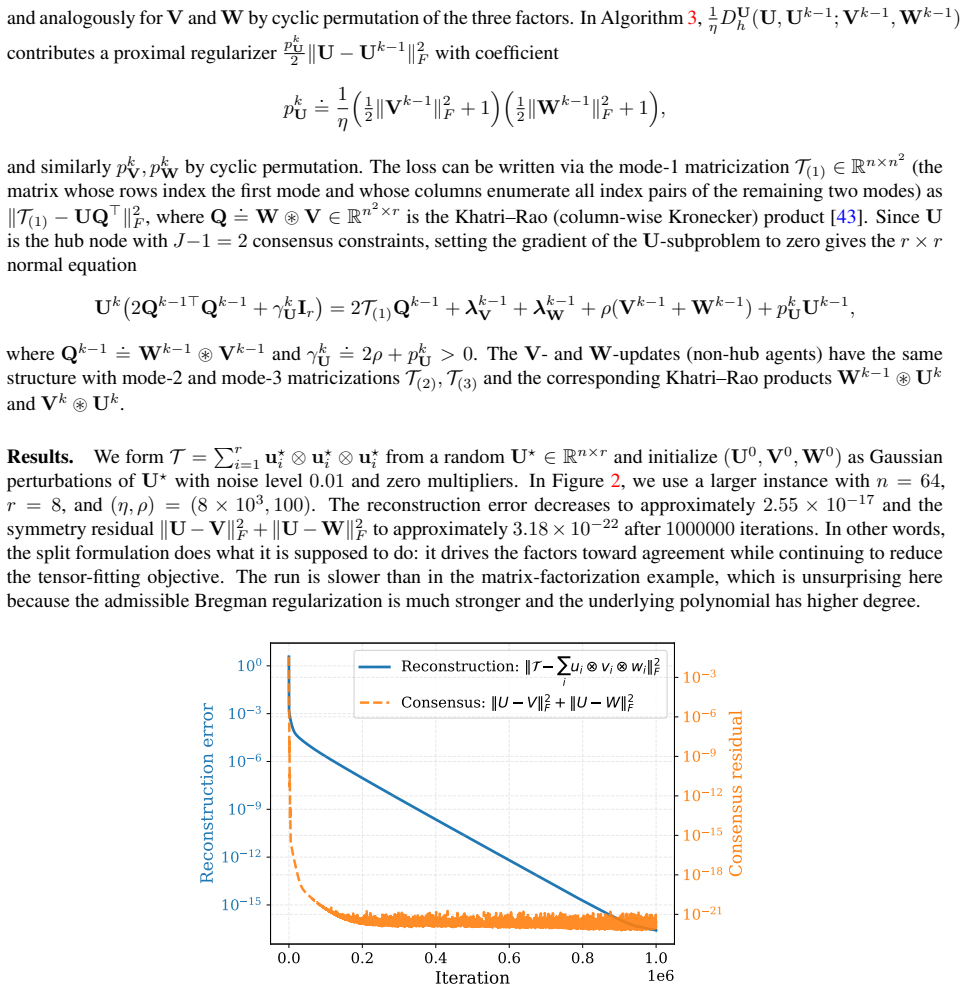
We analyze Bregman ADMM for nonconvex linearly constrained problems under two-sided relative smoothness, a condition that replaces the standard Lipschitz gradient assumption with a Hessian comparison relative to a Bregman kernel. This setting covers polynomial objectives arising in matrix and tensor models for which a global Lipschitz-gradient constant need not exist. We show that on an invariant open state-space domain, one iteration of Bregman ADMM defines a smooth primal--dual fixed-point map whose strict-saddle KKT points are unstable fixed points; consequently, from random initialization the iterates converge to a strict saddle with probability zero. Combined with existing first-order convergence results, this yields almost-sure second-order stationarity of limiting KKT points. We extend the analysis to a multi-block star consensus formulation for distributed optimization. The technical novelty lies in a determinant reduction with a Bregman-specific symmetrization and scaling step in the two block spectral argument, together with a null space cancellation exploiting the star graph structure in the consensus case. Numerical experiments on distributed matrix factorization illustrate the theory, and a symmetric tensor factorization example demonstrates the broader Bregman proximal splitting idea beyond the separable consensus setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes Bregman ADMM for nonconvex linearly constrained problems under two-sided relative smoothness (replacing global Lipschitz gradients). It claims that on an invariant open state-space domain, one iteration defines a C^1 primal-dual fixed-point map T whose strict-saddle KKT points are hyperbolic unstable fixed points; by the stable-manifold theorem, random initialization yields convergence to strict saddles with probability zero. Combined with existing first-order convergence results, this implies almost-sure second-order stationarity of limiting KKT points. The analysis extends to a multi-block star-consensus formulation, with technical novelty in a determinant reduction, Bregman-specific symmetrization/scaling, and star-graph null-space cancellation. Numerical experiments on distributed matrix factorization and symmetric tensor factorization are included.
Significance. If the invariant-domain construction and invariance of T hold, the result supplies second-order stationarity guarantees for Bregman proximal methods in non-Lipschitz settings (e.g., polynomial objectives in matrix/tensor models) where standard Lipschitz-based analyses fail. The work credits existing first-order results and supplies a concrete spectral argument (determinant reduction plus Bregman symmetrization) that is specific to the Bregman kernel; the star-graph extension is a useful distributed-optimization contribution. The absence of global Lipschitz assumptions broadens applicability beyond classical ADMM theory.
major comments (2)
- [§3] §3 (state-space domain and fixed-point map): The central probability-zero claim rests on the existence of an explicitly constructed open invariant domain D on which the Bregman ADMM operator T is C^1 and T(D) ⊆ D. The manuscript asserts this under two-sided relative smoothness but does not provide a concrete construction or proof that invariance survives when proximal mappings can drive iterates toward singularities or infinity (the precise setting where global Lipschitz fails). Without this, the stable-manifold argument does not apply to sequences generated from random initialization, even if first-order convergence holds separately.
- [§4.2] §4.2 (two-block spectral argument): The instability claim for strict saddles relies on a determinant reduction combined with Bregman symmetrization and scaling. The reduction is stated to be parameter-free after scaling, yet the scaling factor appears to depend on the local Hessian comparison constants from the two-sided relative smoothness assumption; this dependence must be verified to ensure the sign of the determinant is independent of the particular Bregman kernel.
minor comments (2)
- [§2] Notation for the Bregman kernel and its conjugate should be introduced once with a single consistent symbol rather than alternating between φ and D_φ in the fixed-point map definition.
- [Figure 1] Figure 1 (phase portrait) would benefit from an explicit overlay of the claimed invariant domain boundary to illustrate that random initializations remain inside D.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments on the invariant-domain construction and the spectral analysis. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [§3] §3 (state-space domain and fixed-point map): The central probability-zero claim rests on the existence of an explicitly constructed open invariant domain D on which the Bregman ADMM operator T is C^1 and T(D) ⊆ D. The manuscript asserts this under two-sided relative smoothness but does not provide a concrete construction or proof that invariance survives when proximal mappings can drive iterates toward singularities or infinity (the precise setting where global Lipschitz fails). Without this, the stable-manifold argument does not apply to sequences generated from random initialization, even if first-order convergence holds separately.
Authors: We agree that an explicit construction of the open invariant domain D and a self-contained proof of its invariance under T are necessary for the stable-manifold argument to apply rigorously to random initializations. In the revised manuscript we will add a new subsection in §3 that constructs D explicitly as the set of primal-dual points whose Bregman divergences to the constraint set remain bounded by a constant derived from the two-sided relative smoothness parameters. We will prove T(D)⊆D by showing that the Bregman proximal mappings cannot escape D in one step, using the relative smoothness inequality to control the growth near singularities and at infinity. This construction ensures T is C^1 on D and that the stable-manifold theorem applies directly to trajectories starting in D. revision: yes
-
Referee: [§4.2] §4.2 (two-block spectral argument): The instability claim for strict saddles relies on a determinant reduction combined with Bregman symmetrization and scaling. The reduction is stated to be parameter-free after scaling, yet the scaling factor appears to depend on the local Hessian comparison constants from the two-sided relative smoothness assumption; this dependence must be verified to ensure the sign of the determinant is independent of the particular Bregman kernel.
Authors: We thank the referee for this observation. The scaling is chosen exactly as the ratio of the two relative-smoothness constants appearing in the Hessian comparison; after this normalization the reduced matrix whose determinant is computed has eigenvalues whose signs are controlled solely by the strict-saddle condition and are therefore independent of the specific Bregman kernel. In the revision we will insert an explicit algebraic verification of this independence immediately after the determinant-reduction step in §4.2, including the intermediate matrix expressions before and after scaling. revision: yes
Circularity Check
No circularity: derivation is a self-contained mathematical argument combining new spectral analysis with external first-order results.
full rationale
The paper's core argument establishes an invariant open domain on which Bregman ADMM yields a C^1 fixed-point map, applies a determinant-reduction + symmetrization argument to show strict saddles are unstable, invokes the stable-manifold theorem for measure-zero convergence, and combines the result with separately existing first-order convergence theorems. None of these steps reduce to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain; the technical novelty (Bregman symmetrization, star-graph cancellation) is presented as new algebraic manipulation inside the proof. The abstract explicitly separates the new second-order contribution from the cited first-order results, satisfying the criteria for an independent derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Two-sided relative smoothness with respect to a Bregman kernel
- domain assumption Existence of an invariant open state-space domain
Reference graph
Works this paper leans on
-
[1]
Glowinski and A
R. Glowinski and A. Marroco. Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de Dirichlet non linéaires.Revue française d’automatique, in- formatique, recherche opérationnelle. Analyse numérique, 9(R2):41–76, 1975
1975
-
[2]
A dual algorithm for the solution of nonlinear variational problems via finite element approximation.Computers & Mathematics with Applications, 2(1):17–40, 1976
Daniel Gabay and Bertrand Mercier. A dual algorithm for the solution of nonlinear variational problems via finite element approximation.Computers & Mathematics with Applications, 2(1):17–40, 1976
1976
-
[3]
Proximal alternating directions method for structured variational inequalities.Journal of Optimization Theory and Applications, 134(1):107–117, 2007
MH Xu. Proximal alternating directions method for structured variational inequalities.Journal of Optimization Theory and Applications, 134(1):107–117, 2007
2007
-
[4]
Max L. N. Goncalves, Jefferson G. Melo, and Renato D. C. Monteiro. Convergence rate bounds for a proximal ADMM with over-relaxation stepsize parameter for solving nonconvex linearly constrained problems, 2017
2017
-
[5]
Gradient primal-dual algorithm converges to second-order stationary solution for nonconvex distributed optimization over networks
Mingyi Hong, Meisam Razaviyayn, and Jason Lee. Gradient primal-dual algorithm converges to second-order stationary solution for nonconvex distributed optimization over networks. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 2009–2...
2009
-
[6]
An alternating direction algorithm for matrix completion with nonnegative factors.Frontiers of Mathematics in China, 7(2):365–384, 2012
Yangyang Xu, Wotao Yin, Zaiwen Wen, and Yin Zhang. An alternating direction algorithm for matrix completion with nonnegative factors.Frontiers of Mathematics in China, 7(2):365–384, 2012
2012
-
[7]
Distributed optimization and statistical learning via the alternating direction method of multipliers.Foundations and Trends® in Machine learning, 3(1):1–122, 2011
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, Jonathan Eckstein, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers.Foundations and Trends® in Machine learning, 3(1):1–122, 2011
2011
-
[8]
Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems.SIAM Journal on Optimization, 26(1):337–364, 2016
Mingyi Hong, Zhi-Quan Luo, and Meisam Razaviyayn. Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems.SIAM Journal on Optimization, 26(1):337–364, 2016
2016
-
[9]
Convergence of Bregman alternating direction method with multipliers for nonconvex composite problems, 2014
Fenghui Wang, Zongben Xu, and Hong-Kun Xu. Convergence of Bregman alternating direction method with multipliers for nonconvex composite problems, 2014
2014
-
[10]
Global convergence of ADMM in nonconvex nonsmooth optimization
Yu Wang, Wotao Yin, and Jinshan Zeng. Global convergence of ADMM in nonconvex nonsmooth optimization. Journal of Scientific Computing, 78:29–63, 2019
2019
-
[11]
Rina Foygel Barber and Emil Y . Sidky. Convergence for nonconvex ADMM, with applications to CT imaging. Journal of Machine Learning Research, 25(38):1–46, 2024. 18
2024
-
[12]
A decentralized primal-dual framework for non-convex smooth consensus optimization.IEEE Transactions on Signal Processing, 71:525–538, 2023
Gabriel Mancino-Ball, Yangyang Xu, and Jie Chen. A decentralized primal-dual framework for non-convex smooth consensus optimization.IEEE Transactions on Signal Processing, 71:525–538, 2023
2023
-
[13]
Matrix completion has no spurious local minimum
Rong Ge, Jason D Lee, and Tengyu Ma. Matrix completion has no spurious local minimum. InAdvances in Neural Information Processing Systems 29, pages 2973–2981, 2016
2016
-
[14]
Escaping from saddle points—online stochastic gradient for tensor decomposition
Rong Ge, Furong Huang, Chi Jin, and Yang Yuan. Escaping from saddle points—online stochastic gradient for tensor decomposition. InConference on Learning Theory, pages 797–842, 2015
2015
-
[15]
Springer Science & Business Media, 2013
Michael Shub.Global stability of dynamical systems. Springer Science & Business Media, 2013
2013
-
[16]
First-order methods almost always avoid saddle points: The case of vanishing step sizes
Ioannis Panageas, Georgios Piliouras, and Xiao Wang. First-order methods almost always avoid saddle points: The case of vanishing step sizes. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[17]
Proximal methods avoid active strict saddles of weakly convex func- tions.Foundations of Computational Mathematics, 22(2):561–606, 2022
Damek Davis and Dmitriy Drusvyatskiy. Proximal methods avoid active strict saddles of weakly convex func- tions.Foundations of Computational Mathematics, 22(2):561–606, 2022
2022
-
[18]
A descent lemma beyond Lipschitz gradient continuity: First-order methods revisited and applications.Mathematics of Operations Research, 42(2):330–348, 2016
Heinz H Bauschke, Jérôme Bolte, and Marc Teboulle. A descent lemma beyond Lipschitz gradient continuity: First-order methods revisited and applications.Mathematics of Operations Research, 42(2):330–348, 2016
2016
-
[19]
First order methods beyond convexity and Lipschitz gradient continuity with applications to quadratic inverse problems.SIAM Journal on Optimization, 28(3):2131–2151, 2018
Jérôme Bolte, Shoham Sabach, Marc Teboulle, and Yakov Vaisbourd. First order methods beyond convexity and Lipschitz gradient continuity with applications to quadratic inverse problems.SIAM Journal on Optimization, 28(3):2131–2151, 2018
2018
-
[20]
An iterative row-action method for interval convex programming.Journal of Optimization theory and Applications, 34(3):321–353, 1981
Yair Censor and Arnold Lent. An iterative row-action method for interval convex programming.Journal of Optimization theory and Applications, 34(3):321–353, 1981
1981
-
[21]
Lev M Bregman. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming.USSR computational mathematics and mathematical physics, 7(3):200–217, 1967
1967
-
[22]
Convergence of multi-block Bregman ADMM for nonconvex composite problems.Science China Information Sciences, 61(12):122101, 2018
Fenghui Wang, Wenfei Cao, and Zongben Xu. Convergence of multi-block Bregman ADMM for nonconvex composite problems.Science China Information Sciences, 61(12):122101, 2018
2018
-
[23]
Bregman alternating direction method of multipliers
Huahua Wang and Arindam Banerjee. Bregman alternating direction method of multipliers. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014
2014
-
[24]
Peng-Jie Liu, Jin-Bao Jian, Hu Shao, Xiao-Quan Wang, Jia-Wei Xu, and Xiao-Yu Wu. A Bregman-style im- proved ADMM and its linearized version in the nonconvex setting: Convergence and rate analyses.Journal of the Operations Research Society of China, 12(2):298–340, 2024
2024
-
[25]
Dao, Andrew Eberhard, and Nargiz Sultanova
Tan Nhat Pham, Minh N. Dao, Andrew Eberhard, and Nargiz Sultanova. Bregman proximal linearized ADMM for minimizing separable sums coupled by a difference of functions.Journal of Optimization Theory and Appli- cations, 203(2):1622–1658, 2024
2024
-
[26]
Distributed multi-block partially symmetric Bregman ADMM for nonconvex and nonsmooth sharing problem.Journal of the Operations Research Society of China, 2025
Tian-Tian Cui, Ya-Zheng Dang, and Yan Gao. Distributed multi-block partially symmetric Bregman ADMM for nonconvex and nonsmooth sharing problem.Journal of the Operations Research Society of China, 2025
2025
-
[27]
A note on the second-order convergence of proximal ADMM for non-convex optimization.Journal of Optimization Theory and Applications, 209(1):1–17, April 2026
Jingyu Gao and Xiurui Geng. A note on the second-order convergence of proximal ADMM for non-convex optimization.Journal of Optimization Theory and Applications, 209(1):1–17, April 2026
2026
-
[28]
Qiuwei Li, Zhihui Zhu, Gongguo Tang, and Michael B. Wakin. Provable Bregman-divergence based methods for nonconvex and non-Lipschitz problems, 2019. arXiv preprint arXiv:1904.09712
Pith/arXiv arXiv 2019
-
[29]
The geometry of equality-constrained global consensus problems
Qiuwei Li, Zhihui Zhu, Gongguo Tang, and Michael B Wakin. The geometry of equality-constrained global consensus problems. InICASSP, pages 7928–7932, 2019
2019
-
[30]
Distributed low-rank matrix factorization with exact consensus.Advances in Neural Information Processing Systems, 32, 2019
Zhihui Zhu, Qiuwei Li, Xinshuo Yang, Gongguo Tang, and Michael B Wakin. Distributed low-rank matrix factorization with exact consensus.Advances in Neural Information Processing Systems, 32, 2019. 19
2019
-
[31]
First-order methods almost always avoid strict saddle points.Mathematical Programming, 176(1–2):311–337, 2019
Jason D Lee, Ioannis Panageas, Georgios Piliouras, Max Simchowitz, Michael I Jordan, and Benjamin Recht. First-order methods almost always avoid strict saddle points.Mathematical Programming, 176(1–2):311–337, 2019
2019
-
[32]
Introduction to the implicit function theorem
Steven G Krantz and Harold R Parks. Introduction to the implicit function theorem. InThe Implicit Function Theorem, pages 1–12. Springer, 2003
2003
-
[33]
Springer Science & Business Media, 2013
Tosio Kato.Perturbation theory for linear operators, volume 132. Springer Science & Business Media, 2013
2013
-
[34]
On nonconvex decentralized gradient descent.IEEE Signal Process., 66(11):2834– 2848, 2018
Jinshan Zeng and Wotao Yin. On nonconvex decentralized gradient descent.IEEE Signal Process., 66(11):2834– 2848, 2018
2018
-
[35]
EXTRA: An exact first-order algorithm for decentralized con- sensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
Wei Shi, Qing Ling, Gang Wu, and Wotao Yin. EXTRA: An exact first-order algorithm for decentralized con- sensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
2015
-
[36]
Learning deep models: Critical points and local openness.INFORMS Journal on Optimization, 4(2):148–173, 2022
Maher Nouiehed and Meisam Razaviyayn. Learning deep models: Critical points and local openness.INFORMS Journal on Optimization, 4(2):148–173, 2022
2022
-
[37]
Tensor decompositions and applications.SIAM review, 51(3):455–500, 2009
Tamara G Kolda and Brett W Bader. Tensor decompositions and applications.SIAM review, 51(3):455–500, 2009
2009
-
[38]
Symmetric tensors and symmetric tensor rank.SIAM Journal on Matrix Analysis and Applications, 30(3):1254–1279, 2008
Pierre Comon, Gene Golub, Lek-Heng Lim, and Bernard Mourrain. Symmetric tensors and symmetric tensor rank.SIAM Journal on Matrix Analysis and Applications, 30(3):1254–1279, 2008
2008
-
[39]
Tensor decompositions for learning latent variable models.Journal of Machine Learning Research, 15(1):2773–2832, 2014
Animashree Anandkumar, Rong Ge, Daniel Hsu, Sham M Kakade, and Matus Telgarsky. Tensor decompositions for learning latent variable models.Journal of Machine Learning Research, 15(1):2773–2832, 2014
2014
-
[40]
Local and global convergence of general Burer-Monteiro tensor optimizations.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 36(9):10266–10274, 2022
Shuang Li and Qiuwei Li. Local and global convergence of general Burer-Monteiro tensor optimizations.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 36(9):10266–10274, 2022
2022
-
[41]
Numerical optimization for symmetric tensor decomposition.Mathematical Programming, 151(1):225–248, 2015
Tamara G Kolda. Numerical optimization for symmetric tensor decomposition.Mathematical Programming, 151(1):225–248, 2015
2015
-
[42]
Structured data fusion.IEEE Journal of Selected Topics in Signal Processing, 9(4):586–600, 2015
Laurent Sorber, Marc Van Barel, and Lieven De Lathauwer. Structured data fusion.IEEE Journal of Selected Topics in Signal Processing, 9(4):586–600, 2015
2015
-
[43]
Hadamard, khatri-rao, kronecker and other matrix products.International Journal of Information and Systems Sciences, 4(1):160–177, 2008
Shuangzhe Liu and Goetz Trenkler. Hadamard, khatri-rao, kronecker and other matrix products.International Journal of Information and Systems Sciences, 4(1):160–177, 2008. 20 APPENDIX A Proof of Theorem 3.1 Proof of Theorem 3.1.We verify the two conditions of Theorem 5.1:det(Dg)̸= 0everywhere, and every strict-saddle KKT point inΩis an unstable fixed point...
2008
-
[44]
We showα=β=γ=0. Observe that Dg1(x,y,λ) α β γ =0⇐ ⇒ ∇xx+ ∇yx+ ∇λx+ Im Ip α β γ = 0 0 0 =⇒β=0,γ=0,∇ xx+ α=0=⇒α=0 where the last step uses the nonsingularity, for every state inΩ, of ∇xx+ = ∇2f1(x+) +ρA ⊤A+ 1 η ∇2h1(x+) −1 1 η ∇2h1(x) , which follows from relative smoothness: the first factor is nonsingular by the positive de...
-
[45]
Then there existd x,d 1 y,d 2 y,d 3 y such that x⋆ 1 =x ⋆ 2 =x ⋆ 3, ∇xf1(x⋆ 1,y ⋆ 1)−λ ⋆ 2 −λ ⋆ 3 =0, ∇xf2(x⋆ 2,y ⋆
-
[46]
+λ ⋆ 2 =0, ∇xf3(x⋆ 3,y ⋆
-
[47]
It remains to show that the spectral radius ofDg(x ⋆ 1,y ⋆ 1,x ⋆ 2,y ⋆ 2,x ⋆ 3,y ⋆ 3,λ ⋆ 2,λ ⋆ 3)is larger than 1
+λ ⋆ 3 =0, ∇yfj(x⋆ j ,y ⋆ j ) =0,∀j∈ {1,2,3}, (71) 3X i=1 [d⊤ x di⊤ y ]∇2fi(x⋆ i ,y ⋆ i ) dx di y <0.(72) Now,(x ⋆ 1,y ⋆ 1,· · ·,x ⋆ 3,y ⋆ 3,λ ⋆ 2,λ ⋆ 3)is a fixed point ofgsince (71) satisfies the fixed point equations (52)-(59). It remains to show that the spectral radius ofDg(x ⋆ 1,y ⋆ 1,x ⋆ 2,y ⋆ 2,x ⋆ 3,y ⋆ 3,λ ⋆ 2,λ ⋆ 3)is larger than 1. Set (x+ 1 ,...
-
[48]
Therefore the negative-curvature direction from (72) can be chosen with allx-components equal to a commond x. Indeed, the constraintsx j =x 1 forj= 2,3force every feasible perturbation to satisfyδx j =δx 1, so any direction witnessing the strict-saddle condition (72) must already have this equal-xform. Set d= (d x,d 1 y,d x,d 2 y,d x,d 3 y,0,0)̸=0, whered...
-
[49]
Proof.The proof uses exactly the same two ingredients as theJ= 3case
every strict-saddle KKT point of(11)inΩis an unstable fixed point ofg. Proof.The proof uses exactly the same two ingredients as theJ= 3case. Nonsingularity.One full iteration decomposes into2J+ 1elementary maps: onex j-update and oney j-update for each agent, followed by the dual update. Each Jacobian is block triangular with diagonal blocks given by the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.