LEDGER: Scaling Agentic Document Editing with Dependency-aware Graph Retrieval
Pith reviewed 2026-06-30 10:29 UTC · model grok-4.3
The pith
LEDGER builds a lightweight dependency graph to retrieve only relevant context for edits, lifting consistency from 56% to 76% across models while cutting tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
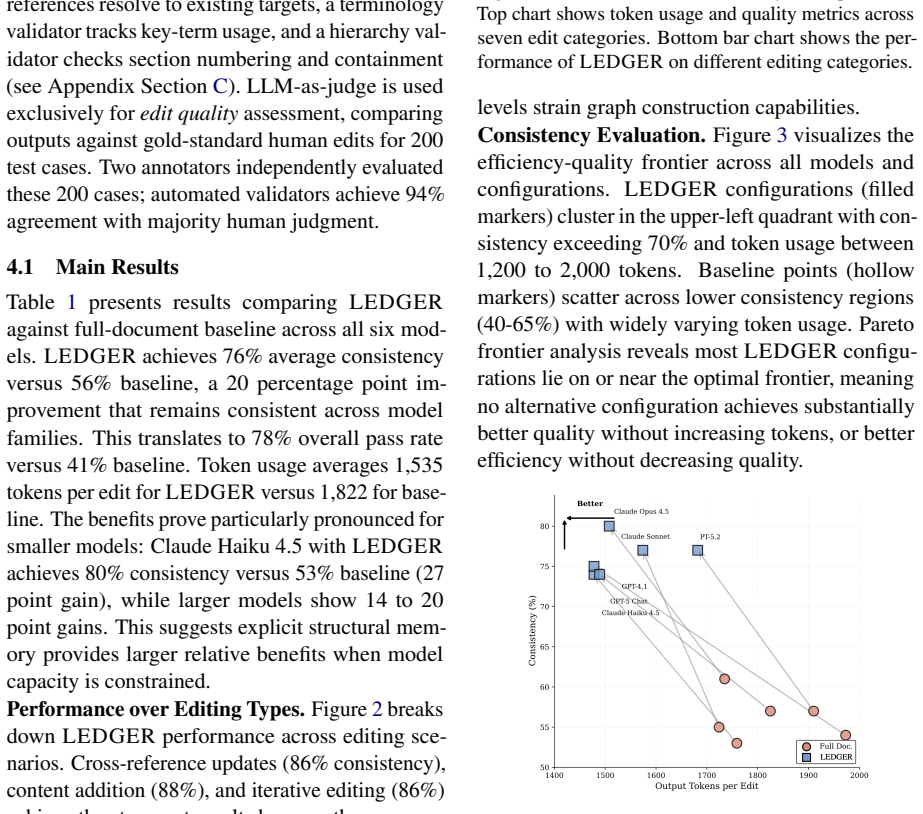
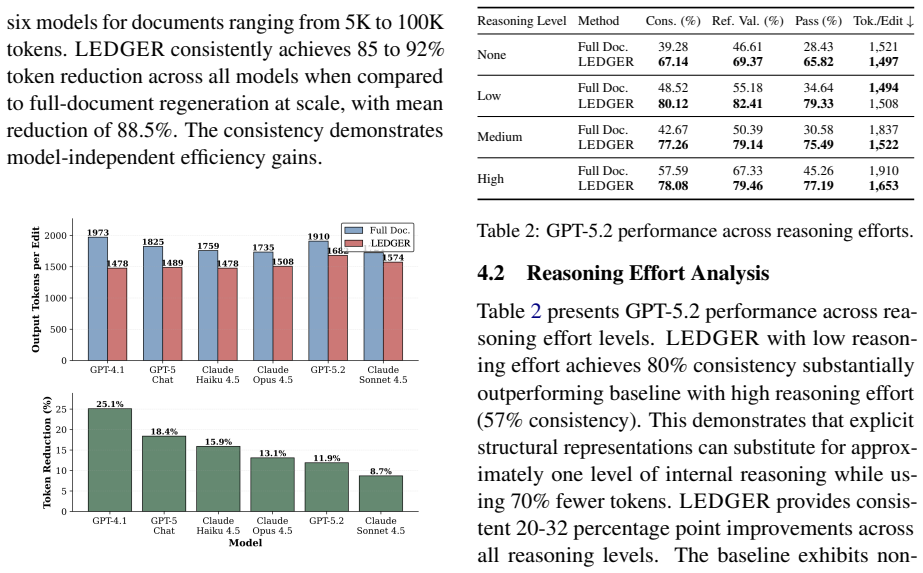
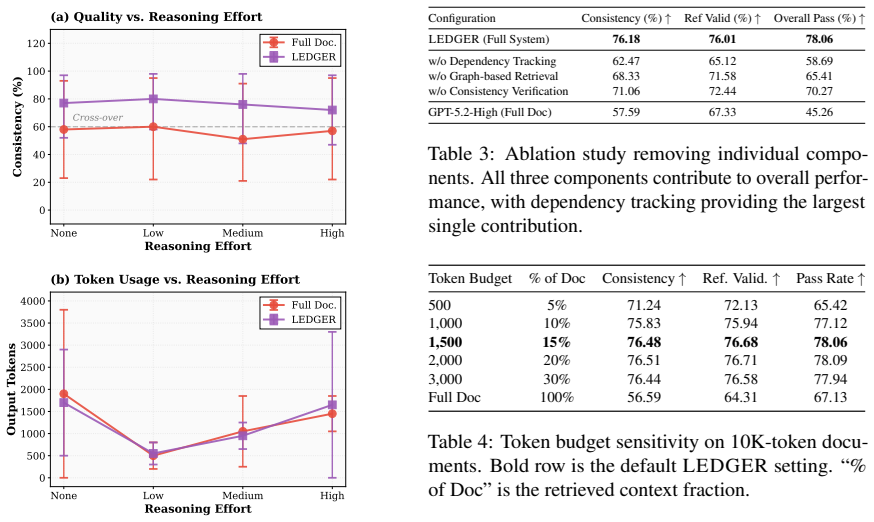
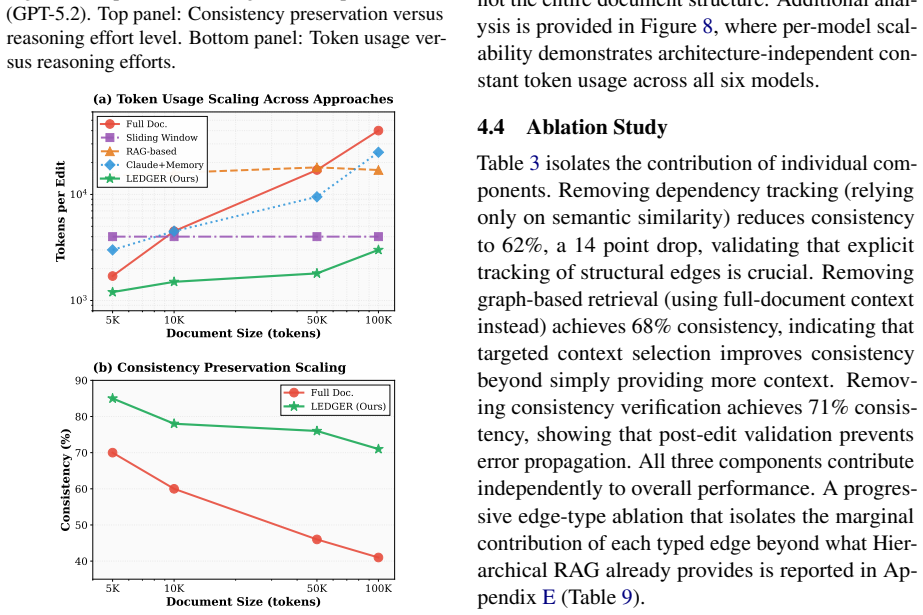
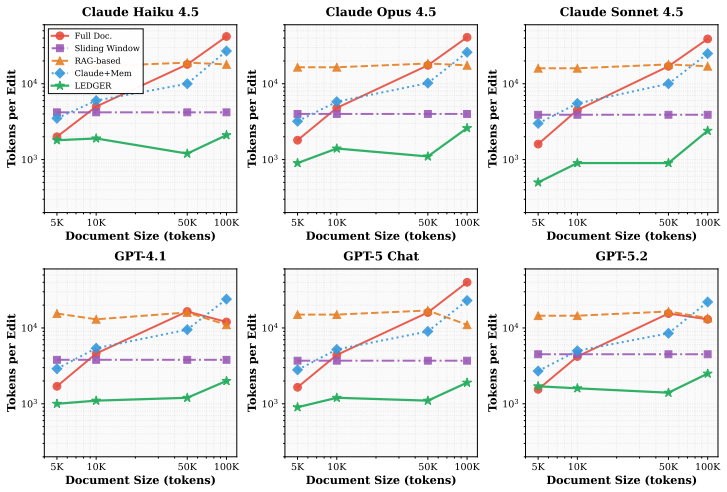
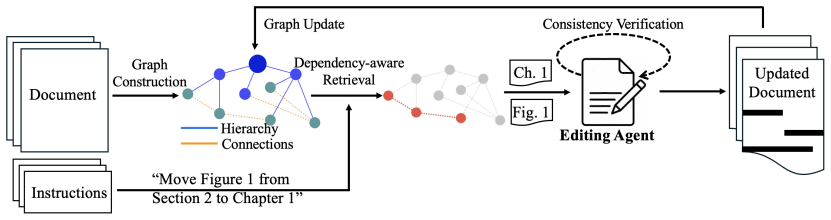
LEDGER constructs a dependency graph that explicitly encodes document hierarchy, explicit references, implicit dependencies, and semantic relationships; graph-guided retrieval then supplies only the minimal context required for each edit, which improves consistency from 56% to 76% across six models while reducing token consumption, and enables low-reasoning-effort runs to equal high-reasoning-effort baselines.
What carries the argument
The dependency graph that models hierarchical organization, explicit references, implicit dependencies, and semantic relationships, then supplies graph-guided retrieval for each edit.
If this is right
- Consistency improves across all tested models and document types when the graph is used for retrieval.
- Token usage drops because only graph-selected context is sent to the model.
- Low-reasoning-effort runs achieve the same quality as high-reasoning-effort baselines.
- Explicit dependency representations can substitute for some internal model reasoning in editing tasks.
Where Pith is reading between the lines
- The same graph construction could be applied to other agentic tasks that require maintaining consistency across long structured outputs, such as code refactoring or legal contract revision.
- If the graph can be updated incrementally after each edit, the method might scale to interactive, multi-turn document workflows without rebuilding the structure each time.
- The approach suggests that lightweight symbolic structures can reduce reliance on expensive model reasoning steps in agent systems more broadly.
Load-bearing premise
The automatically built dependency graph correctly identifies every cross-reference and semantic relationship that matters for consistency and does not introduce construction errors or omit critical links.
What would settle it
A set of edits on documents where the graph misses at least one cross-reference, resulting in a measurable drop in consistency relative to full-document baselines.
Figures
read the original abstract
We introduce LEDGER to tackle the novel context engineering challenge of agentic document editing, where localized edits to long, structured documents must be applied efficiently without breaking cross-references or semantic consistency. LEDGER constructs a lightweight dependency graph that explicitly models document structure, including hierarchical organization, explicit references, implicit dependencies, and semantic relationships. For each edit, graph-guided retrieval selects only the necessary context, avoiding full-document processing while preserving consistency. We evaluate LEDGER on a curated benchmark of 1.9k test cases with various document types and lengths, spanning six state-of-the-art models: LEDGER improves consistency from 56% to 76% across all six models and test scenarios while reducing token usage. Notably, LEDGER with low reasoning effort matches baseline performance at high reasoning effort using fewer tokens, showing that explicit dependency representations can partially substitute for expensive internal reasoning in agentic document editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEDGER, a method for agentic document editing that constructs a lightweight dependency graph modeling hierarchical structure, explicit references, implicit dependencies, and semantic relationships. Graph-guided retrieval then selects minimal context for localized edits. On a curated 1.9k-case benchmark spanning six models and various document types, LEDGER is reported to raise consistency from 56% to 76% while cutting token usage; low-reasoning-effort LEDGER is claimed to match high-reasoning baselines.
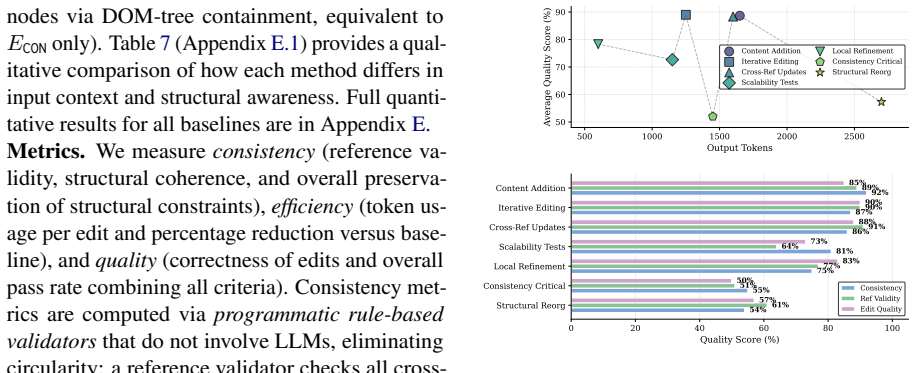
Significance. If the reported gains are reproducible and the graph construction is shown to be reliable, the work would provide a concrete, graph-based alternative to full-context or high-reasoning approaches for maintaining consistency in long structured documents, with direct relevance to document-centric agent systems.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline consistency improvement (56% → 76%) and token-reduction claims rest on a 1.9k-case benchmark whose construction, consistency metric, baseline prompting protocol, and error analysis are not described, rendering the empirical link unverifiable.
- [§3] §3 (Dependency Graph Construction): the central attribution of gains to the graph requires an explicit construction algorithm, validation procedure against ground-truth cross-references, and error analysis; none are supplied, so it is impossible to assess whether omitted links or construction errors undermine the reported improvements.
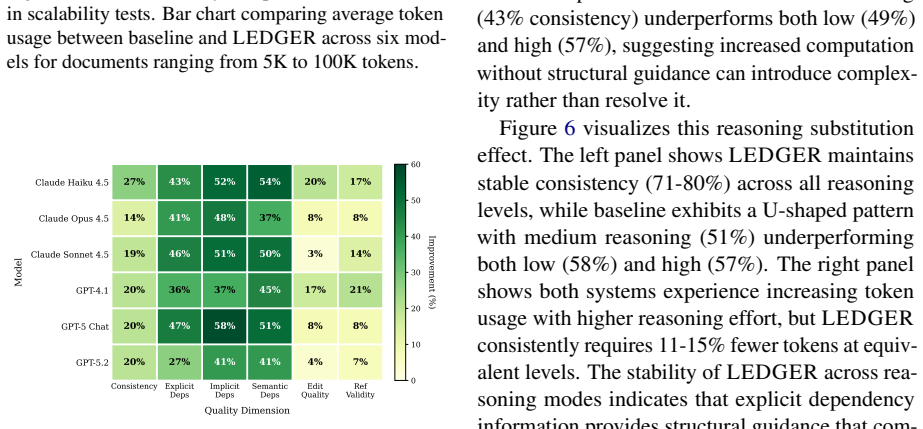
- [Table 1] Table 1 / Results: without per-model, per-scenario breakdowns, statistical significance tests, or ablation of the graph components, the aggregate 56%→76% figure cannot be assessed for robustness across the six models.
minor comments (2)
- [§3] Notation for the dependency graph (nodes, edge types, retrieval function) should be formalized with a small example in §3 to make the retrieval step reproducible.
- [Abstract] The abstract states 'various document types and lengths' but supplies no breakdown by length or type; a supplementary table would clarify coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our empirical evaluation and graph construction details. We address each major comment below and commit to revisions that will strengthen the manuscript's verifiability without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline consistency improvement (56% → 76%) and token-reduction claims rest on a 1.9k-case benchmark whose construction, consistency metric, baseline prompting protocol, and error analysis are not described, rendering the empirical link unverifiable.
Authors: We agree that additional detail is required for full verifiability. The Evaluation section will be expanded in revision to describe the benchmark curation process (including document sampling, edit scenario generation, and ground-truth labeling), the precise definition and computation of the consistency metric, the exact baseline prompting protocols used across models, and a categorized error analysis of failure cases. These additions will directly support the reported 56% to 76% improvement and token reductions. revision: yes
-
Referee: [§3] §3 (Dependency Graph Construction): the central attribution of gains to the graph requires an explicit construction algorithm, validation procedure against ground-truth cross-references, and error analysis; none are supplied, so it is impossible to assess whether omitted links or construction errors undermine the reported improvements.
Authors: We acknowledge that §3 provides a high-level description but lacks the requested explicit elements. In the revised manuscript we will insert a formal algorithm (pseudocode and step-by-step procedure) for constructing the dependency graph from hierarchical structure, explicit references, implicit dependencies, and semantic relationships. We will also add a validation subsection reporting agreement with manually annotated ground-truth cross-references on a held-out subset and an error analysis quantifying the impact of any missed links. revision: yes
-
Referee: [Table 1] Table 1 / Results: without per-model, per-scenario breakdowns, statistical significance tests, or ablation of the graph components, the aggregate 56%→76% figure cannot be assessed for robustness across the six models.
Authors: We agree that aggregate results alone limit assessment of robustness. The revised Table 1 (or supplementary tables) will report per-model and per-scenario consistency and token-usage numbers. We will add statistical significance tests (e.g., paired t-tests or McNemar's test with p-values) comparing LEDGER against baselines. Finally, we will include an ablation study isolating the contribution of each graph component (hierarchical, explicit, implicit, semantic) to the observed gains. revision: yes
Circularity Check
No circularity; empirical evaluation on benchmark with no derivation chain
full rationale
The paper presents LEDGER as an empirical system for agentic document editing that builds a dependency graph and performs graph-guided retrieval, then reports consistency gains (56% to 76%) and token reductions on a 1.9k-case benchmark across six models. No equations, fitted parameters, self-citations, or derivation steps appear in the abstract or description. The central claims rest on direct experimental comparison rather than any reduction of outputs to inputs by construction, self-definition, or self-citation load-bearing. This is the expected non-finding for a purely empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Process- ing Systems, volume 30
Inductive representation learning on large graphs. InAdvances in Neural Information Process- ing Systems, volume 30. Coleman Richard Charles Hooper, Sehoon Kim, Hiva Mohammadzadeh, Monishwaran Maheswaran, Se- bastian Zhao, June Paik, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. 2025. Squeezed atten- tion: Accelerating long context length llm inferen...
2025
-
[2]
Learning semantic similarity.Advances in neural information processing systems, 15. Thomas N Kipf and Max Welling. 2017. Semi- supervised classification with graph convolutional networks. InInternational Conference on Learning Representations. Philippe Laban, Alexander Richard Fabbri, Caiming Xiong, and Chien-Sheng Wu. 2024. Summary of a haystack: A chall...
-
[3]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Reflexion: Language agents with verbal rein- forcement learning. InAdvances in Neural Informa- tion Processing Systems, volume 36. Lin Song, Yukang Chen, Shuai Yang, Xiaohan Ding, Yixiao Ge, Ying-Cong Chen, and Ying Shan. 2024. Low-rank approximation for sparse attention in multi- modal llms. InProceedings of the IEEE/CVF Con- ference on Computer Vision a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Section 2.1
Explicit naming:The substring m must ex- plicitly and unambiguously refer to another document unit by identifier (e.g., section num- ber “Section 2.1”, equation label “Equation 3”, figure caption “Figure 5”, named definition “Theorem 1”)
-
[5]
as shown in Fig- ure 3 above
Minimality:The span m must be minimal – removing any token from m must break the reference. For example, in “as shown in Fig- ure 3 above”, the minimal span is “Figure 3”, not “Figure 3 above”
-
[6]
the matrix operation discussed ear- lier
Surface-level only:Do not infer references that rely on semantic similarity, paraphras- ing, or topic relatedness. Only surface-level, identifier-based references are allowed. For example, “the matrix operation discussed ear- lier” is NOT an explicit reference unless it includes an identifier
-
[7]
The method described in Section 2.1 extends Theorem 4 from (Vaswani et al., 2017)
LaTeX references:Include LaTeX cross- references (e.g., \ref{sec:method}, \eqref{eq:loss}, \cite{smith2020}) as explicit references when the label can be resolved toid j. Output format:Return a set of pairs {(m1,id j1),(m 2,id j2), . . .} where each mk is the minimal substring and idjk is the referenced identi- fier. If no such spans exist, return an empt...
2017
-
[8]
All other units remain available
Counterfactual removal:Consider ui in iso- lation, assuming that uj (and only uj) is re- moved from the document. All other units remain available
-
[9]
Semantic completeness check:Decide whether ui becomes semantically incomplete, ambiguous, or ill-defined due to missing con- tent from uj. Specifically, check if ui relies on: • Definitions or terminology introduced in uj • Mathematical notation or variables de- fined inu j • Assumptions, constraints, or problem setup fromu j Figure 9: LEDGER workflow for...
-
[10]
The dependency must be concrete, not merely topical similarity
Specificity requirement:Identify the specific elements in ui that rely on content introduced in uj. The dependency must be concrete, not merely topical similarity
-
[11]
gradient descent
Generic knowledge exclusion:The depen- dency must not be resolvable by generic back- ground knowledge in the domain. For ex- ample, if ui uses the term “gradient descent” and uj defines it, but gradient descent is com- mon knowledge in machine learning, this does NOT establishr imp(ui, uj)
-
[12]
We define the loss function L(θ) =Pn i=1(yi −f θ(xi))2
Directionality:Verify that the dependency is strictly directional: uj →u i. The relationship cannot be bidirectional or circular. Output format:Return True if all conditions are satisfied, establishing rimp(ui, uj) = 1. Other- wise, return False. If True, also return the specific elements inu i that depend onu j. Example: •u j: “We define the loss functio...
-
[13]
Extract the main claim or thesis of the section (1 sentence)
-
[14]
Identify 2-3 key contributions, findings, or concepts introduced
-
[15]
In this sec- tion
Exclude: Structural markers (“In this sec- tion...”), transitional phrases, citations
-
[16]
Target length: 50-100 tokens For paragraphs (τi =paragraph):
-
[17]
Identify the central idea or main point (1-2 sentences)
-
[18]
Include key technical terms or concepts
-
[19]
Exclude: Supporting details, examples, cita- tions
-
[20]
Target length: 30-50 tokens For figures (τi =figure):
-
[21]
Use the figure caption directly ass i
-
[22]
If caption is very long (>100 tokens), extract the first sentence and key technical terms
-
[23]
graph showing
Include figure type (e.g., “graph showing”, “architecture diagram of”) For tables (τi =table):
-
[24]
Use the table caption ass i
-
[25]
Perfor- mance comparison of methods on datasets
If caption is uninformative, describe what is being compared or measured (e.g., “Perfor- mance comparison of methods on datasets”)
-
[26]
Include column/row headers if they convey key concepts For equations (τi =equation):
-
[27]
Extract any accompanying description or in- line explanation
-
[28]
optimization objective
If no description exists, describe the equation type (e.g., “optimization objective”, “proba- bility distribution”)
-
[29]
Novel attention mechanism using multi-head cross-attention over encoder and decoder states, improving transformer perfor- mance
Target length: 20-40 tokens Output format:Return summary si as a coher- ent text string. The embedding ei =Embed(s i) is computed from this summary. Semantic edge creation:After computing em- beddings for all units, create edge(vi, vj,RELATED) when: • sim(ei, ej) = ei·ej ∥ei∥∥ej ∥ > θwhereθ= 0.7 •(v i, vj)/∈EREF ∪E DEP (not already connected by explicit o...
-
[30]
Referential Integrity:All explicit citations to Theorem 2 now correctly describe the O(1) bound
-
[31]
Semantic Coherence:Algorithm design and case study sections align with the tightened theoretical guarantee
-
[32]
Proof Validity:Proof outline mecha- nism (potential-based charging) supports the stronger constant bound
-
[33]
constant additive gap
Terminology Consistency:Uniform use of “constant additive gap” and “ O(1) bound” throughout dependent sections The edit preserves document flow while imple- menting a substantial theoretical improvement that cascades through algorithm description, empirical validation, and discussion sections—demonstrating LEDGER’s capability to maintain consistency in co...
-
[34]
see Section 4
Consistency preservation:We compute three sub-metrics: (a)Reference validitychecks whether all cross-references resolve correctly after edits (e.g., “see Section 4” still points to an existing Sec- tion 4), (b)Terminology consistencyverifies that all usages of modified terms or definitions remain aligned, and (c)Semantic coherenceensures no contradictions...
-
[35]
For scalability tests, we addition- ally compute the scaling coefficient by fitting token usage as a function of document size and verifying it approachesO(1)rather thanO(|D|)
Token efficiency:We measure tokens per edit as the sum of input context tokens (document content provided to the LLM) and output tokens (generated modifications). For scalability tests, we addition- ally compute the scaling coefficient by fitting token usage as a function of document size and verifying it approachesO(1)rather thanO(|D|)
-
[36]
A subset of 200 test cases in- cludes human-annotated gold-standard edits for validation
Edit quality:We assess whether modifications correctly address the instruction using LLM-as- judge evaluation. A subset of 200 test cases in- cludes human-annotated gold-standard edits for validation. Quality is measured as the percentage of test cases where the edit satisfies the instruction without introducing errors
-
[37]
Section X
Overall pass rate:We compute the percent- age of test cases passing all criteria (consistency, efficiency within expected bounds, and quality), representing end-to-end system reliability. Automated validation:We implement program- matic validators for consistency metrics: • Reference validator:Parses all cross- references (“Section X”, “Figure Y”, “Theo- ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.