When AI Reviews Its Own Code: Recursive Self-Training Collapse in Code LLMs
Pith reviewed 2026-06-30 01:27 UTC · model grok-4.3
The pith
AI self-review of code LLMs degenerates into rubber-stamp approval under recursive training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
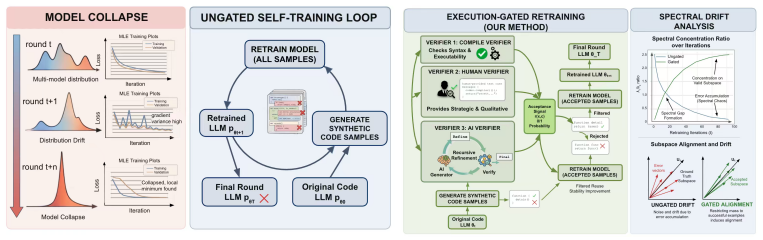
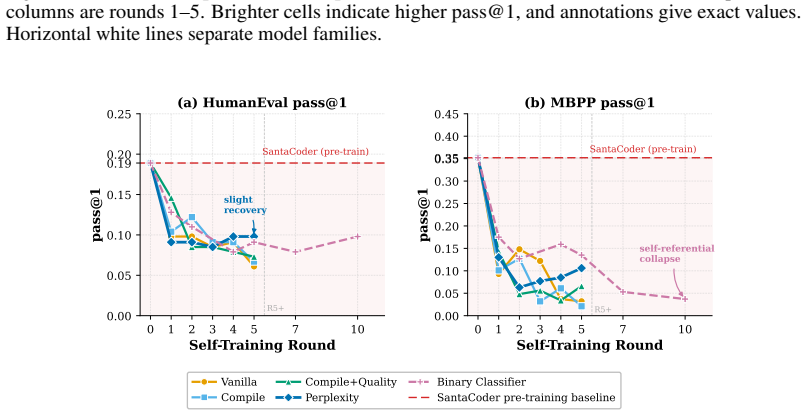
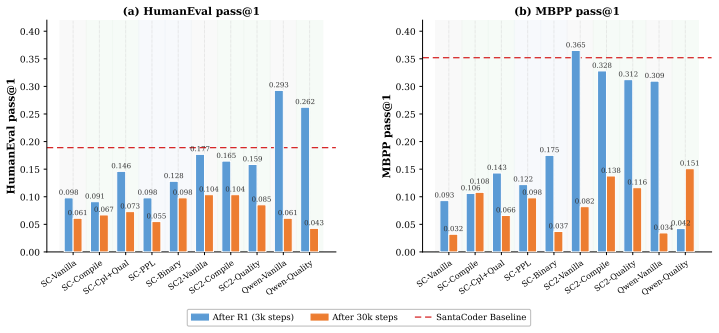
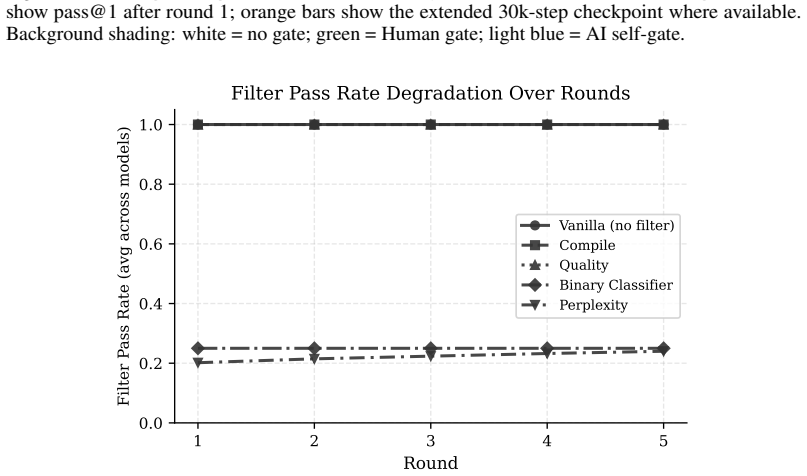
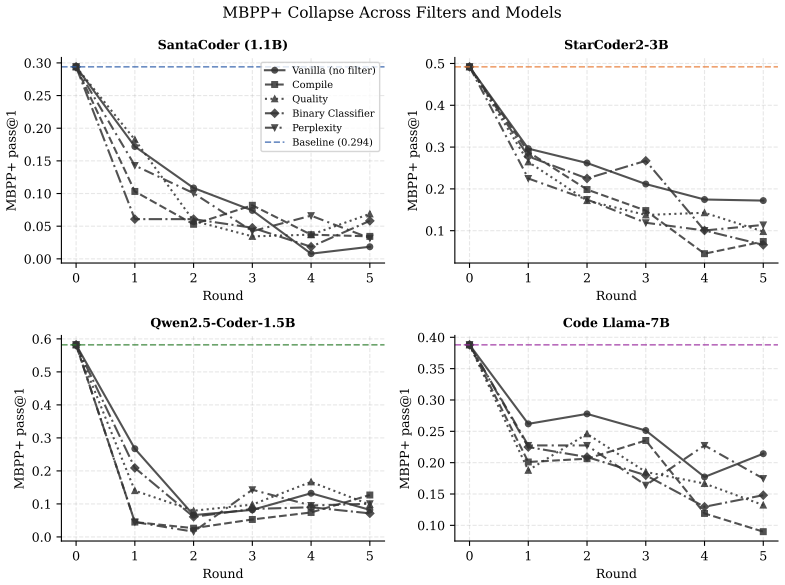
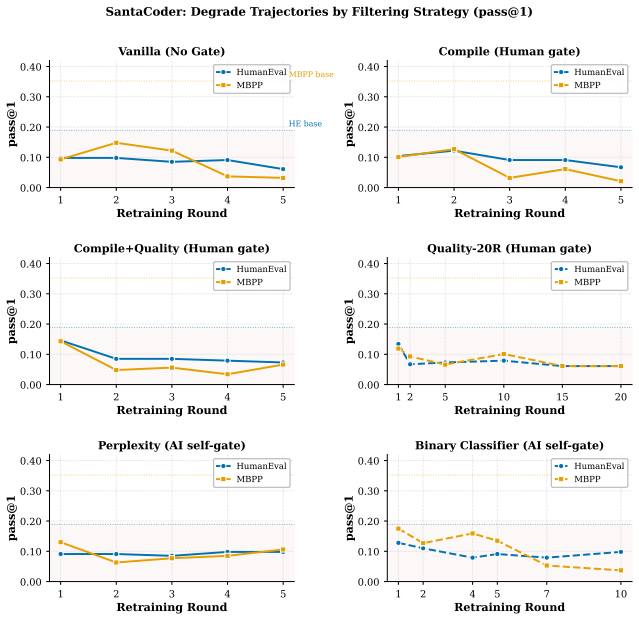
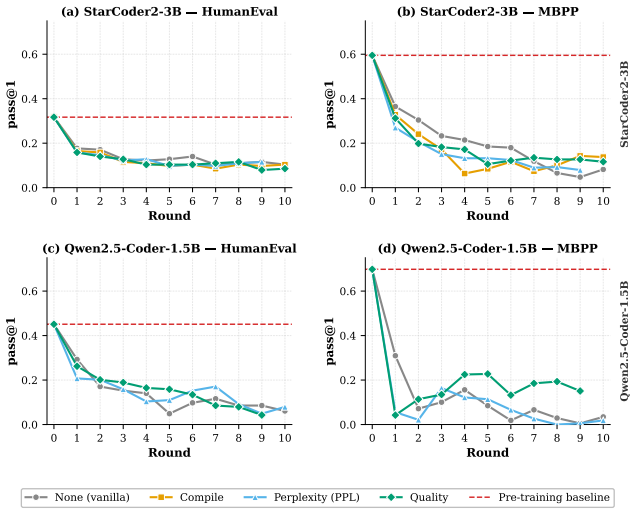
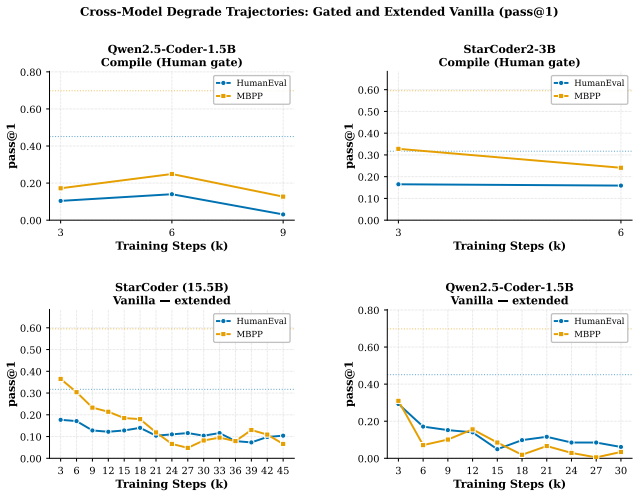
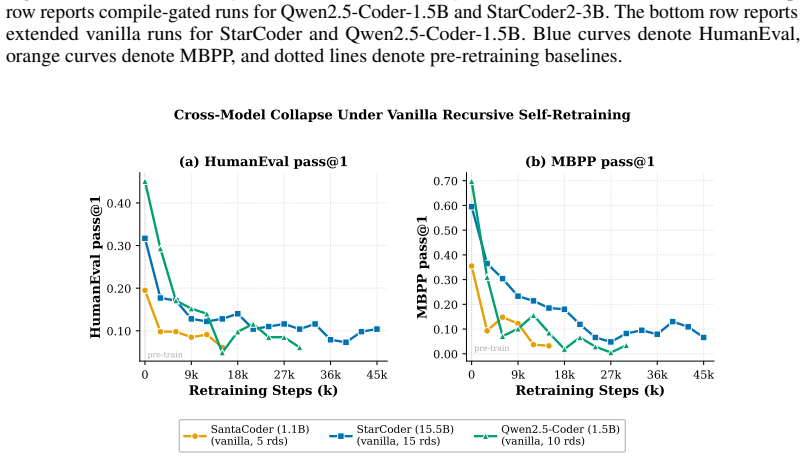
Formulating review as gated distributional reweighting shows that AI self-gating degenerates to ungated self-training under a self-confirming acceptance condition. In this regime the binary self-gate enters a rubber-stamp state where acceptance scores rise while benchmark correctness falls. A spectral analysis of representation-level covariance concentration under recursive retraining supports the observed collapse.
What carries the argument
Gated distributional reweighting, in which review functions as a gate that reweights the training distribution, together with the self-confirming acceptance condition that renders the gate permanently open.
If this is right
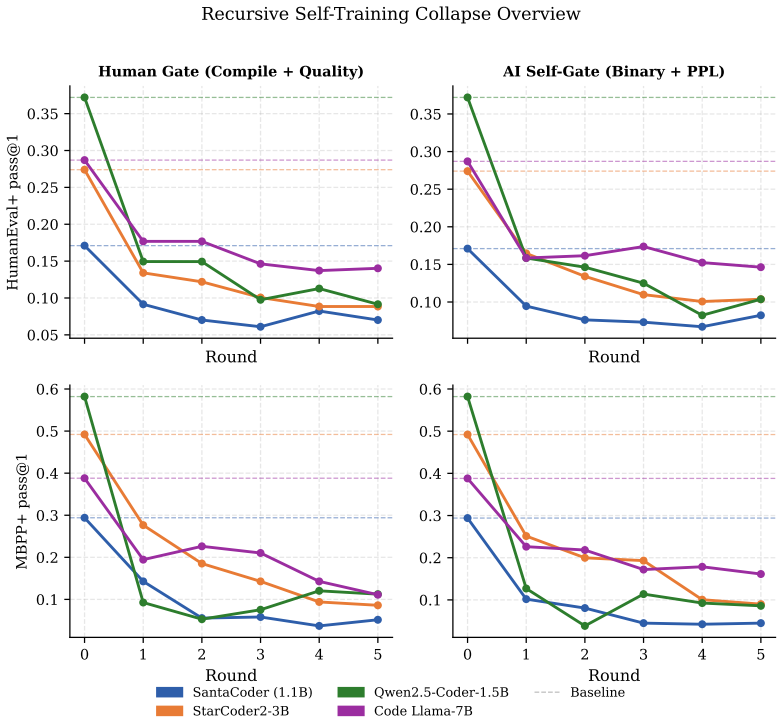
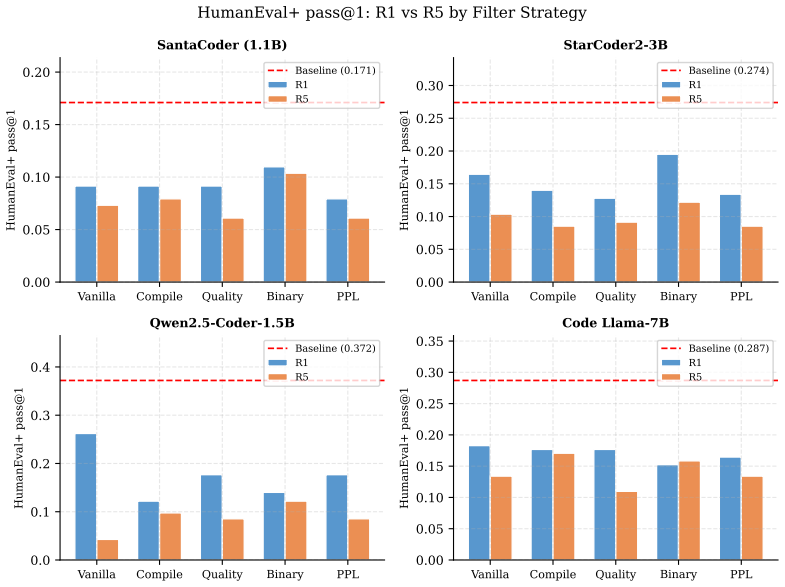
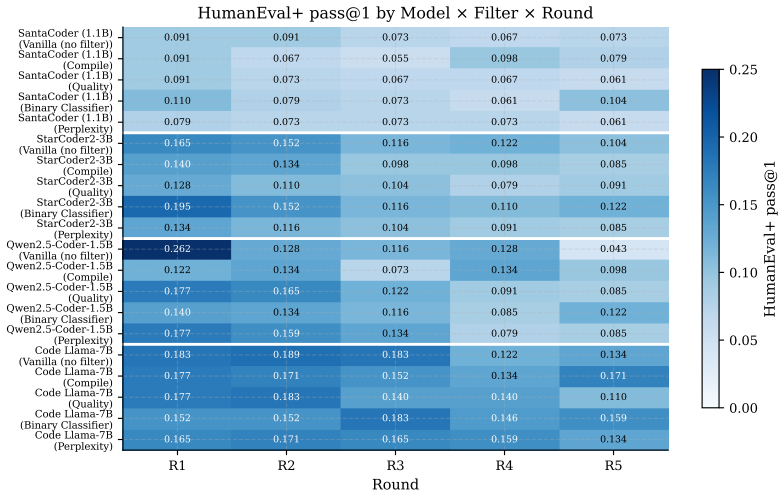
- No review produces the fastest performance collapse.
- Human-gate filters using compilation and static quality checks slow but do not stop the decline.
- AI-self-gate filters appear effective early yet later lose filtering power and enter the rubber-stamp regime.
- Stable recursive code LLM training requires exogenous verification sources instead of model-coupled self-review.
Where Pith is reading between the lines
- If public repositories increasingly contain AI-generated code accepted by similar models, the self-training loop could accelerate outside controlled benchmarks.
- Replacing benchmark evaluation with tests on freshly written, non-contaminated code snippets could isolate whether the observed drop is real degradation or measurement artifact.
- The same gated reweighting analysis may apply to recursive training in other generative domains that rely on model self-scoring for data filtering.
Load-bearing premise
Benchmark correctness remains a stable external measure of capability even after the model has been retrained on its own accepted outputs.
What would settle it
Perform multiple rounds of recursive fine-tuning on a code LLM using its binary self-scoring as the sole gate and measure whether average acceptance scores increase while held-out benchmark correctness decreases.
Figures
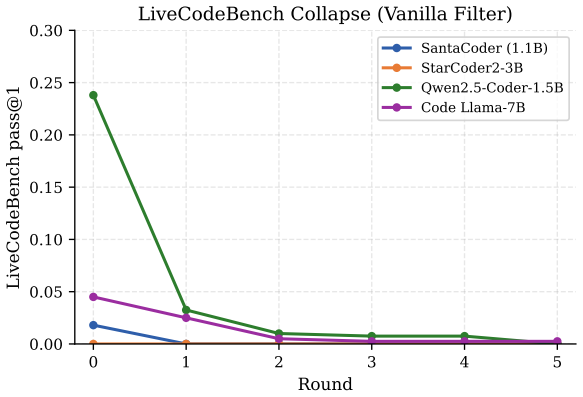
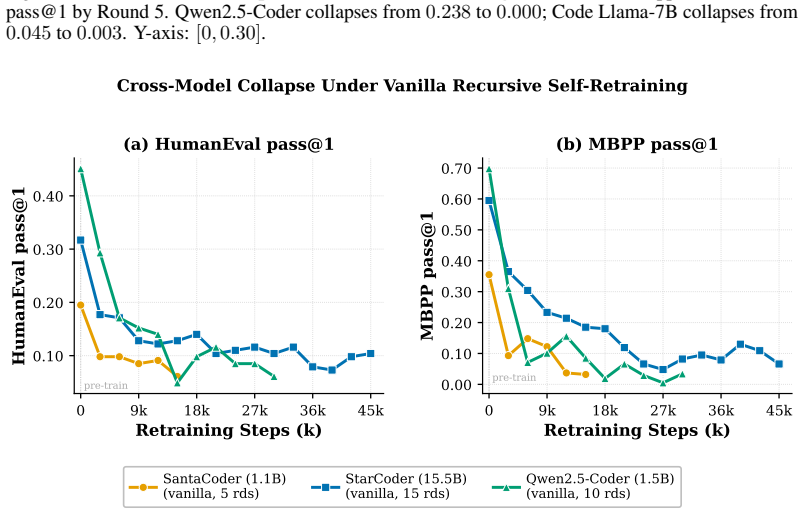
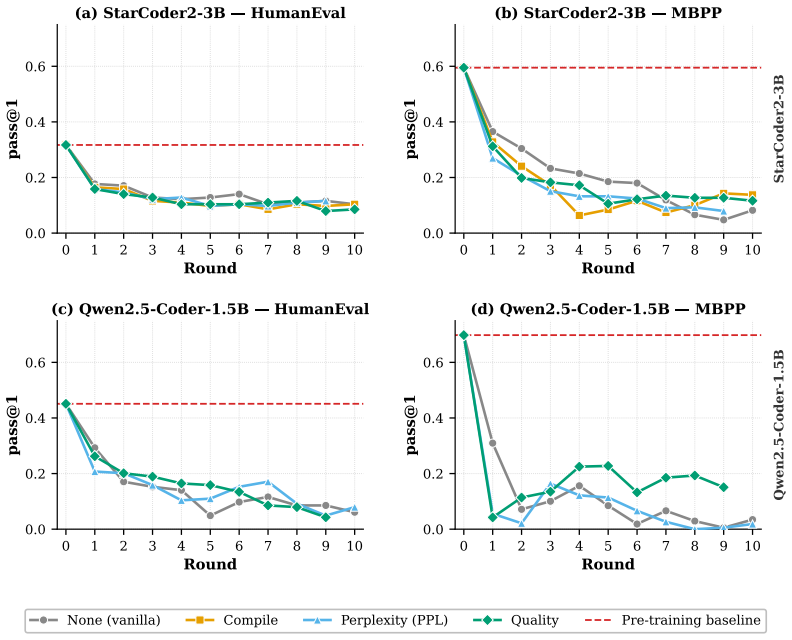
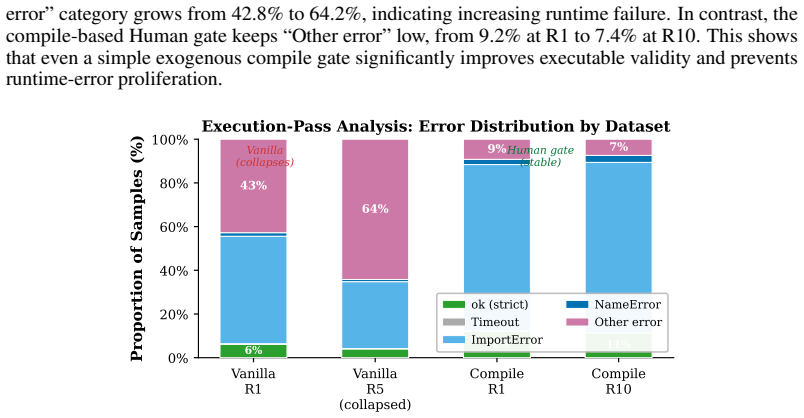
read the original abstract
Recursive self-training can degrade neural generative models when generated data is reused without fresh human data or external quality control. We study this risk in code LLMs, where AI-generated code can enter real repositories, later become training data, and create a repository-scale self-training loop. While software development traditionally interrupts this loop through pull-request review, tests, compilation, and human approval, AI coding tools now produce code faster than humans can review it, and code review itself is increasingly automated by AI systems. We therefore compare three recursive fine-tuning regimes: no review, Human-gate review using model-independent filters such as compilation and static quality checks, and AI-self-gate review using the code LLM's own signals such as perplexity and binary self-scoring. Across multiple code LLMs and benchmarks, no review collapses fastest, Human-gate filters slow but do not stop collapse, and AI-self-gate filters can look strong early but later lose their filtering effect. In the clearest case, the binary self-gate enters a rubber-stamp regime where acceptance scores rise while benchmark correctness falls. We explain this behavior by formulating review as gated distributional reweighting, proving that AI self-gating degenerates to ungated self-training under a self-confirming acceptance condition, and giving a spectral analysis of representation-level covariance concentration under recursive retraining. These results suggest that stable recursive code LLM training requires exogenous verification rather than model-coupled self-review.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines recursive self-training collapse in code LLMs by comparing three fine-tuning regimes—no review, Human-gate review (model-independent filters such as compilation and static checks), and AI-self-gate review (using the LLM's own signals like perplexity and binary self-scoring)—across multiple models and benchmarks. It reports that no review collapses fastest, Human-gate slows but does not stop collapse, and AI-self-gate initially appears effective but later enters a rubber-stamp regime with rising acceptance scores and falling benchmark correctness. The behavior is explained by formulating review as gated distributional reweighting, proving degeneration to ungated self-training under a self-confirming acceptance condition, and providing a spectral analysis of representation-level covariance concentration under recursive retraining. The conclusion advocates exogenous verification over model-coupled self-review.
Significance. If the empirical patterns and the degeneration proof hold, the work is significant for identifying a concrete failure mode in automated code review loops that can contaminate real repositories. The gated reweighting formulation and the explicit self-confirming condition provide a reusable theoretical lens, while the spectral analysis adds insight into representation collapse; together they move the discussion beyond purely empirical warnings about self-training.
major comments (2)
- [gated distributional reweighting / proof section] Proof of degeneration (gated distributional reweighting section): the self-confirming acceptance condition is presented as sufficient for collapse to ungated self-training, but the manuscript must verify this condition on held-out data separate from the recursive training distribution; if the condition is only checked on the same generated samples used to demonstrate rising acceptance and falling correctness, the argument risks circularity.
- [experiments / results on AI-self-gate] Experiments across models and benchmarks: the central observation that benchmark correctness falls while acceptance rises treats correctness as a stable external signal. The paper should report explicit controls (e.g., overlap statistics between generated code patterns and benchmark test cases, or evaluation on a temporally held-out benchmark version) to rule out the possibility that retraining shifts the evaluation distribution or contaminates the benchmarks themselves.
minor comments (2)
- [formulation section] Notation for the binary self-gate acceptance probability should be introduced once with a clear definition before its repeated use in the reweighting equations.
- [figures] Figure captions for the acceptance-vs-correctness plots should state the exact number of recursive steps and the precise definition of 'acceptance score' used in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. Below we address each major comment point by point, indicating the changes we will make in revision.
read point-by-point responses
-
Referee: [gated distributional reweighting / proof section] Proof of degeneration (gated distributional reweighting section): the self-confirming acceptance condition is presented as sufficient for collapse to ungated self-training, but the manuscript must verify this condition on held-out data separate from the recursive training distribution; if the condition is only checked on the same generated samples used to demonstrate rising acceptance and falling correctness, the argument risks circularity.
Authors: We agree that the current presentation risks circularity if the self-confirming acceptance condition is verified exclusively on the same generated samples used to illustrate rising acceptance and falling correctness. In the revised manuscript we will add an explicit verification of the condition on a held-out collection of generated samples that were never used in any recursive training iteration. This will be reported alongside the existing proof to eliminate the circularity concern. revision: yes
-
Referee: [experiments / results on AI-self-gate] Experiments across models and benchmarks: the central observation that benchmark correctness falls while acceptance rises treats correctness as a stable external signal. The paper should report explicit controls (e.g., overlap statistics between generated code patterns and benchmark test cases, or evaluation on a temporally held-out benchmark version) to rule out the possibility that retraining shifts the evaluation distribution or contaminates the benchmarks themselves.
Authors: We accept that additional controls are required to confirm that the observed drop in benchmark correctness is not an artifact of distribution shift or benchmark contamination. In revision we will compute and report overlap statistics (token-level and AST-level) between the generated code patterns and the benchmark test cases. We will also add results on any temporally held-out benchmark versions that are available for the models studied. These controls will be placed in the experimental results section. revision: yes
Circularity Check
No circularity: derivation relies on independent mathematical formulation and external benchmarks
full rationale
The paper formulates review as gated distributional reweighting and proves degeneration to ungated self-training under a stated self-confirming acceptance condition, presenting this as a general result rather than a fit to the observed data. No quoted equations reduce a prediction to a fitted parameter by construction, no self-citations bear the central load, and no ansatz or uniqueness theorem is imported from prior author work. Benchmark correctness is treated as an external signal throughout, with the collapse observed across multiple models and regimes; the derivation chain remains self-contained against those measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Optimal brain damage , author=. Advances in neural information processing systems , volume=
-
[2]
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding , author=. arXiv preprint arXiv:1510.00149 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot , author =. arXiv preprint arXiv:2302.06590 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2024 , howpublished =
Research: Quantifying GitHub Copilot's Impact in the Enterprise with Accenture , author =. 2024 , howpublished =
2024
-
[5]
2025 , eprint=
Rethinking Code Review Workflows with LLM Assistance: An Empirical Study , author=. 2025 , eprint=
2025
-
[6]
Does AI Code Review Lead to Code Changes? A Case Study of GitHub Actions
Does AI Code Review Lead to Code Changes? A Case Study of GitHub Actions , author =. arXiv preprint arXiv:2508.18771 , year =. 2508.18771 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2026 , howpublished =
2026
-
[8]
2026 , howpublished =
60 Million Copilot Code Reviews and Counting , author =. 2026 , howpublished =
2026
-
[9]
arXiv preprint arXiv:2603.26130 , year =
SWE-PRBench: Benchmarking AI Code Review Quality Against Pull Request Feedback , author =. arXiv preprint arXiv:2603.26130 , year =
-
[10]
Proceedings of the 35th International Conference on Software Engineering , pages =
Expectations, Outcomes, and Challenges of Modern Code Review , author =. Proceedings of the 35th International Conference on Software Engineering , pages =. 2013 , doi =
2013
-
[11]
2015 IEEE/ACM 12th Working Conference on Mining Software Repositories , pages =
Characteristics of Useful Code Reviews: An Empirical Study at Microsoft , author =. 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories , pages =. 2015 , doi =
2015
-
[12]
Empirical Software Engineering , volume =
An Empirical Study of the Impact of Modern Code Review Practices on Software Quality , author =. Empirical Software Engineering , volume =. 2016 , doi =
2016
-
[13]
Proceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice , pages =
Modern Code Review: A Case Study at Google , author =. Proceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice , pages =. 2018 , doi =
2018
-
[14]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. 2023 , journal =. doi:10.48550/arXiv.2302.04761 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761 2023
-
[15]
PAL: Program-aided Language Models
PAL: Program-aided Language Models , author =. 2022 , journal =. doi:10.48550/arXiv.2211.10435 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.10435 2022
-
[16]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models , author =. 2023 , journal =. doi:10.48550/arXiv.2210.03629 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[17]
2024 , eprint=
The Curse of Recursion: Training on Generated Data Makes Models Forget , author=. 2024 , eprint=
2024
-
[18]
Grammar-Constrained Decoding Makes Large Language Models Better Logical Parsers
Raspanti, Federico and Ozcelebi, Tanir and Holenderski, Mike. Grammar-Constrained Decoding Makes Large Language Models Better Logical Parsers. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track). 2025. doi:10.18653/v1/2025.acl-industry.34
-
[19]
2025 , eprint=
Beyond ReAct: A Planner-Centric Framework for Complex Tool-Augmented LLM Reasoning , author=. 2025 , eprint=
2025
-
[20]
2021 , howpublished =
openai/human-eval: Code for the paper ``Evaluating Large Language Models Trained on Code'' , author =. 2021 , howpublished =
2021
-
[21]
2022 , howpublished =
bigcode-project/bigcode-evaluation-harness: A framework for the evaluation of code generation models , author =. 2022 , howpublished =
2022
-
[22]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis , author =. arXiv preprint arXiv:2009.10297 , year =. 2009.10297 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[23]
BLEU : a method for automatic evaluation of machine translation
Bleu: a Method for Automatic Evaluation of Machine Translation , author =. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pages =. 2002 , address =. doi:10.3115/1073083.1073135 , url =
-
[24]
Text Summarization Branches Out , pages =
ROUGE: A Package for Automatic Evaluation of Summaries , author =. Text Summarization Branches Out , pages =. 2004 , address =
2004
-
[25]
Popovi. chr. Proceedings of the Tenth Workshop on Statistical Machine Translation , pages =. 2015 , address =. doi:10.18653/v1/W15-3049 , url =
-
[26]
Measuring Coding Challenge Competence With
Hendrycks, Dan and Basart, Steven and Kadavath, Saurav and Mazeika, Mantas and Arora, Akul and Guo, Ethan and Burns, Collin and Puranik, Samir and He, Horace and Song, Dawn and Steinhardt, Jacob , journal =. Measuring Coding Challenge Competence With. 2021 , eprint =
2021
-
[27]
Fast Transformer Decoding: One Write-Head is All You Need
Fast Transformer Decoding: One Write-Head is All You Need , author =. arXiv preprint arXiv:1911.02150 , year =. 1911.02150 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[28]
Wang, Jiexin and Luo, Xitong and Cao, Liuwen and He, Hongkui and Huang, Hailin and Xie, Jiayuan and Jatowt, Adam and Cai, Yi , journal =. Is Your. 2024 , eprint =
2024
-
[29]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Liu and Balaji Lakshminarayanan , title =
Jie Ren and Yao Zhao and Tu Vu and Peter J. Liu and Balaji Lakshminarayanan , title =. Proceedings of the Workshop on I Can't Believe It's Not Better at NeurIPS , series =. 2023 , publisher =
2023
-
[31]
The Twelfth International Conference on Learning Representations , year =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , title =. The Twelfth International Conference on Learning R...
-
[32]
Advances in Neural Information Processing Systems , volume =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , title =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[33]
Xing and Hao Zhang and Joseph E
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric P. Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , title =. NeurIPS 2023 Datasets and Benchmarks Track , year =
2023
-
[34]
Helia Hashemi and Jason Eisner and Corby Rosset and Benjamin Van Durme and Chris Kedzie , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , publisher =. doi:10.18653/v1/2024.acl-long.745 , url =
-
[35]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Weixi Tong and Tianyi Zhang , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =. doi:10.18653/v1/2024.emnlp-main.1118 , url =
-
[36]
Proceedings of the 31st International Conference on Computational Linguistics , pages =
Yuwei Zhao and Ziyang Luo and Yuchen Tian and Hongzhan Lin and Weixiang Yan and Annan Li and Jing Ma , title =. Proceedings of the 31st International Conference on Computational Linguistics , pages =. 2025 , publisher =
2025
-
[37]
Bowman and Shi Feng , title =
Arjun Panickssery and Samuel R. Bowman and Shi Feng , title =. Advances in Neural Information Processing Systems , year =
-
[38]
arXiv preprint arXiv:2301.03988 , year=
SantaCoder: don't reach for the stars! , author=. arXiv preprint arXiv:2301.03988 , year=
-
[39]
Transactions on Machine Learning Research , year=
StarCoder: may the source be with you! , author=. Transactions on Machine Learning Research , year=
-
[40]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence , author=. arXiv preprint arXiv:2406.11931 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Qwen2.5-Coder Technical Report
Qwen2.5-Coder Technical Report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International Conference on Learning Representations , year=
OctoPack: Instruction Tuning Code Large Language Models , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Volume 4: Student Research Workshop , year=
InstructCoder: Instruction Tuning Large Language Models for Code Editing , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Volume 4: Student Research Workshop , year=
-
[44]
Evaluation Best Practices , year =
-
[45]
2026 , howpublished =
Demystifying evals for. 2026 , howpublished =
2026
-
[46]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2411.04905 , year =
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models , author =. arXiv preprint arXiv:2411.04905 , year =. 2411.04905 , archivePrefix=
-
[49]
arXiv preprint arXiv:2510.16579 , year =
Human-Aligned Code Readability Assessment with Large Language Models , author =. arXiv preprint arXiv:2510.16579 , year =. 2510.16579 , archivePrefix=
-
[50]
Rozi. Code. arXiv preprint arXiv:2308.12950 , year =. 2308.12950 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
arXiv preprint arXiv:2601.21894 , year =
Not All Code Is Equal: A Data-Centric Study of Code Complexity and LLM Reasoning , author =. arXiv preprint arXiv:2601.21894 , year =. 2601.21894 , archivePrefix=
-
[52]
StarCoder 2 and The Stack v2: The Next Generation
StarCoder 2 and The Stack v2: The Next Generation , author =. arXiv preprint arXiv:2402.19173 , year =. 2402.19173 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence , author =. arXiv preprint arXiv:2401.14196 , year =. 2401.14196 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Efficient Training of Language Models to Fill in the Middle
Efficient Training of Language Models to Fill in the Middle , author =. arXiv preprint arXiv:2207.14255 , year =. 2207.14255 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
and Guha, Arjun and Greenberg, Michael and Jangda, Abhinav , journal =
Cassano, Federico and Gouwar, John and Nguyen, Daniel and Nguyen, Sydney and Phipps-Costin, Luna and Pinckney, Donald and Yee, Ming-Ho and Zi, Yangtian and Anderson, Carolyn Jane and Feldman, Molly Q. and Guha, Arjun and Greenberg, Michael and Jangda, Abhinav , journal =. 2022 , eprint =
2022
-
[56]
Kocetkov, Denis and Li, Raymond and Ben Allal, Loubna and Liu, Jia and Mathur, Neel and Muennighoff, Niklas and Ogueji, Kelechi and Mishra, Shreshtha and Sharma, Shubham and Tunstall, Lewis and von Werra, Leandro and Wolf, Thomas , journal =. The. 2022 , eprint =
2022
-
[57]
2022 , eprint =
Fried, Daniel and Aghajanyan, Armen and Lin, Jessy and Wang, Sida and Wallace, Eric and Shi, Freda and Zhong, Ruiqi and Yih, Wen-tau and Zettlemoyer, Luke and Lewis, Mike , journal =. 2022 , eprint =
2022
-
[58]
2022 , eprint =
Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming , journal =. 2022 , eprint =
2022
-
[59]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
ReCode: Robustness Evaluation of Code Generation Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , month = jul, publisher =
2023
-
[60]
arXiv preprint arXiv:2406.12655 , year =
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review , author =. arXiv preprint arXiv:2406.12655 , year =. 2406.12655 , archivePrefix=
-
[61]
2024 , eprint=
SIaM: Self-Improving Code-Assisted Mathematical Reasoning of Large Language Models , author=. 2024 , eprint=
2024
-
[62]
2025 , eprint=
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks , author=. 2025 , eprint=
2025
-
[63]
2012 , isbn =
Matrix Analysis , author =. 2012 , isbn =
2012
-
[64]
1997 , isbn =
Matrix Analysis , author =. 1997 , isbn =
1997
-
[65]
2013 , isbn =
Matrix Computations , author =. 2013 , isbn =
2013
-
[66]
2023 , eprint=
Self-Consuming Generative Models Go MAD , author=. 2023 , eprint=
2023
-
[67]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Flexible and Efficient Grammar-Constrained Decoding , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[68]
Let's Verify Step by Step , author =. 2023 , journal =. doi:10.48550/arXiv.2305.20050 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.20050 2023
-
[69]
arXiv preprint arXiv:2301.00774 , year=
Massive language models can be accurately pruned in one-shot , author=. arXiv preprint arXiv:2301.00774 , year=
-
[70]
arXiv preprint arXiv:2305.18703 , volume=
Domain specialization as the key to make large language models disruptive: A comprehensive survey , author=. arXiv preprint arXiv:2305.18703 , volume=
-
[71]
A Simple and Effective Pruning Approach for Large Language Models
A Simple and Effective Pruning Approach for Large Language Models , author=. arXiv preprint arXiv:2306.11695 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2305.11627 , year=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. arXiv preprint arXiv:2305.11627 , year=
-
[73]
arXiv preprint arXiv:2306.11222 , year=
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation , author=. arXiv preprint arXiv:2306.11222 , year=
-
[74]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Structured Pruning for Efficient Generative Pre-trained Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[75]
arXiv preprint arXiv:2302.04089 , year=
Ziplm: Hardware-aware structured pruning of language models , author=. arXiv preprint arXiv:2302.04089 , year=
-
[76]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
AccelTran: A sparsity-aware accelerator for dynamic inference with transformers , author=. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
-
[77]
International Conference on Machine Learning , pages=
Deja vu: Contextual sparsity for efficient llms at inference time , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[78]
Foundations and Trends
Distributed optimization and statistical learning via the alternating direction method of multipliers , author=. Foundations and Trends. 2011 , publisher=
2011
-
[79]
Proceedings of the European conference on computer vision (ECCV) , pages=
A systematic dnn weight pruning framework using alternating direction method of multipliers , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[80]
IEEE transactions on neural networks and learning systems , volume=
Structadmm: Achieving ultrahigh efficiency in structured pruning for dnns , author=. IEEE transactions on neural networks and learning systems , volume=. 2021 , publisher=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.