Developmental Trajectories of Situation Modeling and Mentalizing in Transformer Language Models
Pith reviewed 2026-06-30 01:29 UTC · model grok-4.3
The pith
Larger language models acquire situation modeling before false-belief reasoning, but both emerge late in pretraining and remain fragile.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
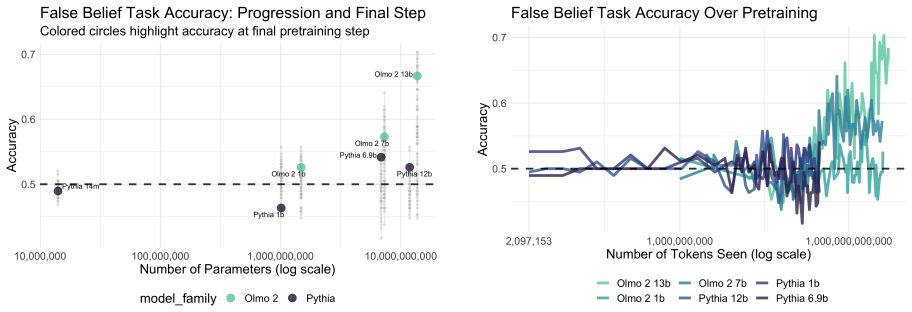
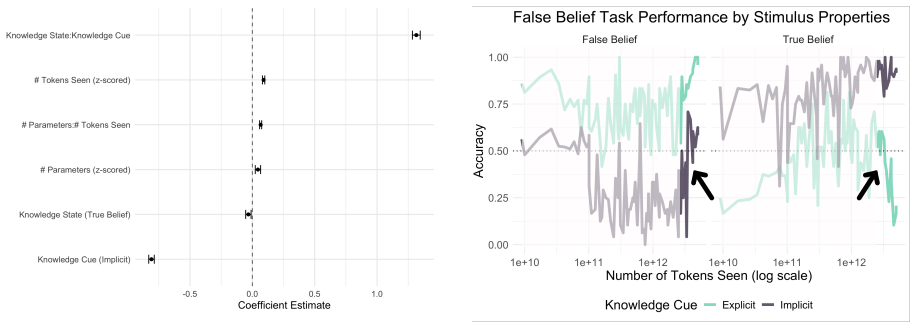
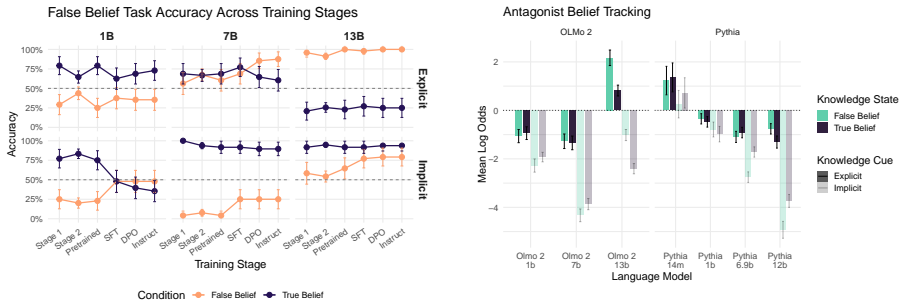
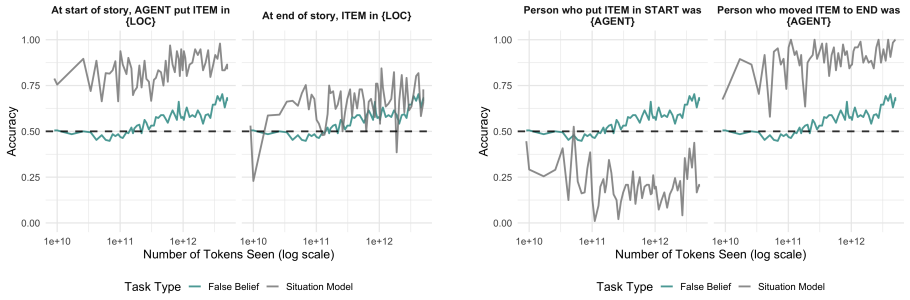
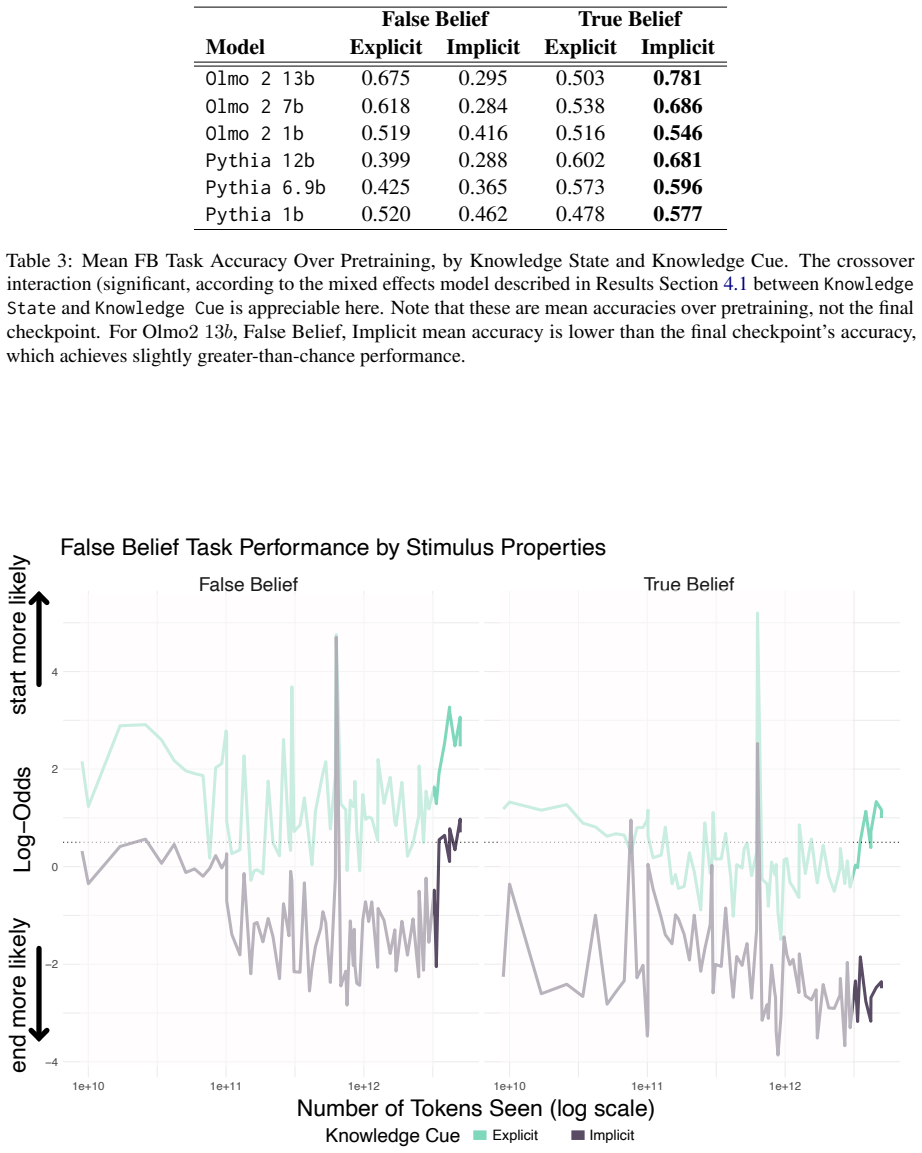
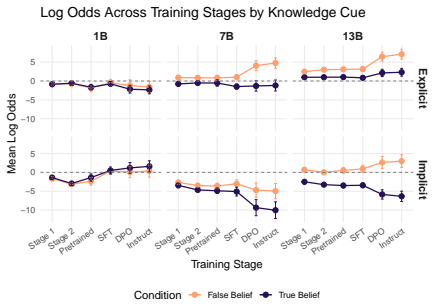
Above-chance false belief task performance depends on both model size and sufficient training volume, emerges relatively late in pretraining, and improves most from post-training interventions in the implicit false belief condition; situation modeling accuracy precedes and exceeds false belief task accuracy yet situational representations remain incoherent because models are influenced by the target agent's knowledge state and non-factive verbs even when reporting on the antagonist who always knows the true location.
What carries the argument
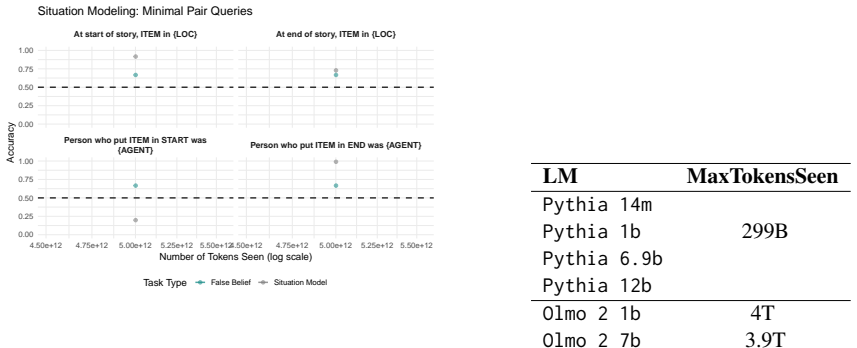
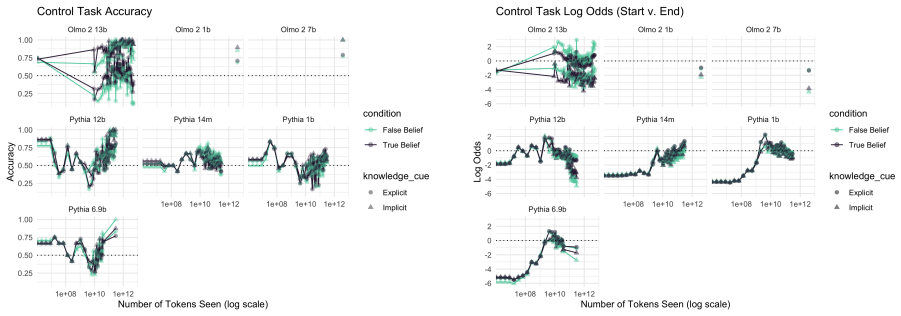
Developmental trajectories of false belief task accuracy and situation modeling probes tracked across pretraining checkpoints and post-training stages in Olmo2 and Pythia suites.
If this is right
- False belief task performance scales with model size and cumulative training tokens.
- Situation modeling reaches usable accuracy before false belief task performance does.
- Supervised fine-tuning and direct preference optimization produce the largest gains on implicit false belief items.
- Non-factive verbs increase false belief attributions even in true belief conditions.
- Situation representations stay partially incoherent when tracking multiple agents' knowledge states.
Where Pith is reading between the lines
- The observed sequence suggests situation modeling may serve as a prerequisite for later mentalizing.
- Fragility to verb choice could limit reliable use of these models in tasks requiring stable belief tracking.
- Targeted post-training on varied verb and agent conditions might reduce incoherence in situation reports.
- Replicating the trajectories on additional model families would test whether the size-and-volume dependence generalizes.
Load-bearing premise
The false belief task and situation modeling probes measure internal mentalizing and scene representations rather than surface statistical patterns in the training text.
What would settle it
An experiment showing that models achieve above-chance false belief task scores solely through sensitivity to non-factive verbs or target-agent phrasing, without corresponding improvement when those cues are removed.
Figures
read the original abstract
Recent work suggests that Large Language Models (LLMs) are sensitive to the belief states of agents described by text, as measured by the false belief task (FBT), yet persistent concerns of construct validity remain. We adopt a **developmental perspective**, tracing the pattern of mental state reasoning behavior -- and likely **preconditions** for this behavior -- across multiple training stages in the Olmo2 and Pythia language model suites. We find that above-chance FBT performance depends both on model size and sufficient training volume, emerges relatively late in pretraining, and is most improved by post-training interventions (SFT, DPO) in the condition most diagnostic of mentalizing (False Belief, Implicit). However, FBT performance is fragile: consistent with past work, the use of non-factive verbs (e.g., thinks) increases false belief attributions even in the True Belief condition. To contextualize these findings, we track the emergence of **situation modeling**: the ability to report on basic factual properties of a described scene. Situation modeling accuracy generally precedes and exceeds FBT accuracy, yet situational representations also prove surprisingly incoherent in certain respects: when asked about the knowledge states of the Antagonist agent -- who always knows the item's true location -- Olmo2 13b is consistently influenced both by the Target agent's knowledge state and the presence of non-factive verbs. Together, these results suggest that larger, sufficiently trained models build partially coherent situation models in a developmentally appropriate sequence, yet display surprising fragility -- highlighting the value of developmental and stress-testing approaches for evaluating LLM capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in the Olmo2 and Pythia model suites, above-chance false-belief task (FBT) performance for mentalizing depends on both model size and sufficient pretraining volume, emerges relatively late during pretraining, and is most improved by post-training interventions (SFT, DPO) in the implicit false-belief condition. Situation-modeling accuracy generally precedes and exceeds FBT accuracy, yet situational representations remain incoherent in specific respects (e.g., antagonist knowledge reports are influenced by target-agent state and non-factive verbs). The work adopts a developmental perspective to trace these abilities and their preconditions while explicitly noting construct-validity concerns with the probes.
Significance. If the empirical patterns hold after addressing the noted limitations, the results would contribute to understanding the training dynamics and developmental sequence of higher-order reasoning capabilities in LLMs, underscoring the value of checkpoint-level analysis, the role of scale and alignment methods, and the need for stress-testing. The multi-model, multi-stage design and the paper's own reporting of fragilities (non-factive verb effects, knowledge leakage) are strengths that could inform future evaluation methodologies.
major comments (2)
- [Abstract] Abstract: the abstract reports directional findings on the dependence of FBT performance on model size, training volume, and post-training interventions but supplies no statistical details, exact accuracies, error bars, or controls for confounds, limiting assessment of whether the data support the stated claims about emergence and improvement.
- [Abstract] Abstract: the central claim that larger, sufficiently trained models build 'partially coherent situation models' and mentalizing abilities rests on FBT and situation probes reflecting internal representations rather than surface lexical associations; however, the abstract itself documents that non-factive verbs increase false-belief attributions even in True Belief conditions and that antagonist knowledge reports are contaminated by target-agent state and verb choice, which directly undermines interpretability of the reported size/training-volume dependence, late emergence, and SFT/DPO gains as evidence of mentalizing.
minor comments (1)
- [Abstract] Abstract: the specific reference to 'Olmo2 13b' for the antagonist-influence finding should clarify whether this pattern holds across the full range of model sizes examined or is size-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and indicate planned revisions to strengthen the presentation of results and qualifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract reports directional findings on the dependence of FBT performance on model size, training volume, and post-training interventions but supplies no statistical details, exact accuracies, error bars, or controls for confounds, limiting assessment of whether the data support the stated claims about emergence and improvement.
Authors: We agree that the abstract would be improved by including select quantitative details. In revision we will incorporate key accuracy figures (e.g., peak FBT performance ranges by model size), a brief note on statistical thresholds used, and reference to the confound controls and error-bar reporting already present in the main results and appendix. Abstract length constraints will limit the number of numbers, but the additions will directly address the concern. revision: yes
-
Referee: [Abstract] Abstract: the central claim that larger, sufficiently trained models build 'partially coherent situation models' and mentalizing abilities rests on FBT and situation probes reflecting internal representations rather than surface lexical associations; however, the abstract itself documents that non-factive verbs increase false-belief attributions even in True Belief conditions and that antagonist knowledge reports are contaminated by target-agent state and verb choice, which directly undermines interpretability of the reported size/training-volume dependence, late emergence, and SFT/DPO gains as evidence of mentalizing.
Authors: The abstract already foregrounds these fragilities precisely to signal the construct-validity limits of the probes, and the core claims are qualified with the phrases 'partially coherent' and 'surprising fragility.' The reported dependencies on scale, pretraining volume, and post-training are measured across multiple conditions and persist after the documented verb-type and knowledge-leakage effects are accounted for in the full analyses. We will revise the abstract to add an explicit clause stating that the emergence patterns hold after controlling for these factors, thereby clarifying that the limitations do not negate the observed developmental trajectories. revision: partial
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper reports direct experimental results on FBT accuracy and situation-modeling probes across model sizes, training checkpoints, and post-training interventions in Olmo2 and Pythia suites. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methods. Performance is measured against external task benchmarks with explicit construct-validity caveats noted by the authors themselves. The central claims (late emergence, size/training dependence, SFT/DPO gains) rest on observed accuracies rather than any reduction to prior definitions or self-referential fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The false belief task is a valid probe of mentalizing in language models
Reference graph
Works this paper leans on
-
[1]
Explanation as. Minds and Machines , author =. 1998 , keywords =. doi:10.1023/A:1008290415597 , language =
-
[2]
Perspectives on Psychological Science , author =
Repositioning. Perspectives on Psychological Science , author =. 2025 , note =. doi:10.1177/17456916231195852 , abstract =
-
[3]
Inventing
Chang, Hasok , month = aug, year =. Inventing
-
[4]
Nature Human Behaviour , author =
How to evaluate the cognitive abilities of. Nature Human Behaviour , author =. 2025 , pmid =. doi:10.1038/s41562-024-02096-z , language =
-
[5]
Trends in Cognitive Sciences , author =
Identifying indicators of consciousness in. Trends in Cognitive Sciences , author =. 2025 , pmid =. doi:10.1016/j.tics.2025.10.011 , language =
-
[6]
Philosophy of the Social Sciences , author =
Valid for. Philosophy of the Social Sciences , author =. 2021 , note =. doi:10.1177/0048393120971169 , abstract =
-
[7]
Finding Interpretable Prompt-Specific Circuits in Language Models
Franco, Gabriel and Tassis, Lucas M. and Rohr, Azalea and Crovella, Mark , month = feb, year =. Finding. doi:10.48550/arXiv.2602.13483 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.13483
-
[8]
The Journal of Philosophy , author =
Real. The Journal of Philosophy , author =. 1991 , note =. doi:10.2307/2027085 , number =
-
[9]
Psychological Review , author =
The. Psychological Review , author =. 2004 , keywords =. doi:10.1037/0033-295X.111.4.1061 , language =
-
[10]
Saxon, Michael and Holtzman, Ari and West, Peter and Wang, William Yang and Saphra, Naomi , month = jul, year =. Benchmarks as. doi:10.48550/arXiv.2407.16711 , abstract =
-
[11]
Psychological Bulletin , author =
Construct validity in psychological tests , volume =. Psychological Bulletin , author =. 1955 , note =. doi:10.1037/h0040957 , abstract =
-
[12]
Philosophy of Science , author =
A. Philosophy of Science , author =. 2019 , keywords =. doi:10.1086/705567 , abstract =
-
[13]
Philosophy of Science , author =
Is. Philosophy of Science , author =. 2016 , keywords =. doi:10.1086/687941 , abstract =
-
[14]
Auxiliary task demands mask the capabilities of smaller language models , url =
Hu, Jennifer and Frank, Michael , month = aug, year =. Auxiliary task demands mask the capabilities of smaller language models , url =
-
[15]
Nature Human Behaviour , author =
Testing theory of mind in large language models and humans , volume =. Nature Human Behaviour , author =. 2024 , note =. doi:10.1038/s41562-024-01882-z , abstract =
-
[16]
Advances in Methods and Practices in Psychological Science , author =
Measurement. Advances in Methods and Practices in Psychological Science , author =. 2020 , note =. doi:10.1177/2515245920952393 , abstract =
-
[17]
Current Directions in Psychological Science , author =
Credibility. Current Directions in Psychological Science , author =. 2022 , note =. doi:10.1177/09637214211067779 , abstract =
-
[18]
arXiv preprint arXiv:2111.15366 , year=
Raji, Inioluwa Deborah and Bender, Emily M. and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , month = nov, year =. doi:10.48550/arXiv.2111.15366 , abstract =
-
[19]
Bean, Andrew M. and Kearns, Ryan Othniel and Romanou, Angelika and Hafner, Franziska Sofia and Mayne, Harry and Batzner, Jan and Foroutan, Negar and Schmitz, Chris and Korgul, Karolina and Batra, Hunar and Deb, Oishi and Beharry, Emma and Emde, Cornelius and Foster, Thomas and Gausen, Anna and Grandury, María and Han, Simeng and Hofmann, Valentin and Ibra...
-
[20]
The British Journal for the Philosophy of Science , author =
Model. The British Journal for the Philosophy of Science , author =. 2015 , pages =. doi:10.1093/bjps/axt055 , abstract =
-
[21]
Six problems for causal inference from. NeuroImage , author =. 2010 , pages =. doi:10.1016/j.neuroimage.2009.08.065 , abstract =
-
[22]
Transactions of the Association for Computational Linguistics , author =
Are. Transactions of the Association for Computational Linguistics , author =. 2024 , pages =. doi:10.1162/tacl_a_00690 , abstract =
-
[23]
Goldstein, Simon and Lederman, Harvey , file =. What
-
[24]
Fehlauer, Finlay and Mahowald, Kyle and Pimentel, Tiago , editor =. Convergence and. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.1675 , abstract =
-
[25]
arXiv.org , author =
Predicting the. arXiv.org , author =. 2025 , file =
2025
-
[26]
Tigges, Curt and Hanna, Michael and Biderman, Stella and Yu, Qinan , keywords =
-
[27]
Advances in Neural Information Processing Systems , author =. 2024 , pages =. doi:10.52202/079017-1287 , language =
-
[28]
Tsvilodub, Polina and Klumpp, Jan-Felix and Mohammadpour, Amir and Hu, Jennifer and Franke, Michael , month = feb, year =. On. doi:10.48550/arXiv.2602.10298 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.10298
-
[29]
Trends in Cognitive Sciences , author =. 2025 , pmid =. doi:10.1016/j.tics.2025.09.012 , language =
-
[30]
ArXiv , author =
Measuring and. ArXiv , author =. 2025 , pmid =
2025
-
[31]
, file =
Nefdt, Ryan M. , file =. What it's like to be an
-
[32]
Bauman, Christopher W. and McGraw, A. Peter and Bartels, Daniel M. and Warren, Caleb , file =. Revisiting. doi:10.1111/spc3.12131 , abstract =
-
[33]
Human-like individual differences emerge from random weight initializations in neural networks , issn =. bioRxiv , author =. 2025 , pmid =. doi:10.1101/2025.10.25.684448 , abstract =
-
[34]
Transactions on Machine Learning Research , author =
Latent. Transactions on Machine Learning Research , author =. 2023 , file =
2023
-
[35]
and Saphra, Naomi , month = oct, year =
Chen, Angelica and Shwartz-Ziv, Ravid and Cho, Kyunghyun and Leavitt, Matthew L. and Saphra, Naomi , month = oct, year =. Sudden
-
[36]
, month = nov, year =
Zhao, Rosie and Saphra, Naomi and Kakade, Sham M. , month = nov, year =. Distributional
-
[37]
arXiv.org , author =
Random. arXiv.org , author =. 2025 , file =
2025
-
[38]
arXiv.org , author =
Sometimes. arXiv.org , author =. 2024 , file =
2024
-
[39]
PLOS Computational Biology , author =
Neuronal identity is not static:. PLOS Computational Biology , author =. 2025 , note =. doi:10.1371/journal.pcbi.1013821 , abstract =
-
[40]
Nature Machine Intelligence , author =
A taxonomy and review of generalization research in. Nature Machine Intelligence , author =. 2023 , note =. doi:10.1038/s42256-023-00729-y , abstract =
-
[41]
Trott, Sean , month = sep, year =. Toward a. doi:10.48550/arXiv.2509.22831 , abstract =
-
[42]
Two reasons to abandon the false belief task as a test of theory of mind , volume =. Cognition , author =. 2000 , keywords =. doi:10.1016/S0010-0277(00)00096-2 , abstract =
-
[43]
Trott, Sean and Taylor, Samuel and Jones, Cameron and Michaelov, James A. and Rivière, Pamela D. , month = feb, year =. Language. doi:10.48550/arXiv.2602.16085 , abstract =
-
[44]
Transactions of the Association for Computational Linguistics , author =
Comparing. Transactions of the Association for Computational Linguistics , author =. 2024 , note =. doi:10.1162/tacl_a_00674 , abstract =
-
[45]
Behavioral and Brain Sciences , author =
Understanding and sharing intentions:. Behavioral and Brain Sciences , author =. 2005 , keywords =. doi:10.1017/S0140525X05000129 , abstract =
-
[46]
What is “theory of mind”?. Quarterly Journal of Experimental Psychology , author =. 2012 , note =. doi:10.1080/17470218.2012.676055 , abstract =
-
[47]
Proceedings of the Annual Meeting of the Cognitive Science Society , author =
Does reading words help you to read minds?. Proceedings of the Annual Meeting of the Cognitive Science Society , author =. 2024 , file =
2024
-
[48]
Shapira, Natalie and Levy, Mosh and Alavi, Seyed Hossein and Zhou, Xuhui and Choi, Yejin and Goldberg, Yoav and Sap, Maarten and Shwartz, Vered , editor =. Clever. Proceedings of the 18th. 2024 , pages =. doi:10.18653/v1/2024.eacl-long.138 , abstract =
-
[49]
Ullman, Tomer , month = mar, year =. Large. doi:10.48550/arXiv.2302.08399 , abstract =
-
[50]
Advances in Neural Information Processing Systems , author =
Understanding. Advances in Neural Information Processing Systems , author =. 2023 , pages =
2023
-
[51]
Xu, Hainiu and Zhao, Runcong and Zhu, Lixing and Du, Jinhua and He, Yulan , editor =. Proceedings of the 62nd. 2024 , pages =. doi:10.18653/v1/2024.acl-long.466 , abstract =
-
[52]
Do. Cognitive Science , author =. 2023 , note =. doi:10.1111/cogs.13309 , abstract =
-
[53]
Philosophical Transactions of the Royal Society B: Biological Sciences , author =
Re-evaluating. Philosophical Transactions of the Royal Society B: Biological Sciences , author =. 2025 , pages =. doi:10.1098/rstb.2023.0499 , abstract =
-
[54]
Developmental Psychology , author =
I can talk you into it:. Developmental Psychology , author =. 2013 , note =. doi:10.1037/a0028280 , abstract =
-
[55]
Cooperation and. PLOS ONE , author =. 2008 , note =. doi:10.1371/journal.pone.0002023 , abstract =
-
[56]
Small-. Child Development , author =. 1989 , note =. doi:10.2307/1130919 , abstract =
-
[57]
Meta-. Child Development , author =. 2001 , note =. doi:10.1111/1467-8624.00304 , abstract =
-
[58]
Trends in Cognitive Sciences , author =
Does the chimpanzee have a theory of mind? 30 years later , volume =. Trends in Cognitive Sciences , author =. 2008 , pmid =. doi:10.1016/j.tics.2008.02.010 , language =
-
[59]
WIREs Cognitive Science , author =
Theory of mind in animals:. WIREs Cognitive Science , author =. 2019 , note =. doi:10.1002/wcs.1503 , abstract =
-
[60]
Great apes anticipate that other individuals will act according to false beliefs , volume =. Science , author =. 2016 , note =. doi:10.1126/science.aaf8110 , abstract =
-
[61]
Frontiers in Human Neuroscience , author =. 2026 , note =. doi:10.3389/fnhum.2025.1633272 , abstract =
-
[62]
Evaluating large language models in theory of mind tasks.arXiv preprint arXiv:2302.02083,
Evaluating large language models in theory of mind tasks , volume =. Proceedings of the National Academy of Sciences , author =. 2024 , note =. doi:10.1073/pnas.2405460121 , abstract =
-
[63]
Why. Child Development , author =. 1996 , note =. doi:10.1111/j.1467-8624.1996.tb01767.x , abstract =
-
[64]
Topics in Language Disorders , author =
The. Topics in Language Disorders , author =. 2014 , pages =. doi:10.1097/TLD.0000000000000037 , abstract =
-
[65]
Artificial Intelligence Review , author =
Lies, damned lies, and language statistics: a comprehensive review of risks from manipulation, persuasion, and deception with large language models , volume =. Artificial Intelligence Review , author =. 2026 , keywords =. doi:10.1007/s10462-026-11517-6 , abstract =
-
[66]
Child development , volume=
Sensorimotor decoupling contributes to triadic attention: A longitudinal investigation of mother--infant--object interactions , author=. Child development , volume=. 2016 , publisher=
2016
-
[67]
Journal of Autism and Developmental Disorders , volume=
Does the neurotypical human have a ‘theory of mind’? , author=. Journal of Autism and Developmental Disorders , volume=. 2023 , publisher=
2023
-
[68]
PloS one , volume=
Using fiction to assess mental state understanding: a new task for assessing theory of mind in adults , author=. PloS one , volume=. 2013 , publisher=
2013
-
[69]
British Journal of Developmental Psychology , volume=
Reliability and validity of advanced theory-of-mind measures in middle childhood and adolescence , author=. British Journal of Developmental Psychology , volume=. 2017 , publisher=
2017
-
[70]
Discourse Processes , volume=
Individual differences in mentalizing capacity predict indirect request comprehension , author=. Discourse Processes , volume=. 2019 , publisher=
2019
-
[71]
Cognition , volume=
Beliefs about beliefs: Representation and constraining function of wrong beliefs in young children's understanding of deception , author=. Cognition , volume=. 1983 , publisher=
1983
-
[72]
theory of mind
Does the autistic child have a “theory of mind”? , author=. Cognition , volume=. 1985 , publisher=
1985
-
[73]
Journal of statistical software , volume=
Fitting linear mixed-effects models using lme4 , author=. Journal of statistical software , volume=
-
[74]
OLMo, Team and Walsh, Pete and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Arora, Shane and Bhagia, Akshita and Gu, Yuling and Huang, Shengyi and Jordan, Matt and others , journal=. 2
-
[75]
Proceedings of the 40th International Conference on Machine Learning , pages=
Pythia: a suite for analyzing large language models across training and scaling , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[76]
2026 , eprint=
Traces of Social Competence in Large Language Models , author=. 2026 , eprint=
2026
-
[77]
cortex , volume=
The neural basis of belief-attribution across the lifespan: False-belief reasoning and the N400 effect , author=. cortex , volume=. 2020 , publisher=
2020
-
[78]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
arXiv preprint arXiv:2510.24963 , year=
Language Model Behavioral Phases are Consistent Across Architecture, Training Data, and Scale , author=. arXiv preprint arXiv:2510.24963 , year=
-
[80]
, author=
A longitudinal study of the relation between language and theory-of-mind development. , author=. Developmental psychology , volume=. 1999 , publisher=
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.