SEATauBench: Adapting Tool-Agent-User Evaluation Into Low-Resource Southeast Asian Languages
Pith reviewed 2026-06-30 10:10 UTC · model grok-4.3
The pith
Adapting TauBench to five Southeast Asian languages shows agent performance holds for conversation-language changes but drops sharply with localized tools and domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
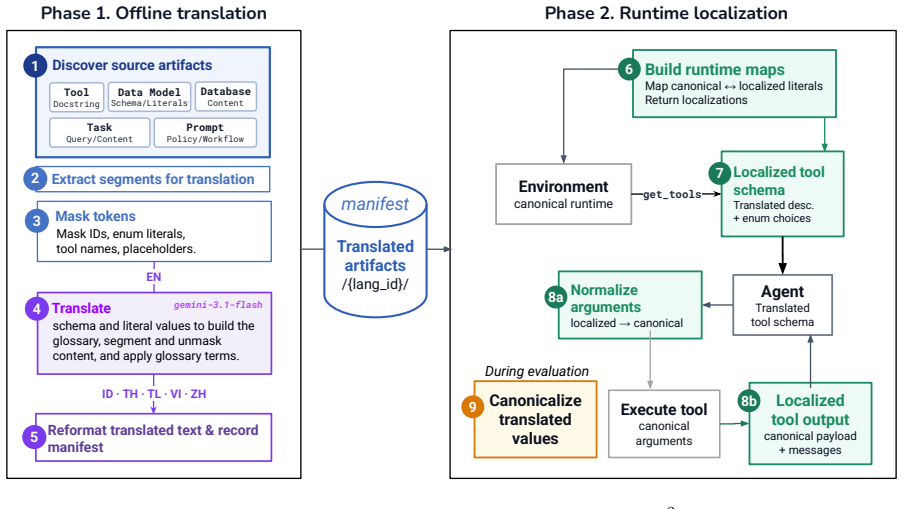
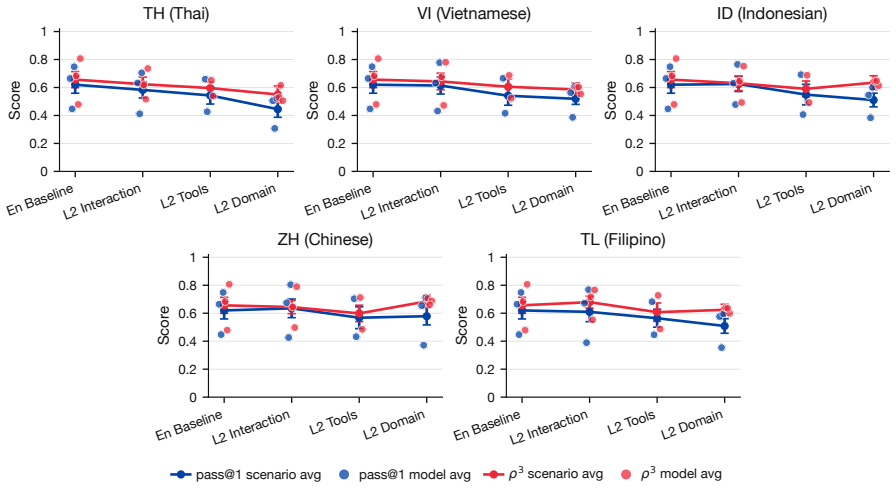
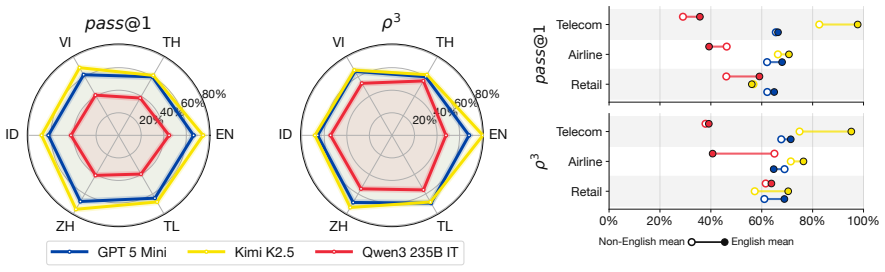
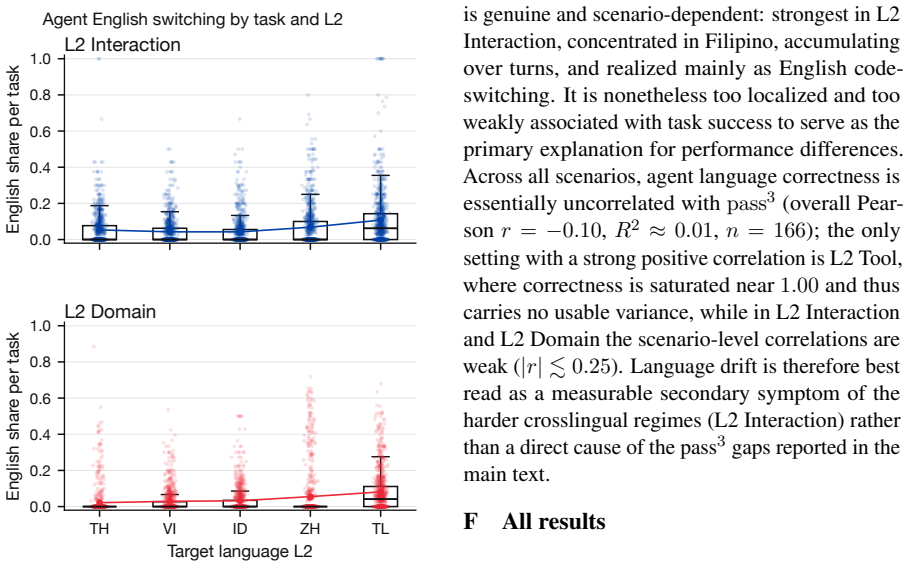
SEATauBench adapts TauBench to five SEA languages and evaluates agents in progressively localized conditions that change the language of user-agent interaction, the tool specifications, and the underlying task domains. Across three recent models the results show English agent capabilities transfer reasonably well when only the conversation language is altered, but quality and robustness degrade sharply once tool specifications and task domains are also localized, with the largest losses appearing under full domain adaptation. The work therefore demonstrates the limits of English-only assessment for measuring agent capabilities in SEA languages and supplies both a diagnostic benchmark and an
What carries the argument
The progressive localization pipeline of SEATauBench, which independently varies conversation language, tool specifications, and task domains while keeping the underlying agent evaluation structure fixed.
If this is right
- Agent robustness remains high when only the conversation language changes.
- Performance and robustness losses increase steadily as tool specifications are localized.
- The largest performance drops occur under full domain adaptation.
- English-only evaluations cannot reliably measure agent capabilities in the target SEA languages.
- The adaptation pipeline can be reused to create similar benchmarks for other languages or regions.
Where Pith is reading between the lines
- The same localization pattern may appear in other low-resource language families outside Southeast Asia.
- Models fine-tuned on localized domain data might reduce the observed drops in full-adaptation settings.
- Native-speaker review of the adapted tasks could be added as a standard validation step in future extensions of the benchmark.
Load-bearing premise
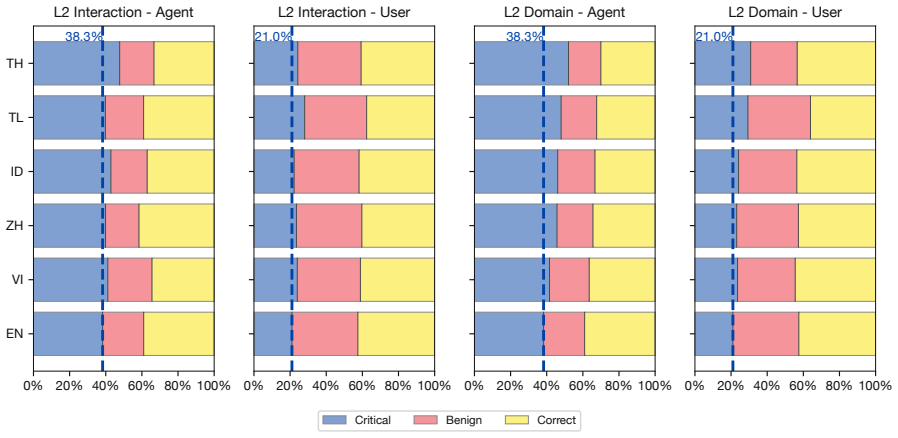
The localized task versions preserve the original difficulty, tool semantics, and evaluation validity without introducing translation or domain-shift artifacts.
What would settle it
Re-running the full set of localized tasks with native-speaker validation and finding materially different difficulty ratings or altered tool behaviors relative to the English originals would undermine the measured performance gaps.
Figures

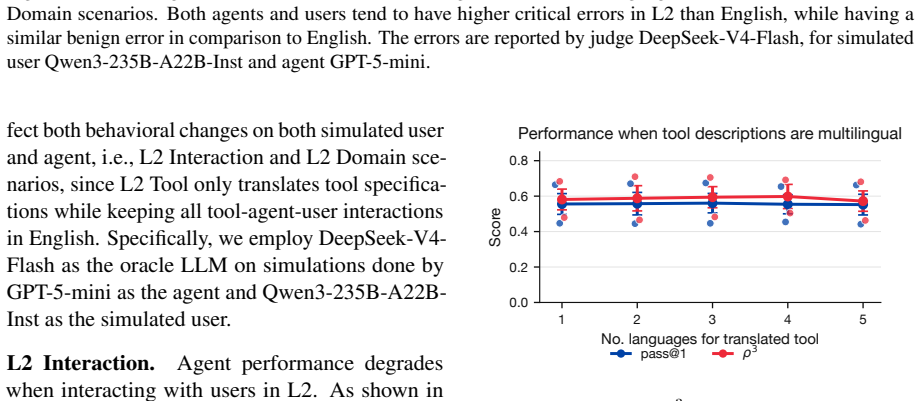
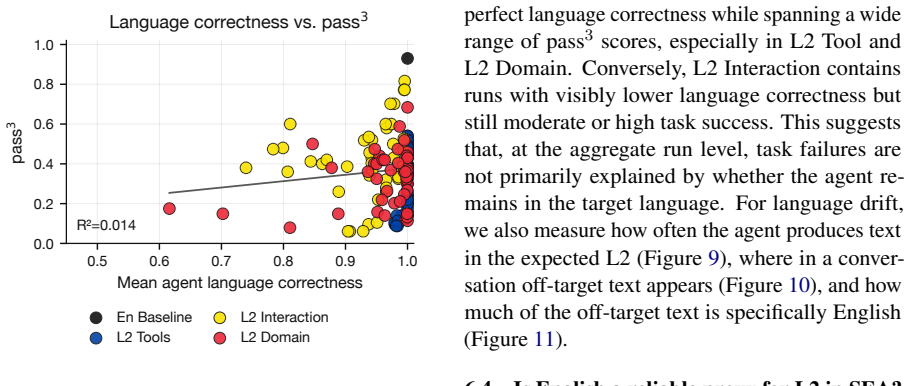
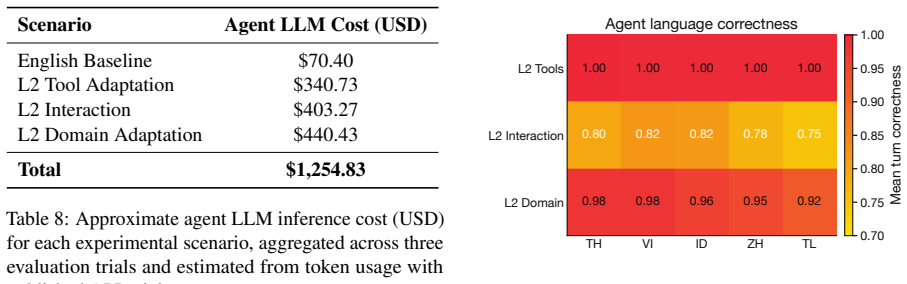

read the original abstract
While AI development and evaluation for Southeast Asia (SEA) has grown rapidly, agent capabilities in regional languages are still poorly understood despite its importance to sovereign AI. To fill this gap, we introduce SEATauBench, the first agent-focused evaluation framework for SEA sovereign AI. SeaTau adapts TauBench to five languages -- Mandarin, Vietnamese, Thai, Indonesian, and Filipino -- and evaluates agents across progressively localized settings that vary the language of user-agent interaction, tool specifications, and task domains. Across three recent models, we find that English agent capabilities transfer reasonably well when only the conversation language changes, but quality and robustness degrade sharply as more task contexts are localized, with the largest losses in full domain adaptation. We also the limits of English-only agent assessment for measuring agent capabilities in SEA languages. More broadly, SeaTau provides a diagnostic benchmark and reusable adaptation pipeline for building reliable multilingual agents for linguistically diverse regions. Data and code can be accessed at github.com/SEACrowd/SEATauBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SEATauBench, the first agent-focused evaluation framework for Southeast Asian languages, by adapting TauBench to Mandarin, Vietnamese, Thai, Indonesian, and Filipino. Agents are evaluated across progressively localized settings that vary conversation language, tool specifications, and task domains. Across three recent models, the central claim is that English agent capabilities transfer reasonably well when only the conversation language changes, but quality and robustness degrade sharply as more task contexts are localized, with the largest losses under full domain adaptation. The work also highlights limits of English-only assessment for SEA languages and releases a diagnostic benchmark plus reusable adaptation pipeline, with data and code publicly available.
Significance. If the empirical patterns hold, the work is significant for sovereign AI efforts in linguistically diverse regions by providing concrete evidence that English-centric agent evaluations are insufficient for SEA languages and by supplying a reusable multi-stage adaptation pipeline with reported human validation. The public release of data and code strengthens reproducibility and enables follow-on work.
minor comments (1)
- [Abstract] Abstract: the sentence beginning 'We also the limits of English-only agent assessment...' is missing a verb and should be revised for grammatical completeness (e.g., 'We also demonstrate the limits...').
Simulated Author's Rebuttal
We thank the referee for their positive assessment of SEATauBench and for recommending minor revision. The provided summary correctly reflects our central findings on language transfer versus domain localization in agent evaluations for Southeast Asian languages. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper performs direct empirical evaluation by adapting TauBench into SEATauBench via an explicit multi-stage localization pipeline (language, tool specs, domains) with reported human validation. Central claims are observational results on model performance degradation across localization levels, not derived predictions, fitted parameters renamed as outputs, or self-referential definitions. No equations, uniqueness theorems, or load-bearing self-citations appear in the provided text; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[2]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[3]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[4]
Assessing Socio-Cultural Alignment and Technical Safety of Sovereign LLM s
Chae, Kyubyung and Kim, Gihoon and Lee, Gyuseong and Kim, Taesup and Lee, Jaejin and Kim, Heejin. Assessing Socio-Cultural Alignment and Technical Safety of Sovereign LLM s. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.559
-
[5]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[9]
2026 , url=
Alejandro Cuadron and Pengfei Yu and Yang Liu and Arpit Gupta , booktitle=. 2026 , url=
2026
-
[10]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Minghao Li and Yingxiu Zhao and Bowen Yu and Feifan Song and Hangyu Li and Haiyang Yu and Zhoujun Li and Fei Huang and Yongbin Li , year=. 2304.08244 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , year=. Gorilla: Large Language Model Connected with Massive. 2305.15334 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Patil and Huanzhi Mao and Charlie Cheng-Jie Ji and Fanjia Yan and Vishnu Suresh and Ion Stoica and Joseph E
Shishir G. Patil and Huanzhi Mao and Charlie Cheng-Jie Ji and Fanjia Yan and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , booktitle=. The Berkeley Function Calling Leaderboard (. 2025 , url=
2025
-
[13]
2025 , url=
Jiarui Lu and Thomas Holleis and Yizhe Zhang and Bernhard Aumayer and Feng Nan and Haoping Bai and Shuang Ma and Shen Ma and Mengyu Li and Guoli Yin and Zirui Wang and Ruoming Pang , booktitle=. 2025 , url=
2025
-
[14]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , year=. 2307.13854 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh and Robert Lo and Lawrence Jang and Vikram Duvvur and Ming Chong Lim and Po-Yu Huang and Graham Neubig and Shuyan Zhou and Ruslan Salakhutdinov and Daniel Fried , year=. 2401.13649 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2026 , eprint=
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author=. 2026 , eprint=
2026
-
[17]
2024 , url=
Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu , booktitle=. 2024 , url=
2024
-
[18]
Windows agent arena: Evaluating multi-modal os agents at scale, 2024
Rogerio Bonatti and Dan Zhao and Francesco Bonacci and Dillon Dupont and Sara Abdali and Yinheng Li and Justin Wagle and Kazuhito Koishida and Arthur Bucker and Lawrence Jang and Zack Hui , year=. Windows Agent Arena: Evaluating Multi-Modal. 2409.08264 , archivePrefix=
-
[19]
Yosephine Susanto and Adithya Venkatadri Hulagadri and Jann Railey Montalan and Jian Gang Ngui and Xian Bin Yong and Weiqi Leong and Hamsawardhini Rengarajan and Peerat Limkonchotiwat and Yifan Mai and William Chandra Tjhi , year=. 2502.14301 , archivePrefix=
-
[20]
Chaoqun Liu and Wenxuan Zhang and Jiahao Ying and Mahani Aljunied and Anh Tuan Luu and Lidong Bing , year=. 2502.06298 , archivePrefix=
-
[21]
2021 , url=
Li, Haoran and Arora, Abhinav and Chen, Shuohui and Gupta, Anchit and Gupta, Sonal and Mehdad, Yashar , booktitle=. 2021 , url=
2021
-
[22]
2023 , url=
Moradshahi, Mehrad and Shen, Tianhao and Bali, Kalika and Choudhury, Monojit and de Chalendar, Gael and Goel, Anmol and Kim, Sungkyun and Kodali, Prashant and Kumaraguru, Ponnurangam and Semmar, Nasredine and Semnani, Sina and Seo, Jiwon and Seshadri, Vivek and Shrivastava, Manish and Sun, Michael and Yadavalli, Aditya and You, Chaobin and Xiong, Deyi and...
2023
-
[23]
2025 , url=
Kulkarni, Mayank and Mazzia, Vittorio and Gaspers, Judith and Hench, Chris and FitzGerald, Jack , booktitle=. 2025 , url=
2025
-
[24]
Alham Fikri Aji and Trevor Cohn , year=. 2508.12459 , archivePrefix=
-
[25]
2026 , eprint=
-Knowledge: Evaluating Conversational Agents over Unstructured Knowledge , author=. 2026 , eprint=
2026
-
[26]
M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling
Budzianowski, Pawe and Wen, Tsung-Hsien and Tseng, Bo-Hsiang and Casanueva, I \ n igo and Ultes, Stefan and Ramadan, Osman and Ga s i \'c , Milica. M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/...
-
[27]
M ulti WOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines
Eric, Mihail and Goel, Rahul and Paul, Shachi and Sethi, Abhishek and Agarwal, Sanchit and Gao, Shuyang and Kumar, Adarsh and Goyal, Anuj and Ku, Peter and Hakkani-Tur, Dilek. M ulti WOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. Proceedings of the Twelfth Language Resources and Evaluation Confer...
2020
-
[28]
Zang, Xiaoxue and Rastogi, Abhinav and Sunkara, Srinivas and Gupta, Raghav and Zhang, Jianguo and Chen, Jindong. M ulti WOZ 2.2 : A Dialogue Dataset with Additional Annotation Corrections and State Tracking Baselines. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI. 2020. doi:10.18653/v1/2020.nlp4convai-1.13
-
[29]
MultiWOZ 2.3: A Multi-domain Task-Oriented Dialogue Dataset Enhanced with Annotation Corrections and Co-Reference Annotation
Han, Ting and Liu, Ximing and Takanabu, Ryuichi and Lian, Yixin and Huang, Chongxuan and Wan, Dazhen and Peng, Wei and Huang, Minlie. MultiWOZ 2.3: A Multi-domain Task-Oriented Dialogue Dataset Enhanced with Annotation Corrections and Co-Reference Annotation. Natural Language Processing and Chinese Computing. 2021
2021
-
[30]
Ye, Fanghua and Manotumruksa, Jarana and Yilmaz, Emine. M ulti WOZ 2.4: A Multi-Domain Task-Oriented Dialogue Dataset with Essential Annotation Corrections to Improve State Tracking Evaluation. Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2022. doi:10.18653/v1/2022.sigdial-1.34
-
[31]
FitzGerald, Jack and Hench, Christopher and Peris, Charith and Mackie, Scott and Rottmann, Kay and Sanchez, Ana and Nash, Aaron and Urbach, Liam and Kakarala, Vishesh and Singh, Richa and Ranganath, Swetha and Crist, Laurie and Britan, Misha and Leeuwis, Wouter and Tur, Gokhan and Natarajan, Prem. MASSIVE : A 1 M -Example Multilingual Natural Language Und...
-
[32]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , url =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and li, dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. ToolLLM: Facilitating Large Language Models t...
-
[33]
Huang, Kung-Hsiang and Prabhakar, Akshara and Dhawan, Sidharth and Mao, Yixin and Wang, Huan and Savarese, Silvio and Xiong, Caiming and Laban, Philippe and Wu, Chien-Sheng. CRMA rena: Understanding the Capacity of LLM Agents to Perform Professional CRM Tasks in Realistic Environments. Proceedings of the 2025 Conference of the Nations of the Americas Chap...
-
[34]
Frank F. Xu and Yufan Song and Boxuan Li and Yuxuan Tang and Kritanjali Jain and Mengxue Bao and Zora Zhiruo Wang and Xuhui Zhou and Zhitong Guo and Murong Cao and Mingyang Yang and Hao Yang Lu and Amaad Martin and Zhe Su and Leander Melroy Maben and Raj Mehta and Wayne Chi and Lawrence Keunho Jang and Yiqing Xie and Shuyan Zhou and Graham Neubig , bookti...
2026
-
[35]
2024 , eprint=
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? , author=. 2024 , eprint=
2024
-
[36]
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks , url =
Boisvert, L\'. WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks , url =. Advances in Neural Information Processing Systems , doi =
-
[37]
Kim and Samuel Miserendino and Gildas Chabot and David Li and Patrick Chao and Michael Sharman and Alexandra Barr and Amelia Glaese and Jerry Tworek , booktitle=
Tejal Patwardhan and Rachel Dias and Elizabeth Proehl and Grace Kim and Michele Wang and Olivia Watkins and Simon Posada Fishman and Marwan Aljubeh and Phoebe Thacker and Laurance Fauconnet and Natalie S. Kim and Samuel Miserendino and Gildas Chabot and David Li and Patrick Chao and Michael Sharman and Alexandra Barr and Amelia Glaese and Jerry Tworek , b...
2026
-
[38]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[39]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[40]
G lot E val: A Test Suite for Massively Multilingual Evaluation of Large Language Models
Luo, Hengyu and Li, Zihao and Attieh, Joseph and Devkota, Sawal and de Gibert, Ona and Huang, Xu and Ji, Shaoxiong and Lin, Peiqin and Mantina, Bhavani Sai Praneeth Varma and Sreenidhi, Ananda and V. G lot E val: A Test Suite for Massively Multilingual Evaluation of Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural ...
-
[41]
2024 , eprint=
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark , author=. 2024 , eprint=
2024
-
[42]
2025 , howpublished =
2025
-
[43]
N usa X : Multilingual Parallel Sentiment Dataset for 10 I ndonesian Local Languages
Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya, Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony, Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo, Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau, Jey Han and Sennrich, Rico and Ruder, Sebastian. N usa X : Multilingual Parallel Sentiment Dataset for 10 I ndonesian Loca...
-
[44]
Cahyawijaya, Samuel and Lovenia, Holy and Koto, Fajri and Adhista, Dea and Dave, Emmanuel and Oktavianti, Sarah and Akbar, Salsabil and Lee, Jhonson and Shadieq, Nuur and Cenggoro, Tjeng Wawan and Linuwih, Hanung and Wilie, Bryan and Muridan, Galih and Winata, Genta and Moeljadi, David and Aji, Alham Fikri and Purwarianti, Ayu and Fung, Pascale. N usa W r...
-
[45]
N usa D ialogue: Dialogue Summarization and Generation for Underrepresented and Extremely Low-Resource Languages
Purwarianti, Ayu and Adhista, Dea and Baptiso, Agung and Mahfuzh, Miftahul and Sabila, Yusrina and Adila, Aulia and Cahyawijaya, Samuel and Aji, Alham Fikri. N usa D ialogue: Dialogue Summarization and Generation for Underrepresented and Extremely Low-Resource Languages. Proceedings of the Second Workshop in South East Asian Language Processing. 2025
2025
-
[46]
I ndo T o D : A Multi-Domain I ndonesian Benchmark For End-to-End Task-Oriented Dialogue Systems
Kautsar, Muhammad and Nurdini, Rahmah and Cahyawijaya, Samuel and Winata, Genta and Purwarianti, Ayu. I ndo T o D : A Multi-Domain I ndonesian Benchmark For End-to-End Task-Oriented Dialogue Systems. Proceedings of the First Workshop in South East Asian Language Processing. 2023. doi:10.18653/v1/2023.sealp-1.7
-
[47]
Lovenia, Holy and Mahendra, Rahmad and Akbar, Salsabil Maulana and Miranda, Lester James V. and Santoso, Jennifer and Aco, Elyanah and Fadhilah, Akhdan and Mansurov, Jonibek and Imperial, Joseph Marvin and Kampman, Onno P. and Moniz, Joel Ruben Antony and Habibi, Muhammad Ravi Shulthan and Hudi, Frederikus and Montalan, Railey and Ignatius, Ryan and Lopo,...
-
[48]
Cahyawijaya, Samuel and Zhang, Ruochen and Cruz, Jan Christian Blaise and Lovenia, Holy and Gilbert, Elisa and Nomoto, Hiroki and Aji, Alham Fikri. Thank You, Stingray: Multilingual Large Language Models Can Not (Yet) Disambiguate Cross-Lingual Word Senses. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.f...
-
[49]
S ea E xam and S ea B ench: Benchmarking LLM s with Local Multilingual Questions in S outheast A sia
Liu, Chaoqun and Zhang, Wenxuan and Ying, Jiahao and Aljunied, Mahani and Luu, Anh Tuan and Bing, Lidong. S ea E xam and S ea B ench: Benchmarking LLM s with Local Multilingual Questions in S outheast A sia. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.341
-
[50]
SEA - HELM : S outheast A sian Holistic Evaluation of Language Models
Susanto, Yosephine and Hulagadri, Adithya Venkatadri and Montalan, Jann Railey and Ngui, Jian Gang and Yong, Xianbin and Leong, Wei Qi and Rengarajan, Hamsawardhini and Limkonchotiwat, Peerat and Mai, Yifan and Tjhi, William Chandra. SEA - HELM : S outheast A sian Holistic Evaluation of Language Models. Findings of the Association for Computational Lingui...
-
[51]
N usa C rowd: Open Source Initiative for I ndonesian NLP Resources
Cahyawijaya, Samuel and Lovenia, Holy and Aji, Alham Fikri and Winata, Genta and Wilie, Bryan and Koto, Fajri and Mahendra, Rahmad and Wibisono, Christian and Romadhony, Ade and Vincentio, Karissa and Santoso, Jennifer and Moeljadi, David and Wirawan, Cahya and Hudi, Frederikus and Wicaksono, Muhammad Satrio and Parmonangan, Ivan and Alfina, Ika and Putra...
-
[52]
and Han, Kenneth Chen Ko and Santos, Anjela Gail D
Cahyawijaya, Samuel and Lovenia, Holy and Moniz, Joel Ruben Antony and Wong, Tack Hwa and Farhansyah, Mohammad Rifqi and Maung, Thant Thiri and Hudi, Frederikus and Anugraha, David and Habibi, Muhammad Ravi Shulthan and Qorib, Muhammad Reza and Agarwal, Amit and Imperial, Joseph Marvin and Patel, Hitesh Laxmichand and Feliren, Vicky and Nasution, Bahrul I...
-
[53]
2026 , eprint=
Anthropogenic Regional Adaptation in Multimodal Vision-Language Model , author=. 2026 , eprint=
2026
-
[54]
SEA - VQA : S outheast A sian Cultural Context Dataset For Visual Question Answering
Urailertprasert, Norawit and Limkonchotiwat, Peerat and Suwajanakorn, Supasorn and Nutanong, Sarana. SEA - VQA : S outheast A sian Cultural Context Dataset For Visual Question Answering. Proceedings of the 3rd Workshop on Advances in Language and Vision Research (ALVR). 2024. doi:10.18653/v1/2024.alvr-1.15
-
[55]
2024 , howpublished =
2024
-
[56]
2025 , eprint=
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. 2025 , eprint=
2025
-
[57]
2026 , eprint=
-Voice: Benchmarking Full-Duplex Voice Agents on Real-World Domains , author=. 2026 , eprint=
2026
-
[58]
Position: The Right to
Rashid Mushkani and Hugo Berard and Allison Cohen and Shin Koseki , booktitle=. Position: The Right to. 2025 , url=
2025
-
[59]
2026 , url =
Barasa, Hilda and Tay, PeiChin and McBride, Keegan and Iosad, Alexander and M. 2026 , url =
2026
-
[60]
Sovereignty in the Age of AI: Strategic Choices, Structural Dependencies , month = jan, year =
-
[61]
2026 , month = apr, day =
Bhandari, Manik and Modi, Gaurav , title =. 2026 , month = apr, day =
2026
-
[62]
Why Sovereign Artificial Intelligence Is Imperative in Southeast Asia , year =
-
[63]
Frontiers in Artificial Intelligence , VOLUME=
Putra, Bama Andika , TITLE=. Frontiers in Artificial Intelligence , VOLUME=. 2024 , URL=. doi:10.3389/frai.2024.1411838 , ISSN=
-
[64]
2024 , url =
Wenxuan Zhang and Hou Pong Chan and Yiran Zhao and Mahani Aljunied and Jianyu Wang and Chaoqun Liu and Yue Deng and Zhiqiang Hu and Weiwen Xu and Yew Ken Chia and Xin Li and Lidong Bing , title =. 2024 , url =
2024
-
[65]
2024 , booktitle =
Xuan-Phi Nguyen and Wenxuan Zhang and Xin Li and Mahani Aljunied and Zhiqiang Hu and Chenhui Shen and Yew Ken Chia and Xingxuan Li and Jianyu Wang, Qingyu Tan and Liying Cheng and Guanzheng Chen and Yue Deng and Sen Yang and Chaoqun Liu and Hang Zhang and Lidong Bing , title =. 2024 , booktitle =
2024
-
[66]
2026 , eprint=
Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.