Generative Learning as a Tool to Improve Perception of Emotional Body Motion Expressions
Pith reviewed 2026-06-30 09:17 UTC · model grok-4.3
The pith
A generative model can implicitly learn to produce recognizable emotional body motions from motion-capture data using only emotion labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
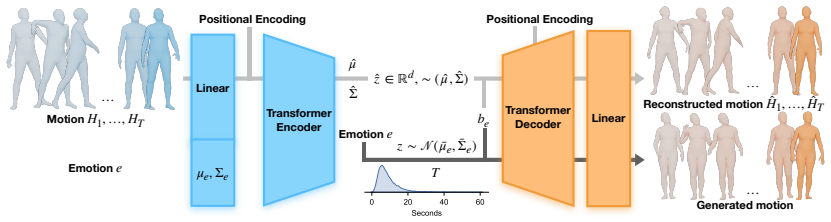
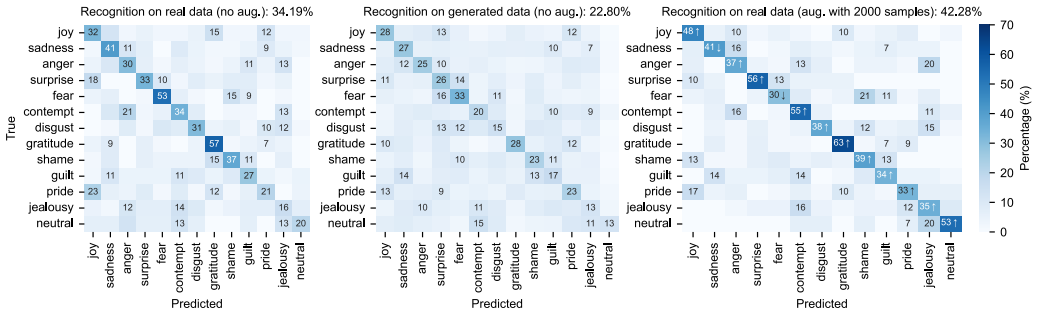
A Transformer-based generative model trained on a dataset of emotional performances by 49 Japanese actors can generate expressive motions conditioned on 13 discrete emotion labels that are recognizable by both an LSTM classifier (22.80 percent accuracy) and Japanese human raters (24.91 percent accuracy), demonstrating implicit learning of emotional body motions from culturally grounded data without explicit emotion-motion guidance. The model further supports practical tasks including augmenting recognition models, extracting emotion-specific patterns, and synthesizing emotion intensity transitions.
What carries the argument
Transformer-based generative model conditioned on 13 discrete emotion labels that maps labels to motion sequences learned from motion-capture data.
If this is right
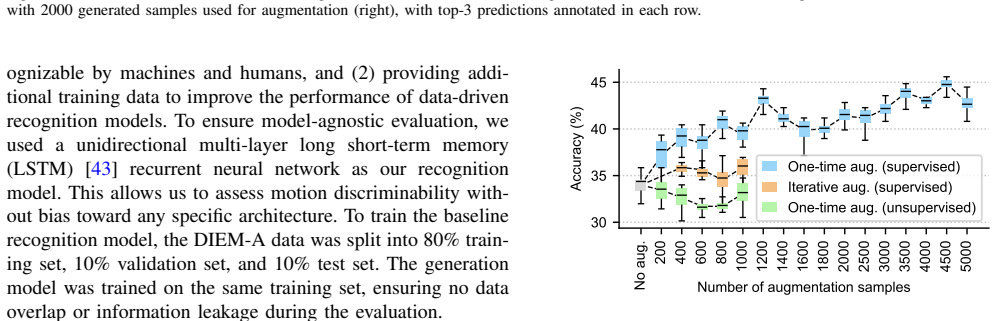
- The generated motions can be added to training sets to improve the accuracy of separate emotion recognition models.
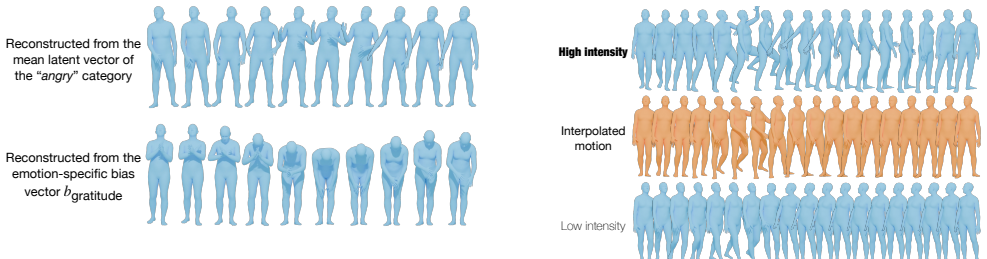
- Representative motion patterns specific to each of the 13 emotions can be extracted from the trained generative model.
- Smooth transitions between different emotion intensities can be synthesized by varying the conditioning labels.
Where Pith is reading between the lines
- The same conditioning approach could be tested on motion datasets from additional cultures to check whether the learned patterns generalize beyond Japanese actors.
- Generated motions could be inserted into virtual-reality avatars to test whether they improve perceived emotional clarity in real-time interactions.
- The method offers a route to create varied training examples for social-robotics systems without manually designing each emotional movement.
Load-bearing premise
Conditioning on only 13 discrete emotion labels from one cultural group of actors is enough for the model to discover distinguishable motion patterns.
What would settle it
If retraining the same model on a non-Japanese dataset or testing the generated motions with raters from another culture yields recognition rates at chance level, the implicit-learning claim would not hold.
Figures


read the original abstract
Emotional body motion expressions are an essential element of non-verbal communication. Effectively conveying these expressions through technology is of utmost importance, for example, with virtual reality avatars and in social robotics. Recent advances in generative models have opened new opportunities for advancing research on emotional body motion learning. However, generating accurate emotional expression representations is challenging, given the subtlety of emotional cues, individual variability, and cultural differences. We investigate whether a generative model can implicitly learn emotional body motions directly from culturally grounded motion-capture data, without explicit emotion-motion guidance. Using a dataset of emotional performances by 49 Japanese actors, we trained a Transformer-based generative model to generate expressive motions conditioned on 13 discrete emotion labels. We evaluate the generated motions from two perspectives: (1) an LSTM-based classifier to assess recognizability by machine observers, achieving a recognition accuracy of 22.80%, and (2) a human perception study with Japanese raters to assess alignment with human affective interpretations, yielding a recognition accuracy of 24.91%. Beyond these, we evaluate the utility of generative modeling for three practical tasks: augmenting emotion recognition models, extracting representative emotion-specific motion patterns, and synthesizing smooth transitions between emotion intensities. Our findings highlight the potential of implicit, data-driven generative modeling to enhance affective computing applications and our understanding of emotion expressions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a Transformer-based generative model trained on motion-capture data from 49 Japanese actors performing 13 emotions can implicitly learn emotional body motions directly from the data without explicit emotion-motion guidance. This is supported by reported recognition accuracies of 22.80% (LSTM classifier) and 24.91% (human raters), with additional evaluations showing utility for augmenting emotion recognition, extracting representative patterns, and synthesizing emotion transitions.
Significance. If the central claim can be reconciled with the method, the work could contribute to affective computing by illustrating how label-conditioned generative models trained on culturally specific motion data might support applications in VR avatars and social robotics. The dual machine-human evaluation approach is a positive aspect, though the modest accuracies limit the strength of the practical implications.
major comments (2)
- [Abstract] Abstract: The claim that the model learns emotional body motions 'without explicit emotion-motion guidance' is directly contradicted by the described training procedure, in which the Transformer is conditioned on 13 discrete emotion labels. This setup constitutes supervised conditional generation rather than implicit or guidance-free learning, making the qualifier load-bearing for the headline claim.
- [Abstract] Abstract (evaluation paragraph): The reported accuracies of 22.80% and 24.91% are presented without baselines (e.g., chance level of ~7.7% for 13 classes), statistical tests, or details on data splits and held-out sets. These omissions prevent assessment of whether the results robustly demonstrate successful learning beyond what explicit label conditioning would be expected to produce.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the abstract accordingly to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the model learns emotional body motions 'without explicit emotion-motion guidance' is directly contradicted by the described training procedure, in which the Transformer is conditioned on 13 discrete emotion labels. This setup constitutes supervised conditional generation rather than implicit or guidance-free learning, making the qualifier load-bearing for the headline claim.
Authors: We agree that the phrasing 'without explicit emotion-motion guidance' is inconsistent with the label-conditioned training procedure and risks overstating the implicit nature of the learning. The model is trained via supervised conditioning on the 13 emotion labels, allowing it to learn motion patterns from the data. We will revise the abstract to remove this qualifier and state that the Transformer is trained as a label-conditioned generative model on the motion-capture data, enabling it to capture emotion-specific patterns implicitly. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): The reported accuracies of 22.80% and 24.91% are presented without baselines (e.g., chance level of ~7.7% for 13 classes), statistical tests, or details on data splits and held-out sets. These omissions prevent assessment of whether the results robustly demonstrate successful learning beyond what explicit label conditioning would be expected to produce.
Authors: We agree that the abstract would be strengthened by including context on the evaluation. The full manuscript details the held-out actor splits for testing, reports statistical significance, and compares against chance. We will revise the abstract to note the chance baseline of ~7.7% and that the accuracies exceed this level significantly (with full tests and split details in the main text). revision: yes
Circularity Check
No circularity: empirical evaluation on held-out generations
full rationale
The paper trains a conditional Transformer on labeled motion-capture data and reports measured recognition accuracies (22.80% machine, 24.91% human) from separate LSTM classifiers and human raters on the generated outputs. These are external evaluation results, not quantities that reduce by construction to the training inputs or fitted parameters. No equations, self-citations, or ansatzes are invoked that would make the reported recognizability tautological. The study is self-contained against external benchmarks (classifier accuracy, human perception study), satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of emotion categories
axioms (1)
- domain assumption Motion-capture recordings faithfully capture distinguishable emotional expressions
Reference graph
Works this paper leans on
-
[1]
Automatic facial expression analysis: a survey,
B. Fasel and J. Luettin, “Automatic facial expression analysis: a survey,” Pattern recognition, vol. 36, no. 1, pp. 259–275, 2003. 1
2003
-
[2]
V ocal communication of emotion: A review of research paradigms,
K. R. Scherer, “V ocal communication of emotion: A review of research paradigms,”Speech communication, vol. 40, no. 1-2, pp. 227–256, 2003. 1
2003
-
[3]
Deep facial expression recognition: A survey,
S. Li and W. Deng, “Deep facial expression recognition: A survey,”IEEE transactions on affective computing, vol. 13, no. 3, pp. 1195–1215, 2020. 1
2020
-
[4]
The perception of emo- tion in body expressions,
B. De Gelder, A. W. de Borst, and R. Watson, “The perception of emo- tion in body expressions,”Wiley Interdisciplinary Reviews: Cognitive Science, vol. 6, no. 2, pp. 149–158, 2015. 1
2015
-
[5]
L. Elansary, Z. Taha, and W. Gad, “Survey on emotion recognition through posture detection and the possibility of its application in virtual reality,”arXiv preprint arXiv:2408.01728, 2024. 1
-
[6]
S. Mousavi, “Synthetic data generation by supervised neural gas network for physiological emotion recognition data,”arXiv preprint arXiv:2501.16353, 2025. 1
-
[7]
Action-conditioned 3D human motion synthesis with transformer V AE,
M. Petrovich, M. J. Black, and G. Varol, “Action-conditioned 3D human motion synthesis with transformer V AE,” inInternational Conference on Computer Vision (ICCV), 2021. 1, 2, 4, 5
2021
-
[8]
Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis,
——, “Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9488–9497. 1, 2
2023
-
[9]
Motiongpt: Human motion as a foreign language,
B. Jiang, X. Chen, W. Liu, J. Yu, G. Yu, and T. Chen, “Motiongpt: Human motion as a foreign language,”Advances in Neural Information Processing Systems, vol. 36, pp. 20 067–20 079, 2023. 1, 2
2023
-
[10]
Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements,
L. F. Barrett, R. Adolphs, S. Marsella, A. M. Martinez, and S. D. Pollak, “Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements,”Psychological Science in the Public Interest, vol. 20, no. 1, pp. 1–68, Jul. 2019. 2
2019
-
[11]
Personality and the enactment of emotion,
H. S. Friedman, R. E. Riggio, and D. O. Segall, “Personality and the enactment of emotion,”Journal of Nonverbal Behavior, vol. 5, no. 1, pp. 35–48, Sep. 1980. 2
1980
-
[12]
Affective body expression perception and recognition: A survey,
A. Kleinsmith and N. Bianchi-Berthouze, “Affective body expression perception and recognition: A survey,”IEEE Transactions on Affective Computing, vol. 4, no. 1, pp. 15–33, 2013. 2
2013
-
[13]
Towards emotion- enriched text-to-motion generation via llm-guided limb-level emotion manipulating,
T. Yu, J. Wang, J. Wang, J. Luo, and G. Zhou, “Towards emotion- enriched text-to-motion generation via llm-guided limb-level emotion manipulating,” inProceedings of the 32nd ACM International Confer- ence on Multimedia, 2024, pp. 612–621. 2
2024
-
[14]
Recurrent Network Models for Human Dynamics,
K. Fragkiadaki, S. Levine, P. Felsen, and J. Malik, “Recurrent Network Models for Human Dynamics,” 2015, version Number: 2. 2
2015
-
[15]
On Human Motion Prediction Using Recurrent Neural Networks,
J. Martinez, M. J. Black, and J. Romero, “On Human Motion Prediction Using Recurrent Neural Networks,” in2017 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). Honolulu, HI: IEEE, Jul. 2017, pp. 4674–4683. 2
2017
-
[16]
Action2motion: Conditioned generation of 3d human motions,
C. Guo, X. Zuo, S. Wang, S. Zou, Q. Sun, A. Deng, M. Gong, and L. Cheng, “Action2motion: Conditioned generation of 3d human motions,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 2021–2029. 2
2020
-
[17]
Action-conditioned 3d human motion synthesis with transformer vae,
M. Petrovich, M. J. Black, and G. Varol, “Action-conditioned 3d human motion synthesis with transformer vae,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 985–10 995. 2, 3
2021
-
[18]
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano, “Human motion diffusion model,”arXiv preprint arXiv:2209.14916, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Executing your commands via motion diffusion in latent space,
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu, “Executing your commands via motion diffusion in latent space,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 000–18 010. 2, 4
2023
-
[20]
Language2Pose: Natural Language Grounded Pose Forecasting,
C. Ahuja and L.-P. Morency, “Language2Pose: Natural Language Grounded Pose Forecasting,” in2019 International Conference on 3D Vision (3DV). Qu ´ebec City, QC, Canada: IEEE, Sep. 2019, pp. 719–
2019
-
[21]
Temos: Generating diverse human motions from textual descriptions,
M. Petrovich, M. J. Black, and G. Varol, “Temos: Generating diverse human motions from textual descriptions,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 480–497. 2
2022
-
[22]
We are More than Our Joints: Predicting how 3D Bodies Move,
Y . Zhang, M. J. Black, and S. Tang, “We are More than Our Joints: Predicting how 3D Bodies Move,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, Jun. 2021, pp. 3371–3381. 2
2021
-
[23]
Generat- ing diverse and natural 3d human motions from text,
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng, “Generat- ing diverse and natural 3d human motions from text,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5152–5161. 2
2022
-
[24]
Deep Facial Expression Recognition: A Survey,
S. Li and W. Deng, “Deep Facial Expression Recognition: A Survey,” IEEE Transactions on Affective Computing, vol. 13, no. 3, pp. 1195– 1215, Jul. 2022. 2
2022
-
[25]
Speech Emotion Recog- nition: A Comprehensive Survey,
M. J. Al-Dujaili and A. Ebrahimi-Moghadam, “Speech Emotion Recog- nition: A Comprehensive Survey,”Wireless Personal Communications, vol. 129, no. 4, pp. 2525–2561, Apr. 2023. 2
2023
-
[26]
X2Face: A Network for Controlling Face Generation Using Images, Audio, and Pose Codes,
O. Wiles, A. S. Koepke, and A. Zisserman, “X2Face: A Network for Controlling Face Generation Using Images, Audio, and Pose Codes,” in Computer Vision – ECCV 2018, V . Ferrari, M. Hebert, C. Sminchisescu, and Y . Weiss, Eds. Cham: Springer International Publishing, 2018, vol. 11217, pp. 690–706, series Title: Lecture Notes in Computer Science. 2
2018
-
[27]
Text2gestures: A transformer-based network for generating emotive body gestures for virtual agents,
U. Bhattacharya, N. Rewkowski, A. Banerjee, P. Guhan, A. Bera, and D. Manocha, “Text2gestures: A transformer-based network for generating emotive body gestures for virtual agents,” in2021 IEEE virtual reality and 3D user interfaces (VR). IEEE, 2021, pp. 1–10. 2
2021
-
[28]
Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis,
H. Liu, Z. Zhu, N. Iwamoto, Y . Peng, Z. Li, Y . Zhou, E. Bozkurt, and B. Zheng, “Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis,” inEuropean conference on computer vision. Springer, 2022, pp. 612–630. 2
2022
-
[29]
Emotionally Enhanced Talking Face Generation,
S. Goyal, S. Bhagat, S. Uppal, H. Jangra, Y . Yu, Y . Yin, and R. R. Shah, “Emotionally Enhanced Talking Face Generation,” inProceedings of the 1st International Workshop on Multimedia Content Generation and Evaluation: New Methods and Practice. Ottawa ON Canada: ACM, Oct. 2023, pp. 81–90. 2
2023
-
[30]
Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation,
X. Qi, C. Liu, L. Li, J. Hou, H. Xin, and X. Yu, “Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation,”IEEE Transactions on Multimedia, 2024. 2
2024
-
[31]
Weakly-supervised emotion transition learning for diverse 3d co-speech gesture generation,
X. Qi, J. Pan, P. Li, R. Yuan, X. Chi, M. Li, W. Luo, W. Xue, S. Zhang, Q. Liuet al., “Weakly-supervised emotion transition learning for diverse 3d co-speech gesture generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 424–10 434. 2
2024
-
[32]
Embodying Emotion,
P. M. Niedenthal, “Embodying Emotion,”Science, vol. 316, no. 5827, pp. 1002–1005, May 2007. 2
2007
-
[33]
The spontaneous expression of pride and shame: Evidence for biologically innate nonverbal displays,
J. L. Tracy and D. Matsumoto, “The spontaneous expression of pride and shame: Evidence for biologically innate nonverbal displays,”Pro- ceedings of the National Academy of Sciences, vol. 105, no. 33, pp. 11 655–11 660, Aug. 2008. 2
2008
-
[34]
The contribution of general features of body movement to the attribution of emotions,
M. De Meijer, “The contribution of general features of body movement to the attribution of emotions,”Journal of Nonverbal Behavior, vol. 13, no. 4, pp. 247–268, Dec. 1989. 2
1989
-
[35]
On the universality and cultural specificity of emotion recognition: A meta-analysis
H. A. Elfenbein and N. Ambady, “On the universality and cultural specificity of emotion recognition: A meta-analysis.”Psychological Bulletin, vol. 128, no. 2, pp. 203–235, 2002. 3
2002
-
[36]
Cross-cultural differences in recognizing affect from body posture,
A. Kleinsmith, P. R. De Silva, and N. Bianchi-Berthouze, “Cross-cultural differences in recognizing affect from body posture,”Interacting with Computers, vol. 18, no. 6, pp. 1371–1389, Dec. 2006. 3
2006
-
[37]
Asian emotional body movement database: Diverse intercultural e- motion database of asian performers (diem-a),
M. Cheng, C.-H. Tseng, K. Fujiwara, V . Schneider, and Y . Kitamura, “Asian emotional body movement database: Diverse intercultural e- motion database of asian performers (diem-a),” in2025 13th Interna- tional Conference on Affective Computing and Intelligent Interaction (ACII), 2025. 3, 8
2025
-
[38]
Smpl: a skinned multi-person linear model,
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: a skinned multi-person linear model,”ACM Trans. Graph., vol. 34, no. 6, Oct. 2015. 3
2015
-
[39]
AMASS: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “AMASS: Archive of motion capture as surface shapes,” inInternational Conference on Computer Vision, Oct. 2019, pp. 5442–5451. 3
2019
-
[40]
BABEL: Bodies, action and behavior with english labels,
A. R. Punnakkal, A. Chandrasekaran, N. Athanasiou, A. Quiros- Ramirez, and M. J. Black, “BABEL: Bodies, action and behavior with english labels,” inProceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2021, pp. 722–731. 3
2021
-
[41]
Soul dancer: Emotion-based human action generation,
Y . Hou, H. Yao, X. Sun, and H. Li, “Soul dancer: Emotion-based human action generation,”ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 15, no. 3s, pp. 1–19,
-
[42]
A unified framework for multimodal, multi-part human motion synthesis,
Z. Zhou, Y . Wan, and B. Wang, “A unified framework for multimodal, multi-part human motion synthesis,”arXiv preprint arXiv:2311.16471,
-
[43]
Long short-term memory,
S. Hochreiter, “Long short-term memory,”Neural Computation MIT- Press, 1997. 5
1997
-
[44]
Toward an asian-based bodily movement database for emotional communication,
M. Cheng, C.-h. Tseng, K. Fujiwara, S. Higashiyama, A. Weng, and Y . Kitamura, “Toward an asian-based bodily movement database for emotional communication,”Behavior Research Methods, vol. 57, no. 1, p. 10, 2024. 6
2024
-
[45]
Emotion recognition in spontaneous and acted dialogues,
L. Tian, J. D. Moore, and C. Lai, “Emotion recognition in spontaneous and acted dialogues,” in2015 international conference on affective computing and intelligent interaction (ACII). IEEE, 2015, pp. 698–
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.