Mechanistic Personality Analysis of LLMs Steering Personality via Latent Feature Interventions
Pith reviewed 2026-06-30 09:42 UTC · model grok-4.3
The pith
LLMs' personality traits can be steered by adding small shifts to specific latent directions in their activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
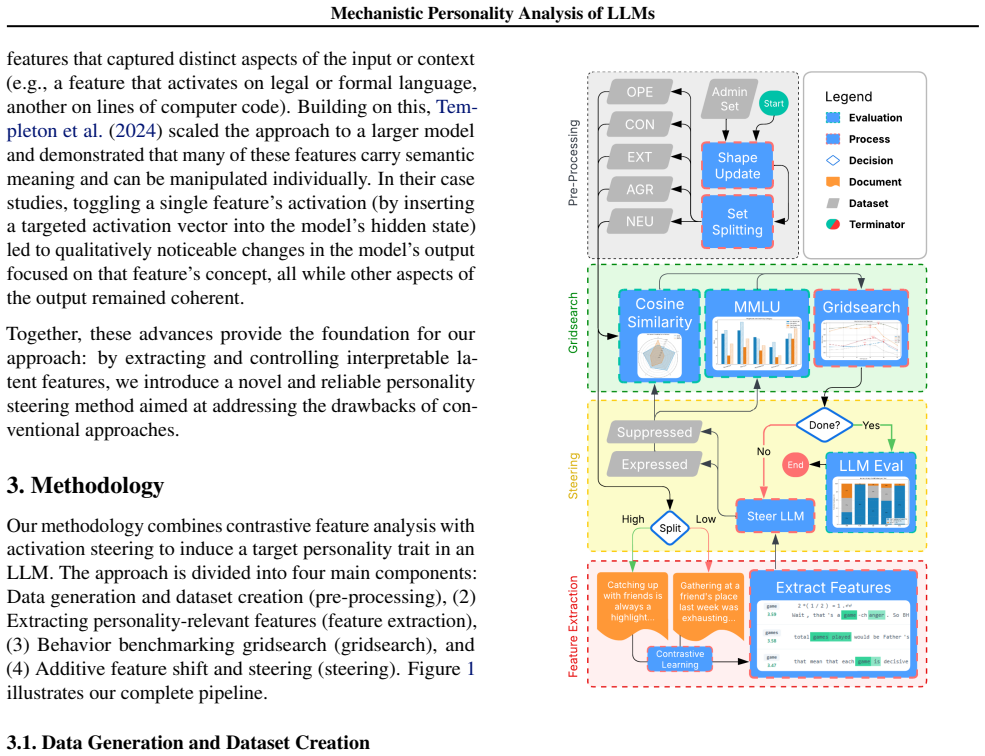
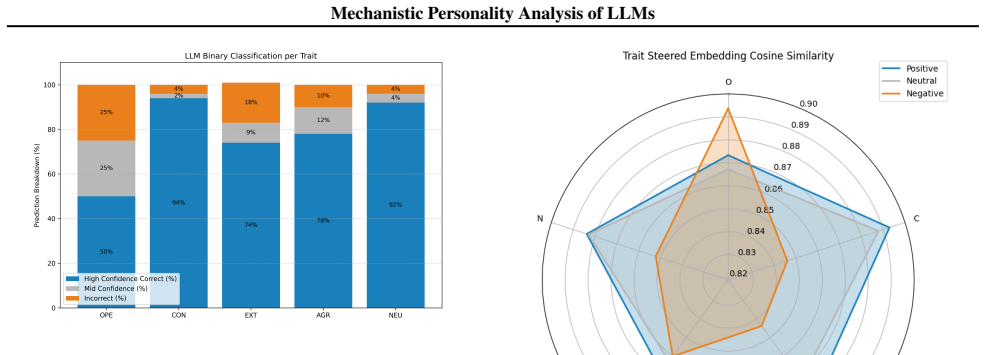
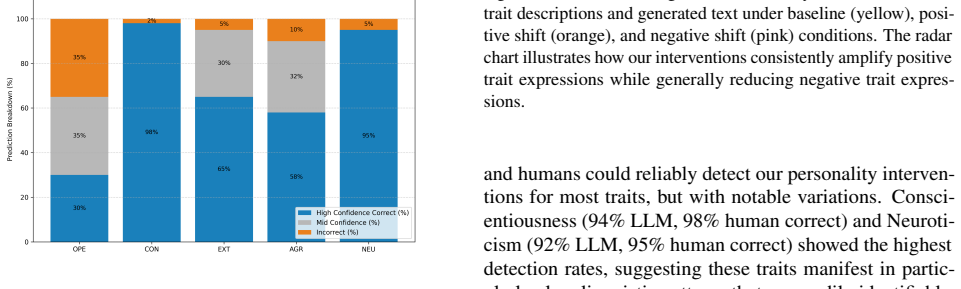
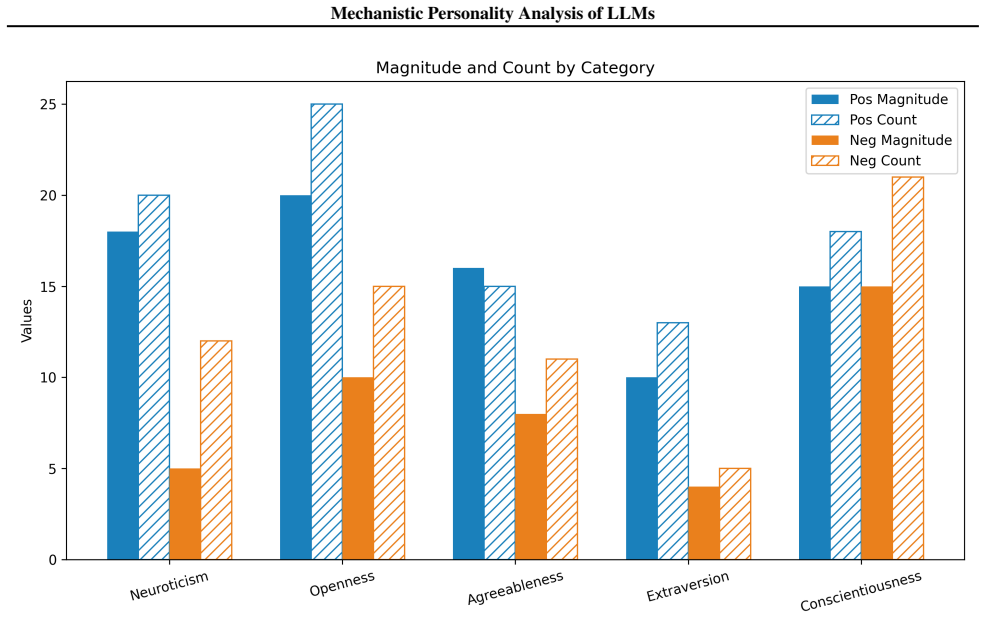
The authors show that latent directions identified via sparse autoencoders and contrastive activation analysis in the residual stream can be used to construct additive steering vectors. Applying these vectors enhances the expression of a target OCEAN trait in generated text. The method uses a linear weighting heuristic optimized via grid search to balance trait expression against task performance.
What carries the argument
The additive steering vector constructed from SAE latent directions via contrastive activation analysis, applied as a small shift in the residual stream.
If this is right
- Targeted personality traits can be enhanced while overall language modeling performance remains high on standard benchmarks.
- Grid search optimization finds combinations of feature shifts that balance personality expression with task performance.
- This approach offers a mechanistic alternative to prompt engineering for controlling LLM personality.
Where Pith is reading between the lines
- If the directions prove causal, similar interventions could allow editing of other model behaviors like safety or consistency after deployment.
- The technique might generalize to steering non-personality attributes by identifying their corresponding latent directions.
- It suggests personality expression in LLMs may depend on a limited set of identifiable features rather than being fully distributed.
Load-bearing premise
The latent directions identified by the sparse autoencoders and contrastive analysis causally correspond to the OCEAN personality traits rather than just appearing in the training data.
What would settle it
Measuring personality in model outputs before and after applying the steering vector and finding no statistically significant change in trait scores on validated tests.
Figures
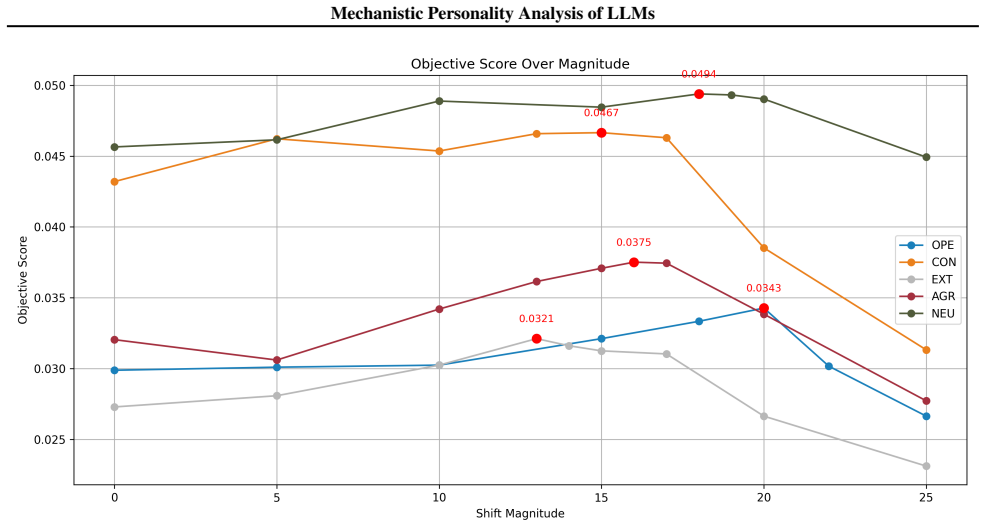
read the original abstract
Large Language Models (LLMs) have demonstrated the ability to simulate human-like OCEAN personality traits in generated text. Previous efforts have focused on prompt engineering or fine-tuning to shape LLM personality. In this work, we propose a mechanistic interpretability approach that directly intervenes on the model's latent features. Our method identifies latent directions in the residual stream corresponding to a target OCEAN trait using sparse autoencoders (SAEs) and contrastive activation analysis. We formalize an additive steering vector in activation space and demonstrate how applying a small additive shift to the hidden states enhances the target trait while preserving overall language modeling performance. To determine the optimal combination of feature shifts, we explore a linear weighting heuristic with grid search optimization that balances personality expression with task performance. Our approach shows promise in controllably steering personality traits at the mechanistic level while maintaining high performance on standard benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a mechanistic interpretability approach for steering OCEAN personality traits in LLMs by identifying latent directions in the residual stream using sparse autoencoders (SAEs) and contrastive activation analysis. It formalizes additive steering vectors applied to hidden states and uses a linear weighting heuristic with grid search to optimize the balance between personality expression and task performance, asserting that this method allows controllable steering at the mechanistic level while maintaining high performance on standard benchmarks.
Significance. If the results hold and the interventions prove causally effective, this would represent a significant advance in controllable generation and mechanistic understanding of LLMs, offering a way to edit specific behavioral traits without retraining or prompting, which could have implications for alignment and personalized AI systems.
major comments (3)
- [Abstract] The abstract states that the method 'shows promise' and 'demonstrates' effects but supplies no quantitative results, error bars, benchmark numbers, or ablation data. This is load-bearing for the central claim of demonstrating controllable steering, as the empirical support is not visible.
- [Linear weighting heuristic description] The linear weighting heuristic with grid search is described as balancing personality and performance without stating whether the search is performed on held-out data or risks fitting to the evaluation itself. This raises a potential circularity issue for the performance preservation claim.
- [Identification of latent directions] The SAE and contrastive activation analysis identify directions that differ across trait-conditioned activations, but this does not establish that additive interventions on these directions will causally control the OCEAN traits rather than merely correlating with them. This is the weakest assumption underlying the steering method.
minor comments (1)
- [Notation] The formalization of the additive steering vector could benefit from explicit equations to clarify the intervention process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, proposing revisions where they strengthen the manuscript without misrepresenting our results.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the method 'shows promise' and 'demonstrates' effects but supplies no quantitative results, error bars, benchmark numbers, or ablation data. This is load-bearing for the central claim of demonstrating controllable steering, as the empirical support is not visible.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revision we will incorporate specific benchmark numbers, personality expression metrics, and error bars drawn from the experimental sections to make the central claims concrete. revision: yes
-
Referee: [Linear weighting heuristic description] The linear weighting heuristic with grid search is described as balancing personality and performance without stating whether the search is performed on held-out data or risks fitting to the evaluation itself. This raises a potential circularity issue for the performance preservation claim.
Authors: This concern is valid given the current description. The grid search was performed on a held-out validation split separate from the reported test benchmarks. We will revise the methods section to explicitly document this procedure and confirm that evaluation metrics reflect performance on unseen data. revision: yes
-
Referee: [Identification of latent directions] The SAE and contrastive activation analysis identify directions that differ across trait-conditioned activations, but this does not establish that additive interventions on these directions will causally control the OCEAN traits rather than merely correlating with them. This is the weakest assumption underlying the steering method.
Authors: The identification step is correlational, but the paper's central evidence for causal control comes from the subsequent intervention experiments, which apply the vectors and measure resulting changes in generated text personality scores. We will add a short discussion paragraph clarifying this distinction and the evidential role of the steering results. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and description outline identifying directions via SAEs plus contrastive activation analysis, formalizing additive steering vectors, applying shifts, and using grid search for linear weights to balance traits and performance. No equations or steps are shown that reduce by construction to their own inputs, no self-citations are load-bearing on uniqueness or ansatzes, and no fitted parameters are relabeled as independent predictions. The optimization step is presented as a heuristic without evidence it collapses the central claim to the identification data itself. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders recover disentangled, causally relevant features from LLM residual stream activations.
Reference graph
Works this paper leans on
-
[1]
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., and Nanda, N
doi: 10.3389/fncom.2021.654315. Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., and Nanda, N. Refusal in language models is mediated by a single direction,
-
[2]
URL https://arxiv.org/abs/2406.11717. Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y ., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., and Olah, C. Towar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L
https: //transformer-circuits.pub/2023/ monosemantic-features/index.html. Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models,
2023
-
[4]
URL https:// arxiv.org/abs/2309.08600. Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCandlish, S., Kaplan, J., Amodei, D., Wattenberg, M., and Olah, C. Toy models of superposition.Transformer Circuits Thread,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Fatemi, S., Hu, Y ., and Mousavi, M
https://transformer-circuits.pub/ 2022/toy_model/index.html. Fatemi, S., Hu, Y ., and Mousavi, M. A comparative analysis of instruction fine-tuning llms for financial text classifica- tion,
2022
-
[6]
Scaling and evaluating sparse autoencoders
URL https: //arxiv.org/abs/2406.04093. Hagendorff, T., Dasgupta, I., Binz, M., Chan, S. C. Y ., Lampinen, A., Wang, J. X., Akata, Z., and Schulz, E. Machine psychology,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https://arxiv. org/abs/2303.13988. Hilliard, A., Munoz, C., Wu, Z., and Koshiyama, A. S. Eliciting personality traits in large language models,
-
[8]
Jiang, H., Zhang, X., Cao, X., Breazeal, C., Roy, D., and Kabbara, J
URLhttps://arxiv.org/abs/2402.08341. Jiang, H., Zhang, X., Cao, X., Breazeal, C., Roy, D., and Kabbara, J. Personallm: Investigating the ability of large 13 Mechanistic Personality Analysis of LLMs language models to express personality traits,
-
[9]
Kerz, E., Qiao, Y ., Zanwar, S., and Wiechmann, D
URL https://arxiv.org/abs/2305.02547. Kerz, E., Qiao, Y ., Zanwar, S., and Wiechmann, D. Push- ing on personality detection from verbal behavior: A transformer meets text contours of psycholinguistic fea- tures. In Barnes, J., De Clercq, O., Barriere, V ., Tafreshi, S., Alqahtani, S., Sedoc, J., Klinger, R., and Balahur, A. (eds.),Proceedings of the 12th ...
-
[10]
doi: 10.18653/v1/2022.wassa-1.17
Association for Computational Linguis- tics. doi: 10.18653/v1/2022.wassa-1.17. URL https: //aclanthology.org/2022.wassa-1.17/. Lee, S., Lim, S., Han, S., Oh, G., Chae, H., Chung, J., Kim, M., woo Kwak, B., Lee, Y ., Lee, D., Yeo, J., and Yu, Y . Do llms have distinct and consistent personality? trait: Personality testset designed for llms with psychomet- rics,
- [11]
-
[12]
doi: 10.1093/pnasnexus/pgae231. Reynolds, L. and McDonell, K. Prompt program- ming for large language models: Beyond the few-shot paradigm,
-
[13]
URL https://arxiv.org/abs/ 2102.07350. Serapio-Garc´ıa, G., Safdari, M., Crepy, C., Sun, L., Fitz, S., Romero, P., Abdulhai, M., Faust, A., and Matari´c, M. Personality traits in large language models,
-
[14]
Personality traits in large language models,
URL https://arxiv.org/abs/2307.00184. Sorokovikova, A., Fedorova, N., Rezagholi, S., and Yamshchikov, I. P. Llms simulate big five personality traits: Further evidence,
-
[15]
URL https://arxiv. org/abs/2402.01765. Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., and Henighan, T. Scaling monosemanticity: Ex- ...
-
[16]
Wang, S., Li, R., Chen, X., Yuan, Y ., Wong, D
URL https: //transformer-circuits.pub/2024/ scaling-monosemanticity/index.html. Wang, S., Li, R., Chen, X., Yuan, Y ., Wong, D. F., and Yang, M. Exploring the impact of personality traits on llm bias and toxicity,
2024
-
[17]
Exploring the impact of personality traits on llm bias and toxicity,
URL https://arxiv. org/abs/2502.12566. Wei, J., Tay, Y ., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E. H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W. Emergent abili- ties of large language models,
-
[18]
Emergent Abilities of Large Language Models
URL https: //arxiv.org/abs/2206.07682. Widiger, T. A. and Crego, C. The five factor model of personality structure: an update.World Psychiatry, 18 (3):271–272,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: https://doi.org/10.1002/wps. 20658. URL https://onlinelibrary.wiley. com/doi/abs/10.1002/wps.20658. 14 Mechanistic Personality Analysis of LLMs A. Additional Results 15 Mechanistic Personality Analysis of LLMs Table 4.Full Comparison of Tuned-Up vs. Tuned-Down Responses for All Five Traits. Trait Tuned Up Response Excerpt Tuned Down Response Excerpt ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.