Categorizing Mathematical Concepts with LLM Voting Ensembles in Mathswitch
Pith reviewed 2026-06-30 08:53 UTC · model grok-4.3
The pith
A voting ensemble of LLM judges can filter noise from Wikidata mathematical concepts by treating MathWorld-linked items as a positive control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
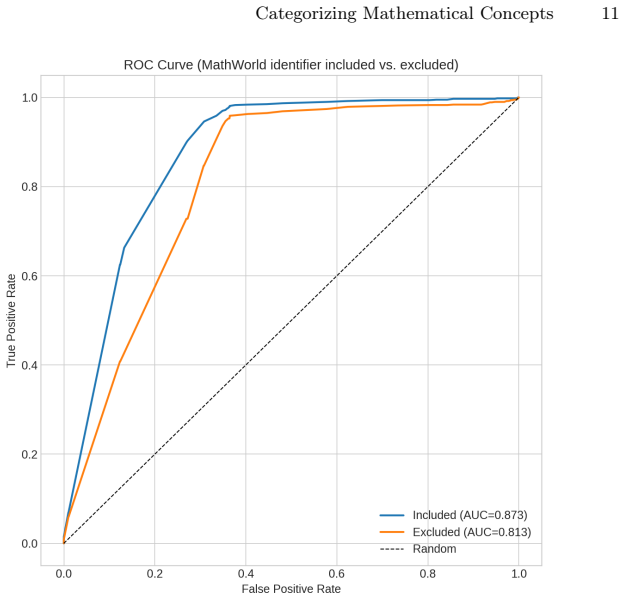
The authors show that an ensemble of LLM judges, deciding by majority vote, can classify Wikidata items as mathematical or not with measurable agreement to a positive control set of items carrying MathWorld identifiers. Performance is compared when database identifiers are present or absent from the prompt context, and the cases of mismatch are partitioned into degenerate descriptions, narrow scope bias, and editorial-scope mismatches that each point to distinct remediation steps.
What carries the argument
The LLM voting ensemble that assigns each Wikidata item to a mathematical or non-mathematical category by majority vote among several model judges.
If this is right
- The ensemble can be run on the full set of Wikidata-imported items to remove noise before further linking.
- Stripping database identifiers from the input changes how often the ensemble agrees with MathWorld labels.
- Disagreements fall into three repeatable categories that each map to a concrete improvement action on data or prompts.
- The same voting procedure can be reused when additional sources are imported into Mathswitch.
Where Pith is reading between the lines
- The labeled disagreements could serve as training data to fine-tune a smaller classifier for the same task.
- The method might be applied to other noisy sources such as Wikipedia or nLab to improve cross-resource linking.
- Extending the ensemble to also suggest concept merges could reduce manual work in the Mathswitch linking step.
Load-bearing premise
Wikidata items carrying known MathWorld identifiers form a reliable positive control set that accurately represents true mathematical concepts.
What would settle it
If a substantial fraction of items already linked to MathWorld are labeled non-mathematical by the ensemble, the filtering claim would not hold.
Figures

read the original abstract
Mathswitch is an open-source project that imports mathematical concept records from sources such as Wikidata, Wikipedia, MathWorld, Encyclopedia of Mathematics, nLab, ProofWiki, and Agda-Unimath, and links records that refer to the same concept. It does not reorganize or redefine the imported content; each source retains its own structure. The current focus is on importing concept data from Wikidata and the resources it links to, with plans to expand to further sources and better concept linking. Because the concept set is approximated through queries over Wikidata's collaboratively edited graph, the imported data is noisy: some items are non-mathematical, while others are ambiguous. In this paper, we test whether a voting ensemble of LLM judges can filter this noise. We evaluate it on Wikidata items with known MathWorld identifiers as a positive control, and examine how classification changes when database identifiers are removed from context. We then inspect the cases where the judges disagree with MathWorld and group these disagreements into three categories (degenerate descriptions, narrow scope bias, and editorial-scope mismatches) that suggest different remediation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Mathswitch open-source project for importing and linking mathematical concept records from Wikidata, Wikipedia, MathWorld and other sources without reorganizing content. It identifies noise in Wikidata-derived data (non-mathematical or ambiguous items) and tests whether a voting ensemble of LLM judges can filter this noise. Evaluation is performed on a positive control set of Wikidata items with known MathWorld identifiers, with analysis of how classifications change when database identifiers are removed from context, followed by qualitative grouping of disagreements into three categories (degenerate descriptions, narrow scope bias, editorial-scope mismatches) that suggest remediation strategies.
Significance. If the central claim holds, the LLM voting ensemble would supply a scalable, practical method for cleaning noisy collaborative data sources used in mathematical concept aggregation projects. The explicit categorization of disagreement cases into remediation-oriented groups is a constructive contribution. The open-source release of Mathswitch and its emphasis on preserving source structures while improving linking are strengths that support reproducibility and community use.
major comments (2)
- [Evaluation] Evaluation (as described in the abstract): The evaluation is conducted solely on a positive control set of Wikidata items already known to be mathematical via MathWorld links. No negative control set of known non-mathematical Wikidata items (e.g., items with non-math instance-of values) or direct quantitative test on the actual noisy items is described. Without measuring precision or rejection rate on negatives, performance on positives alone does not establish selective noise filtering.
- [Abstract] Abstract and evaluation description: No quantitative results (recall, agreement rates, classification change statistics, or error rates), error analysis, or prompt details are reported despite outlining an evaluation design with positive control and disagreement analysis. This leaves the claim that the voting ensemble filters noise without demonstrated empirical support.
minor comments (1)
- The manuscript would benefit from including the exact LLM prompts and voting procedure in an appendix or supplementary material to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below, acknowledging limitations in the current evaluation design while clarifying the intended scope of the work.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (as described in the abstract): The evaluation is conducted solely on a positive control set of Wikidata items already known to be mathematical via MathWorld links. No negative control set of known non-mathematical Wikidata items (e.g., items with non-math instance-of values) or direct quantitative test on the actual noisy items is described. Without measuring precision or rejection rate on negatives, performance on positives alone does not establish selective noise filtering.
Authors: We agree that the evaluation relies exclusively on a positive control and provides no negative controls or direct quantitative measures of precision or rejection rates on non-mathematical items. This means the study does not establish the ensemble as a selective noise filter in a quantitative sense. The work instead uses the positive control to surface and categorize disagreement patterns (degenerate descriptions, narrow scope bias, editorial-scope mismatches) that can guide remediation in Mathswitch. We will revise the abstract, introduction, and discussion to explicitly limit claims to disagreement analysis and remediation insights rather than validated filtering performance. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No quantitative results (recall, agreement rates, classification change statistics, or error rates), error analysis, or prompt details are reported despite outlining an evaluation design with positive control and disagreement analysis. This leaves the claim that the voting ensemble filters noise without demonstrated empirical support.
Authors: The referee is correct that the manuscript describes the evaluation design but does not report quantitative metrics such as agreement rates or classification change statistics, nor does it include prompt details or formal error analysis. We will add these elements in revision: summary statistics on how classifications shift when identifiers are removed, counts and examples within each disagreement category, and representative prompts, to provide the missing empirical grounding. revision: yes
Circularity Check
No significant circularity; evaluation uses external MathWorld control set
full rationale
The paper's core procedure applies an LLM voting ensemble to classify Wikidata items as mathematical concepts and evaluates recall plus disagreement categories against an independent external control (Wikidata items already linked to MathWorld). No parameters are fitted to the target labels and then re-used as predictions, no self-definitional loops appear in the classification rule, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The derivation chain therefore remains self-contained against the stated external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judges can reliably determine whether a concept record is mathematical and unambiguous
Reference graph
Works this paper leans on
-
[1]
Formal abstracts,https://formalabstracts.github.io/
-
[2]
Elizarov, A., Kirillovich, A., Lipachev, E., Nevzorova, O.: OntoMathPRO: An On- tology of Mathematical Knowledge. Doklady Mathematics106(3), 429–435 (Dec 2022).https://doi.org/10.1134/S1064562422700016 Categorizing Mathematical Concepts 15
-
[3]
Jour- nal of Symbolic Computation90, 89–123 (Jan 2019).https://doi.org/10.1016/ j.jsc.2018.04.005
Gauthier, T., Kaliszyk, C.: Aligning concepts across proof assistant libraries. Jour- nal of Symbolic Computation90, 89–123 (Jan 2019).https://doi.org/10.1016/ j.jsc.2018.04.005
2019
-
[4]
Hosseini Beghaeiraveri, S.A., Labra Gayo, J.E., Waagmeester, A., Ammar, A., Gonzalez, C., Slenter, D., Ul-Hasan, S., Willighagen, E., McNeill, F., Gray, A.: Wikidata subsetting: Approaches, tools, and evaluation. Semantic Web pp. 1–27 (Dec 2023).https://doi.org/10.3233/SW-233491
-
[5]
In: Watt, S., Davenport, J., Sexton, A., Sojka, P., Urban, J
Iancu, M., Jucovschi, C., Kohlhase, M., Wiesing, T.: System Description: Math- Hub.info. In: Watt, S., Davenport, J., Sexton, A., Sojka, P., Urban, J. (eds.) In- telligent Computer Mathematics, vol. 8543, pp. 431–434. Springer International Publishing, Cham (2014).https://doi.org/10.1007/978-3-319-08434-3_33
-
[6]
In: Annual Meeting of the Associa- tion for Computational Linguistics (2023),https://api.semanticscholar.org/ CorpusID:259075564
Jiang, D., Ren, X., Lin, B.Y.: Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. In: Annual Meeting of the Associa- tion for Computational Linguistics (2023),https://api.semanticscholar.org/ CorpusID:259075564
2023
-
[7]
Kohlhase, M.: OMDoc – An Open Markup Format for Mathematical Documents [Version 1.2], Lecture Notes in Computer Science, vol. 4180. Springer Berlin Hei- delberg, Berlin, Heidelberg (2006).https://doi.org/10.1007/11826095
-
[8]
Li, J., Zhang, Q., Yu, Y., Fu, Q., Ye, D.: More agents is all you need. Trans. Mach. Learn. Res.2024(2024),https://api.semanticscholar.org/CorpusID: 267547997
2024
-
[9]
In: Geuvers, H., England, M., Hasan, O., Rabe, F., Teschke, O
Müller, D., Gauthier, T., Kaliszyk, C., Kohlhase, M., Rabe, F.: Classification of Alignments Between Concepts of Formal Mathematical Systems. In: Geuvers, H., England, M., Hasan, O., Rabe, F., Teschke, O. (eds.) Intelligent Computer Math- ematics, vol. 10383, pp. 83–98. Springer International Publishing, Cham (2017). https://doi.org/10.1007/978-3-319-62075-6_7
-
[10]
In: Proceedings of the 18th BioNLP Workshop and Shared Task
Neumann, M., King, D., Beltagy, I., Ammar, W.: ScispaCy: Fast and Robust Models for Biomedical Natural Language Processing. In: Proceedings of the 18th BioNLP Workshop and Shared Task. pp. 319–327. Association for Computational Linguistics,Florence,Italy(Aug2019).https://doi.org/10.18653/v1/W19-5034, https://www.aclweb.org/anthology/W19-5034
-
[11]
In: 2022 IEEE International Conference on Big Data (Big Data)
Nguyen, P., Takeda, H.: Wikidata-lite for Knowledge Extraction and Exploration. In: 2022 IEEE International Conference on Big Data (Big Data). pp. 3684–3686. IEEE, Osaka, Japan (Dec 2022).https://doi.org/10.1109/BigData55660.2022. 10020716
-
[12]
In: Proceedings of the 15th International Symposium on Open Collaboration
Piscopo, A., Simperl, E.: What we talk about when we talk about wikidata quality: A literature survey. In: Proceedings of the 15th International Symposium on Open Collaboration. pp. 1–11. ACM, Skövde Sweden (Aug 2019).https://doi.org/10. 1145/3306446.3340822
-
[13]
Information and Computation 230, 1–54 (Sep 2013).https://doi.org/10.1016/j.ic.2013.06.001
Rabe, F., Kohlhase, M.: A scalable module system. Information and Computation 230, 1–54 (Sep 2013).https://doi.org/10.1016/j.ic.2013.06.001
-
[14]
Gen- ovese, 2023-10-26
Rijke, E., Agda Unimath contributors: Concept indexing infrastructure for the agda-unimath library (2023),https://github.com/UniMath/agda-unimath/ pull/884#issuecomment-1783354443, pull request #884, comment by F. Gen- ovese, 2023-10-26
2023
-
[15]
In: Proceedings of the International ACM SIGIR ConferenceonResearchandDevelopmentinInformationRetrieval(SIGIR)(2018), https://ceur-ws.org/Vol-2132/paper5.pdf 16 K
Scharpf, P., Schubotz, M., Gipp, B.: Representing mathematical formulae in con- tent mathml using wikidata. In: Proceedings of the International ACM SIGIR ConferenceonResearchandDevelopmentinInformationRetrieval(SIGIR)(2018), https://ceur-ws.org/Vol-2132/paper5.pdf 16 K. Berčič and S. Stanojevikj
2018
-
[16]
In: Companion Proceedings of the Web Conference 2021
Scharpf, P., Schubotz, M., Gipp, B.: Fast Linking of Mathematical Wikidata En- tities in Wikipedia Articles Using Annotation Recommendation. In: Companion Proceedings of the Web Conference 2021. pp. 602–609. ACM, Ljubljana Slovenia (Apr 2021).https://doi.org/10.1145/3442442.3452348
-
[17]
In: Proceedings of the Wikidata Workshop (Wikidata’23) at ISWC 2023 (2023)
Schubotz, M., Ferrer, E., Stegmüller, J., Mietchen, D., Teschke, O., Pusch, L., Conrad, T.: Bravo MaRDI: A Wikibase knowledge graph on mathematics. In: Proceedings of the Wikidata Workshop (Wikidata’23) at ISWC 2023 (2023). https://doi.org/10.48550/arXiv.2309.11484
-
[18]
SSRN Electronic Journal (2021).https://doi.org/10.2139/ssrn
Shenoy, K., Ilievski, F., Garijo, D., Schwabe, D., Szekely, P.: A Study of the Quality of Wikidata. SSRN Electronic Journal (2021).https://doi.org/10.2139/ssrn. 3967025
-
[19]
In: The Eleventh International Conference on Learning Repre- sentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdh- ery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in lan- guage models. In: The Eleventh International Conference on Learning Repre- sentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net (2023), https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[20]
Wikidata contributors: Wikidata:WikiProject Mathematics.https: //www.wikidata.org/wiki/Wikidata:WikiProject_Mathematics, accessed 2026-04-14
2026
-
[21]
Wikidata contributors: Wikidata:WikiProject Schemas/Subsetting.https:// www.wikidata.org/wiki/Wikidata:WikiProject_Schemas/Subsetting, accessed 2026-04-14
2026
-
[22]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J., Stoica, I.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023) Categor...
2023
-
[23]
confidence: a number from 0 to 100 (representing your confidence percentage)
-
[24]
Wiener sausage
reasoning: a brief explanation of why you chose that answer IMPORTANT: Format your response as three lines, exactly like this: answer: yes confidence: 85 reasoning: The concept is clearly mathematical because... --- CONCEPT INFORMATION: Name: Wiener sausage Description: Mathematical concept --- PREDICATE TO EVALUATE: Is the given concept a mathematical co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.