wav2VOT: Automatic estimation of voice onset time, closure duration, and burst realisation with wav2vec2
Pith reviewed 2026-06-30 08:53 UTC · model grok-4.3
The pith
wav2VOT applies wav2vec2 to estimate voice onset time, closure duration, and burst realisation at accuracy levels matching current tools on new data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
wav2VOT demonstrates that wav2vec2 can be used to automatically estimate voice onset time, closure duration, and burst realisation, performing comparably to current approaches on unseen datasets and achieving high accuracy with fine-tuning, with high fidelity across stop voicing and place of articulation.
What carries the argument
wav2vec2 representations, used directly or after fine-tuning, to predict the acoustic timing and burst events that define stop consonants.
If this is right
- Phonetic annotation pipelines can incorporate wav2VOT to label large corpora with less manual review.
- Fine-tuning on a small amount of target data improves timing estimates for specific research datasets.
- Performance remains consistent across voicing categories and places of articulation without extra adjustments.
- Large speech models can replace or supplement rule-based or smaller trained systems for stop-consonant measurements.
Where Pith is reading between the lines
- The same model backbone could be adapted to measure other timing events such as vowel formant transitions.
- Large-scale phonetic studies that were previously limited by annotation cost become feasible.
- Domain mismatch between training and test recordings remains the main practical limit on out-of-the-box use.
Load-bearing premise
wav2vec2 representations already encode the timing and burst details of stop consonants well enough to transfer across different datasets and speakers.
What would settle it
A new test set from a clearly different domain, such as a different language or recording condition, where wav2VOT accuracy drops well below that of existing tools.
Figures


read the original abstract
While automatic tools for speech annotation are now commonplace within phonetic research pipelines, many tasks require substantial manual correction or training sets to perform accurately. Simultaneously, large speech models such as wav2vec2 have been shown to perform well at speech classification tasks, raising the question of how these models may be applied to phonetic annotation tasks. We introduce wav2VOT: a tool for the automatic estimation of voice onset time, closure duration, and burst realisation using wav2vec2. We demonstrate that wav2VOT performs comparably with current approaches on unseen datasets, and can estimate with high accuracy with fine-tuning. Analysis of wav2VOT predictions demonstrate high fidelity across stop voicing and place of articulation. These results demonstrate that large speech models are capable of producing accurate annotations, and further motivate exploration of large speech models as tools in phonetic research pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces wav2VOT, a tool based on wav2vec2 for automatic estimation of voice onset time (VOT), closure duration, and burst realisation for stop consonants. The central claim is that wav2VOT performs comparably to existing approaches on unseen datasets, achieves high accuracy after fine-tuning, and produces predictions with high fidelity across stop voicing and place of articulation.
Significance. If the quantitative results and generalization claims hold, the work would be significant for phonetic research pipelines by demonstrating that large pre-trained speech models can handle fine-grained timing and realisation tasks with reduced need for manual correction or large training sets. The explicit testing on unseen datasets and analysis across phonetic categories provide a concrete basis for further exploration of such models in annotation tasks.
minor comments (1)
- The abstract would be strengthened by including at least one key quantitative result (e.g., correlation or error metric) to support the performance claims, even though the full manuscript presumably contains these details in the results section.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending acceptance. We are pleased that the significance of applying wav2vec2 to fine-grained phonetic timing and realisation tasks was recognised, particularly the evaluation on unseen data and across phonetic categories.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical ML application of pretrained wav2vec2 models (with optional fine-tuning) to estimate VOT, closure duration, and burst features, evaluated on unseen datasets. No derivation chain, equations, or first-principles results are present. Performance claims rest on direct comparison to existing tools and human annotations rather than any self-referential fitting or imported uniqueness theorem. The central results are externally falsifiable via replication on held-out speech data and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Many analyses now utilise a pipeline of (semi-)automatic utterance- and word-level tran- scription and automatic time-alignment of phonemic labels to the speech signal (e.g
Introduction Automatic approaches to the segmentation and annotation of speech data has become increasingly popular within phonetic and speech science research. Many analyses now utilise a pipeline of (semi-)automatic utterance- and word-level tran- scription and automatic time-alignment of phonemic labels to the speech signal (e.g. [1, 2, 3]), with furth...
-
[2]
Model The architecture of wav2vec2 consists of a Feature Encoder (FE) block and Transformer Encoder (TE) block. Feature en- coding in wav2vec2 is performed via a set of 1-dimensional 1Source code and models available at https://github.com/james-tanner/wav2VOT. arXiv:2606.28857v1 [cs.SD] 27 Jun 2026 0.000 0.015 0.030 0.045 0.060 0.075 0.090 0.105 0.120 Tim...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
3.1), and 2) across a variety of unseen datasets, along with changes in performance when fine-tuned on varying amounts of data (Sec
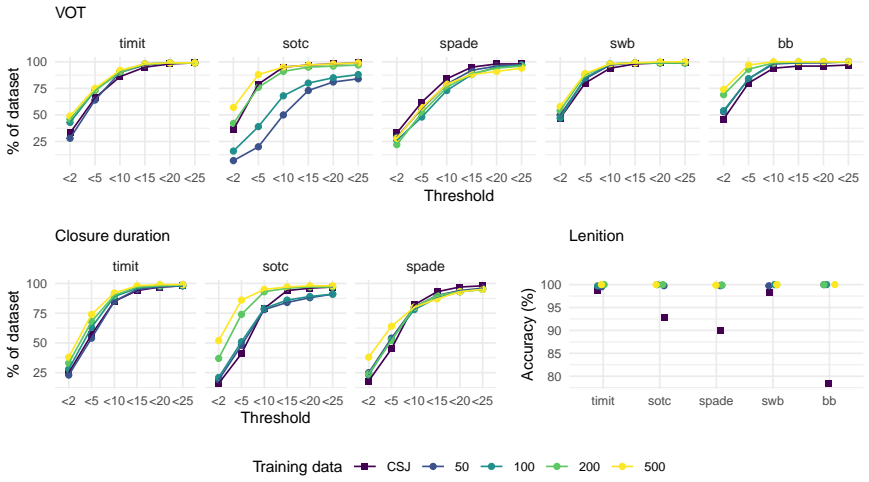
Experiment 1 The goals of Experiment 1 are to demonstrate that wav2VOT is capable of learning and capturing the fine-grained tempo- ral properties of stops in 1) a large set of training data with a matched test set (Sec. 3.1), and 2) across a variety of unseen datasets, along with changes in performance when fine-tuned on varying amounts of data (Sec. 3.2...
1903
-
[4]
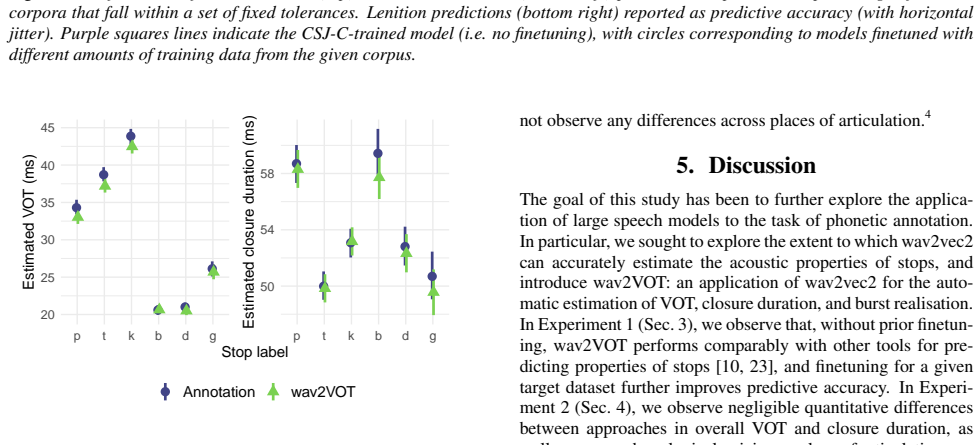
Experiment 2 Following previous work evaluating the performance of auto- matic VOT annotations [10, 12], we also evaluate the predictive performance of wav2VOT by comparing predictions directly with manual annotations in a hypothetical phonetic study con- text. Specifically, we take a regression modelling approach to estimate the degree of similarity betw...
-
[5]
Discussion The goal of this study has been to further explore the applica- tion of large speech models to the task of phonetic annotation. In particular, we sought to explore the extent to which wav2vec2 can accurately estimate the acoustic properties of stops, and introduce wav2VOT: an application of wav2vec2 for the auto- matic estimation of VOT, closur...
-
[6]
Computational resources were provided by the Digital Research Alliance of Canada
Acknowledgements The authors thank the SPADE Data Guardians, Rachel Macdon- ald, Michael McAuliffe, and Vanna Willerton. Computational resources were provided by the Digital Research Alliance of Canada. This research was supported by a T-AP Digging into Data award in the form of the following grants: ESRC Grant #ES/R003963/1, NSERC/CRSNG Grants #RGPDD-501...
2023
-
[7]
Generative AI Use Disclosure The authors declare that no Generative AI tools were used in the research, design, analysis, writing, or editing of this work
-
[8]
Articulation rate in American English in a corpus of YouTube videos,
S. Coats, “Articulation rate in American English in a corpus of YouTube videos,”Language and Speech, vol. 63, pp. 799–831, 2020
2020
-
[9]
Towards “English
J. Tanner, M. Sonderegger, J. Stuart-Smith, and J. Fruehwald, “Towards “English” phonetics: variability in the pre-consonantal voicing effect across English dialects and speakers,”Frontiers in Artificial Intelligence, vol. 3, 2020
2020
-
[10]
Sys- tematic co-variation of monophthongs across speakers of New Zealand English,
J. Brand, J. Hay, L. Clark, K. Watson, and M. S ´oskuthy, “Sys- tematic co-variation of monophthongs across speakers of New Zealand English,”Journal of Phonetics, vol. 88, 2021
2021
-
[11]
V oice Onset Time (VOT) at 50: Theoretical and practical issues in measuring voicing distinc- tions,
A. S. Abramson and D. H. Whalen, “V oice Onset Time (VOT) at 50: Theoretical and practical issues in measuring voicing distinc- tions,”Journal of Phonetics, vol. 63, pp. 75–86, 2017
2017
-
[12]
A cross-language study of voicing in initial stops: Acoustical measurements,
L. Lisker and A. S. Abramson, “A cross-language study of voicing in initial stops: Acoustical measurements,”Word, vol. 20, no. 3, pp. 384–422, 1964
1964
-
[13]
Rapid versus rabid: A catalogue of acoustic features that may cue the distinction,
L. Lisker, “Rapid versus rabid: A catalogue of acoustic features that may cue the distinction,”Journal of the Acoustical Society of America, vol. 62, pp. S77–S78, 1977
1977
-
[14]
Relation between voice-onset time and vowel duration,
R. F. Port and R. Rotunno, “Relation between voice-onset time and vowel duration,”Journal of the Acoustical Society of America, vol. 66, pp. 654–662, 1979
1979
-
[15]
Variation and universals in VOT: evi- dence from 18 languages,
T. Cho and P. Ladefoged, “Variation and universals in VOT: evi- dence from 18 languages,”Journal of Phonetics, vol. 27, pp. 207– 229, 1999
1999
-
[16]
Laryngeal phonetics, phonology, assimilation and final neutralization,
J. Salmons, “Laryngeal phonetics, phonology, assimilation and final neutralization,” inCambridge Handbook of Germanic Lin- guistics, R. Page and M. T. Putnam, Eds. Cambridge: Cambridge University Press, 2019, pp. 119–142
2019
-
[17]
Automatic measurement of voice onset time using discriminative structured predictions,
M. Sonderegger and J. Keshet, “Automatic measurement of voice onset time using discriminative structured predictions,”Journal of the Acoustical Society of America, vol. 132, pp. 3965–3979, 2012
2012
-
[18]
Structure in talker-specific phonetic realization: Covariation of stop consonant VOT in American En- glish,
E. Chodroff and C. Wilson, “Structure in talker-specific phonetic realization: Covariation of stop consonant VOT in American En- glish,”Journal of Phonetics, vol. 61, pp. 30–47, 2017
2017
-
[19]
Assessing auto- matic VOT annotation using unimpaired and impaired speech,
E. Buz, A. Buchwald, T. Fuchs, and J. Keshet, “Assessing auto- matic VOT annotation using unimpaired and impaired speech,” International Journal of Speech-Language Pathology, vol. 20, pp. 624–634, 2018
2018
-
[20]
Structured heterogeneity in Scottish stops over the twentieth century,
M. Sonderegger, J. Stuart-Smith, T. Knowles, R. MacDonald, and T. Rathcke, “Structured heterogeneity in Scottish stops over the twentieth century,”Language, vol. 96, pp. 94–125, 2020
2020
-
[21]
Automatic estimation of voice onset time for word-initial stops by applying random forest to onset detec- tion,
H.-C. W. Chi-Yueh Lin, “Automatic estimation of voice onset time for word-initial stops by applying random forest to onset detec- tion,”Journal of thr Acoustical Society of America, vol. 130, p. 514–525, 2011
2011
-
[22]
Estimation of voice-onset time in continuous speech using temporal measures,
A. P. Prathosh, A. G. Ramakrishnan, and T. V . Ananthapadman- abha, “Estimation of voice-onset time in continuous speech using temporal measures,”Journal of the Acoustical Society of America, vol. 136, p. EL122–EL128, 2014
2014
-
[23]
Sequence segmentation using joint rnn and structured prediction models,
Y . Adi, J. Keshet, E. Cibelli, and M. A. Goldrick, “Sequence segmentation using joint rnn and structured prediction models,” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2422–2426, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:885991
2017
-
[24]
Dr. vot: Measuring posi- tive and negative voice onset time in the wild,
Y . Shrem, M. Goldrick, and J. Keshet, “Dr. vot: Measuring posi- tive and negative voice onset time in the wild,”Proc. Interspeech 2019, pp. 629–633, 2019
2019
-
[25]
Puggaard-Rode, “getVOT,” 2024, version 0.2.0
R. Puggaard-Rode, “getVOT,” 2024, version 0.2.0. [Online]. Available: https://github.com/rpuggaardrode/getVOT
2024
-
[26]
Segmental and prosodic effects on intervocalic voiced stop reduction in connected speech,
D. Bouavichith and L. Davidson, “Segmental and prosodic effects on intervocalic voiced stop reduction in connected speech,”Pho- netica, vol. 70, pp. 182–206, 2013
2013
-
[27]
The causal structure of lenition: a case for the causal precedence of durational shortening,
U. Cohen Priva and E. Gleason, “The causal structure of lenition: a case for the causal precedence of durational shortening,”Lan- guage, vol. 96, pp. 413–448, 2020
2020
-
[28]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,” CoRR, vol. abs/1904.05862, 2019. [Online]. Available: http: //arxiv.org/abs/1904.05862
-
[29]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,”CoRR, vol. abs/2006.11477, 2020. [Online]. Available: https://arxiv.org/abs/2006.11477
-
[30]
Automatic classification of stop realisation with wav2vec2.0,
J. Tanner, M. Sonderegger, J. Stuart-Smith, J. Mielke, and T. Kendall, “Automatic classification of stop realisation with wav2vec2.0,” inInterspeech 2025, 2025, pp. 2270–2274
2025
-
[31]
Using wav2vec 2.0 for phonetic classi- fication tasks: methodological aspects,
L. Kim and C. Gendrot, “Using wav2vec 2.0 for phonetic classi- fication tasks: methodological aspects,” inProceedings of Inter- speech 2024, 2024, pp. 1530–1534
2024
-
[32]
Comparing human and ma- chine’s use of coarticulatory vowel nasalization for linguistic clas- sification,
G. Zellou, L. Kim, and C. Gendrot, “Comparing human and ma- chine’s use of coarticulatory vowel nasalization for linguistic clas- sification,”Journal of the Acoustical Society of America, vol. 156, pp. 489–502, 2024
2024
-
[33]
Speech recognition in adverse con- ditions by humans and machines,
C. Patman and E. Chodroff, “Speech recognition in adverse con- ditions by humans and machines,”JASA Express Letters, vol. 4, 2024
2024
-
[34]
AI-assisted analysis of phonological variation in English,
V . Partridge, J. Pater, P. Bhangla, A. Nirheche, and B. Prickett, “AI-assisted analysis of phonological variation in English,” inSpecial session on Deep Phonology, Annual Meeting on Phonology, University of California Berkeley, 2025. [Online]. Available: https://github.com/ginic/wav2ipa
2025
-
[35]
Phone-to-audio alignment without text: A semi-supervised approach,
J. Zhu, C. Zhang, and D. Jurgens, “Phone-to-audio alignment without text: A semi-supervised approach,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 8167–8171
2022
-
[36]
Tradition or innovation: A comparison of modern ASR methods for forced alignment,
R. Rousso, E. Cohen, J. Keshet, and E. Chodroff, “Tradition or innovation: A comparison of modern ASR methods for forced alignment,” inInterspeech 2024, 2024, pp. 1525–1529
2024
-
[37]
Spontaneous speech corpus of Japanese,
K. Maekawa, H. Koiso, S. Furui, and H. Isahara, “Spontaneous speech corpus of Japanese,” inProceedings of the Second In- ternational Conference of Language Resources and Evaluation (LREC), vol. 2, 2000, pp. 946–952
2000
-
[38]
Design and development of an RDB version of the Corpus of Spontaneous Japanese,
H. Koiso, Y . Den, K. Nishikawa, and K. Maekawa, “Design and development of an RDB version of the Corpus of Spontaneous Japanese,” inProceedings of the Ninth International Conference on Language Resources and Evaluation, 2014, pp. 1471–1476
2014
-
[39]
Shimizu,A cross-language study of the voicing contrasts of stop consonants in Asian languages
K. Shimizu,A cross-language study of the voicing contrasts of stop consonants in Asian languages. Tokyo: Seibido, 1996
1996
-
[40]
The intermediate degree of VOT in Japanese initial stops,
T. J. Riney, N. Takagi, K. Ota, and Y . Uchida, “The intermediate degree of VOT in Japanese initial stops,”Journal of Phonetics, vol. 35, pp. 439–443, 2007
2007
-
[41]
DARPA TIMIT acoustic phonetic continuous speech corpus CD-ROM,
J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, “DARPA TIMIT acoustic phonetic continuous speech corpus CD-ROM,” 1993
1993
-
[42]
Changing sounds in a changing city: An acoustic phonetic investigation of real-time change over a century of Glaswegian,
J. Stuart-Smith, B. Jose, T. Rathcke, R. MacDonald, and E. Law- son, “Changing sounds in a changing city: An acoustic phonetic investigation of real-time change over a century of Glaswegian,” inLanguage and a Sense of Place: Studies in Language and Re- gion, C. Montgomery and E. Moore, Eds. Cambridge: Cam- bridge University Press, 2017, pp. 38–65
2017
-
[43]
Managing data for integrated speech corpus anal- ysis in SPeech Across Dialects of English (SPADE),
M. Sonderegger, J. Stuart-Smith, M. McAuliffe, R. Macdonald, and T. Kendall, “Managing data for integrated speech corpus anal- ysis in SPeech Across Dialects of English (SPADE),” inOpen Handbook of Linguistic Data Management. Cambridge: MIT Press, 2022
2022
-
[44]
SWITCH- BOARD: telephone speech corpus for research and development,
J. J. Godfrey, E. C. Holliman, and J. McDaniel, “SWITCH- BOARD: telephone speech corpus for research and development,” inProceedings of the 1992 IEEE international conference on Acoustics, speech and signal processing - Volume 1, 1992, pp. 517–520
1992
-
[45]
The medium-term dy- namics of accents on reality television,
M. Sonderegger, M. Bane, and P. Graff, “The medium-term dy- namics of accents on reality television,”Language, vol. 93, pp. 598–640, 2017
2017
-
[46]
Advanced Bayesian multilevel modeling with the R package brms,
P.-C. B ¨urkner, “Advanced Bayesian multilevel modeling with the R package brms,”The R Journal, vol. 10, no. 1, pp. 395–411, 2018
2018
-
[47]
R. V . Lenth,emmeans: Estimated Marginal Means, aka Least-Squares Means, 2024, r package version 1.10.0. [Online]. Available: https://CRAN.R-project.org/package=emmeans
2024
-
[48]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, p. 1505–1518, Oct. 2022. [Online]....
-
[49]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.