A Task-Driven and Quality-Assured Agent Framework for SAR Data Generation
Pith reviewed 2026-06-30 08:36 UTC · model grok-4.3
The pith
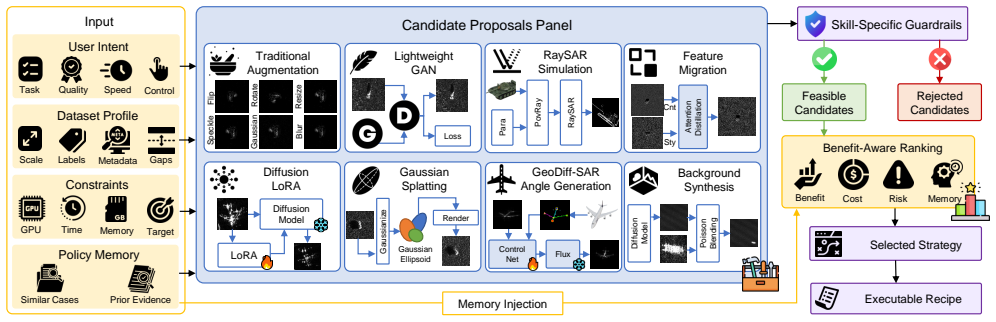
SAGA is a schema-grounded agent framework that turns natural-language requests into validated, task-specific SAR data augmentations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
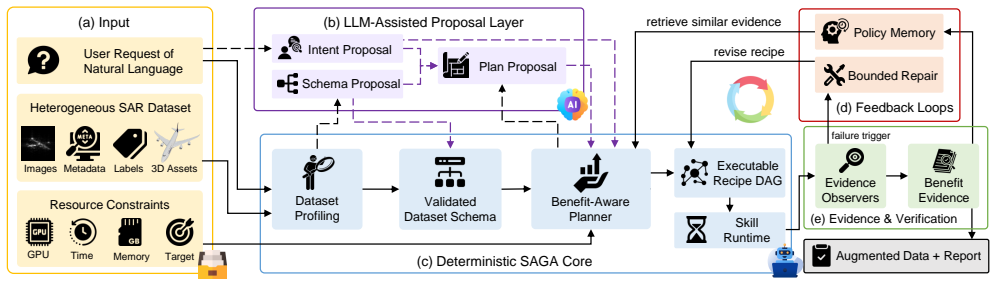
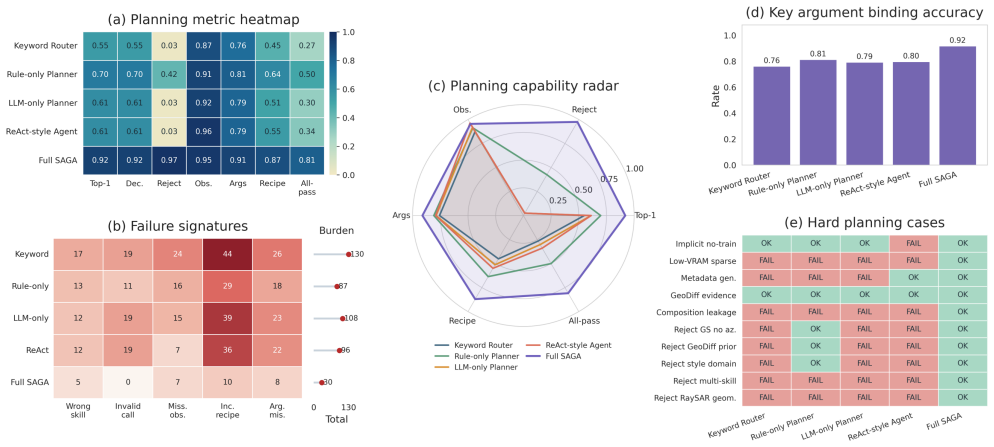
By separating semantic proposal from deterministic validation and execution, SAGA improves the reliability and reproducibility of SAR augmentation decisions, yielding better schema grounding, skill planning, invalid-sample rejection, and downstream augmentation utility than rule-based, LLM-only, ReAct-style, and fixed-augmentation baselines.
What carries the argument
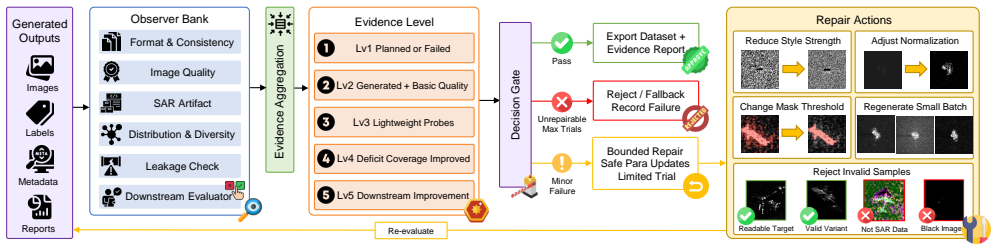
Validator-constrained planning plus a multi-evaluator pipeline (quality, distribution, SAR-artifact, duplicate, leakage, and downstream-task evaluators) that qualifies generated samples before acceptance.
If this is right
- SAR interpretation models can receive augmentations whose utility is supported by explicit evaluator evidence rather than unverified generation.
- Augmentation decisions become auditable because each step from request to workflow is logged through schema validation and planning constraints.
- Invalid or low-value samples are rejected earlier, reducing wasted computation on downstream training.
- Natural-language task descriptions can drive reproducible augmentation pipelines across heterogeneous dataset formats.
Where Pith is reading between the lines
- The same separation of proposal and validation might reduce selection bias in augmentation pipelines for other sensor modalities that face format heterogeneity.
- If the evaluator set is expanded, the framework could support iterative refinement loops where users adjust requests based on evaluator scores.
- The approach could lower the manual effort needed to curate training sets for SAR models when new tasks or sensors appear.
Load-bearing premise
The framework assumes that its validator-constrained planning and multi-evaluator pipeline can reliably identify useful augmentations without introducing selection bias that affects downstream task performance.
What would settle it
Adding SAGA-generated samples to a SAR interpretation model and measuring no gain or a drop in accuracy relative to unaugmented or baseline-augmented versions on the same task.
Figures




read the original abstract
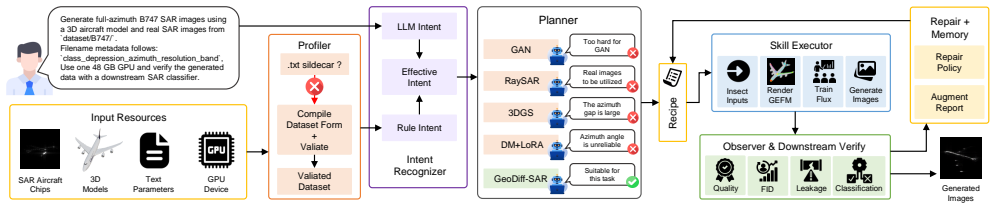
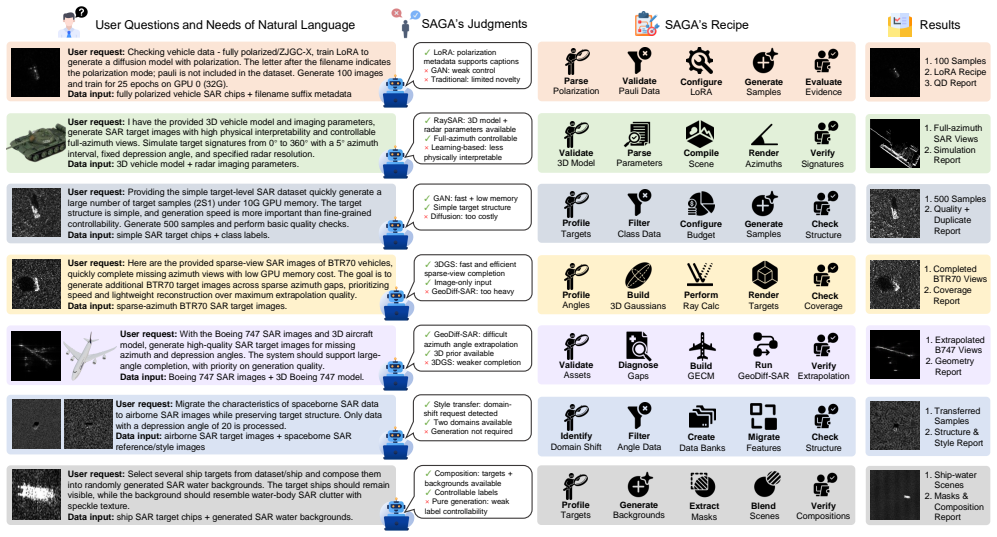
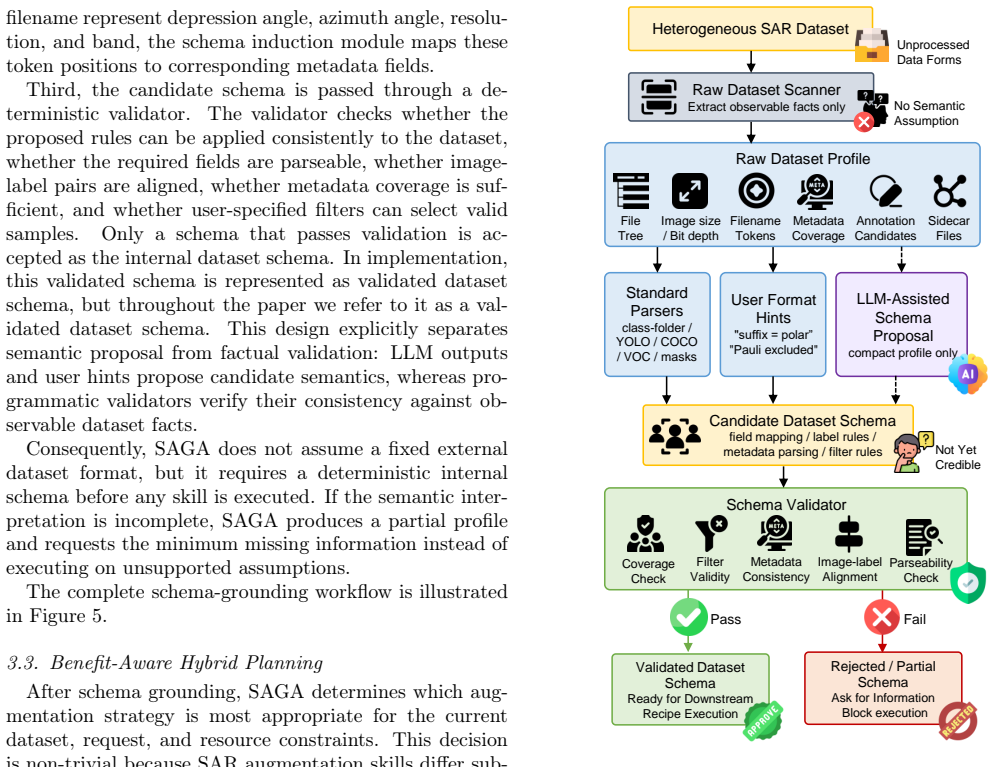
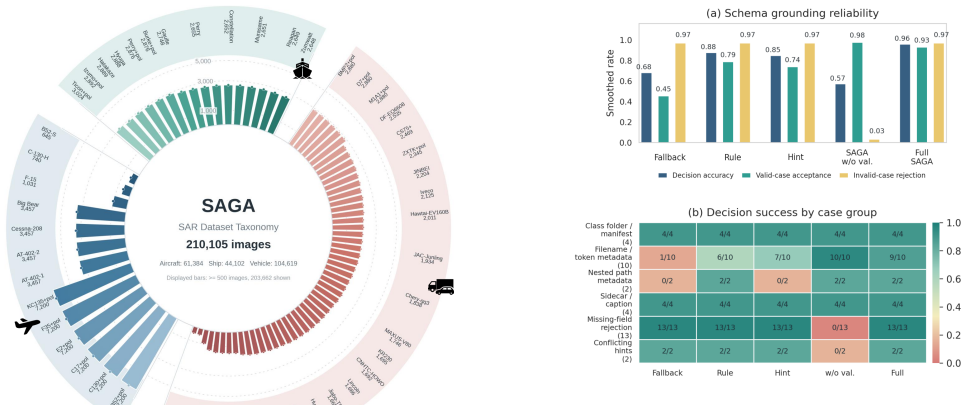
Synthetic aperture radar (SAR) data augmentation is important for improving the generalization of data-driven SAR interpretation models, yet practical augmentation workflows are often hindered by heterogeneous dataset formats, task-dependent metadata requirements, diverse generation methods, and weak validation of generated samples. This paper presents the \textbf{S}AR \textbf{A}ugmentation and \textbf{G}eneration \textbf{A}gent (SAGA), a schema-grounded and benefit-aware agent framework for task-oriented SAR data generation and augmentation. Given a natural-language request and heterogeneous SAR inputs, SAGA extracts observable dataset facts, validates executable dataset schemas, selects feasible augmentation strategies through validator-constrained planning, and compiles the selected strategy into an auditable augmentation workflow. Generated data are further assessed by quality, distribution, SAR-artifact, duplicate, leakage, and optional downstream-task evaluators to support evidence-qualified augmentation claims. By separating semantic proposal from deterministic validation and execution, SAGA improves the reliability and reproducibility of SAR augmentation decisions. Experiments on controlled agentic benchmarks and downstream SAR interpretation tasks show that SAGA improves schema grounding, skill planning, invalid-sample rejection, and downstream augmentation utility compared with rule-based, LLM-only, ReAct-style, and fixed-augmentation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SAR Augmentation and Generation Agent (SAGA), a schema-grounded and benefit-aware agent framework for task-oriented SAR data generation and augmentation. Given natural-language requests and heterogeneous SAR inputs, SAGA extracts observable dataset facts, validates executable dataset schemas, selects feasible augmentation strategies through validator-constrained planning, and compiles the selected strategy into an auditable augmentation workflow. Generated data are assessed by quality, distribution, SAR-artifact, duplicate, leakage, and optional downstream-task evaluators. The framework separates semantic proposal from deterministic validation and execution to improve reliability and reproducibility. Experiments on controlled agentic benchmarks and downstream SAR interpretation tasks are claimed to show improvements in schema grounding, skill planning, invalid-sample rejection, and downstream augmentation utility compared with rule-based, LLM-only, ReAct-style, and fixed-augmentation baselines.
Significance. If the experimental results hold with adequate quantitative support, the framework could meaningfully advance practical SAR data augmentation workflows by addressing heterogeneous formats, weak validation, and task-dependency through a hybrid agentic-deterministic design. The multi-evaluator pipeline and emphasis on auditable, evidence-qualified outputs represent a structured response to reproducibility challenges in the field. However, the absence of any metrics, datasets, or statistical details in the manuscript as provided makes it impossible to evaluate whether these benefits are realized or to compare effect sizes against baselines.
major comments (1)
- [Abstract] Abstract: The central claim that 'Experiments on controlled agentic benchmarks and downstream SAR interpretation tasks show that SAGA improves schema grounding, skill planning, invalid-sample rejection, and downstream augmentation utility' is stated without any quantitative metrics, dataset descriptions, statistical tests, error analysis, or result tables. This omission renders the primary experimental contribution unevaluable and is load-bearing for the paper's contribution.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying the critical gap in experimental reporting. We address the single major comment below and commit to a substantive revision of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experiments on controlled agentic benchmarks and downstream SAR interpretation tasks show that SAGA improves schema grounding, skill planning, invalid-sample rejection, and downstream augmentation utility' is stated without any quantitative metrics, dataset descriptions, statistical tests, error analysis, or result tables. This omission renders the primary experimental contribution unevaluable and is load-bearing for the paper's contribution.
Authors: We agree that the current abstract (and, per the referee's summary, the manuscript as provided) lacks the quantitative metrics, dataset descriptions, statistical tests, error analysis, and result tables needed to substantiate the experimental claims. This is a genuine shortcoming that prevents proper evaluation. In the revised manuscript we will (1) expand the abstract to report key quantitative results (e.g., schema-grounding accuracy, planning success rate, invalid-sample rejection rate, and downstream-task utility deltas versus baselines), (2) add explicit dataset descriptions and benchmark details, (3) include statistical significance tests and error analysis, and (4) ensure the main text contains complete result tables and evaluation protocols so that the contribution can be assessed and reproduced. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an agent framework (SAGA) for SAR data augmentation and generation, with claims resting on experimental comparisons against rule-based, LLM-only, ReAct-style, and fixed-augmentation baselines on agentic benchmarks and downstream SAR tasks. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology. The central claims are supported by external benchmark results rather than internal reductions to inputs by construction, making the derivation chain self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural-language requests can be parsed into observable dataset facts and executable schemas with high reliability.
- domain assumption The suite of quality, distribution, artifact, duplicate, leakage, and task evaluators can correctly rank augmentation utility.
invented entities (1)
-
SAGA agent framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” inAdv. Neural Inf. Pro- cess. Syst., vol. 27, 2014, pp. 2672–2680. A. Radford, L. Metz, and S. Chintala, “Unsupervised rep- resentation learning with deep convolutional generative adversarial networks,” inProc. Int. Conf...
2014
-
[2]
Denoising diffusion proba- bilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion proba- bilistic models,” inAdv. Neural Inf. Process. Syst., vol. 33, 2020, pp. 6840–6851. R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., New Orleans, LA, USA, 2022, pp. 106...
2020
-
[3]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, 2023, pp. 3836–3847. T. Balz, H. Hammer, and S. Auer, “Potentials and limi- tations of SAR image simulators–A comparative study of three simulation approaches,”ISPRS J. Photogramm. Remote Sens., vol. 1...
2023
-
[4]
S. Auer, R. Bamler, and P. Reinartz, “RaySAR–3D SAR simulator: Nowopensource,” inProc. Eur. Conf. Synth. Aperture Radar, Hamburg, Germany, 2016, pp. 1–4. H. Furukawa, “Deep learning for target classification from SAR imagery: Data augmentation and translation in- variance,”arXiv preprint arXiv:1708.07920,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
AutoAugment: Learning augmentation strate- gies from data,
E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le, “AutoAugment: Learning augmentation strate- gies from data,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Long Beach, CA, USA, 2019, pp. 113–123. E. D. Cubuk, B. Zoph, J. Shlens, and Q. V. Le, “RandAug- ment: Practical automated data augmentation with a reducedsearchspace,” inAdv. Neural...
2019
-
[6]
CutMix: Regularization strategy to train strong classi- fiers with localizable features,
S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “CutMix: Regularization strategy to train strong classi- fiers with localizable features,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Seoul, Korea, 2019, pp. 6023–6032. 15 D. Hendrycks, N. Mu, E. D. Cubuk, B. Zoph, J. Gilmer, and B. Lakshminarayanan, “AugMix: A simple data processing method to improve...
2019
-
[7]
Unpaired image-to-image translation using cycle-consistent adver- sarialnetworks,
J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adver- sarialnetworks,” inProc. IEEE Int. Conf. Comput. Vis., Venice, Italy, 2017, pp. 2223–2232. Z. Cui, M. Zhang, Z. Cao, and C. Cao, “Image data augmentation for SAR sensor via generative adversar- ial nets,”IEEE Access, vol. 7, pp. 42255–42268,
2017
-
[8]
SAR target recognition with generative adversarial network-based data augmentation,
J. Kong, X. Cao, C. Ren, Z. Li, and Q. Su, “SAR target recognition with generative adversarial network-based data augmentation,” inProc. Int. Conf. Adv. Inf. Tech- nol., 2021, pp. 51–57. S. Oghim, S. Lee, and J. Kim, “SAR image generation method using GANs with dual discriminator and high- frequency pass filter for automatic target recognition,” Remote Se...
2021
-
[9]
Generative artificial intelligence meets synthetic aperture radar: A survey,
Z. Huang, X. Zhang, Z. Tang, F. Xu, M. Datcu, and J. Han, “Generative artificial intelligence meets synthetic aperture radar: A survey,”arXiv preprint arXiv:2411.05027,
-
[10]
Automatic target recognition on synthetic aperture radar imagery: A sur- vey,
O. Kechagias-Stamatis and N. Aouf, “Automatic target recognition on synthetic aperture radar imagery: A sur- vey,”arXiv preprint arXiv:2007.02106,
-
[11]
SAR target image generation method using azimuth-controllable generative adversarial net- work,
C. Wang, J. Pei, X. Liu, Y. Huang, D. Mao, Y. Zhang, and J. Yang, “SAR target image generation method using azimuth-controllable generative adversarial net- work,”arXiv preprint arXiv:2308.05489,
-
[12]
SAR im- age synthesis with diffusion models,
D. Qosja, S. Wagner, and D. O’Hagan, “SAR im- age synthesis with diffusion models,”arXiv preprint arXiv:2405.07776,
-
[13]
Im- proving SAR automatic target recognition using simu- lated images under deep residual refinements,
M. Cha, S. Majumdar, H. T. Kung, and J. Barber, “Im- proving SAR automatic target recognition using simu- lated images under deep residual refinements,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process., Cal- gary, AB, Canada, 2018, pp. 2606–2610. S. Feng, X. Liu, Y. Zhang, and J. Wang, “Single-scene SAR image data augmentation based on shooting and...
2018
-
[14]
Remote Sensing ChatGPT: Solving remote sensing tasks with ChatGPT and visual models,
H. Guo, X. Su, C. Wu, B. Du, L. Zhang, and D. Li, “Remote Sensing ChatGPT: Solving remote sensing tasks with ChatGPT and visual models,”arXiv preprint arXiv:2401.09083,
-
[15]
RS- Agent: Automating remote sensing tasks through intelligent agent,
W. Xu, Z. Yu, Y. Wang, J. Wang, and M. Peng, “RS- Agent: Automating remote sensing tasks through intel- ligent agents,”arXiv preprint arXiv:2406.07089,
-
[16]
Change- Agent: Toward interactive comprehensive remote sens- ing change interpretation and analysis,
C. Liu, R. Zhao, H. Chen, Z. Zou, and Z. Shi, “Change- Agent: Toward interactive comprehensive remote sens- ing change interpretation and analysis,”arXiv preprint arXiv:2403.19646,
-
[17]
An LLM agent for automatic geospatial data analysis,
Y. Chen, W. Wang, and C. Kurtz, “An LLM agent for automatic geospatial data analysis,”arXiv preprint arXiv:2410.18792,
-
[18]
A. Shabbir, M. A. Munir, A. Dudhane, M. U. Sheikh, M. H. Khan, P. Fraccaro, J. B. Moreno, F. S. Khan, and S. Khan, “ThinkGeo: Evaluating tool- augmented agents for remote sensing tasks,”arXiv preprint arXiv:2505.23752,
-
[19]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan, “τ- bench: A benchmark for tool-agent-user interaction in real-world domains,”arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. 16 W. White, D. Burger, and C. Wang, “AutoGen: En- abling next-gen LLM applications via multi-agent con- versation,”arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Available: https://arxiv.org/abs/2402.18679
S. Hong, Y. Lin, B. Liu, B. Liu, B. Wu, C. Zhang, C. Wei, D. Li, J. Chen, J. Zhang, J. Wang, L. Zhang, L. Zhang, M. Yang, M. Zhuge, T. Guo, T. Zhou, W. Tao, X. Tang, X. Lu, X. Zheng, X. Liang, Y. Fei, Y. Cheng, Z. Gou, Z. Xu, and C. Wu, “Data Interpreter: An LLM agent for data science,”arXiv preprint arXiv:2402.18679,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.