Multi-Agent Routing as Set-Valued Prediction: A WildChat Benchmark and Cost-Aware Evaluation
Pith reviewed 2026-06-30 09:50 UTC · model grok-4.3
The pith
Supervised routers substantially outperform nearest-neighbor and zero-shot LLM routing on a new WildChat-derived benchmark for selecting sets of agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
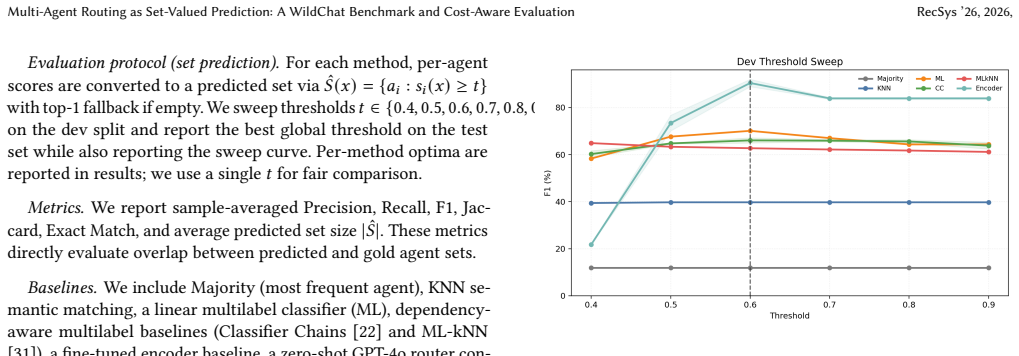
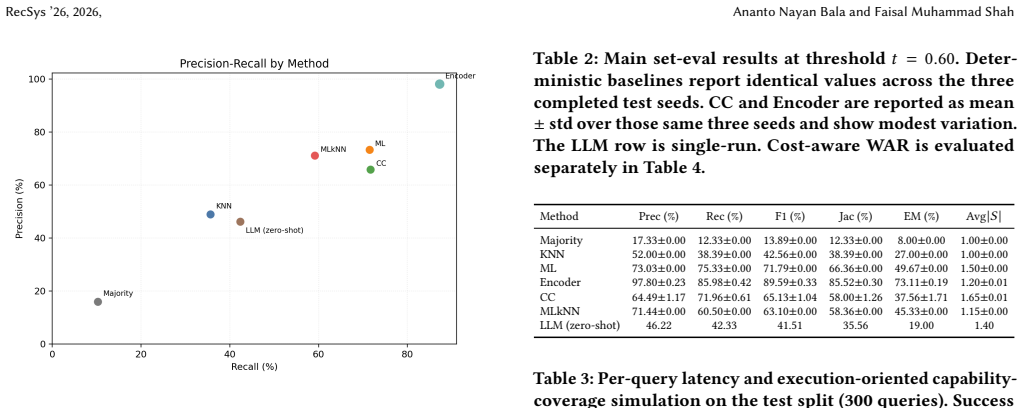
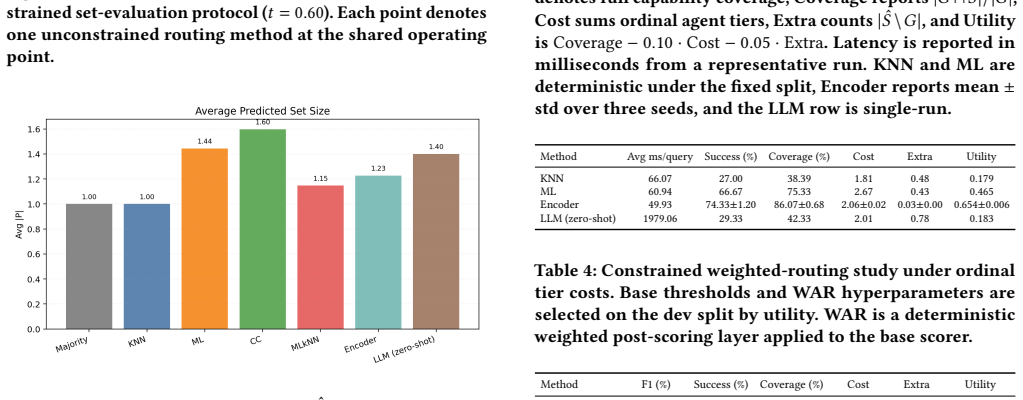
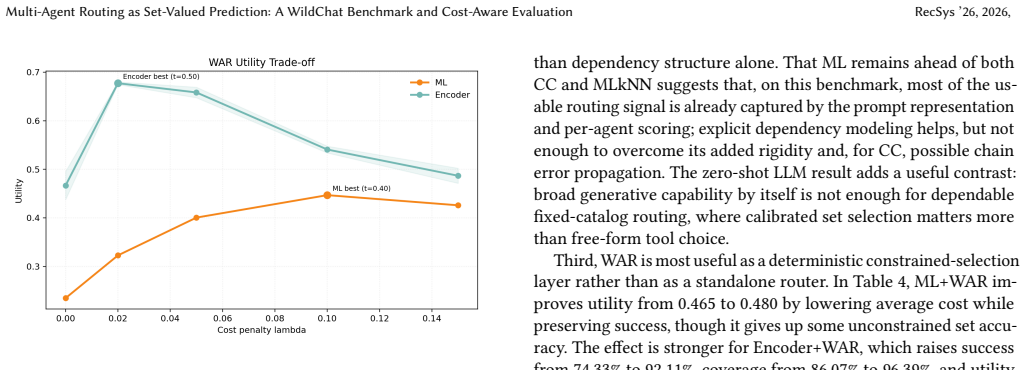
Supervised routers substantially outperform nearest-neighbor and zero-shot LLM routing. The fine-tuned encoder achieves the strongest unconstrained set accuracy, while the linear multilabel model provides the strongest practical baseline. In the constrained setting, the weighted routing layer improves utility when applied on top of strong supervised scorers, with the largest gain observed for Encoder+WAR. The benchmark and evaluation protocol support reproducible study of accuracy-cost trade-offs in fixed-catalog multi-agent routing.
What carries the argument
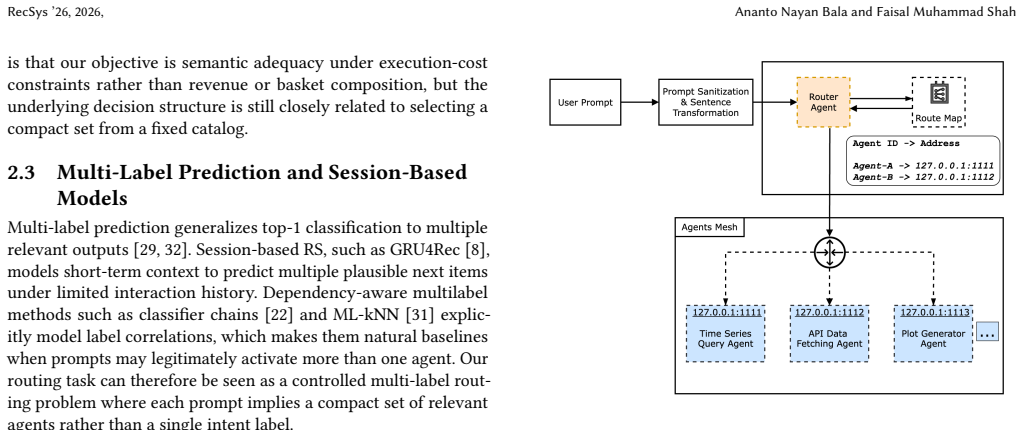
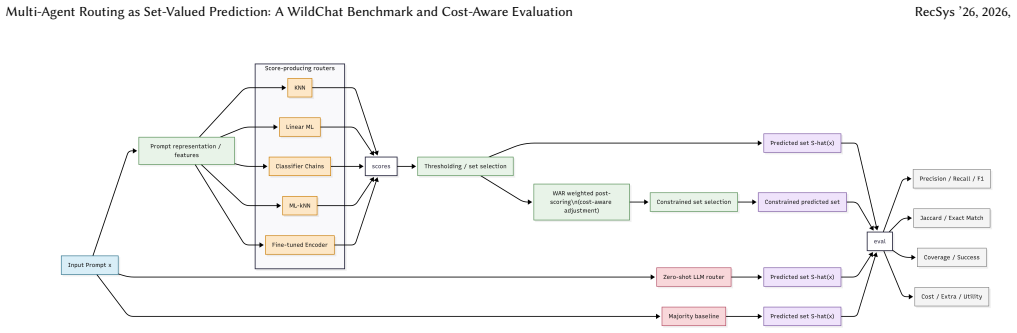
The Weighted Agent Routing (WAR) deterministic weighted post-scoring layer applied on top of base scorers, together with the multi-label evaluation protocol that combines set metrics and an execution-oriented capability-coverage simulation under ordinal cost tiers.
Load-bearing premise
The AI-assisted heuristic labels under a fixed schema and the controlled rebalancing accurately represent the true sets of required agents without introducing systematic bias into the multi-label evaluation.
What would settle it
Human re-labeling of the same 3,000 prompts that reverses the observed ranking between the fine-tuned encoder and the linear multilabel model on set-level metrics or on constrained utility.
Figures
read the original abstract
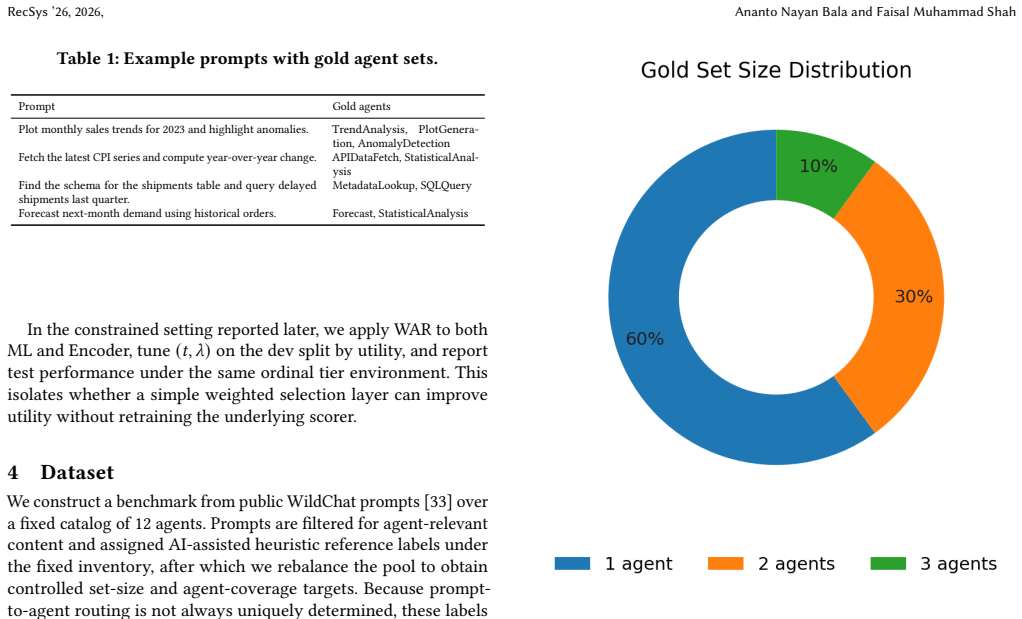
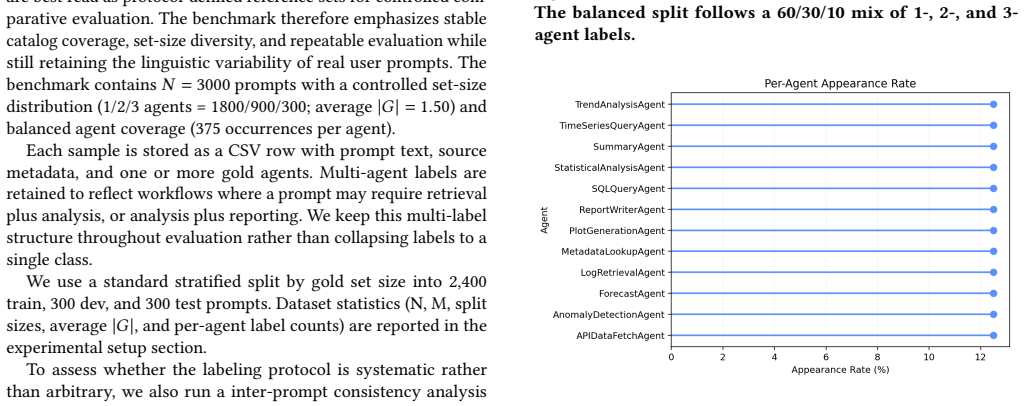
Tool and agent routing from natural-language prompts is naturally a set-valued prediction problem: a single query may require multiple agents, while over-selection increases execution cost. The benchmark introduced here is derived from WildChat and contains 3,000 prompts over a fixed 12-agent catalog, with AI-assisted heuristic labels under a fixed schema and controlled rebalancing for multi-label evaluation. The evaluation protocol combines set-level metrics (Precision, Recall, F1, Jaccard, and Exact Match), latency, an execution-oriented capability-coverage simulation, and a constrained weighted-routing setting based on ordinal agent-cost tiers. Compared methods include nearest-neighbor matching, linear multilabel classification, dependency-aware baselines, a fine-tuned encoder, deterministic weighted post-scoring via Weighted Agent Routing (WAR), and a zero-shot LLM baseline. Results show that supervised routers substantially outperform nearest-neighbor and zero-shot LLM routing. The fine-tuned encoder achieves the strongest unconstrained set accuracy, while the linear multilabel model provides the strongest practical baseline. In the constrained setting, the weighted routing layer improves utility when applied on top of strong supervised scorers, with the largest gain observed for Encoder+WAR. Overall, the benchmark and evaluation protocol support reproducible study of accuracy-cost trade-offs in fixed-catalog multi-agent routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a benchmark for multi-agent routing as a set-valued prediction task, derived from WildChat with 3,000 prompts over a fixed 12-agent catalog. Labels are produced via AI-assisted heuristics under a fixed schema with controlled rebalancing. It evaluates nearest-neighbor matching, linear multilabel classification, dependency-aware baselines, a fine-tuned encoder, deterministic Weighted Agent Routing (WAR), and zero-shot LLM routing using set-level metrics (Precision/Recall/F1/Jaccard/Exact Match), latency, capability-coverage simulation, and a constrained weighted-routing setting. Claims include that supervised routers substantially outperform nearest-neighbor and zero-shot baselines, with the fine-tuned encoder strongest on unconstrained set accuracy, the linear model strongest as a practical baseline, and WAR improving utility on top of supervised scorers (largest gain for Encoder+WAR).
Significance. If the labels are shown to be reliable, the work supplies a reproducible benchmark and cost-aware evaluation protocol for fixed-catalog multi-agent routing, including an execution-oriented simulation and ordinal cost tiers that could support future accuracy-cost studies.
major comments (1)
- [Benchmark construction and labeling procedure (as described in the abstract)] The central empirical claims (supervised routers outperforming baselines on set accuracy and constrained utility) rest on labels generated by AI-assisted heuristics under a fixed 12-agent schema followed by controlled rebalancing. No description of human validation, inter-annotator agreement, or sensitivity analysis to the labeling procedure is provided; any systematic bias in agent assignment would propagate to all reported metrics (Precision/Recall/F1, capability-coverage, and WAR utility gains) and undermine the comparative results.
minor comments (2)
- [Abstract] The abstract reports comparative outcomes without any numerical values, error bars, dataset statistics, or label-distribution details, which reduces the ability to gauge effect sizes from the summary alone.
- [Benchmark construction (as described in the abstract)] The description of how the 12-agent schema and rebalancing interact with prompt distribution is not elaborated, leaving unclear whether certain agents are over- or under-represented in the final label sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the labeling procedure. We address the concern below and will revise the manuscript to strengthen the benchmark's validation.
read point-by-point responses
-
Referee: The central empirical claims (supervised routers outperforming baselines on set accuracy and constrained utility) rest on labels generated by AI-assisted heuristics under a fixed 12-agent schema followed by controlled rebalancing. No description of human validation, inter-annotator agreement, or sensitivity analysis to the labeling procedure is provided; any systematic bias in agent assignment would propagate to all reported metrics (Precision/Recall/F1, capability-coverage, and WAR utility gains) and undermine the comparative results.
Authors: We agree that the reliability of the labels is central to the validity of the reported results. The current manuscript describes the labeling as AI-assisted heuristics under a fixed schema with controlled rebalancing but does not include human validation, inter-annotator agreement, or sensitivity analysis. In the revised version we will add a human validation study on a 300-prompt subset (reporting agreement with the heuristic labels), inter-annotator agreement statistics, and a sensitivity analysis varying heuristic parameters to quantify impact on relative method rankings. These additions will directly address the risk of systematic bias. revision: yes
Circularity Check
No circularity: purely empirical benchmark study with no derivations or self-referential predictions
full rationale
The paper introduces a new benchmark from WildChat with AI-assisted heuristic labels and reports direct empirical comparisons of routing methods (nearest-neighbor, linear multilabel, encoder, WAR, zero-shot LLM) using set-level metrics. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims rest on performance numbers computed against the constructed labels, which constitutes an independent empirical evaluation rather than any reduction by construction. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moran Beladev, Lior Rokach, and Bracha Shapira. 2016. Recommender systems for product bundling.Knowledge-Based Systems111 (2016), 193–206. doi:10.1016/ j.knosys.2016.08.013
2016
-
[2]
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to Rank: From Pairwise Approach to Listwise Approach. InProceedings of the 24th International Conference on Machine Learning (ICML ’07). ACM, New York, NY, USA, 129–136. doi:10.1145/1273496.1273513
-
[3]
Inigo Casanueva, Tadas Temcinas, Daniela Gerz, Matthew Henderson, and Ivan Vulic. 2020. Efficient intent detection with dual sentence encoders. InNLP4ConvAI Workshop @ ACL
2020
-
[4]
Lingjiao Chen et al. 2023. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.arXiv preprint(2023)
2023
-
[5]
Dujian Ding et al. 2024. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. InICLR 2024
2024
-
[6]
Chih-Wen Goo, Guang Gao, Yun-Kai Hsu, Chih-Li Huo, Tsung-Chieh Chen, Keng- Wei Hsu, and Yun-Nung Chen. 2018. Slot-gated modeling for joint slot filling and intent prediction. InNAACL
2018
-
[7]
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2023. ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. Multi-Agent Routing as Set-Valued Prediction: A WildChat Benchmark and Cost-Aware Evaluation RecSys ’26, 2026, InThirty-seventh Conference on Neural Information Processing Systems. https: //openreview.net/forum?id...
2023
-
[8]
Balazs Hidasi et al. 2016. Session-based Recommendations with Recurrent Neural Networks.arXiv preprint arXiv:1511.06939(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Sirui Hong et al. 2024. MetaGPT: Meta Programming for a Multi-Agent Collabora- tive Framework. InICLR 2024. https://openreview.net/forum?id=VtmBAGCN7o
2024
-
[10]
2010.Recommender Systems: An Introduction
Dietmar Jannach et al. 2010.Recommender Systems: An Introduction. Cambridge University Press
2010
-
[11]
Vladimir Karpukhin et al . 2020. Dense Passage Retrieval for Open-Domain Question Answering. InEMNLP 2020
2020
-
[12]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InSIGIR 2020
2020
-
[13]
Jimmy Lin et al . 2021. Pretrained Transformers for Text Ranking: BERT and Beyond.Synthesis Lectures(2021)
2021
-
[14]
Junhua Liu, Tan Yong Keat, Bin Fu, and Kwan Hui Lim. 2024. LARA: Linguistic- Adaptive Retrieval-Augmentation for Multi-Turn Intent Classification. InPro- ceedings of EMNLP 2024 (Industry Track). doi:10.18653/v1/2024.emnlp-industry.82
-
[15]
Junhua Liu, Yong Keat Tan, Bin Fu, and Kwan Hui Lim. 2025. From Intents to Con- versations: Generating Intent-Driven Dialogues with Contrastive Learning for Multi-Turn Classification. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery, New ...
-
[16]
Keming Lu et al. 2024. Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models. InNAACL 2024. https://aclanthology.org/2024.naacl- long.109/
2024
-
[17]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. Gorilla: Large Language Model Connected with Massive APIs. InNeurIPS 2024. https: //arxiv.org/abs/2305.15334
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Chen Qian et al. 2024. ChatDev: Communicative Agents for Software Develop- ment. InACL 2024. https://aclanthology.org/2024.acl-long.810/
2024
- [20]
-
[21]
Yujia Qin et al . 2024. ToolLLM: Facilitating Large Language Models to Mas- ter 16000+ Real-world APIs. InICLR 2024. https://openreview.net/forum?id= dHng2O0Jjr
2024
-
[22]
Jesse Read et al. 2011. Classifier Chains for Multi-label Classification.Machine Learning(2011)
2011
-
[23]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InEMNLP 2019. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Steffen Rendle et al. 2009. BPR: Bayesian Personalized Ranking from Implicit Feedback. InUAI 2009
2009
-
[25]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, et al. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InNeurIPS 2023. https://arxiv.org/ abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Kaitao Song et al. 2020. MPNet: Masked and Permuted Pre-training for Language Understanding. InNeurIPS 2020
2020
-
[27]
Harald Steck. 2013. Evaluation of Recommendations: Rating-Prediction and Ranking. InRecSys 2013
2013
-
[28]
Nandan Thakur et al. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InNeurIPS Datasets and Benchmarks Track
2021
-
[29]
Grigorios Tsoumakas and Ioannis Katakis. 2007. Multi-Label Classification: An Overview.IJDM(2007)
2007
-
[30]
Qingyun Wu et al. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. InCOLM 2024. https://openreview.net/forum?id= BAakY1hNKS
2024
-
[31]
Min-Ling Zhang and Zhi-Hua Zhou. 2007. ML-KNN: A Lazy Learning Approach to Multi-Label Learning.Pattern Recognition(2007)
2007
-
[32]
Min-Ling Zhang and Zhi-Hua Zhou. 2014. A Review on Multi-Label Learning Algorithms.IEEE TKDE(2014)
2014
-
[33]
Wenting Zhao et al. 2024. WildChat: 1M ChatGPT Interaction Logs in the Wild. InICLR 2024. https://openreview.net/forum?id=Bl8u7ZRlbM
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.