Faster than Fast-LTS: Robust Regression and Outlier Detection with DC Programming
Pith reviewed 2026-06-30 08:31 UTC · model grok-4.3
The pith
Reformulating Least Trimmed Squares as a DC program enables the sBDCA algorithm to solve robust regression faster and more accurately than Fast-LTS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
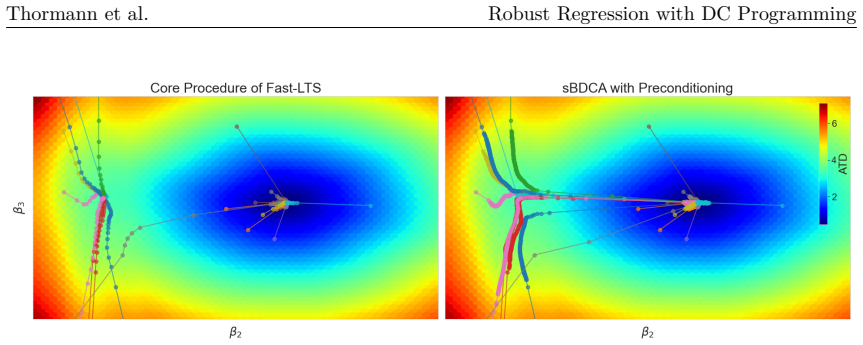
The LTS problem can be exactly recast as a concave minimization subject to a capped simplex constraint. The sBDCA algorithm solves this reformulation and, when combined with a derived preconditioning matrix, converges to a local solution with linear rate in the fastest case while delivering robust performance from a single initialization.
What carries the argument
The successive Boosted Difference of Convex Functions Algorithm (sBDCA) applied to the DC reformulation of the LTS estimator under a capped simplex constraint, augmented by a problem-specific preconditioning matrix.
If this is right
- sBDCA converges linearly to local solutions via the Lojasiewicz property.
- The preconditioning matrix enables robustness from one initialization without loss of solution quality.
- The method runs up to 3.25 times faster than Fast-LTS on tested instances.
- Objective function values are up to 90% lower than those from Fast-LTS, especially in high dimensions.
- Open Python code is provided for practical use in robust regression.
Where Pith is reading between the lines
- The DC reformulation approach could be tested on other robust estimators that involve combinatorial subset selection.
- Preconditioning strategies derived here might improve convergence for similar DC programs in statistics.
- High-dimensional performance gains suggest potential for scaling robust methods to large datasets where Fast-LTS struggles.
Load-bearing premise
The combinatorial LTS problem admits an exact reformulation as a concave minimization over a capped simplex whose solutions match the original problem, and the preconditioning matrix ensures single-start robustness.
What would settle it
Running the method on a high-dimensional dataset where the preconditioned sBDCA returns a worse objective value or requires multiple starts to match Fast-LTS performance would falsify the practical claims.
Figures


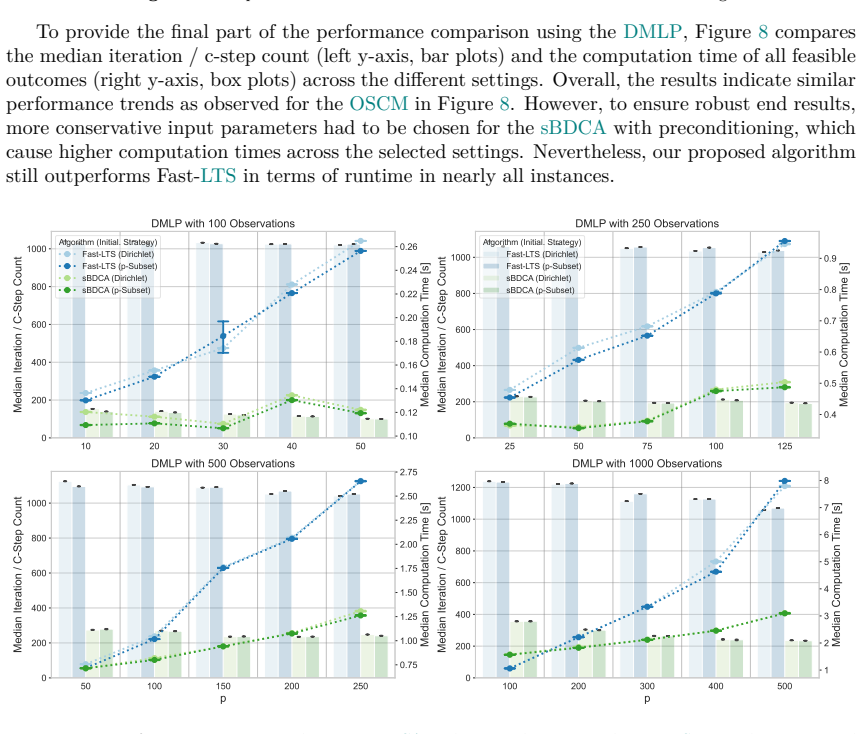
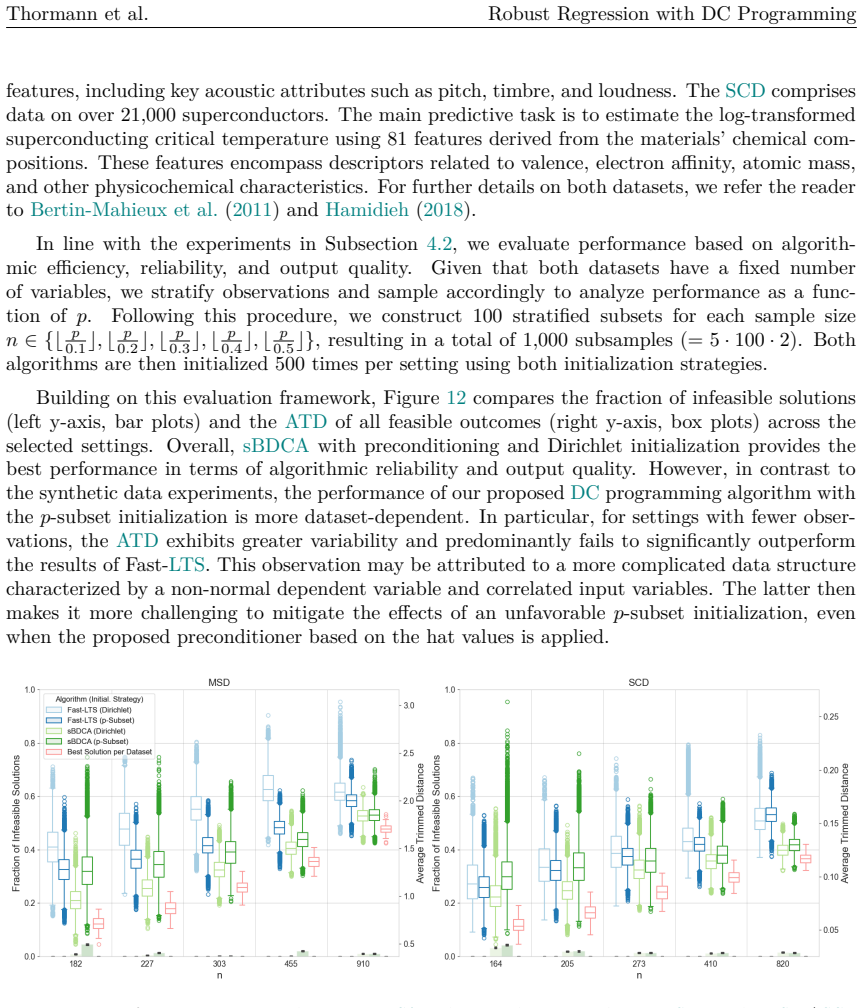
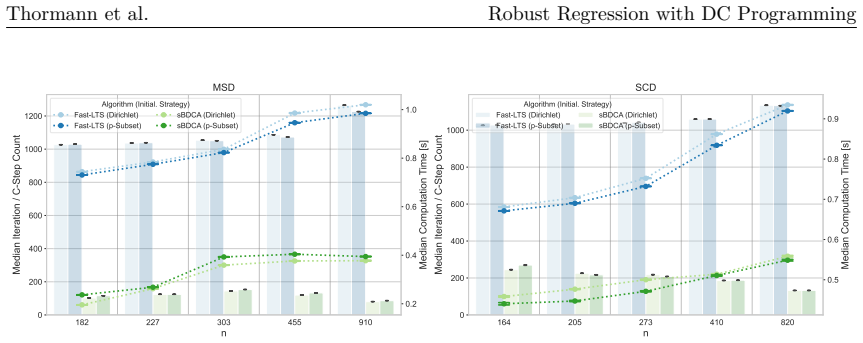

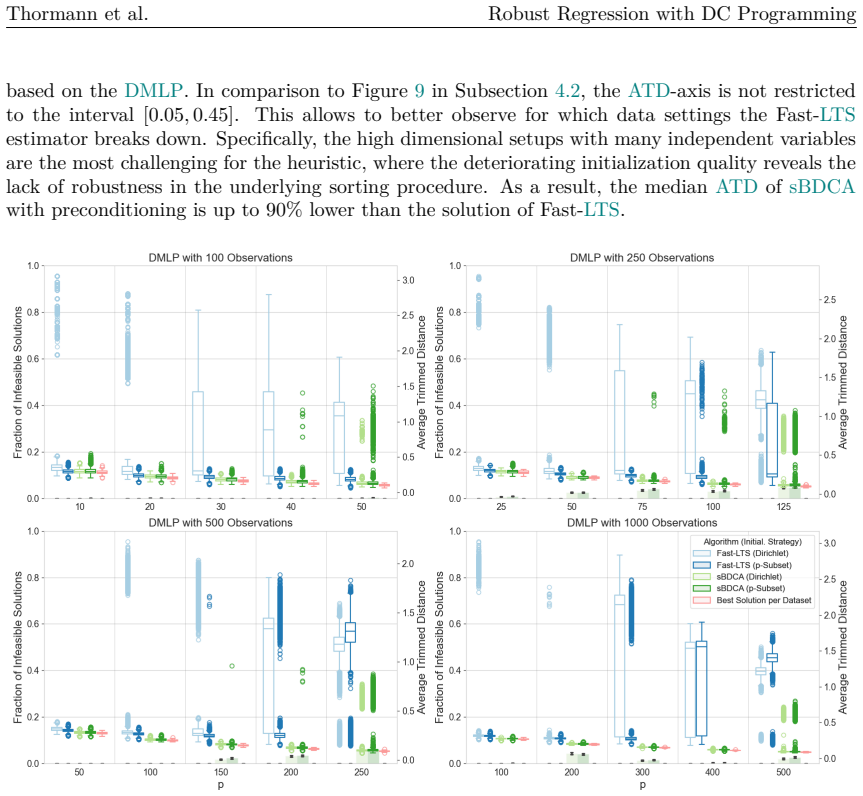
read the original abstract
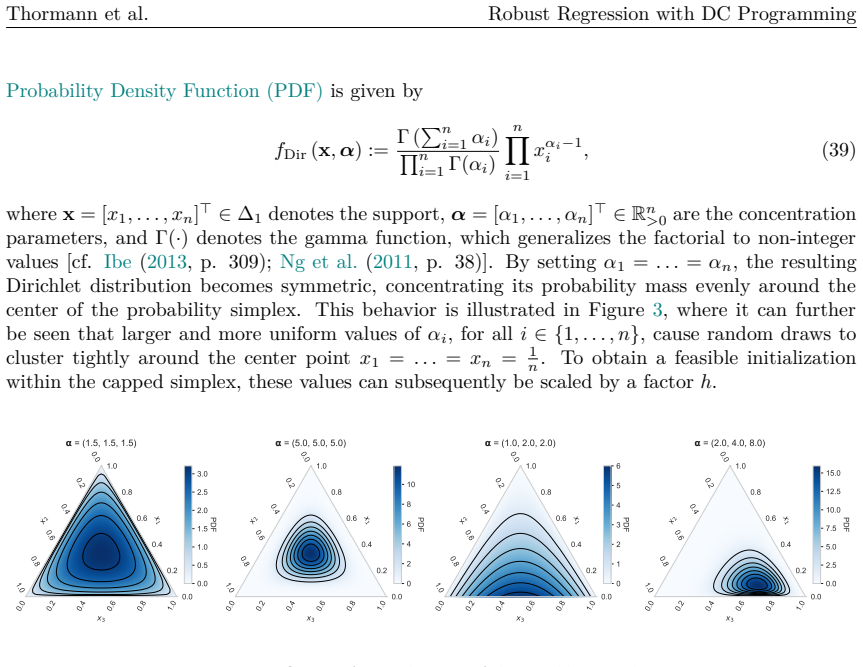
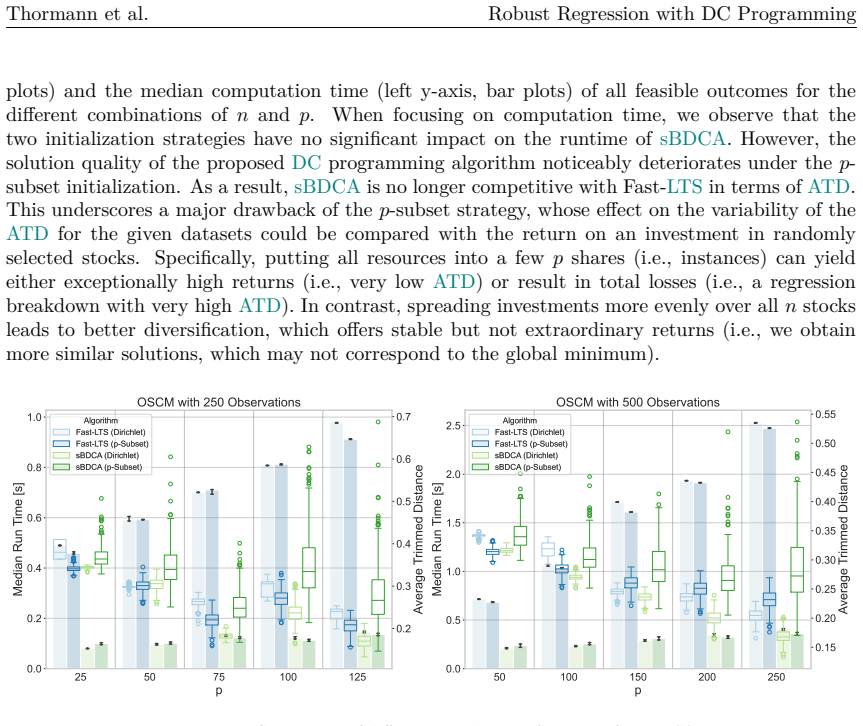
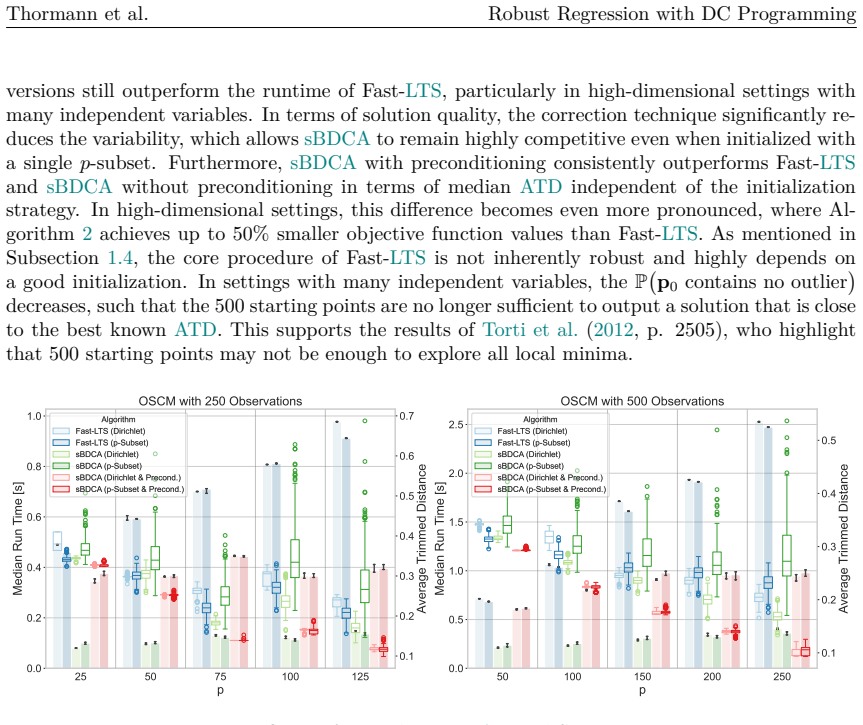
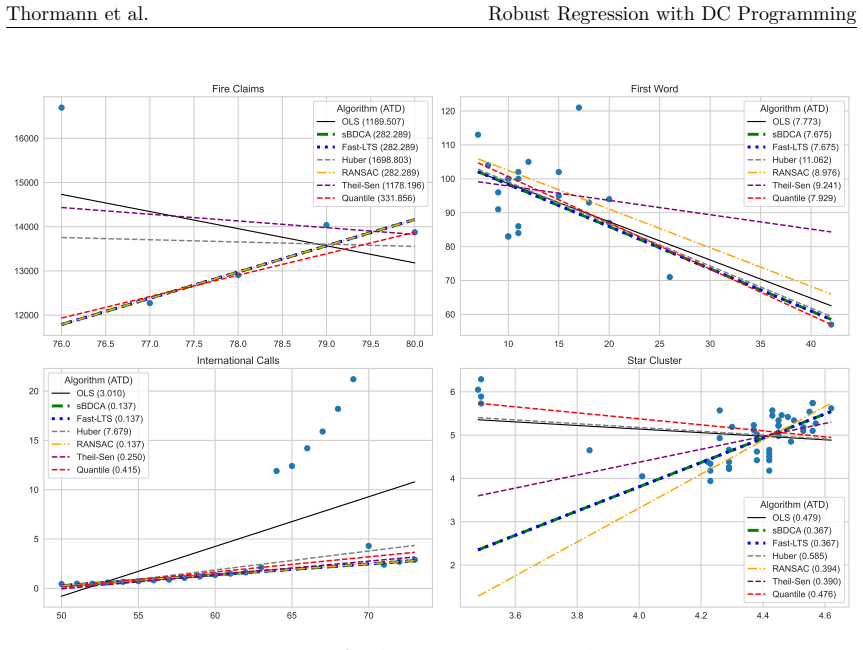
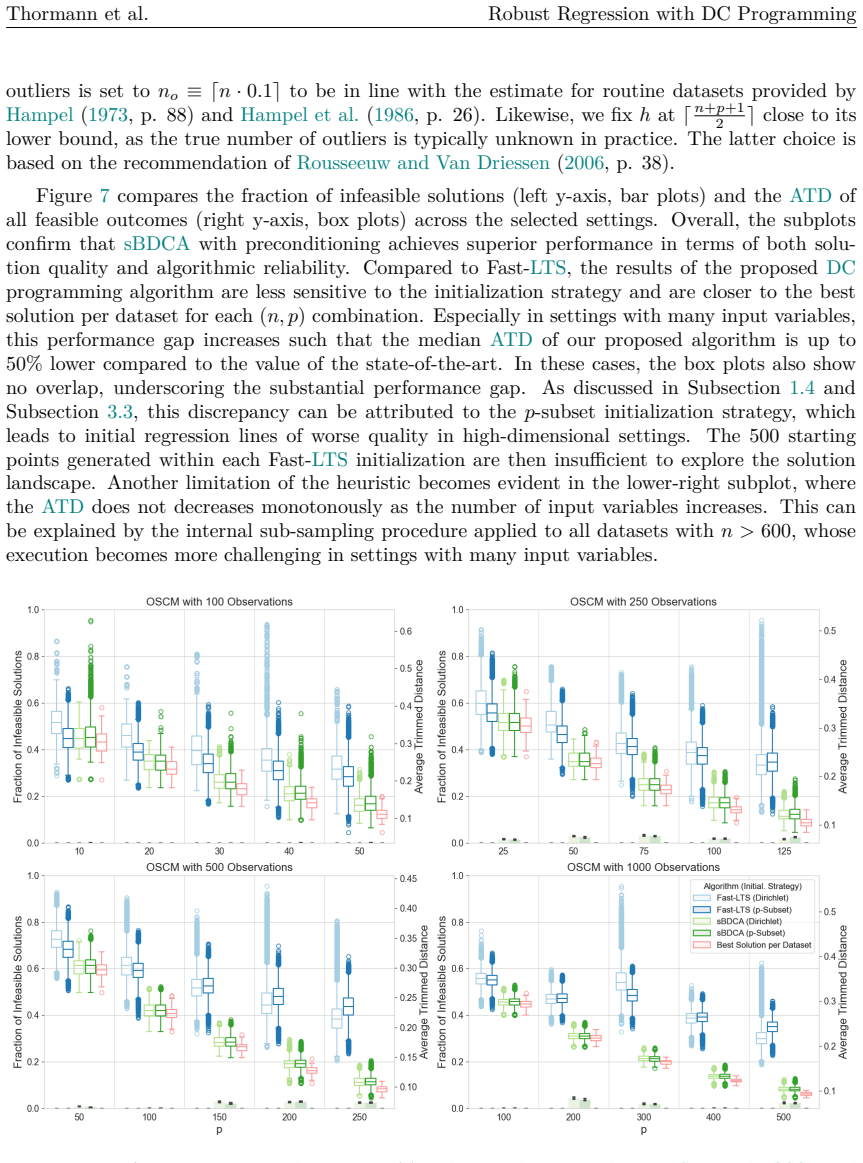
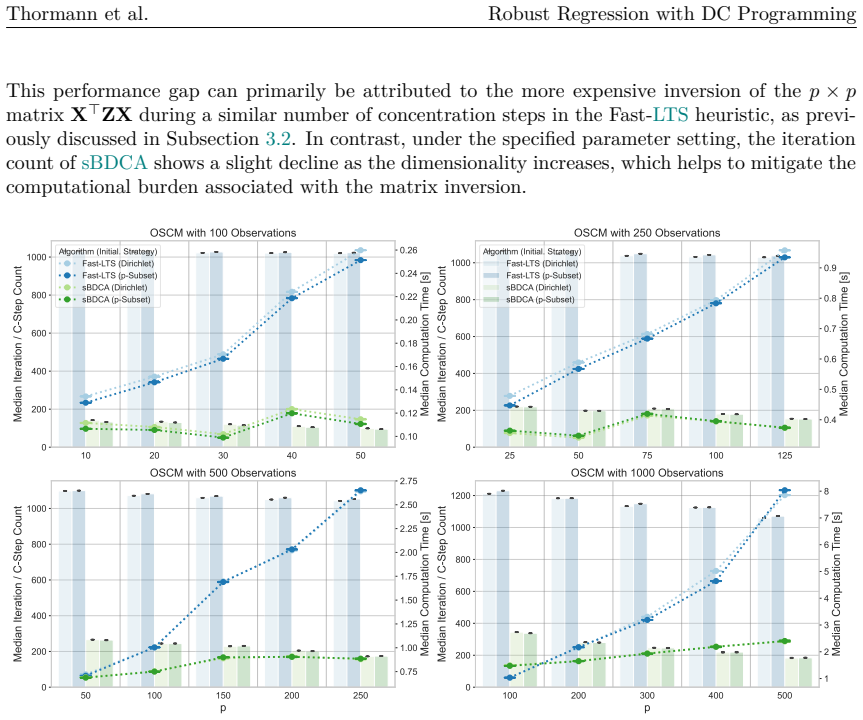
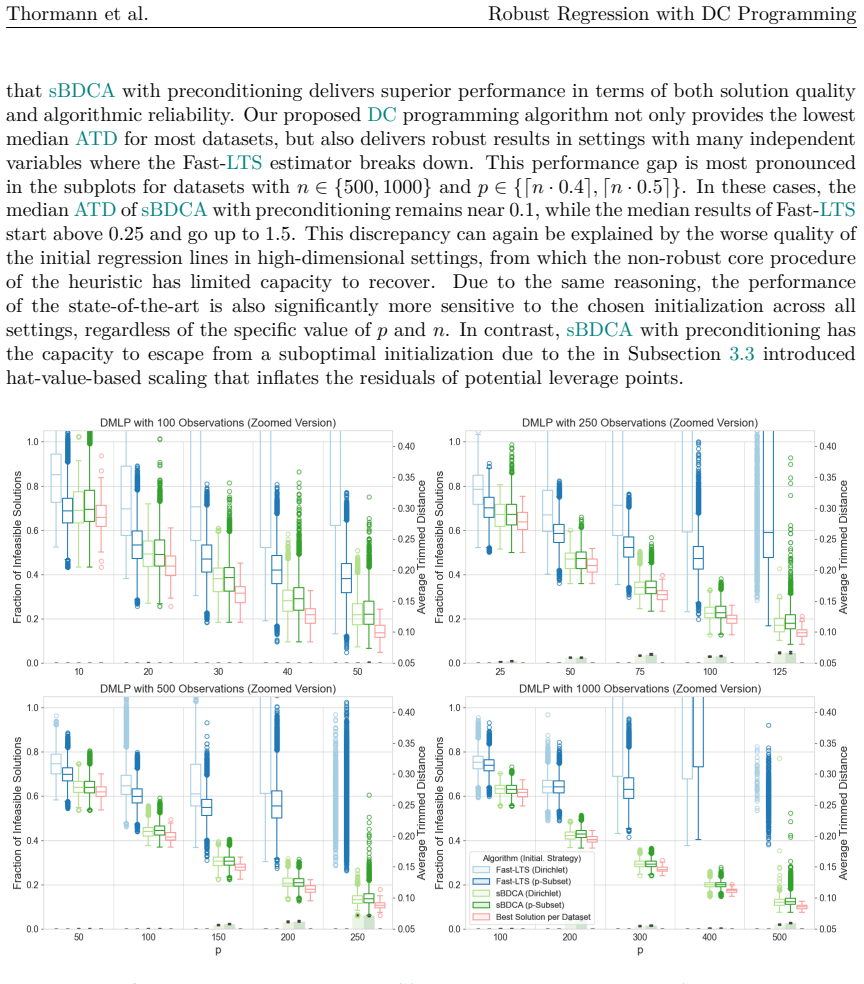
When datasets contain outliers, robust regression is a well-established alternative to Ordinary Least Squares. A commonly employed robust estimator is Least Trimmed Squares (LTS), which computes the regression coefficients from a subset of observations. Determining the exact solution corresponds to a combinatorial problem with prohibitive computational costs, even for instances of moderate dimension. Thus, the most prevalent approach in practice remains a heuristic known as Fast-LTS. Although the heuristic often performs effectively, certain elements of the approach remain open to improvement. In particular, its core procedure provides robust results only when initialized with a large number of starting points. To address the heuristic's limitations, this paper reformulates the LTS problem as a concave minimization problem subject to a capped simplex constraint, and proposes the successive Boosted Difference of Convex Functions Algorithm (sBDCA) as a solution method. Theoretically, we establish via the \L ojasiewicz property that sBDCA converges to a local solution with a linear rate in the fastest case. To ensure robustness from a single initialization in practice, we derive and integrate a problem-specific preconditioning matrix into the algorithmic setup. Building on this theoretical foundation, we conduct numerical studies on various synthetic and real-world datasets to demonstrate the effectiveness of sBDCA with preconditioning. Specifically, we show that our approach is up to 3.25 times faster than Fast-LTS and achieves up to 90% lower objective function values, particularly in high-dimensional settings. As all code is openly available, this paper further provides a practical guide to robust regression in Python.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reformulates the combinatorial Least Trimmed Squares (LTS) problem exactly as a concave minimization over a capped simplex constraint and introduces the successive Boosted Difference of Convex Functions Algorithm (sBDCA) together with a derived problem-specific preconditioning matrix. It establishes linear convergence to a local solution via the Łojasiewicz property and reports that sBDCA with preconditioning is up to 3.25 times faster than Fast-LTS while attaining up to 90% lower objective values on synthetic and real data, with all code released openly.
Significance. If the DC equivalence and preconditioner construction hold, the paper supplies a theoretically grounded, single-start robust alternative to Fast-LTS that is especially advantageous in high dimensions. The explicit reformulation, the Lojasiewicz-based rate, the open reproducible code, and the fair numerical comparisons (identical objective, same instances) are concrete strengths.
minor comments (2)
- The abstract states convergence 'in the fastest case'; a brief clarification of the precise Łojasiewicz exponent range that yields the linear rate would improve readability.
- Notation for the capped simplex and the preconditioning matrix could be introduced once in a dedicated preliminary section rather than inline in the algorithmic description.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the manuscript, the recognition of its theoretical and practical contributions, and the recommendation to accept.
Circularity Check
No significant circularity identified
full rationale
The paper's derivation begins with an explicit combinatorial-to-DC reformulation of the LTS objective (concave minimization over capped simplex) and derives a preconditioning matrix from the problem geometry; both steps are presented as direct mathematical constructions rather than fits. Convergence follows from the external Łojasiewicz inequality with a stated linear rate. Numerical claims compare runtime and attained objective values on identical instances against Fast-LTS; these are empirical measurements, not quantities forced by internal fitting or self-citation. No load-bearing step reduces a reported result to its own inputs by construction, and the chain is self-contained against external benchmarks and open code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LTS objective admits an exact reformulation as concave minimization subject to a capped simplex constraint.
Reference graph
Works this paper leans on
-
[1]
Aggarwal, C. C. (2015).Data Mining: The Textbook, 1st edn, Springer, Cham.https: //doi.org/10.1007/978-3-319-14142-8
-
[2]
Agulló, J. (2001). New algorithms for computing the least trimmed squares regression estima- tor,Computational Statistics & Data Analysis36(4): 425–439.https://doi.org/10.1016/ S0167-9473(00)00056-6
2001
-
[3]
Ahipaşaoğlu, S. D. (2015). Fast algorithms for the minimum volume estimator,Journal of Global Optimization62: 351–370.https://doi.org/10.1007/s10898-014-0233-8
-
[4]
Al-Noor, N. H. and Mohammad, A. A. (2013). Model of Robust Regression with Parametric and Nonparametric Methods,Mathematical Theory and Modeling3(5): 27–39
2013
-
[5]
Alfons, A., Croux, C. and Gelper, S. (2013). Sparse least trimmed squares regression for analyzing high-dimensional large data sets,The Annals of Applied Statistics7(1): 226–248. https://doi.org/10.1214/12-AOAS575
-
[6]
Alma, Ö. G. (2011). Comparison of robust regression methods in linear regression,Interna- tional Journal of Contemporary Mathematical Sciences6(9): 409–421
2011
-
[7]
Ang, A., Ma, J., Liu, N., Huang, K. and Wang, Y. (2021). Fast Projection onto the Capped Simplex with Applications to Sparse Regression in Bioinformatics, arXiv preprint, arXiv:2110.08471 [math.OC].https://doi.org/10.48550/arXiv.2110.08471
-
[8]
Anjos, M. F. and Lasserre, J. B. (2011).Handbook on Semidefinite, Conic and Polynomial Optimization, International Series in Operations Research & Management Science, 1st edn, Springer, New York.https://doi.org/10.1007/978-1-4614-0769-0
-
[9]
Antoniou, A. and Lu, W.-S. (2021).Practical Optimization: Algorithms and Engineering Applications, Texts in Computer Science, 2nd edn, Springer, New York.https://doi.org/ 10.1007/978-1-0716-0843-2
-
[10]
Aragón-Artacho, F. J., Campoy, R. and Vuong, P. T. (2022). The Boosted DC Algorithm for Linearly Constrained DC Programming,Set-Valued and Variational Analysis30: 1265–1289. https://doi.org/10.1007/s11228-022-00656-x
-
[11]
AcceleratingtheDCalgorithm for smooth functions,Mathematical Programming169: 95–118.https://doi.org/10.1007/ s10107-017-1180-1
Aragón-Artacho, F.J., Fleming, R.M.andVuong, P.T.(2018). AcceleratingtheDCalgorithm for smooth functions,Mathematical Programming169: 95–118.https://doi.org/10.1007/ s10107-017-1180-1
2018
-
[12]
Aragón-Artacho, F. J. and Vuong, P. T. (2020). The Boosted Difference of Convex Functions Algorithm For Nonsmooth Functions,SIAM Journal on Optimization30(1): 980–1006.https: //doi.org/10.1137/18M123339X
-
[13]
Armstrong, R. A. (2014). When to use the Bonferroni correction,Ophthalmic and Physiological Optics34(5): 502–508.https://doi.org/10.1111/opo.12131
-
[14]
Atkinson, A. C. and Cheng, T.-C. (1999). Computing least trimmed squares regression with the forward search,Statistics and Computing9: 251–263.https://doi.org/10.1023/A: 1008942604045
work page doi:10.1023/a: 1999
-
[15]
Baesens, B., Mues, C., Martens, D. and Vanthienen, J. (2009). 50 years of data mining and OR: upcoming trends and challenges,Journal of the Operational Research Society60(sup1): S16– S23.https://doi.org/10.1057/jors.2008.171. 32 Thormann et al. Robust Regression with DC Programming
-
[16]
Barbato, M. and Ceselli, A. (2024). Mathematical programming for simultaneous feature selection and outlier detection under l1 norm,European Journal of Operational Research 316(3): 1070–1084.https://doi.org/10.1016/j.ejor.2024.03.035
-
[17]
Becher, H., Hall, P. and Wilson, S. R. (1993). Bootstrap hypothesis testing procedures,Bio- metrics49(4): 1268–1272.https://doi.org/10.2307/2532271
-
[18]
and Lucet, Y
Beiranvand, V., Hare, W. and Lucet, Y. (2017). Best practices for comparing optimiza- tion algorithms,Optimization and Engineering18: 815–848.https://doi.org/10.1007/ s11081-017-9366-1
2017
-
[19]
Beliakov, G., Johnstone, M. and Nahavandi, S. (2012). Computing of high breakdown re- gression estimators without sorting on graphics processing units,Computing94: 433–447. https://doi.org/10.1007/s00607-011-0183-7
-
[20]
Bernholt, T. (2006). Robust Estimators are Hard to Compute, Technical Report, No. 2005/52, Universität Dortmund, Sonderforschungsbereich 475 - Komplexitätsreduktion in Multivari- aten Datenstrukturen, Dortmund.https://www.econstor.eu/bitstream/10419/22645/1/ tr52-05.pdf
2006
-
[21]
P., Whitman, B
Bertin-Mahieux, T., Ellis, D. P., Whitman, B. and Lamere, P. (2011). The Million Song Dataset. UCI Machine Learning Repository. Available athttps://archive.ics.uci.edu/ dataset/203/yearpredictionmsd
2011
-
[22]
Bertsekas, D. P. (1999).Nonlinear Programming, 2nd edn, Athena Scientific, Belmont (Mas- sachusetts). ISBN 1-886529-00-0
1999
-
[23]
Bertsimas, D. and King, A. (2016). OR Forum—An Algorithmic Approach to Linear Regres- sion,Operations Research64(1): 2–16.https://doi.org/10.1287/opre.2015.1436
-
[24]
Bonferroni, C. (1936). Teoria statistica delle classi e calcolo delle probabilita,Pubblicazioni del R istituto superiore di scienze economiche e commericiali di firenze8: 3–62
1936
-
[25]
Boyd, S. and Vandenberghe, L. (2009).Convex Optimization, Cambridge University Press, Cambridge.https://doi.org/10.1017/CBO9780511804441
-
[26]
Brualdi, R. A. and Ryser, H. J. (1991).Combinatorial Matrix Theory, Encyclopedia of Mathematics and its Applications, 1st edn, Cambridge University Press, Cambridge.https: //doi.org/10.1017/CBO9781107325708
-
[27]
Çelik, M. and Abur, A. (1992). A robust WLAV state estimator using transformations,IEEE Transactions on Power Systems7(1): 106–113.https://doi.org/10.1109/59.141693
-
[28]
Chatterjee, S. and Simonoff, J. S. (2020).Handbook of Regression Analysis With Applications in R, Wiley Series in Probability and Statistics, 2nd edn, John Wiley & Sons, Hoboken (NJ). https://doi.org/10.1002/9781119392491
-
[29]
Chave, A. D. and Thomson, D. J. (2003). A Bounded Influence Regression Estimator Based on the Statistics of the Hat Matrix,Journal of the Royal Statistical Society Series C: Applied Statistics52(3): 307–322.https://doi.org/10.1111/1467-9876.00406
-
[30]
and Paschalidis, I
Chen, R. and Paschalidis, I. C. (2018). A Robust Learning Approach for Regression Mod- els Based on Distributionally Robust Optimization,Journal of Machine Learning Research 19(13): 1–48.http://jmlr.org/papers/v19/17-295.html
2018
-
[31]
and Gondzio, J
Cipolla, S. and Gondzio, J. (2024). Proximal-stabilized semidefinite programming, Computational Optimization and Applications,pp. 1–44.https://doi.org/10.1007/ s10589-024-00614-3
2024
-
[32]
Critchley, F., Schyns, M., Haesbroeck, G., Fauconnier, C., Lu, G., Atkinson, R. A. and Wang, D. Q. (2010). A relaxed approach to combinatorial problems in robustness and diagnostics, Statistics and Computing20: 99–115.https://doi.org/10.1007/s11222-009-9119-x
-
[33]
and Massart, D
De Maesschalck, R., Jouan-Rimbaud, D. and Massart, D. L. (2000). The Mahalanobis distance, Chemometrics and Intelligent Laboratory Systems50(1): 1–18.https://doi.org/10.1016/ 33 Thormann et al. Robust Regression with DC Programming S0169-7439(99)00047-7
2000
-
[34]
de Oliveira, W. (2020). The ABC of DC programming,Set-Valued and Variational Analysis 28: 679–706.https://doi.org/10.1007/s11228-020-00566-w
-
[35]
Doğru, F. Z. and Arslan, O. (2018). Robust mixture regression modeling using the least trimmed squares (LTS)-estimation method,Communications in Statistics - Simulation and Computation47(7): 2184–2196.https://doi.org/10.1080/03610918.2017.1341528
- [36]
-
[37]
Fahrmeir, L., Kneib, T., Lang, S. and Marx, B. D. (2021).Regression: Models, Methods and Applications, 2nd edn, Springer, Berlin.https://doi.org/10.1007/978-3-662-63882-8
-
[38]
Fernandes, A. A. A., Koehler, M., Konstantinou, N., Pankin, P. and Paton, N. P. (2023). Data preparation: A technological perspective and review,SN Computer Science4(425): 1– 20.https://doi.org/10.1007/s42979-023-01828-8
-
[39]
Flores, S. (2015). SOCP relaxation bounds for the optimal subset selection problem applied to robust linear regression,European Journal of Operational Research246(1): 44–50.https: //doi.org/10.1016/j.ejor.2015.04.024
-
[40]
(2015).Applied Regression Analysis and Generalized Linear Models, 3rd edn, SAGE Publications, Thousand Oaks (California)
Fox, J. (2015).Applied Regression Analysis and Generalized Linear Models, 3rd edn, SAGE Publications, Thousand Oaks (California)
2015
-
[41]
and Weisberg, S
Fox, J. and Weisberg, S. (2019).An R companion to applied regression, 3rd edn, SAGE Publications, Thousand Oaks (California)
2019
-
[42]
Gafni, E. M. and Bertsekas, D. P. (1984). Two-Metric Projection Methods for Constrained Optimization,SIAM Journal on Control and Optimization22(6): 936–964.https://doi. org/10.1137/0322061
-
[43]
and Herrera, F
García, S., Luengo, J. and Herrera, F. (2015).Data Preprocessing in Data Mining, Intel- ligent Systems Reference Library, 1st edn, Springer, Cham.https://doi.org/10.1007/ 978-3-319-10247-4
2015
-
[44]
Giloni, A. and Padberg, M. (2002). Least Trimmed Squares Regression, Least Median Squares Regression, and Mathematical Programming,Mathematical and Computer Modelling35(9– 10): 1043–1060.https://doi.org/10.1016/S0895-7177(02)00069-9
-
[45]
Giorgi, G., Jimenéz, B. and Novo, V. (2023).Basic Mathematical Programming Theory, International Series in Operations Research & Management Science, 1st edn, Springer, Cham. https://doi.org/10.1007/978-3-031-30324-1
-
[46]
Habshah, M., Norazan, M. R. and Rahmatullah Imon, A. H. (2009). The performance of diagnostic-robust generalized potentials for the identification of multiple high leverage points in linear regression,Journal of Applied Statistics36(5): 507–520.https://doi.org/10.1080/ 02664760802553463
2009
-
[47]
Hadi, A. S. and Simonoff, J. S. (1993). Procedures for the Identification of Multiple Outliers in Linear Models,Journal of the American Statistical Association88(424): 1264–1272.https: //doi.org/10.1080/01621459.1993.10476407
-
[48]
Hamidieh, K. (2018). A data-driven statistical model for predicting the critical temperature of a superconductor,Computational Materials Science154: 346–354.https://doi.org/10. 1016/j.commatsci.2018.07.052
2018
-
[49]
Hampel, F. R. (1973). Robust estimation: A condensed partial survey,Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete27: 87–104.https://doi.org/10.1007/ BF00536619
1973
-
[50]
Hampel, F. R., Ronchetti, E. M., Rousseeuw, P. J. and Stahel, W. A. (1986).Robust Statistics: The Approach Based on Influence Functions, Wiley Series in Probability and Statistics, 1st edn, John Wiley & Sons, New York.https://doi.org/10.1002/9781118186435. 34 Thormann et al. Robust Regression with DC Programming
-
[51]
Harrington, J. and Salibián-Barrera, M. (2010). Finding approximate solutions to combinato- rial problems with very large data sets using BIRCH,Computational Statistics & Data Analysis 54(3): 655–667.https://doi.org/10.1016/j.csda.2008.08.001
-
[52]
Hartman, P. (1959). On functions representable as a difference of convex functions,Pacific Journal of Mathematics9(3): 707–713.https://doi.org/10.2140/pjm.1959.9.707
-
[53]
and Friedman, J
Hastie, T., Tibshirani, R. and Friedman, J. H. (2009).The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd edn, Springer, New York.https://doi.org/10. 1007/b94608
2009
-
[54]
Hawkins, D. M. (1980).Identification of Outliers, Monographs on Statistics and Applied Probability, 1st edn, Springer, Dordrecht.https://doi.org/10.1007/978-94-015-3994-4
-
[55]
Hawkins, D. M. (1994). The feasible solution algorithm for least trimmed squares regres- sion,Computational Statistics & Data Analysis17(2): 185–196.https://doi.org/10.1016/ 0167-9473(92)00070-8
1994
-
[56]
Hawkins, D. M., Bradu, D. and Kass, G. V. (1984). Location of Several Outliers in Multiple- Regression Data Using Elemental Sets,Technometrics26(3): 197–208.https://doi.org/10. 1080/00401706.1984.10487956
-
[57]
Hawkins, D. M. and Olive, D. J. (1999). Improved feasible solution algorithms for high break- down estimation,Computational Statistics & Data Analysis30(1): 1–11.https://doi.org/ 10.1016/S0167-9473(98)00082-6
-
[58]
Hawkins, D. M. and Olive, D. J. (2002). Inconsistency of Resampling Algorithms for High- Breakdown Regression Estimators and a New Algorithm,Journal of the American Statistical Association97(457): 136–159.https://doi.org/10.1198/016214502753479293
-
[59]
and Lange, K
Heng, Q. and Lange, K. (2025). Bootstrap estimation of the proportion of outliers in robust regression,Statistics and Computing35(3): 1–14.https://doi.org/10.1007/ s11222-024-10526-1
2025
-
[60]
Ho, V. T., Le Thi, H. A. and Pham Dinh, T. (2020). DCA with Successive DC Decomposition for Convex Piecewise-Linear Fitting,inH. A. Le Thi, H. M. Le, T. Pham Dinh and N. T. Nguyen (eds),Advanced Computational Methods for Knowledge Engineering, Springer Inter- national Publishing, Cham, pp. 39–51.https://doi.org/10.1007/978-3-030-38364-0_4
-
[61]
Ho, V. T., Le Thi, H. A. and Pham Dinh, T. (2021). DCA-based algorithms for DC fitting, Journal of Computational and Applied Mathematics389:113353.https://doi.org/10.1016/ j.cam.2020.113353
-
[62]
Hoaglin, D. C. and Welsch, R. E. (1978). The Hat Matrix in Regression and ANOVA,The American Statistician32(1): 17–22.https://doi.org/10.1080/00031305.1978.10479237
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.1978.10479237 1978
-
[63]
Hocking, R. R. (2003).Methods and Applications of Linear Models: Regression and the Anal- ysis of Variance, 2nd edn, John Wiley & Sons, Hoboken (New Jersey).https://doi.org/10. 1002/0471434159
2003
-
[64]
Hofmann, M., Gatu, C. and Kontoghiorghes, E. J. (2010). An Exact Least Trimmed Squares Algorithm for a Range of Coverage Values,Journal of Computational and Graphical Statistics 19(1): 191–204.https://doi.org/10.1198/jcgs.2009.07091
-
[65]
and Pardalos, P
Horst, R. and Pardalos, P. M. (1995).Handbook of Global Optimization: Volume 2, Nonconvex Optimization and Its Applications, 1st edn, Springer, New York.https://doi.org/10.1007/ 978-1-4757-5362-2
1995
-
[66]
Hössjer, O. (1995). Exact computation of the least trimmed squares estimate in simple linear regression,Computational Statistics & Data Analysis19(3): 265–282.https://doi.org/10. 1016/0167-9473(95)92697-V
1995
-
[67]
Huang, D., Cabral, R. and Torre, F. D. l. (2016). Robust regression,IEEE Transactions on Pattern Analysis and Machine Intelligence38(2): 363–375.https://doi.org/10.1109/ TPAMI.2015.2448091. 35 Thormann et al. Robust Regression with DC Programming
-
[68]
Huber, P. J. and Ronchetti, E. M. (2009).Robust Statistics, Wiley Series in Probabil- ity and Statistics, 2nd edn, John Wiley & Sons, Hoboken.https://doi.org/10.1002/ 9780470434697
2009
-
[69]
Ibe, O. C. (2013).Markov Processes for Stochastic Modeling, 2nd edn, Elsevier, London. https://doi.org/10.1016/C2012-0-06106-6
-
[70]
James, G., Witten, D., Hastie, T. and Tibshirani, R. (2021).An Introduction to Statistical Learning with Applications in R, Springer Texts in Statistics, 2nd edn, Springer, New York. https://doi.org/10.1007/978-1-0716-1418-1
-
[71]
Kan, B., Alpu, Ö. and Yazıcı, B. (2013). Robust ridge and robust Liu estimator for regression based on the LTS estimator,Journal of Applied Statistics40(3): 644–655.https://doi.org/ 10.1080/02664763.2012.750285
-
[72]
Lasserre, J. B. (2015).An Introduction to Polynomial and Semi-Algebraic Optimization, Cambridge Texts in Applied Mathematics, 1st edn, Cambridge University Press, Cambridge. https://doi.org/10.1017/CBO9781107447226
-
[73]
Le Thi, H. A. (2000). An efficient algorithm for globally minimizing a quadratic function under convex quadratic constraints,Mathematical Programming87: 401–426.https://doi. org/10.1007/s101070050003
-
[74]
Le Thi, H. A., Ho, V. T. and Pham Dinh, T. (2019). A unified DC programming framework and efficient DCA based approaches for large scale batch reinforcement learning,Journal of Global Optimization73: 279–310.https://doi.org/10.1007/s10898-018-0698-y
-
[75]
Le Thi, H. A. and Pham Dinh, T. (2005). The DC (Difference of Convex Functions) Program- ming and DCA Revisited with DC Models of Real World Nonconvex Optimization Problems, Annals of Operations Research133: 23–46.https://doi.org/10.1007/s10479-004-5022-1
-
[76]
Le Thi, H. A. and Pham Dinh, T. (2018). DC programming and DCA: thirty years of developments,Mathematical Programming169: 5–68.https://doi.org/10.1007/ s10107-018-1235-y
2018
-
[77]
Le Thi, H. A. and Pham Dinh, T. (2024). Open issues and recent advances in DC program- ming and DCA,Journal of Global Optimization88: 533–590.https://doi.org/10.1007/ s10898-023-01272-1
2024
-
[78]
Lewis, A. D. (2023).Geometric Analysis on Real Analytic Manifolds, Lecture Notes in Math- ematics, 1st edn, Springer, Cham.https://doi.org/10.1007/978-3-031-37913-0
-
[79]
Liu, T., Pong, T. K. and Takeda, A. (2019). A refined convergence analysis ofpDCAe with ap- plications to simultaneous sparse recovery and outlier detection,Computational Optimization and Applications73: 69–100.https://doi.org/10.1007/s10589-019-00067-z
-
[80]
(1965).Ensembles Semi-Analytiques, Institute des Hautes Etudes Scientifiques, Bures-sur-Yvette (Seine-et-Oise), France
Łojasiewicz, S. (1965).Ensembles Semi-Analytiques, Institute des Hautes Etudes Scientifiques, Bures-sur-Yvette (Seine-et-Oise), France
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.