Preventing Error Propagation in Multi-Agent AI through Runtime Monitoring
Pith reviewed 2026-06-30 09:19 UTC · model grok-4.3
The pith
Multi-agent AI systems with reasoning exchange can correct mistakes but also propagate errors depending on the situation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
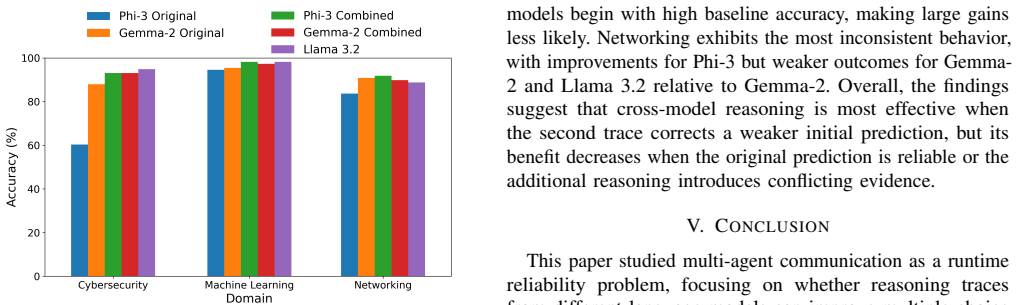
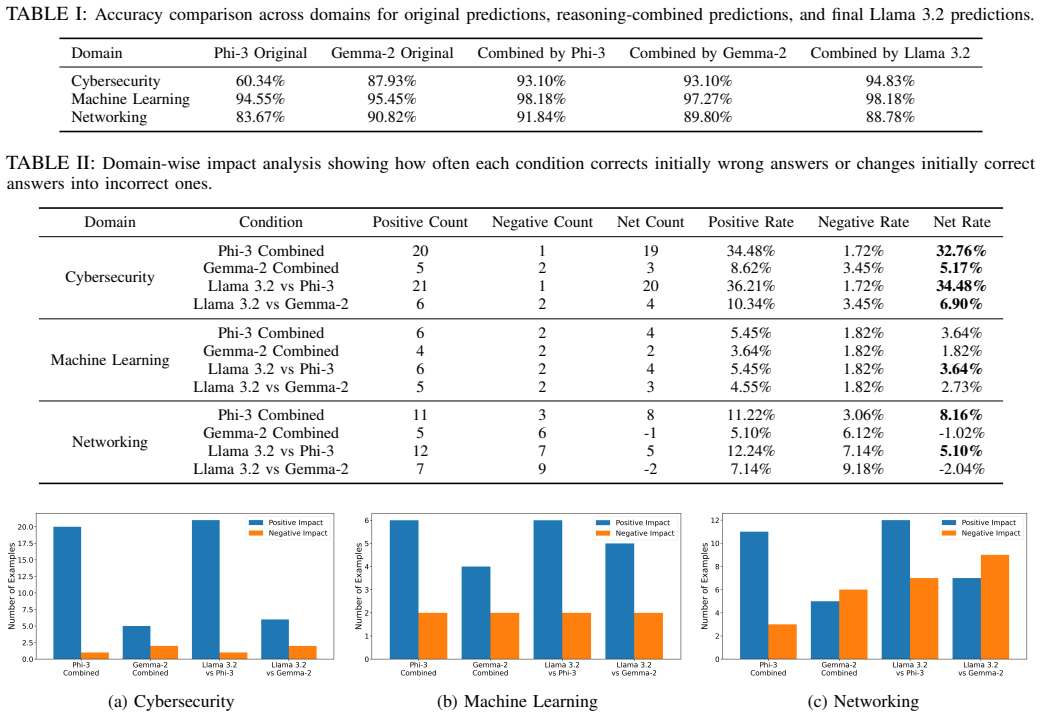
In the developed framework, agents answer questions independently before exchanging reasoning traces and revising decisions. Experiments assess whether accuracy rises, if positive revisions outnumber negative ones, and if results hold across selected domains, thereby identifying conditions for improved reliability and potential error propagation in multi-agent reasoning.
What carries the argument
The runtime monitoring framework involving independent initial answers, sharing of reasoning traces, and subsequent answer revision.
If this is right
- Accuracy can improve through multi-agent reasoning in specific domains.
- More positive answer transitions than negative ones indicate reliable communication.
- Effectiveness remains consistent or varies across domains such as cybersecurity, networking, and general knowledge.
- Runtime monitoring helps detect when error propagation is likely.
Where Pith is reading between the lines
- Similar monitoring techniques could be applied to tasks beyond multiple-choice questions.
- Systems might incorporate thresholds to prevent revisions from low-confidence agents.
- Findings suggest the need for domain-specific testing before deploying multi-agent AI.
Load-bearing premise
That experiments on multiple-choice questions in selected domains capture the dynamics of error propagation in deployed multi-agent AI systems.
What would settle it
Observing error propagation behaviors in a real-world multi-agent AI deployment that contradict the patterns found in the multiple-choice experiments would challenge the central claim.
Figures


read the original abstract
Multi-agent AI systems can improve answer selection by allowing different language models to exchange reasoning traces, revise initial predictions, and support a final decision. However, such communication may also introduce reliability risks: reasoning from one agent can correct another agent's mistake, but it can also mislead an agent that was initially correct. This paper studies reliable multi-agent AI communication through reasoning exchange and runtime answer revision. We develop a framework in which agents first answer multiple-choice questions independently, then share reasoning traces and revise their decisions. We conduct numerical experiments where we evaluate whether this process improves accuracy, produces more positive than negative answer transitions, and remains effective across domains such as cybersecurity, networking, and general knowledge. The results help identify when multi-agent reasoning improves reliability and when it may propagate errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for multi-agent AI in which independent language-model agents first answer multiple-choice questions, then exchange reasoning traces and revise their answers at runtime. Numerical experiments are described that evaluate accuracy changes, the balance of positive versus negative answer transitions, and consistency across domains including cybersecurity, networking, and general knowledge; the central claim is that these experiments identify conditions under which multi-agent reasoning exchange improves reliability versus propagating errors.
Significance. If the reported experiments were to supply quantitative evidence that the monitoring framework reliably distinguishes beneficial from harmful reasoning exchanges on MCQ tasks, the work could inform practical safeguards for multi-agent deployments. The absence of any methods, data, metrics, or controls in the manuscript, however, prevents any assessment of whether that identification result holds even on the narrow MCQ setting.
major comments (2)
- Abstract: the manuscript states that numerical experiments were conducted to evaluate accuracy, positive/negative transitions, and domain consistency, yet supplies no methods, datasets, sample sizes, accuracy figures, transition counts, statistical controls, or baseline comparisons. Without these elements the central claim that the results identify when multi-agent reasoning improves reliability cannot be evaluated.
- Abstract (and implied experimental design): the evaluation is restricted to fixed-option multiple-choice questions with short reasoning traces. The manuscript provides no argument or additional experiments showing that the observed transition statistics generalize to open-ended, long-horizon, or deployed multi-agent settings; this assumption is load-bearing for the title and abstract claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made to improve clarity and evaluability of the work.
read point-by-point responses
-
Referee: Abstract: the manuscript states that numerical experiments were conducted to evaluate accuracy, positive/negative transitions, and domain consistency, yet supplies no methods, datasets, sample sizes, accuracy figures, transition counts, statistical controls, or baseline comparisons. Without these elements the central claim that the results identify when multi-agent reasoning improves reliability cannot be evaluated.
Authors: We agree that the abstract does not contain sufficient experimental details for independent evaluation. While the full manuscript describes the setup (independent MCQ answering, reasoning exchange, and revision) along with domain-specific datasets, the abstract omits quantitative elements. We will revise the abstract to concisely report the methods, datasets (cybersecurity, networking, and general-knowledge MCQs), sample sizes, observed accuracy changes, positive/negative transition counts, and any controls or baselines used. This will directly address the evaluability concern. revision: yes
-
Referee: Abstract (and implied experimental design): the evaluation is restricted to fixed-option multiple-choice questions with short reasoning traces. The manuscript provides no argument or additional experiments showing that the observed transition statistics generalize to open-ended, long-horizon, or deployed multi-agent settings; this assumption is load-bearing for the title and abstract claim.
Authors: The current experiments deliberately use fixed-option MCQs with short traces to enable precise measurement of answer transitions and error propagation in a controlled setting. The title and abstract refer to the runtime monitoring framework applied to multi-agent reasoning exchange; MCQ tasks are presented as an initial, quantifiable testbed rather than a comprehensive demonstration of all possible deployments. We acknowledge the lack of generalization evidence or explicit scope discussion. We will add a Limitations section that states the current scope, explains the rationale for the MCQ design, and outlines planned extensions to open-ended and long-horizon tasks. The abstract will be updated to clarify that the reported conditions apply to the MCQ setting studied. revision: partial
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper presents a framework for multi-agent reasoning exchange followed by numerical experiments evaluating accuracy, answer transitions, and domain consistency on multiple-choice questions. No equations, derivations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claims rest on direct experimental outcomes rather than any load-bearing mathematical reduction or imported uniqueness theorem, making the work self-contained against its reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural information processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[3]
CAMEL: Communicative agents for “mind
G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “CAMEL: Communicative agents for “mind”’ exploration of large language model society,”Advances in neural information processing systems, vol. 36, pp. 51 991–52 008, 2023
2023
-
[4]
AutoGen: Enabling next-gen LLM applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “AutoGen: Enabling next-gen LLM applications via multi-agent conversations,” inFirst conference on language modeling, 2024
2024
-
[5]
Chatdev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Conget al., “Chatdev: Communicative agents for software development,” inProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), 2024, pp. 15 174–15 186
2024
-
[6]
Agentbench: Evaluating llms as agents,
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yanget al., “Agentbench: Evaluating llms as agents,” in International Conference on Learning Representations, vol. 2024, 2024, pp. 52 989–53 046
2024
-
[7]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22
2023
-
[8]
Selfcheckgpt: Zero-resource black- box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero-resource black- box hallucination detection for generative large language models,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 9004–9017. TABLE I:Accuracy comparison across domains for original predictions, reasoning-combined predictions, and ...
2023
-
[9]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), 2022, pp. 3214–3252
2022
-
[10]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[11]
R-judge: Benchmarking safety risk awareness for llm agents,
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhanget al., “R-judge: Benchmarking safety risk awareness for llm agents,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 1467–1490
2024
-
[12]
Agent-as-a-judge: Evaluate agents with agents,
M. Zhuge, C. Zhao, D. R. Ashley, W. Wang, D. Khizbullin, Y . Xiong, Z. Liu, E. Chang, R. Krishnamoorthi, Y . Tianet al., “Agent-as-a-judge: Evaluate agents with agents,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 80 569–80 611
2025
-
[13]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
2023
-
[14]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,”arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Improving factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate,” inForty-first international conference on machine learning, 2024
2024
-
[17]
RARR: Researching and revising what language models say, using language models,
L. Gao, Z. Dai, P. Pasupat, A. Chen, A. T. Chaganty, Y . Fan, V . Zhao, N. Lao, H. Lee, D.-C. Juanet al., “RARR: Researching and revising what language models say, using language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 16 477–16 508
2023
-
[18]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iter- ative refinement with self-feedback,”Advances in neural information processing systems, vol. 36, pp. 46 534–46 594, 2023
2023
-
[19]
Open quiz commons: Open quiz data bank,
P. Yeri, “Open quiz commons: Open quiz data bank,” https://github.com/ prahladyeri/open-quiz-commons, 2024, accessed: 2026-05-28
2024
-
[20]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, S. A. Jacobs, A. A. Awanet al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Llama 3.2 model card,
Meta AI, “Llama 3.2 model card,” https://github.com/meta-llama/ llama-models/blob/main/models/llama3_2/MODEL_CARD.md, 2024, accessed: 2026-05-29
2024
-
[23]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, S. Yau, Z. Lin, L. Zhouet al., “MetaGPT: Meta programming for a multi-agent collaborative framework,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 23 247–23 275
2024
-
[24]
A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration
Z. Liu, Y . Zhang, P. Li, Y . Liu, and D. Yang, “Dynamic LLM- agent network: An llm-agent collaboration framework with agent team optimization,”arXiv preprint arXiv:2310.02170, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Domain adaptive inference for neural machine translation,
D. Saunders, F. Stahlberg, A. de Gispert, and B. Byrne, “Domain adaptive inference for neural machine translation,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 222–228
2019
-
[26]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors,
W. Chen, Y . Su, J. Zuo, C. Yang, C. Yuan, C.-M. Chan, H. Yu, Y . Lu, Y .-H. Hung, C. Qianet al., “Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 20 094–20 136
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.