Memory as an Attack Surface in LLM Agents: A Study on Multiple-Choice Question Answering
Pith reviewed 2026-06-30 09:16 UTC · model grok-4.3
The pith
Inserting misleading memories into an LLM agent causes it to select incorrect options on clean multiple-choice questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An LLM-based agent equipped with an external memory component that stores task-relevant information will change its answers to multiple-choice questions when misleading or corrupted memories are inserted beforehand, even though the questions themselves remain clean and well-formed; the agent selects the manipulated options at higher rates after the insertion.
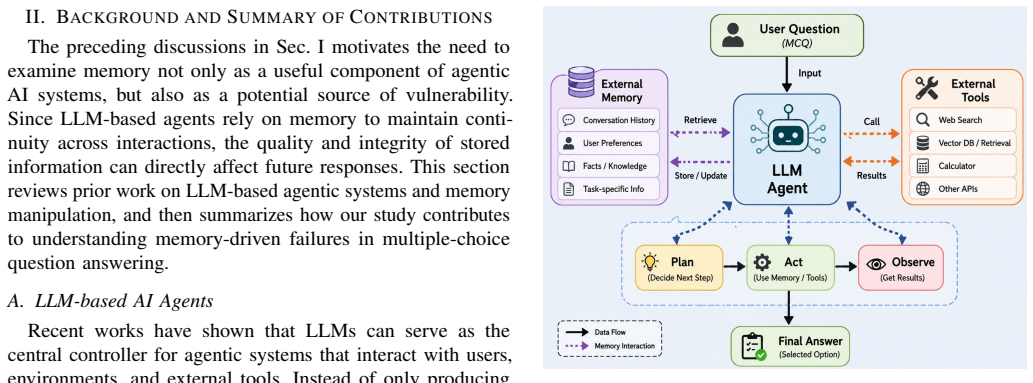
What carries the argument
The external memory component that stores and retrieves task-relevant information for the agent during question answering.
If this is right
- Accuracy on multiple-choice questions drops after memory insertion even though questions are unaltered.
- The agent selects the manipulated option more frequently than before the insertion.
- Simple memory manipulations suffice to produce measurable changes in final answers.
- Attack success rate can be quantified by comparing pre- and post-manipulation selections.
Where Pith is reading between the lines
- Agents that rely on memory for personalization or continuity may require explicit checks on stored content before use.
- The same memory surface could affect other agent tasks beyond multiple-choice answering if retrieval is not isolated.
- Design choices that separate memory writes from query processing might limit the reach of such insertions.
Load-bearing premise
The observed change in the agent's answers is caused by the inserted memory being retrieved and used rather than by unrelated factors in the setup.
What would settle it
Run the same agent on the same clean questions with identical prompts but disable memory retrieval entirely, then confirm that accuracy remains unchanged when the misleading entries are still present in storage.
Figures

read the original abstract
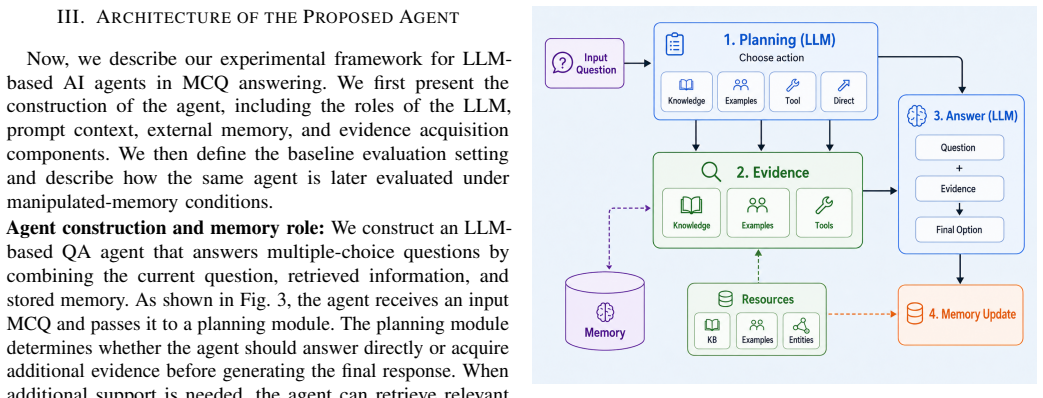
AI agents extend conventional large language model (LLM) applications by integrating language understanding with task execution, external tool use, and memory mechanisms. While memory allows agents to retain prior interactions and provide more personalized and context-aware responses, it also introduces a new vulnerability: information stored in memory can influence future outputs even when the current query is clean. In this paper, we investigate memory manipulation in LLM-based agents for multiple-choice question answering. We first design and implement an LLM-based AI agent with an external memory component that stores and retrieves task-relevant information. We then introduce basic memory manipulation scenarios in which misleading or corrupted memories are inserted into the agent before it answers multiple-choice questions. Using a controlled experimental setup, we compare the agent's performance before and after memory manipulation and measure changes in answer accuracy, attack success rate, and selection of manipulated options. Our results show that even simple memory manipulations can noticeably affect the agent's final answers, causing it to select incorrect options despite receiving clean and well-formed questions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based agents with external memory are vulnerable to manipulation attacks during multiple-choice question answering. By designing an agent that stores and retrieves task-relevant information and then inserting misleading or corrupted memories before clean queries, the authors report measurable drops in answer accuracy, increased attack success rates, and higher selection of manipulated options.
Significance. If the central empirical claim survives proper controls, the work would usefully identify memory as a distinct attack surface in agent architectures, complementing existing prompt-injection literature and motivating defensive research on memory isolation or verification.
major comments (2)
- [Section 3] Section 3: the experimental design inserts corrupted memories but reports no ablation arm in which identical misleading content is supplied directly inside the question prompt (bypassing the memory store/retrieve step). Without this control, any accuracy drop is indistinguishable from ordinary context sensitivity rather than a memory-specific effect.
- [Experimental results] Experimental results (and abstract): no quantitative accuracy figures, error bars, dataset sizes, or per-condition statistics are supplied, so it is impossible to judge the magnitude or reliability of the claimed effect on answer selection.
minor comments (1)
- The abstract refers to 'attack success rate' without defining the metric or the criteria used to label a trial as successful.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Section 3] Section 3: the experimental design inserts corrupted memories but reports no ablation arm in which identical misleading content is supplied directly inside the question prompt (bypassing the memory store/retrieve step). Without this control, any accuracy drop is indistinguishable from ordinary context sensitivity rather than a memory-specific effect.
Authors: We agree that an ablation supplying the same misleading content directly in the prompt (bypassing memory) is necessary to isolate a memory-specific effect from general context sensitivity. This control was not included in the original design. We will add the ablation arm to Section 3, reporting the comparative results to demonstrate that the observed accuracy drops are attributable to the memory mechanism. revision: yes
-
Referee: [Experimental results] Experimental results (and abstract): no quantitative accuracy figures, error bars, dataset sizes, or per-condition statistics are supplied, so it is impossible to judge the magnitude or reliability of the claimed effect on answer selection.
Authors: The current manuscript presents results in qualitative terms only. We acknowledge that quantitative details (accuracy figures, error bars, dataset sizes, and per-condition statistics) are required to assess effect magnitude and reliability. We will expand the experimental results section and abstract with these metrics, including tables or figures as appropriate. revision: yes
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper is an empirical investigation that designs an LLM agent with external memory, inserts manipulated memories, and measures accuracy changes on multiple-choice questions via controlled experiments. It contains no equations, derivations, fitted parameters, model-based predictions, or self-citation chains that reduce any claim to its own inputs by construction. All load-bearing steps are direct experimental observations rather than self-definitional or fitted-input logic, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agentic AI: Autonomous intelligence for complex goals—a comprehensive survey,
D. B. Acharya, K. Kuppan, and B. Divya, “Agentic AI: Autonomous intelligence for complex goals—a comprehensive survey,”IEEE Access, vol. 13, pp. 18 912–18 936, 2025
2025
-
[2]
The role of agentic AI in shaping a smart future: A systematic review,
S. Hosseini and H. Seilani, “The role of agentic AI in shaping a smart future: A systematic review,”Array, vol. 26, p. 100399, 2025
2025
-
[3]
AI agents vs. agentic AI: A conceptual taxonomy, applications and challenges,
R. Sapkota, K. I. Roumeliotis, and M. Karkee, “AI agents vs. agentic AI: A conceptual taxonomy, applications and challenges,”Information Fusion, p. 103599, 2025
2025
-
[4]
S. Raza, R. Sapkota, M. Karkee, and C. Emmanouilidis, “Trism for agentic AI: A review of trust, risk, and security management in LLM- based agentic multi-agent systems,”Preprint arXiv:2506.04133, 2025
-
[5]
Unveiling privacy risks in LLM agent memory,
B. Wang, W. He, S. Zeng, Z. Xiang, Y . Xing, J. Tang, and P. He, “Unveiling privacy risks in LLM agent memory,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 25 241–25 260
2025
-
[6]
Agentic AI in education: State of the art and future directions,
G. Kostopoulos, V . Gkamas, M. Rigou, and S. Kotsiantis, “Agentic AI in education: State of the art and future directions,”IEEE Access, 2025
2025
-
[7]
Redefining elderly care with agentic AI: challenges and opportunities,
R. A. Khalil, K. Ahmad, and H. Ali, “Redefining elderly care with agentic AI: challenges and opportunities,”IEEE Open Journal of the Computer Society, 2026
2026
-
[8]
AI & collective memory,
A. Hoskins, “AI & collective memory,”Current Opinion in Psychology, p. 102156, 2025
2025
-
[9]
Memory in the Age of AI Agents
Y . Hu, S. Liu, Y . Yue, G. Zhang, B. Liu, F. Zhu, J. Linet al., “Memory in the age of AI agents,”arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Agentic AI quiz-based learning system: Enhancing MCQ generation via long-context cached retrieval-augmented generation,
D. Sreekanth, S. Gopi, and N. Dehbozorgi, “Agentic AI quiz-based learning system: Enhancing MCQ generation via long-context cached retrieval-augmented generation,” inIEEE Frontiers in Education Confer- ence (FIE), 2025, pp. 1–8
2025
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
HuggingGPT: Solving AI tasks with ChatGPT and its friends in hugging face,
Y . Shen, K. Song, X. Tanet al., “HuggingGPT: Solving AI tasks with ChatGPT and its friends in hugging face,”Advances in Neural Information Processing Systems, vol. 36, pp. 38 154–38 180, 2023
2023
-
[13]
ToolLLM: Facilitating large language models to master 16000+ real-world apis,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “ToolLLM: Facilitating large language models to master 16000+ real-world apis,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 9695–9717
2024
-
[14]
WebShop: Towards scalable real-world web interaction with grounded language agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “WebShop: Towards scalable real-world web interaction with grounded language agents,” Advances in Neural Information Processing Systems, vol. 35, pp. 20 744– 20 757, 2022
2022
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22
2023
-
[17]
AgentPoison: Red- teaming LLM agents via poisoning memory or knowledge bases,
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “AgentPoison: Red- teaming LLM agents via poisoning memory or knowledge bases,” Advances in Neural Information Processing Systems, vol. 37, pp. 130 185– 130 213, 2024
2024
-
[18]
Memory injection attacks on LLM agents via query-only interaction,
S. Dong, S. Xu, P. Heet al., “Memory injection attacks on LLM agents via query-only interaction,”Advances in Neural Information Processing Systems, vol. 38, pp. 46 697–46 731, 2026
2026
-
[19]
Open quiz commons: Open quiz data bank,
P. Yeri, “Open quiz commons: Open quiz data bank,” https://github.com/ prahladyeri/open-quiz-commons, 2024, accessed: 2026-05-28
2024
-
[20]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” in International Conference on Learning Representations, 2021
2021
-
[21]
Mmlu dataset,
Center for AI Safety, “Mmlu dataset,” https://huggingface.co/datasets/ cais/mmlu, 2023, accessed: 2026-05-28
2023
-
[22]
Computer network mcqs,
PrepBharat, “Computer network mcqs,” https://www.prepbharat.com/ Engineering/cse/ComputerNetwork/computer-network-questions.html, 2024, accessed: 2026-05-28
2024
-
[23]
Introducing gpt-5.4 mini and nano,
OpenAI, “Introducing gpt-5.4 mini and nano,” https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/, 2026, accessed: 2026-05-28
2026
-
[24]
Gpt-4o mini: Advancing cost-efficient intelligence,
——, “Gpt-4o mini: Advancing cost-efficient intelligence,” https://openai. com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/, 2024, ac- cessed: 2026-05-28
2024
-
[25]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, S. A. Jacobs, A. A. Awanet al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.