Knowing in Advance When an Evolutionary Outer Loop Will Not Help: A Pre-Registered Cheap-Baseline Screening Rule
Pith reviewed 2026-06-30 08:04 UTC · model grok-4.3
The pith
A pre-registered ratio of single-shot gain to best cheap baseline decides in advance when evolutionary outer loops add nothing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
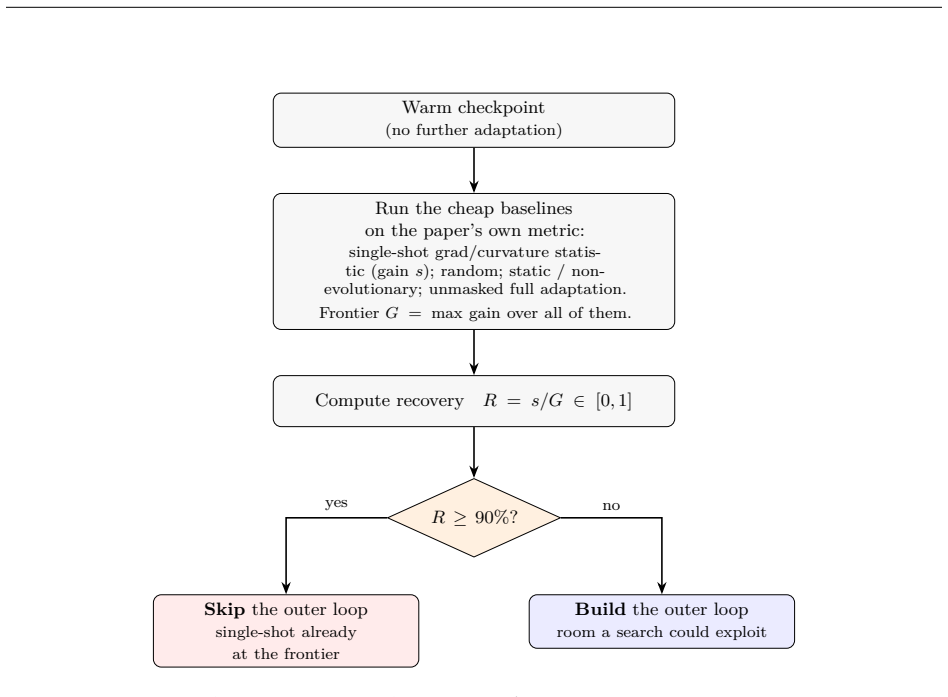
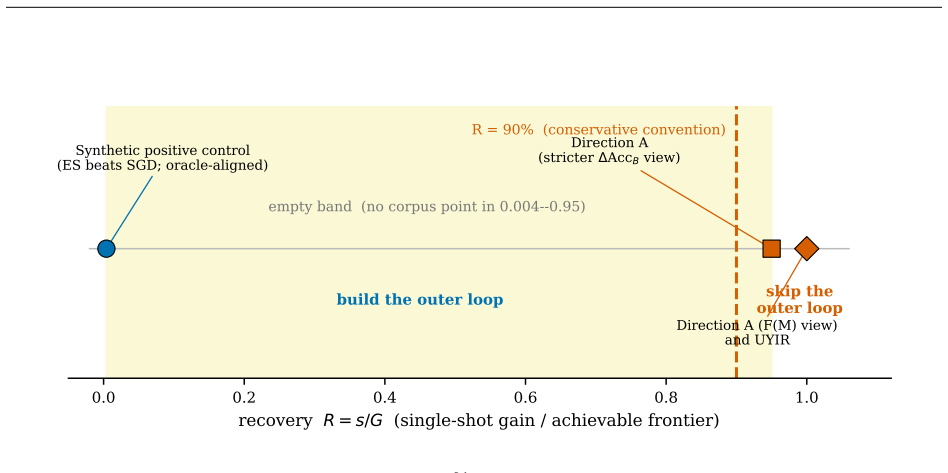
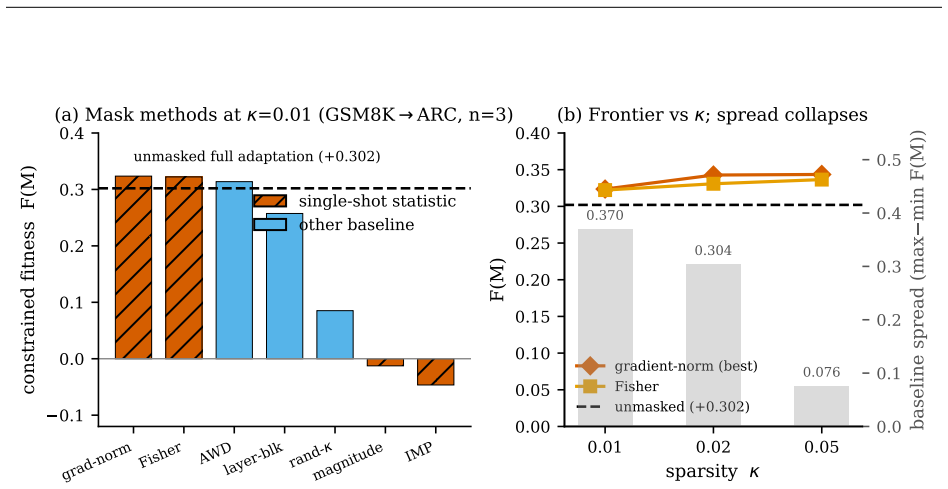
The central claim is that the recovery ratio R = s/G, with s the best single-shot gradient/curvature statistic gain and G the best gain of any cheap method, correctly identifies cases where an evolutionary outer loop provides no detectable additional gain beyond cheap single-shot methods. This is shown in pre-registered cases where R approximately 1.0 caused the gate to fire and the outer loop to be abandoned, including one case where a companion factorial decomposition localizes the apparent win to a static substrate change with the evolutionary lifecycle contributing no detectable gain on the project's metric.
What carries the argument
The recovery ratio R = s/G computed at a Phase-0 gate from the best single-shot gradient or curvature statistic gain divided by the best gain of any cheap method evaluated, which triggers skipping the outer loop when R is at least 90 percent.
If this is right
- When R is approximately 1.0 the outer loop can be abandoned without detectable loss on the target metric.
- A factorial decomposition can localize apparent wins to static substrate changes rather than the evolutionary process.
- The screening gate costs 50-70 GPU hours but avoids an estimated 400-plus GPU hours plus weeks of implementation for the first cell alone.
- The rule yields a 6-8x saving in one documented project and is prospectively falsifiable by specified counterexamples.
Where Pith is reading between the lines
- The same Phase-0 ratio approach could be applied to other expensive outer-loop methods such as hyperparameter search or architecture search to decide when they are unnecessary.
- Routine use of the rule would encourage earlier documentation of strong single-shot baselines before committing resources to population-based methods.
- The pre-registration requirement makes the screening decisions themselves testable on new tasks without retrospective bias.
Load-bearing premise
The set of cheap methods evaluated at the Phase-0 gate includes the best possible single-shot or static baseline for the project's metric.
What would settle it
A task with R less than 90 percent where the outer loop still fails to beat single-shot methods would refute the rule.
Figures
read the original abstract
We introduce a pre-registered screening rule that decides, before any implementation, whether an evolutionary / population / lifecycle outer loop over neural-network parameters or structure is worth building. Such outer loops cost 10^2-10^3x their gradient inner loop, yet whether they beat a cheap single-shot alternative is usually discovered only after the expense is paid. Our rule computes, at a Phase-0 gate, a single number: the recovery R = s/G, the best single-shot gradient/curvature statistic's gain s divided by the best gain G of any cheap method evaluated, and prescribes skipping the outer loop when R >= 90%. We validate the rule on a within-lab series of pre-registered outer-loop bets (two analyzed cases plus a disclosed file drawer): in both analyzed cases a static or single-shot computation captured the effect on the project's own metric, the gate fired (R approximately 1.0 in both cases; approximately 0.95 under a stricter metric on one), and the outer loop was abandoned, including one case where a companion factorial decomposition localizes the apparent win to a static substrate change with the evolutionary lifecycle contributing no detectable gain. On one project the gate cost about 50-70 GPU-hours and screened out an estimated 400+ GPU-hours (first cell only) plus weeks of implementation, a 6-8x saving. The rule is prospectively falsifiable: a task with R < 90% where the outer loop still fails to beat single-shot would refute it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a pre-registered screening rule for deciding whether to implement an evolutionary outer loop over neural network parameters or structure. The rule computes R = s/G at a Phase-0 gate, where s is the gain from the best single-shot gradient/curvature method and G is the best gain from evaluated cheap methods, and recommends skipping the outer loop if R >= 90%. Validation is provided on two pre-registered cases (plus a file drawer) where R was approximately 1.0, the rule fired, and the outer loop was abandoned, with reported savings of 6-8x compute.
Significance. If the rule proves reliable, it offers a practical way to avoid substantial computational costs associated with evolutionary outer loops that do not provide gains beyond single-shot methods. The use of pre-registration and disclosure of the file drawer are positive features that enhance the credibility of the reported cases. The prospective falsifiability of the rule is also a strength.
major comments (2)
- [Abstract] The soundness of the central claim rests on only two analyzed pre-registered cases; the manuscript does not provide independent replication, error bars on the R values, or details on how G was computed across methods, which leaves the support for the 90% threshold only partially established.
- [Abstract] The rule assumes that the set of cheap methods evaluated at the Phase-0 gate includes the best possible single-shot or static baseline (so that s accurately reflects the maximum single-shot gain); however, no argument is given that this will hold when the best baseline is not known in advance, which is load-bearing because omission of a stronger baseline would underestimate s and cause the rule to fail to skip when it should.
minor comments (1)
- [Abstract] The abstract mentions 'approximately 0.95 under a stricter metric on one' but does not specify what the stricter metric is or how it affects the threshold.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our pre-registered screening rule. We address each major comment below with clarifications and planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] The soundness of the central claim rests on only two analyzed pre-registered cases; the manuscript does not provide independent replication, error bars on the R values, or details on how G was computed across methods, which leaves the support for the 90% threshold only partially established.
Authors: We acknowledge that validation rests on two pre-registered within-lab cases (plus disclosed file drawer), which is a genuine limitation for a newly introduced rule. The manuscript already stresses prospective falsifiability rather than claiming broad proof. We will revise the abstract and discussion sections to more explicitly note the small sample size, absence of independent replication, and lack of error bars at this stage. On computation of G, the pre-registration protocol defines the evaluated cheap methods; we will add a short supplementary note with the exact procedure used to select the best G in each case. The 90% threshold remains a conservative heuristic derived from the observed R values near 1.0. These changes will be made in revision. revision: partial
-
Referee: [Abstract] The rule assumes that the set of cheap methods evaluated at the Phase-0 gate includes the best possible single-shot or static baseline (so that s accurately reflects the maximum single-shot gain); however, no argument is given that this will hold when the best baseline is not known in advance, which is load-bearing because omission of a stronger baseline would underestimate s and cause the rule to fail to skip when it should.
Authors: This point is correct and load-bearing. The rule is applied using whatever set of cheap single-shot and static methods the practitioner has evaluated at Phase-0; if a stronger baseline is omitted, computed s is indeed underestimated, which can cause the gate to fail to fire when it should. We will revise the manuscript to add an explicit discussion of this assumption, including practical guidance on selecting a broad initial set of common baselines (e.g., standard optimizers and curvature approximations) and noting the conservative failure mode: the rule may err toward running the outer loop rather than incorrectly skipping. This addresses the concern without altering the core rule. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a pre-registered empirical screening rule based on the ratio R = s/G with a fixed 90% threshold, validated prospectively on pre-registered cases where the rule was applied before outcomes were known and where a factorial decomposition provided independent localization of gains. The central claim is presented as falsifiable by future cases with R < 90% where an outer loop still fails to improve on single-shot baselines. No derivation step reduces the rule or its predictions to the input gains by construction, no parameters are fitted and relabeled as predictions, and no load-bearing premise depends on self-citation chains or imported uniqueness results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 90% threshold for R
axioms (1)
- domain assumption The cheap methods evaluated at Phase-0 represent the best attainable single-shot or static baseline for the target metric.
Reference graph
Works this paper leans on
-
[1]
Evolutionary strategies lead to catastrophic forgetting in LLMs.arXiv preprint arXiv:2601.20861,
Immanuel Abdi, Akshat Gupta, Micah Mok, Alexander Lu, et al. Evolutionary strategies lead to catastrophic forgetting in LLMs.arXiv preprint arXiv:2601.20861,
-
[2]
Mohamadjavad Bahmani, Radwa El Shawi, Nshan Potikyan, and Sherif Sakr. To tune or not to tune? an approach for recommending important hyperparameters.arXiv preprint arXiv:2108.13066,
-
[3]
Amanda Bertsch, Maor Ivgi, Emily Xiao, Uri Alon, Jonathan Berant, Matthew R. Gormley, and Gra- ham Neubig. In-context learning with long-context models: An in-depth exploration.arXiv preprint arXiv:2405.00200,
-
[4]
William Hoy, Binxu Wang, and Xu Pan. Matching accuracy, different geometry: Evolution strategies vs GRPO in LLM post-training.arXiv preprint arXiv:2604.01499,
-
[5]
Differentiable NAS framework and application to ads CTR prediction.arXiv preprint arXiv:2110.14812,
Ravi Krishna, Aravind Kalaiah, Bichen Wu, Maxim Naumov, et al. Differentiable NAS framework and application to ads CTR prediction.arXiv preprint arXiv:2110.14812,
-
[6]
Ramchand Kumaresan. Decomposing evolutionary mixture-of-LoRA architectures: The routing lever, the lifecycle penalty, and a substrate-conditional boundary.arXiv preprint arXiv:2605.11153,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
and Bernard, Samuel and Beslon, Guillaume and Bryson, David M
Joel Lehman, Jeff Clune, Dusan Misevic, Christoph Adami, Lee Altenberg, Julie Beaulieu, Peter J. Bentley, Samuel Bernard, Guillaume Beslon, David M. Bryson, Nick Cheney, et al. The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities.arXiv preprint arXiv:1803.03453,
-
[8]
Non-Differentiable Supervised Learning with Evolution Strategies and Hybrid Methods
Karel Lenc, Erich Elsen, Tom Schaul, and Karen Simonyan. Non-differentiable supervised learning with evolution strategies and hybrid methods.arXiv preprint arXiv:1906.03139,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[9]
Random search and reproducibility for neural architecture search.arXiv preprint arXiv:1902.07638,
Liam Li and Ameet Talwalkar. Random search and reproducibility for neural architecture search.arXiv preprint arXiv:1902.07638,
-
[10]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ilya Sutskever. Evolution strategies as a scalable alternative to reinforcement learning.arXiv preprint arXiv:1703.03864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Evolution strategies at the hyperscale
Bidipta Sarkar, Mattie Fellows, Juan Agustin Duque, Alistair Letcher, et al. Evolution strategies at the hyperscale.arXiv preprint arXiv:2511.16652,
-
[12]
Overcoming Forgetting in LLM Fine-Tuning with Evolution Strategies
Kajetan Schweighofer, Conor F. Hayes, Roberto Dailey, Risto Miikkulainen, and Xin Qiu. Overcoming forgetting in LLM fine-tuning with evolution strategies.arXiv preprint arXiv:2605.30148,
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
-
[14]
Felipe Petroski Such, Vashisht Madhavan, Edoardo Conti, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning.arXiv preprint arXiv:1712.06567,
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
Antoine Yang, Pedro M. Esperança, and Fabio M. Carlucci. NAS evaluation is frustratingly hard.arXiv preprint arXiv:1912.12522,
-
[17]
Compositional exemplars for in-context learning.arXiv preprint arXiv:2302.05698,
Jiacheng Ye, Zhiyong Wu, Jiangtao Feng, Tao Yu, and Lingpeng Kong. Compositional exemplars for in-context learning.arXiv preprint arXiv:2302.05698,
-
[18]
Evaluating the search phase of neural architecture search.arXiv preprint arXiv:1902.08142,
10 Kaicheng Yu, Christian Sciuto, Martin Jaggi, Claudiu Musat, and Mathieu Salzmann. Evaluating the search phase of neural architecture search.arXiv preprint arXiv:1902.08142,
-
[19]
Xingwen Zhang, Jeff Clune, and Kenneth O. Stanley. On the relationship between the OpenAI evolution strategy and stochastic gradient descent.arXiv preprint arXiv:1712.06564,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.