A Multi-Dataset Benchmark for Evaluating LLM Agents in Microservice Failure Diagnosis
Pith reviewed 2026-06-30 02:39 UTC · model grok-4.3
The pith
Two new datasets evaluate LLM agents on the reasoning process in microservice failure diagnosis across localization, identification, and evidence grounding rather than only the final answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the AIOps2025 and RCA100 datasets, under a reasoning-process evaluation paradigm, assess agentic diagnostic capability along three dimensions—Localization (where the fault occurs), Identification (what type of fault it is), and Reason (whether the reasoning trace is grounded in relevant evidence)—with labels produced by domain experts and validated through competitions involving over 6,000 teams.
What carries the argument
The reasoning-process evaluation paradigm that scores agents separately on Localization, Identification, and Reason using fine-grained causal evidence from the failure cases.
If this is right
- The datasets supply fine-grained causal evidence that can be used to train or fine-tune agents on systematic diagnosis.
- They cover a broad range of fault categories across two representative microservice systems, enabling evaluation under varied conditions.
- The competition-validated labels support reproducible assessment of agent performance in realistic operational environments.
- They shift development focus from outcome accuracy alone to the quality of the diagnostic reasoning trace.
Where Pith is reading between the lines
- If the three dimensions turn out to be only weakly correlated, agent architectures could be optimized for each one independently rather than for end-to-end accuracy.
- The competition-based validation method could be reused to create comparable benchmarks in adjacent domains such as network or cloud operations.
- The provision of explicit causal evidence alongside each case may encourage agent designs that retrieve and cite supporting data rather than rely on pattern matching alone.
Load-bearing premise
Expert labeling combined with validation through large-scale competitions produces reliable ground truth for the three evaluation dimensions.
What would settle it
An independent re-labeling exercise in which multiple domain experts assign substantially different values on the Reason dimension to the same set of cases, or in which the diagnoses produced by competition-winning teams systematically diverge from the provided ground truth.
Figures




read the original abstract
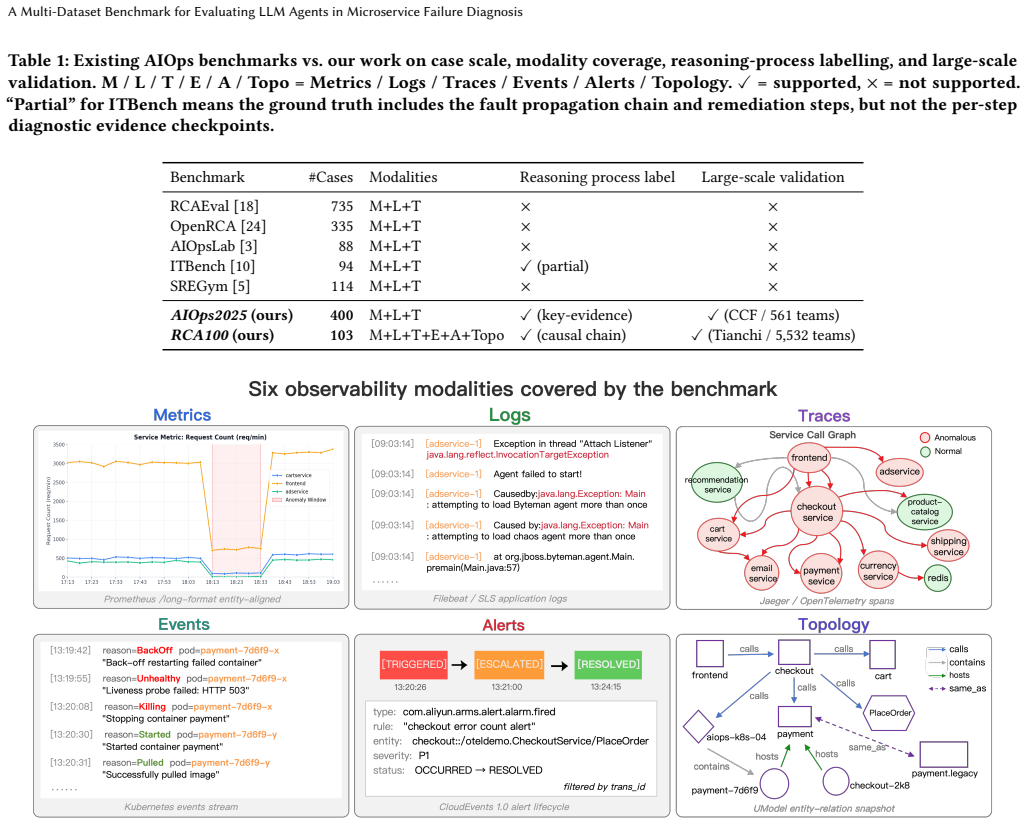
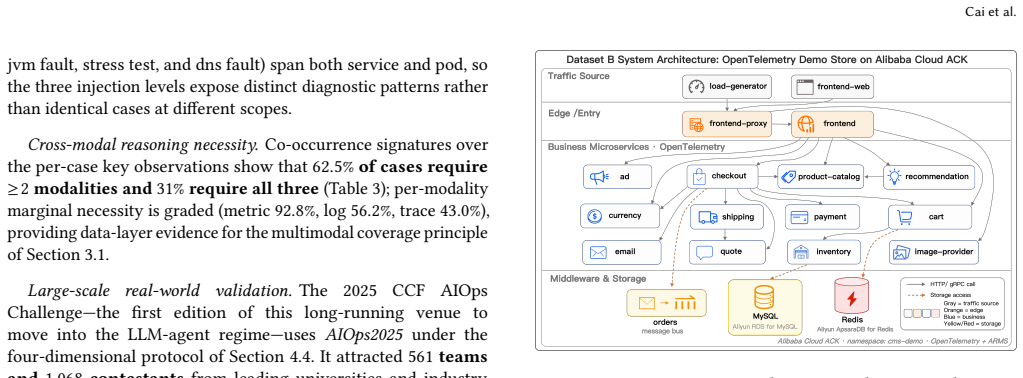
LLM-based agents are reshaping microservice operations into AgentOps, where benchmarks are key to evaluating failure diagnosis over multimodal observability data. However, existing benchmarks remain largely outcome-oriented: they score only the final answer and fail to assess the systematic reasoning process in failure diagnosis. We address this gap by introducing two large-scale datasets (AIOps2025 and RCA100) under a reasoning-process evaluation paradigm that assesses agentic diagnostic capability along three dimensions: Localization (where the fault occurs), Identification (what type of fault it is), and Reason (whether the reasoning trace is grounded in relevant evidence). Together, the two datasets comprise over 500 expert-labeled failure cases across two representative microservice systems (HipsterShop and the OpenTelemetry Demo Store). They cover diverse fault scenarios across resource, network, runtime, middleware/database, and application-logic categories and provide fine-grained causal evidence to support agent learning and reasoning-process evaluation. Beyond scale and coverage, the datasets have been carefully labelled by domain experts and validated through large-scale competitions, supporting more than 6,000 participating teams. This makes them not only expert-labeled diagnostic datasets, but also competition-validated benchmarks for evaluating agentic failure diagnosis in real-world microservice environments. Datasets are available at https://www.aiops.cn/gitlab/aiops-live-benchmark/agenticopseval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two large-scale datasets (AIOps2025 and RCA100) with over 500 expert-labeled failure cases from HipsterShop and OpenTelemetry Demo Store microservice systems. It proposes a reasoning-process evaluation paradigm for LLM agents in microservice failure diagnosis, assessing performance along three dimensions: Localization (fault location), Identification (fault type), and Reason (grounding of reasoning trace in evidence). The datasets cover diverse fault categories and are claimed to be validated via expert labeling and large-scale competitions with over 6,000 teams, addressing limitations of outcome-oriented benchmarks.
Significance. If the ground-truth labels prove reliable, particularly for the Reason dimension, these datasets would offer a meaningful advance by shifting evaluation from final answers to systematic reasoning processes in agentic diagnosis. The scale, coverage across fault types, and provision of causal evidence could support more effective training and benchmarking of LLM agents in real-world microservice environments (AgentOps).
major comments (2)
- [Abstract / Dataset construction] Abstract and dataset construction sections: The central claim that the datasets enable reliable reasoning-process evaluation rests on the assertion that labels were 'carefully labelled by domain experts and validated through large-scale competitions.' No quantitative validation details are reported (e.g., inter-expert agreement rates, per-dimension error rates, or how competitions distinguished scoring of reasoning traces from final diagnoses), leaving the reliability of the Reason dimension unsecured.
- [Abstract / Evaluation paradigm] Abstract and evaluation paradigm description: The three dimensions (Localization, Identification, Reason) are introduced without details on operationalization, such as annotation guidelines, examples of what constitutes 'grounded in relevant evidence,' or procedures for assigning Reason labels. This prevents assessment of whether the data supports the stated three-dimensional evaluation claims.
minor comments (1)
- [Abstract] The dataset availability link is provided, but the manuscript would benefit from explicit statements on data format, access restrictions, and any licensing details to facilitate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency on label validation and dimension operationalization. We address each point below and will revise the manuscript to incorporate additional details.
read point-by-point responses
-
Referee: [Abstract / Dataset construction] Abstract and dataset construction sections: The central claim that the datasets enable reliable reasoning-process evaluation rests on the assertion that labels were 'carefully labelled by domain experts and validated through large-scale competitions.' No quantitative validation details are reported (e.g., inter-expert agreement rates, per-dimension error rates, or how competitions distinguished scoring of reasoning traces from final diagnoses), leaving the reliability of the Reason dimension unsecured.
Authors: We agree that quantitative validation metrics are not reported in the current version. The expert labeling process and competition-based validation (with over 6,000 teams) were designed to assess reasoning traces separately from final diagnoses, but these specifics were omitted for brevity. In the revised manuscript we will add a dedicated subsection on dataset construction that reports inter-expert agreement rates, per-dimension consistency statistics, and the competition scoring protocol that isolated the Reason dimension. This directly addresses the concern about reliability of the Reason labels. revision: yes
-
Referee: [Abstract / Evaluation paradigm] Abstract and evaluation paradigm description: The three dimensions (Localization, Identification, Reason) are introduced without details on operationalization, such as annotation guidelines, examples of what constitutes 'grounded in relevant evidence,' or procedures for assigning Reason labels. This prevents assessment of whether the data supports the stated three-dimensional evaluation claims.
Authors: We acknowledge that the manuscript provides only high-level definitions of the three dimensions without explicit operationalization details. In the revision we will expand the evaluation paradigm section to include the annotation guidelines used by experts, concrete examples of what qualifies as 'grounded in relevant evidence' (e.g., explicit citation of logs or metrics versus unsupported inference), and the exact procedure for assigning Reason labels. These additions will allow readers to assess whether the data supports the three-dimensional claims. revision: yes
Circularity Check
No circularity: benchmark paper introduces datasets without derivations or self-referential reductions
full rationale
The paper presents two new datasets and a three-dimensional evaluation paradigm (Localization, Identification, Reason) for LLM agent failure diagnosis. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. Claims rest on external processes (expert labeling, competition validation with >6000 teams) rather than internal reductions or self-citations that would force results by construction. This matches the default expectation of no significant circularity for a dataset/benchmark contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert labels and competition outcomes provide reliable ground truth for localization, identification, and reasoning quality
Reference graph
Works this paper leans on
-
[1]
2016.Site reliability engineering: how Google runs production systems
Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. 2016.Site reliability engineering: how Google runs production systems. O’Reilly Media, Inc
2016
-
[2]
Chaos Mesh Authors. 2020. Chaos Mesh: A Powerful Chaos Engineering Platform on Kubernetes. https://chaos-mesh.org/
2020
-
[3]
Yinfang Chen, Manish Shetty, Gagan Somashekar, Minghua Ma, Yogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia Wang, and Saravan Rajmohan. 2025. Aiop- slab: A holistic framework to evaluate ai agents for enabling autonomous clouds. Proceedings of Machine Learning and Systems7 (2025)
2025
-
[4]
Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, et al. 2024. Automatic root cause analysis via large language models for cloud incidents. InProceedings of the Nineteenth European Conference on Computer Systems (EuroSys). 674–688
2024
-
[5]
Jackson Clark, Yiming Su, Saad Mohammad Rafid Pial, Yifang Tian, Lily Gniedziejko, Hans-Arno Jacobsen, Yinfang Chen, and Tianyin Xu. 2026. SREGym: A Live Benchmark for AI SRE Agents with High-Fidelity Failure Scenarios.arXiv preprint arXiv:2605.07161(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Google Cloud Platform. 2018. Online Boutique (HipsterShop): A Cloud-First Microservices Demo Application. https://github.com/GoogleCloudPlatform/ microservices-demo
2018
-
[7]
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, et al . 2020. TiDB: a Raft-based HTAP database.Proceedings of the VLDB Endowment13, 12 (2020), 3072–3084
2020
-
[8]
Azam Ikram, Sarthak Chakraborty, Subrata Mitra, Shiv Saini, Saurabh Bagchi, and Murat Kocaoglu. 2022. Root cause analysis of failures in microservices through causal discovery.Advances in Neural Information Processing Systems35 (2022), 31158–31170
2022
-
[9]
Jaeger Authors. 2017. Jaeger: Open Source, End-to-End Distributed Tracing. https://www.jaegertracing.io/
2017
-
[10]
Saurabh Jha, Rohan Arora, Yuji Watanabe, Takumi Yanagawa, Yinfang Chen, Jackson Clark, Bhavya Bhavya, Mudit Verma, Harshit Kumar, Hirokuni Kita- hara, et al . 2025. ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks.Proceedings of Machine Learning Research267 (2025), 27134–27197
2025
-
[11]
Jiajun Jiang, Weihai Lu, Junjie Chen, Qingwei Lin, Pu Zhao, Yu Kang, Hongyu Zhang, Yingfei Xiong, Feng Gao, Zhangwei Xu, et al . 2020. How to mitigate the incident? an effective troubleshooting guide recommendation technique for online service systems. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on...
2020
-
[12]
JinJin Lin, Pengfei Chen, and Zibin Zheng. 2018. Microscope: Pinpoint perfor- mance issues with causal graphs in micro-service environments. InInternational Conference on Service-Oriented Computing. Springer, 3–20
2018
- [13]
-
[14]
OpenTelemetry Authors. 2022. OpenTelemetry Demo: A Microservice-based Distributed Application. https://github.com/open-telemetry/opentelemetry- demo
2022
-
[15]
Changhua Pei, Zheyuan Li, Zexin Wang, Hang Cui, Xiaohui Nie, Qi Zhou, Fang Situ, Cheng Zhang, Xin Zhang, Xidao Wen, et al. 2026. UModel: An Agent-Ready Observability Data Modeling Method at Scale.arXiv preprint arXiv:2606.04799 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Changhua Pei, Zexin Wang, Fengrui Liu, Zeyan Li, Yang Liu, Xiao He, Rong Kang, Tieying Zhang, Jianjun Chen, Jianhui Li, et al. 2025. Flow-of-action: SOP enhanced LLM-based multi-agent system for root cause analysis. InCompanion Proceedings of the ACM on Web Conference. 422–431
2025
-
[17]
Luan Pham, Huong Ha, and Hongyu Zhang. 2024. BARO: Robust root cause anal- ysis for microservices via multivariate Bayesian online change point detection. Proceedings of the ACM on Software Engineering1, FSE (2024), 2214–2237
2024
-
[18]
Luan Pham, Hongyu Zhang, Huong Ha, Flora Salim, and Xiuzhen Zhang. 2025. RCAEval: a benchmark for root cause analysis of microservice systems with telemetry data. InCompanion Proceedings of the ACM on Web Conference 2025. 777–780
2025
-
[19]
Prometheus Authors. 2012. Prometheus: Monitoring System and Time Series Database. https://prometheus.io
2012
-
[20]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2024. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations, Vol. 2024. 9695–9717
2024
-
[21]
Yongqian Sun, Yu Luo, Xidao Wen, Yuan Yuan, Xiaohui Nie, Shenglin Zhang, Tong Liu, and Xi Luo. 2025. TrioXpert: An automated incident management framework for microservice system. InIEEE/ACM 40th International Conference on Automated Software Engineering. IEEE, 3239–3250
2025
-
[22]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in Neural Information Processing Systems 35 (2022), 24824–24837
2022
-
[23]
Li Wu, Johan Tordsson, Erik Elmroth, and Odej Kao. 2020. MicroRCA: Root cause localization of performance issues in microservices. InIEEE/IFIP Network Operations and Management Symposium
2020
-
[24]
Junjielong Xu, Qinan Zhang, Zhiqing Zhong, Shilin He, Chaoyun Zhang, Qingwei Lin, Dan Pei, Pinjia He, Dongmei Zhang, and Qi Zhang. 2025. Openrca: Can large language models locate the root cause of software failures?. InThe Thirteenth International Conference on Learning Representations (ICLR)
2025
-
[25]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations
2023
-
[26]
Shenglin Zhang, Pengxiang Jin, Zihan Lin, Yongqian Sun, Bicheng Zhang, Sibo Xia, Zhengdan Li, Zhenyu Zhong, Minghua Ma, Wa Jin, et al. 2023. Robust failure diagnosis of microservice system through multimodal data.IEEE Transactions on Services Computing16, 6 (2023), 3851–3864
2023
-
[27]
Shenglin Zhang, Sibo Xia, Wenzhao Fan, Binpeng Shi, Xiao Xiong, Zhenyu Zhong, Minghua Ma, Yongqian Sun, and Dan Pei. 2025. Failure diagnosis in microservice systems: A comprehensive survey and analysis.ACM Transactions on Software Engineering and Methodology35, 1 (2025), 1–55
2025
-
[28]
Wei Zhang, Hongcheng Guo, Jian Yang, Zhoujin Tian, Yi Zhang, Yan Chaoran, Zhoujun Li, Tongliang Li, Xu Shi, Liangfan Zheng, et al . 2024. mABC: Multi- agent blockchain-inspired collaboration for root cause analysis in micro-services architecture. InFindings of the Association for Computational Linguistics: EMNLP. 4017–4033. Cai et al
2024
-
[29]
Xuanhe Zhou, Guoliang Li, Zhaoyan Sun, Zhiyuan Liu, Weize Chen, Jianming Wu, Jiesi Liu, Ruohang Feng, and Guoyang Zeng. 2024. D-Bot: Database Diagnosis System using Large Language Models.Proceedings of the VLDB Endowment17, 10 (2024), 2514–2527
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.