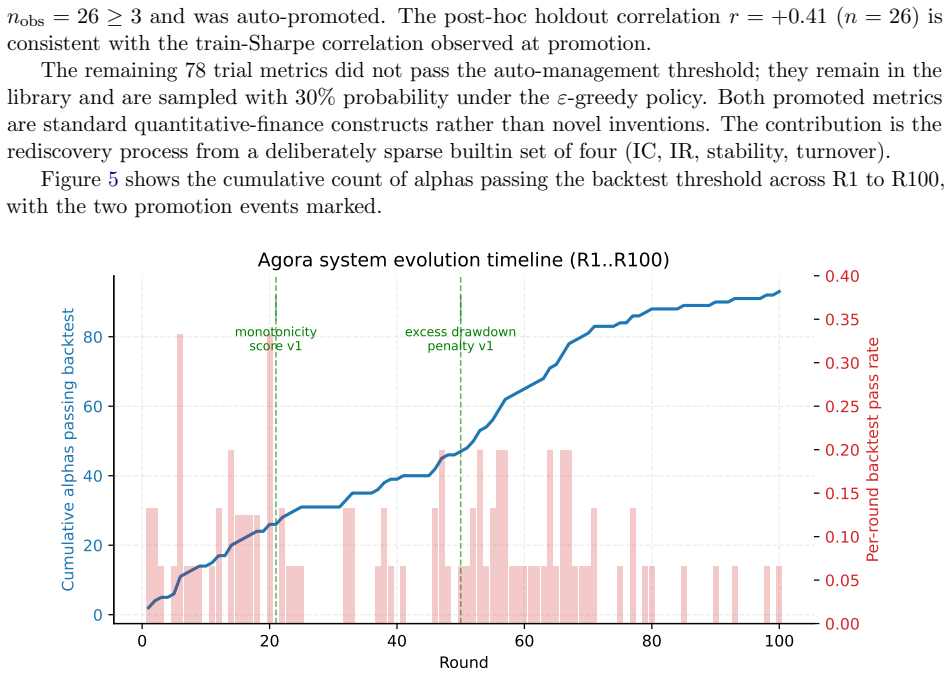
AI Trading's Alpha Singularity: Emergent Market Reasoning through Agent-to-Agent Self-Evolution
Pith reviewed 2026-06-30 07:52 UTC · model grok-4.3
The pith
Sealed Joint Search makes joint evolution of alpha factors and scoring functions admissible by enforcing information-flow constraints that block self-confirmation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
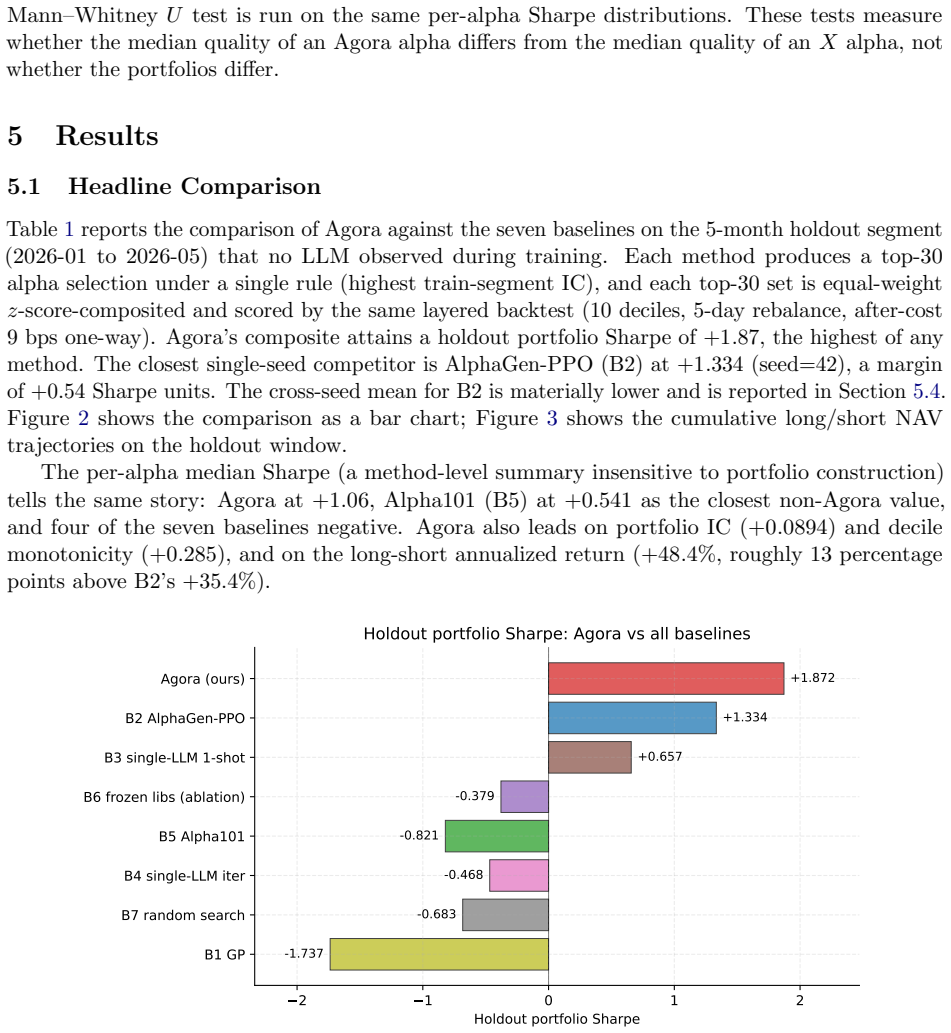
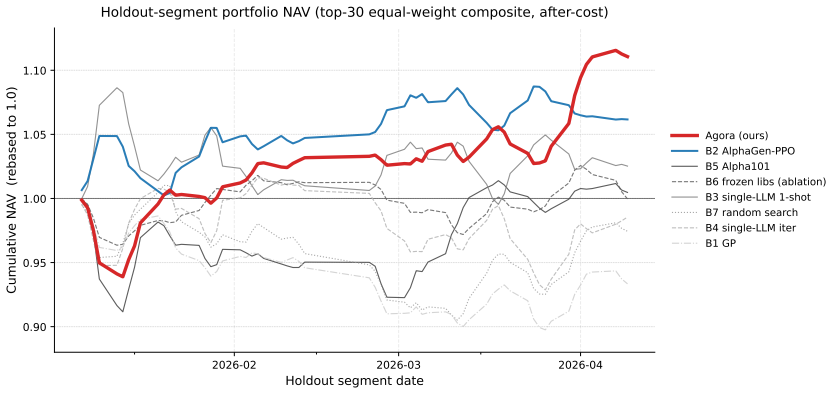
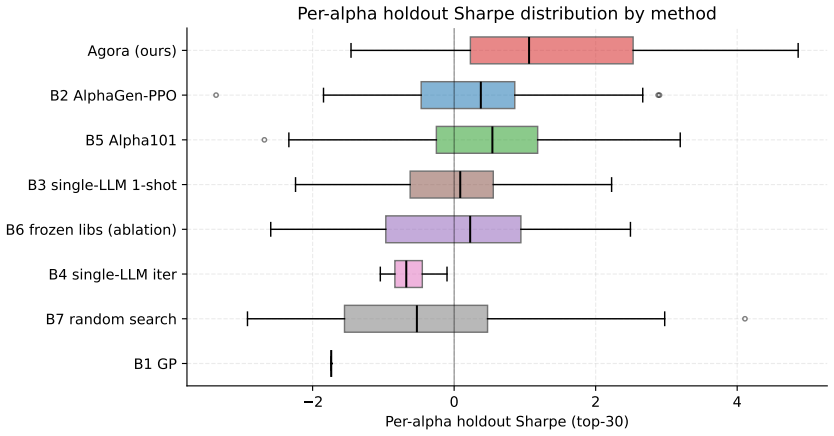
Automated alpha mining holds the scoring function fixed and varies the search algorithm over it. A search that converges against a fixed scorer overfits whatever the scorer cannot penalize, a primary cause of the out-of-sample generalization gap. We treat the scoring function as a search artifact alongside the alpha factors and study what conditions make this joint search admissible. Sealed Joint Search (SJS) is a framework of structural conditions on information flow that prevent collapse into self-confirmation while keeping the evaluator sealed. Agora tests SJS and achieves holdout Sharpe +1.87 on the sealed period.
What carries the argument
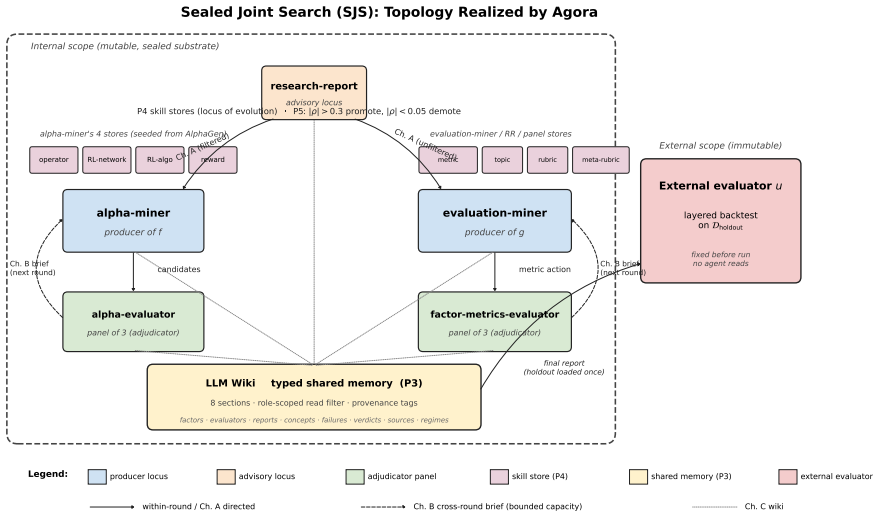
Sealed Joint Search (SJS), a framework consisting of role decomposition, typed inter-role communication, provenance-sealed reads, versioned stores, and substrate-local promotion that keeps the evaluator sealed during joint search of alphas and scorers.
If this is right
- Joint search under SJS conditions produces trading signals with better holdout performance than fixed-scorer baselines.
- Pre-loading known metrics into the system recovers only a fraction of the performance gap achieved by emergent metrics.
- Adding PPO without library evolution does not close the gap and may widen it.
- The two metrics used in evaluation emerge from the process rather than being pre-designed.
Where Pith is reading between the lines
- Similar information-flow constraints might reduce overfitting in other autonomous discovery systems that use learned evaluators.
- Testing the framework on longer holdout periods or additional markets would strengthen evidence that gains are not due to market-specific noise.
- Carrying forward disagreement among evaluators rather than voting may preserve signal diversity in multi-agent setups.
Load-bearing premise
The single random seed used for the 100-round Agora run is representative of the method's behavior and the 91-day holdout is long enough to establish that the performance difference is not due to short-term market noise or seed-specific luck.
What would settle it
Re-running the full Agora process with several independent random seeds on the same sealed holdout period and checking whether the Sharpe advantage over baselines holds on average.
Figures
read the original abstract
Automated alpha mining holds the scoring function fixed and varies the search algorithm over it. A search that converges against a fixed scorer overfits whatever the scorer cannot penalize, a primary cause of the out-of-sample generalization gap. We treat the scoring function as a search artifact alongside the alpha factors and study what conditions make this joint search admissible. Sealed Joint Search (SJS) is a framework: a set of structural conditions on information flow in an autonomous-discovery system that prevent joint search from collapsing into self-confirmation while keeping the evaluator sealed. Conditions cover role decomposition, typed inter-role communication, provenance-sealed reads, versioned stores, and substrate-local promotion. Agora tests SJS empirically: five LLM agent classes communicate via three channels, evolving eight skill libraries, with alpha libraries built on AlphaGen operators. Three evaluators write reports aggregated into one brief, carrying forward disagreement instead of voting. We run Agora for 100 rounds on CSI 1000 and evaluate on a 91-day 2026 holdout sealed from all LLM inputs. Agora achieves holdout Sharpe +1.87; best baseline +1.334 at favorable seed and -0.755 cross-seed mean. Pre-loading Agora's two metrics into a frozen-library ablation recovers only +0.40 of the +2.25 Sharpe gap, and adding PPO without library evolution worsens the gap. The two metrics emerge rather than being designed. Caveats: single-seed run, short-side concentrated signal, intended for long-short.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sealed Joint Search (SJS) as a set of structural conditions on information flow (role decomposition, typed communication, provenance-sealed reads, versioned stores, substrate-local promotion) that permit joint evolution of alpha factors and scoring functions without collapse into self-confirmation. It implements the framework in Agora, a five-class LLM agent system communicating over three channels that evolves eight skill libraries and alpha libraries via AlphaGen operators; three evaluators produce reports whose disagreements are aggregated into a brief. On CSI 1000, a 100-round Agora run yields holdout Sharpe +1.87 on a 91-day 2026 period sealed from all LLM inputs, versus best baseline +1.334 (favorable seed) and -0.755 (cross-seed mean). Ablations indicate that pre-loading the two emergent metrics recovers only +0.40 of the gap and that PPO without library evolution widens it.
Significance. If the performance gap is shown to be robust rather than seed- or period-specific, the result would indicate that carefully constrained multi-agent self-evolution can produce emergent, non-designed metrics that improve out-of-sample generalization in automated alpha discovery. The sealed-holdout design and explicit reporting of baseline seed variance are positive elements; however, the single-seed evaluation prevents strong attribution of the gap to SJS.
major comments (2)
- [Abstract] Abstract: the central claim that Agora achieves holdout Sharpe +1.87 attributable to SJS rests on a single random seed for the 100-round run. The paper itself reports baseline cross-seed mean -0.755 with favorable-seed peak only +1.334, establishing high seed sensitivity on this market and period; without additional independent runs, bootstrap intervals, or longer windows, the observed +2.25 gap cannot be distinguished from the same seed-luck mechanism visible in the baselines.
- [Abstract] Abstract: the 91-day 2026 holdout is short relative to standard equity-factor evaluation horizons and is described as short-side concentrated; combined with the single-seed design, this leaves open the possibility that the reported performance difference arises from short-term market noise rather than the joint-search conditions.
Simulated Author's Rebuttal
We thank the referee for the careful review and for emphasizing the need for statistical robustness in attributing performance to Sealed Joint Search. We respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Agora achieves holdout Sharpe +1.87 attributable to SJS rests on a single random seed for the 100-round run. The paper itself reports baseline cross-seed mean -0.755 with favorable-seed peak only +1.334, establishing high seed sensitivity on this market and period; without additional independent runs, bootstrap intervals, or longer windows, the observed +2.25 gap cannot be distinguished from the same seed-luck mechanism visible in the baselines.
Authors: We agree that the single-seed Agora run limits the ability to attribute the +2.25 gap solely to SJS rather than seed-specific effects. The manuscript already reports the baseline cross-seed mean and favorable-seed peak precisely to illustrate this sensitivity and lists the single-seed caveat explicitly. The ablations show that pre-loading the two emergent metrics recovers only +0.40 Sharpe and that PPO without library evolution widens the gap, providing some evidence that the joint evolution contributes. However, we lack additional independent Agora runs and therefore cannot supply cross-seed statistics or bootstrap intervals for the full system. revision: no
-
Referee: [Abstract] Abstract: the 91-day 2026 holdout is short relative to standard equity-factor evaluation horizons and is described as short-side concentrated; combined with the single-seed design, this leaves open the possibility that the reported performance difference arises from short-term market noise rather than the joint-search conditions.
Authors: The 91-day length and short-side concentration are stated as caveats in the manuscript; the period was selected to remain fully sealed from LLM training cutoffs. While this choice preserves evaluation integrity, it does increase exposure to short-term noise, and the single-seed design compounds the concern. The result is framed as preliminary evidence obtained under these constraints rather than a broad claim of robustness. revision: no
- Additional independent runs of the full 100-round Agora system to obtain seed-robust statistics
- Longer sealed holdout windows while preserving the information-sealing conditions
Circularity Check
No significant circularity; empirical holdout result is independent of inputs
full rationale
The paper defines SJS via explicit structural conditions on information flow (role decomposition, typed channels, provenance-sealed reads, versioned stores) and reports an empirical Sharpe on a 91-day 2026 holdout explicitly sealed from all LLM inputs. The two metrics are stated to emerge rather than being designed, with an ablation showing pre-loading them recovers only +0.40 of the gap. No equations, self-citations, or fitted parameters are presented that reduce the reported performance to the design choices by construction. Statistical concerns (single seed, short horizon) are separate from circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 91-day 2026 holdout period is statistically independent of all LLM inputs and long enough to distinguish signal from noise.
- domain assumption A single random seed is sufficient to establish the method's performance distribution.
Reference graph
Works this paper leans on
-
[1]
The Claude 3 model family: Opus, Sonnet, Haiku.Anthropic technical report (2024)
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku.Anthropic technical report (2024)
2024
-
[2]
Bailey, D. H. and Borwein, J. M. and L´ opez de Prado, M. and Zhu, Q. J.. Pseudo-mathematics and financial charlatanism: The effects of backtest overfitting on out-of-sample performance. Notices of the American Mathematical Society61(5), 458–471 (2014)
2014
-
[3]
Brown, T. B. and Mann, B. and Ryder, N. and Subbiah, M. and Kaplan, J. and Dhariwal, P. and others. Language models are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS)(2020)
2020
-
[4]
Carhart, M. M.. On persistence in mutual fund performance.The Journal of Finance52(1), 57–82 (1997)
1997
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M. and Tworek, J. and Jun, H. and Yuan, Q. and Ponde de Oliveira Pinto, H. and Kaplan, J. and others. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021). 25
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
and Wang, W
Cui, C. and Wang, W. and Zhang, M. and Chen, G. and Luo, Z. and Ooi, B. C.. AlphaEvolve: A learning framework to discover novel alphas in quantitative investment.Proceedings of the 2021 International Conference on Management of Data (SIGMOD), 2208–2216 (2021)
2021
-
[7]
Diebold, F. X. and Mariano, R. S.. Comparing predictive accuracy.Journal of Business & Economic Statistics13(3), 253–263 (1995)
1995
-
[8]
Fama, E. F. and French, K. R.. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics33(1), 3–56 (1993)
1993
-
[9]
Fama, E. F. and French, K. R.. A five-factor asset pricing model.Journal of Financial Economics116(1), 1–22 (2015)
2015
-
[10]
Harvey, C. R. and Liu, Y. and Zhu, H.. . . . and the cross-section of expected returns.The Review of Financial Studies29(1), 5–68 (2016)
2016
-
[11]
and Zhuge, M
Hong, S. and Zhuge, M. and Chen, J. and Zheng, X. and Cheng, Y. and Zhang, C. and Wang, J. and Wang, Z. and Yau, S. K. S. and Lin, Z. and Zhou, L. and Ran, C. and Xiao, L. and Wu, C. and Schmidhuber, J.. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR)(2024)
2024
-
[12]
Automated Design of Agentic Systems
Hu, S. and Lu, C. and Clune, J.. Automated design of agentic systems.arXiv preprint arXiv:2408.08435(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
and Titman, S
Jegadeesh, N. and Titman, S.. Returns to buying winners and selling losers: Implications for stock market efficiency.The Journal of Finance48(1), 65–91 (1993)
1993
-
[14]
101 Formulaic Alphas.Wilmott2016(84), 72–81 (2016)
Kakushadze, Z.. 101 Formulaic Alphas.Wilmott2016(84), 72–81 (2016)
2016
-
[15]
and Rosset, S
Kaufman, S. and Rosset, S. and Perlich, C. and Stitelman, O.. Leakage in data mining: Formulation, detection, and avoidance.ACM Transactions on Knowledge Discovery from Data 6(4), 1–21 (2012)
2012
-
[16]
R..Genetic Programming: On the Programming of Computers by Means of Natural Selection
Koza, J. R..Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press (1992)
1992
-
[17]
and Stanley, K
Lehman, J. and Stanley, K. O.. Exploiting open-endedness to solve problems through the search for novelty.Proceedings of the 11th International Conference on Artificial Life (ALIFE) (2008)
2008
-
[18]
and Hammoud, H
Li, G. and Hammoud, H. A. A. K. and Itani, H. and Khizbullin, D. and Ghanem, B.. CAMEL: Communicative agents for “mind” exploration of large language model society.Advances in Neural Information Processing Systems (NeurIPS)(2023)
2023
-
[19]
and Huang, W
Liang, J. and Huang, W. and Xia, F. and Xu, P. and Hausman, K. and Ichter, B. and Florence, P. and Zeng, A.. Code as policies: Language model programs for embodied control. InIEEE International Conference on Robotics and Automation (ICRA)(2023)
2023
-
[20]
and Yu, H
Liu, X. and Yu, H. and Zhang, H. and Xu, Y. and Lei, X. and Lai, H. and Gu, Y. and Ding, H. and Men, K. and Yang, K. and Zhang, S. and Deng, X. and Zeng, A. and Du, Z. and Zhang, C. and Shen, S. and Zhang, T. and Su, Y. and Sun, H. and Huang, M. and Dong, Y. and Tang, J.. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Repres...
2024
-
[21]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu, C. and Lu, C. and Lange, R. T. and Foerster, J. and Clune, J. and Ha, D.. The AI scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Wiley (2018)
L´ opez de Prado, M..Advances in Financial Machine Learning. Wiley (2018)
2018
-
[23]
Ma, Y. J. and Liang, W. and Wang, G. and Huang, D. and Bastani, O. and Jayaraman, D. and Zhu, Y. and Fan, L. and Anandkumar, A.. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
and Tandon, N
Madaan, A. and Tandon, N. and Gupta, P. and Hallinan, S. and Gao, L. and Wiegreffe, S. and Alon, U. and Dziri, N. and Prabhumoye, S. and Yang, Y. and Gupta, S. and Majumder, B. P. and Hermann, K. and Welleck, S. and Yazdanbakhsh, A. and Clark, P.. Self-Refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems (Ne...
2023
-
[25]
and Schwartz, R
Magar, I. and Schwartz, R.. Data contamination: From memorization to exploitation.Pro- ceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) (2022)
2022
-
[26]
Newey, W. K. and West, K. D.. A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix.Econometrica55(3), 703–708 (1987)
1987
-
[27]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Park, J. S. and O’Brien, J. C. and Cai, C. J. and Morris, M. R. and Liang, P. and Bernstein, M. S.. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST)(2023)
2023
-
[29]
Petersen, B. K. and Landajuela, M. and Mundhenk, T. N. and Santiago, C. P. and Kim, S. K. and Kim, J. T.. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients. InInternational Conference on Learning Representations (ICLR) (2021)
2021
-
[30]
and Liu, W
Qian, C. and Liu, W. and Liu, H. and Chen, N. and Dang, Y. and Li, J. and Yang, C. and Chen, W. and Su, Y. and Cong, X. and Xu, J. and Li, D. and Liu, Z. and Sun, M.. ChatDev: Communicative agents for software development.Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)(2024)
2024
-
[31]
and Hill, A
Raffin, A. and Hill, A. and Gleave, A. and Kanervisto, A. and Ernestus, M. and Dormann, N.. Stable-Baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research22(268), 1–8 (2021)
2021
-
[32]
and Barekatain, M
Romera-Paredes, B. and Barekatain, M. and Novikov, A. and Balog, M. and Kumar, M. P. and Dupont, E. and Ruiz, F. J. R. and Ellenberg, J. S. and Wang, P. and Fawzi, O. and Kohli, P. and Fawzi, A.. Mathematical discoveries from program search with large language models. Nature625, 468–475 (2024)
2024
-
[33]
and Dwivedi-Yu, J
Schick, T. and Dwivedi-Yu, J. and Dess` ı, R. and Raileanu, R. and Lomeli, M. and Zettlemoyer, L. and Cancedda, N. and Scialom, T.. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS)(2023). 27
2023
-
[34]
and Lipson, H
Schmidt, M. and Lipson, H.. Distilling free-form natural laws from experimental data.Science 324(5923), 81–85 (2009)
2009
-
[35]
Proximal Policy Optimization Algorithms
Schulman, J. and Wolski, F. and Dhariwal, P. and Radford, A. and Klimov, O.. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
and Cassano, F
Shinn, N. and Cassano, F. and Berman, E. and Gopinath, A. and Narasimhan, K. and Yao, S.. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS)(2023)
2023
-
[37]
Stanley, K. O. and Lehman, J. and Soros, L.. Open-endedness: The last grand challenge you’ve never heard of.O’Reilly Online(2017)
2017
-
[38]
and Shazeer, N
Vaswani, A. and Shazeer, N. and Parmar, N. and Uszkoreit, J. and Jones, L. and Gomez, A. N. and Kaiser, L. and Polosukhin, I.. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5998–6008 (2017)
2017
-
[39]
Wang, R. and Lehman, J. and Clune, J. and Stanley, K. O.. Paired open-ended trailblazer (POET): Endlessly generating increasingly complex and diverse learning environments and their solutions.arXiv preprint arXiv:1901.01753(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[40]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G. and Xie, Y. and Jiang, Y. and Mandlekar, A. and Xiao, C. and Zhu, Y. and Fan, L. and Anandkumar, A.. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
and Chen, Y
Wang, X. and Chen, Y. and Yuan, L. and Zhang, Y. and Li, Y. and Peng, H. and Ji, H.. Executable code actions elicit better LLM agents. InInternational Conference on Machine Learning (ICML)(2024)
2024
-
[42]
and Wang, X
Wei, J. and Wang, X. and Schuurmans, D. and Bosma, M. and Ichter, B. and Xia, F. and Chi, E. and Le, Q. V. and Zhou, D.. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS)(2022)
2022
-
[43]
A reality check for data snooping.Econometrica68(5), 1097–1126 (2000)
White, H.. A reality check for data snooping.Econometrica68(5), 1097–1126 (2000)
2000
-
[44]
BloombergGPT: A Large Language Model for Finance
Wu, S. and Irsoy, O. and Lu, S. and Dabravolski, V. and Dredze, M. and Gehrmann, S. and Kambadur, P. and Rosenberg, D. and Mann, G.. BloombergGPT: A large language model for finance.arXiv preprint arXiv:2303.17564(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
and Bansal, G
Wu, Q. and Bansal, G. and Zhang, J. and Wu, Y. and Li, B. and Zhu, E. and Jiang, L. and Zhang, X. and Zhang, S. and Liu, J. and Awadallah, A. H. and White, R. W. and Burger, D. and Wang, C.. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. InCOLM(2024)
2024
-
[46]
Xiao, Y. and Sun, E. and Luo, D. and Wang, W.. TradingAgents: Multi-agents LLM financial trading framework.arXiv preprint arXiv:2412.20138(2024)
-
[47]
Yang, H. and Liu, X. and Wang, C. D.. FinGPT: Open-source financial large language models. arXiv preprint arXiv:2306.06031(2023)
-
[48]
and Zhao, J
Yao, S. and Zhao, J. and Yu, D. and Du, N. and Shafran, I. and Narasimhan, K. and Cao, Y.. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)(2023). 28
2023
-
[49]
and Yu, D
Yao, S. and Yu, D. and Zhao, J. and Shafran, I. and Griffiths, T. L. and Cao, Y. and Narasimhan, K.. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems (NeurIPS)(2023)
2023
-
[50]
Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Denghui Zhang, Rong Liu, Jordan W
Yu, Y. and Li, H. and Chen, Z. and Jiang, Y. and Li, Y. and Zhang, D. and Liu, R. and Suchow, J. W. and Khashanah, K.. FinMem: A performance-enhanced LLM trading agent with layered memory and character design.arXiv preprint arXiv:2311.13743(2023)
-
[51]
and Xue, H
Yu, S. and Xue, H. and Ao, X. and Pan, F. and He, J. and Tu, D. and He, Q.. Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pages 5476–5486 (2023)
2023
-
[52]
and Wu, Y
Zelikman, E. and Wu, Y. and Mu, J. and Goodman, N. D.. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems (NeurIPS)(2022)
2022
-
[53]
and Li, Y
Zhang, T. and Li, Y. and Jin, Y. and Li, J.. AutoAlpha: an efficient hierarchical evolutionary algorithm for mining alpha factors in quantitative investment. InProceedings of the AAAI Conference on Artificial Intelligence (Workshop)(2020). A Implementation Details This appendix records the concrete versions, file paths, hyperparameters, and access tables ...
2020
-
[54]
far above / above / near / far below
Cross-round metric feedback uses categorical buckets only.The build metrics feedback routine reports “far above / above / near / far below” rather than numerical Sharpe, IC, annualized return, or drawdown
-
[55]
far above
Test-segment backtest feedback in read-only categorical form.The evaluation-miner calls simple backtest layered on the test segment (2020–2025) to check whether a proposed alpha holds up beyond the training window. The numerical Sharpe value is never passed to the LLM context: build metrics feedback converts it to one of four categorical labels (“far abov...
2020
-
[56]
Test-segment Sharpe is never included in this computation
Metric avg pred corr uses train-segment Sharpe.The auto-management correlation is computed as the Pearson correlation between the metric’s score and thetrain-segment Sharpe of the alpha being scored, accumulated across all rounds in which the metric was used. Test-segment Sharpe is never included in this computation. The promotion threshold is |avg pred c...
-
[57]
far above / above / near / far below
The PPO test-IC computation writes to a separate audit file.The top alphas.json consumed by the LLM stack contains only training IC; top alphas audit.json contains test IC and is read only by the offline analysis path. These five paths correspond to the four sealing enforcement points described in Section 3: the Wiki access-role filter (point 1), Channel ...
2020
-
[58]
A second full seed (approximately 60 GPU-hours) would bound the full-system seed variance
Full 100-round multi-seed Agora.The full system has been run at one seed only. A second full seed (approximately 60 GPU-hours) would bound the full-system seed variance
-
[59]
static value of two metrics
100-round B6 and B6+augmented-builtins runs.The B6 ablation variants ran for 5 outer rounds; Agora ran for 100. A 100-round B6+aug run (roughly 30 hours) would close the round-count confound on the +0 .40 “static value of two metrics” attribution and the −0.80 “PPO relay alone” attribution. Both attributions are expected to hold in direction; the magnitud...
-
[60]
PPO relay alone is harmful
Multi-seed replication of the decomposition ablations.The B6+aug 20-round and B6+relay 5-round results each rest on a single seed. Replication at additional seeds (around 1.5–2 hours each) would tighten the magnitude of the −0.80 “PPO relay alone is harmful” attribution, which is currently preliminary
-
[61]
One LLM instance that both proposes alphas and evolves metrics, without the A2A decomposition, would isolate the contribution of F1 from F4–F5
Single-agent-with-evolution baseline.A direct ablation of F1 (decomposition) is the most important missing empirical test of SJS. One LLM instance that both proposes alphas and evolves metrics, without the A2A decomposition, would isolate the contribution of F1 from F4–F5. We have not run it. 5.Operator, network, and reward library evolution.Seven of the ...
-
[62]
We have not performed this experiment
Replication on non-Chinese universes.The data adapter is dataset-agnostic; porting to S&P 500 or NASDAQ requires only the adapter. We have not performed this experiment
-
[63]
Testing F1–F5 on autonomous theorem proving, autonomous experimental design, or autonomous code synthesis is the direct check
Generalization of SJS beyond alpha mining.The information-flow contract is plausibly domain-agnostic; the cost-effective realization (which LLM, which substrate, which promo- tion outcome variable) is domain-specific. Testing F1–F5 on autonomous theorem proving, autonomous experimental design, or autonomous code synthesis is the direct check
-
[64]
featured
Factor decomposition and capacity analysis.Deployment-relevant questions (factor- adjusted alpha relative to [ 8, 9, 4], ADV-based capacity, short-borrow availability, multiple- testing correction following [ 10, 43]) require new data infrastructure outside the present evaluation harness. B Baseline Implementation Details Each baseline shares a single eva...
-
[65]
Cloning Agora’s repository to a sibling directory with wiki/ emptied, runs/ emptied, and every skill library’s discovered/ contents removed and registry.json reset so only the builtin sets remain (64 builtin skills total)
-
[66]
Monkey-patching every library class’s add, modify, promote, demote, and auto manage meth- ods to no-op (returning a failure tuple of the appropriate arity) before importing the orches- trator
-
[67]
Setting enable incremental ppo = False (the PPO relay would otherwise mutate operator/network/RL-algorithm libraries indirectly through training, breaking the ablation’s framing asfrozenlibraries; this also introduces an additional confound in the Agora-vs-B6 attribution that is discussed in Appendix A.9)
-
[68]
Wall-clock: approximately 1.5 hours per run
Running the orchestrator for5 outer rounds. Wall-clock: approximately 1.5 hours per run
-
[69]
The configuration is otherwise identical to Agora
Reading the resulting holdout report.json and routing the top-30 alphas (selected bytrain- segment IC, matching the selection rule used for every other method) through the common evaluation harness. The configuration is otherwise identical to Agora. Round-count confound.B6 was run for 5 outer rounds; Agora was run for 100. The round count is a real confou...
-
[70]
(Primary) Newey-West HAC t-teston the daily difference in composite portfolio log- returns dt = rAgora t −r X t . The Newey-West sandwich variance estimator is computed directly: σ2 NW = γ0+2P5 L=1(1−L/(Lmax+1))γL with Bartlett kernel and Lmax = 5, where γL is the lag- L autocovariance of dt [26]. The annualized Sharpe SE uses the delta-method approximati...
-
[71]
Reported for distributional characterization only; not a valid portfolio-level test due to cross-sectional correlation
(Secondary, descriptive) Two-sample bootstrap(10,000 resamples, NumPy default RNG seeded with 42) on the difference of medians of the two per-alpha Sharpe distributions; reports the observed difference, 2.5%/97.5% percentiles as the 95% CI, and a two-sided p-value. Reported for distributional characterization only; not a valid portfolio-level test due to ...
-
[72]
correlated but non-monotonic bucketing
(Secondary, descriptive) One-sided Mann–Whitney U testof Agora versus the baseline. These two secondary tests are reported in Table 6 alongside the primary NW HAC results. C Source Code: Two Promoted Metrics This appendix lists the full source of the two metrics promoted from trial to accepted during the 100-round Agora run. Both files are written by the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.