Bayesian Best-Arm Identification with Abstention: A Polynomial-to-Exponential Phase Transition
Pith reviewed 2026-06-30 08:54 UTC · model grok-4.3
The pith
Adding any small abstention budget shifts Bayesian best-arm identification error decay from polynomial to exponential in T.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
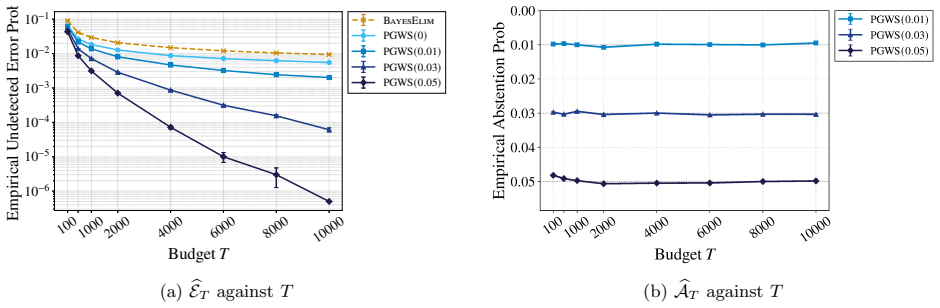
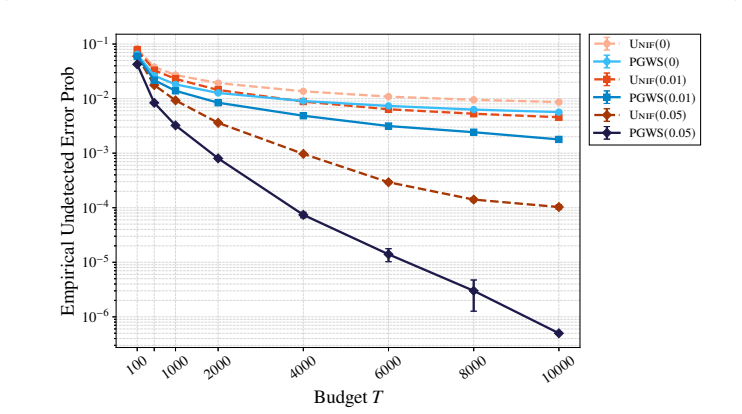
The central claim is that abstention induces a phase transition in the undetected error probability for Bayesian best-arm identification. Without abstention the error decays polynomially in T; with any positive abstention budget α the decay becomes exponential. For Gaussian priors and rewards, after first letting T tend to infinity and then α to zero, the optimal exponent is precisely -α²T/(8κ_ν²) with matching information-theoretic bounds, where κ_ν is the prior density of the top-two gap evaluated at zero. The paper supplies an adaptive algorithm that attains the exponent by expending abstentions on statistically ambiguous instances and notes that the phenomenon does not appear in the freq
What carries the argument
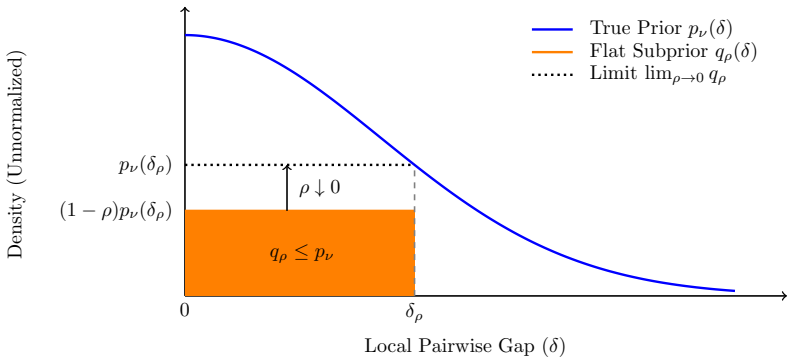
The abstention budget α, which permits the learner to refrain from recommending when the top-two arms have a small gap, with the rate governed by the prior density κ_ν of that gap at zero.
If this is right
- The undetected error probability decays exponentially as exp(-α²T/8κ_ν²) once α is positive.
- An adaptive algorithm attains the optimal exponent by abstaining precisely on instances with small top-two gaps.
- The polynomial-to-exponential shift occurs only in the Bayesian setting; frequentist analysis shows abstention affects only lower-order terms.
- The same phase transition and exponent form extend to models beyond Gaussians.
Where Pith is reading between the lines
- The same abstention mechanism could produce analogous rate improvements in other Bayesian sequential identification or testing problems.
- Estimating the gap density κ_ν from data might allow setting α to achieve a target error level in practice.
- The emphasis on near-tie instances suggests that problem instances with heavy prior mass near zero gaps are the hardest even with abstention.
Load-bearing premise
The exact matching bounds and closed-form exponent require Gaussian priors and rewards together with taking the sampling budget T to infinity before letting the abstention budget α approach zero.
What would settle it
Run simulations with Gaussian rewards and priors, let T grow large then α small, and check whether the observed log error probability scales linearly with α²T at slope -1/(8κ_ν²); deviation from this scaling would falsify the claimed exponent.
Figures
read the original abstract
We study the Bayesian fixed-budget best-arm identification problem in which a learner can abstain from making a terminal recommendation. Subject to an abstention budget $\alpha$, we analyze the probability of undetected error--the risk of recommending a suboptimal arm without abstaining. Our central finding is that abstention induces a phase transition: without abstention, the error probability decays polynomially in the sampling budget $T$; in contrast, introducing any small positive abstention budget shifts this to an exponential decay. For Gaussian priors and rewards, in the regime $T\to\infty$ followed by $\alpha\downarrow0$, we establish exact matching information-theoretic lower bounds and algorithmic upper bounds on the optimal error exponent, which takes the form $\exp(-\frac{\alpha^{2}T}{8\kappa_{\nu}^{2}})$. The hardness parameter $\kappa_{\nu}$ represents the prior density of the top-two gap at zero, highlighting that nearly tied instances drive the fundamental error. We introduce an adaptive algorithm, PGWS, that successfully achieves this optimal exponent by expending its abstention budget on statistically ambiguous instances. We further demonstrate that this polynomial-to-exponential improvement is exclusively a Bayesian phenomenon--in the frequentist setting, abstention only affects lower-order exponent terms. We also extend our results beyond the Gaussian model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Bayesian fixed-budget best-arm identification allowing abstention with budget α. It claims that introducing any small positive α induces a phase transition: error probability decays polynomially in T without abstention but exponentially with abstention. For Gaussian priors and rewards, in the regime T→∞ followed by α↓0, matching information-theoretic lower bounds and algorithmic upper bounds are given for the optimal error exponent exp(−α²T/8κ_ν²), where κ_ν is the prior density of the top-two gap at zero. The adaptive PGWS algorithm achieves this exponent by abstaining on ambiguous instances. The improvement is claimed to be exclusively Bayesian (frequentist setting sees only lower-order effects), and results are stated to extend beyond Gaussians.
Significance. If the matching bounds hold, the work is significant for identifying a sharp phase transition induced by abstention and for precisely characterizing the exponent via the hardness parameter κ_ν tied to nearly-tied instances. The explicit Bayesian-vs-frequentist distinction and the PGWS algorithm provide concrete insight into how abstention can be leveraged. Credit is due for deriving closed-form matching bounds under the stated model and limit order. The result is novel but its scope is narrowed by the Gaussian assumption and double-asymptotic regime.
major comments (2)
- [Abstract] Abstract: The exact matching lower and upper bounds on the exponent exp(−α²T/8κ_ν²) and the polynomial-to-exponential phase transition are derived under Gaussian priors/rewards together with the specific limit order T→∞ then α↓0; the information-theoretic lower-bound construction and PGWS analysis both rely on Gaussian closed-form posteriors and tail bounds, so the central claim does not automatically extend with the same rate.
- [Abstract] Abstract: The statement that results extend beyond the Gaussian model lacks supporting derivation or evidence in the core analysis; without Gaussian structure the identification of nearly-tied instances as the dominant error source and the quadratic dependence on α do not carry over directly.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review, which highlights important points about the scope of our results. We agree that the quantitative matching bounds rely on the Gaussian setting and will revise the abstract to clarify this without overstating generality.
read point-by-point responses
-
Referee: [Abstract] Abstract: The exact matching lower and upper bounds on the exponent exp(−α²T/8κ_ν²) and the polynomial-to-exponential phase transition are derived under Gaussian priors/rewards together with the specific limit order T→∞ then α↓0; the information-theoretic lower-bound construction and PGWS analysis both rely on Gaussian closed-form posteriors and tail bounds, so the central claim does not automatically extend with the same rate.
Authors: We agree. The abstract already qualifies the matching bounds and exponent as holding for Gaussian priors and rewards under the stated limit order. The central contribution is the identification of the phase transition in this setting. We will revise the abstract to emphasize that the precise rate and matching bounds are Gaussian-specific and do not automatically extend at the same quantitative level to other models. revision: yes
-
Referee: [Abstract] Abstract: The statement that results extend beyond the Gaussian model lacks supporting derivation or evidence in the core analysis; without Gaussian structure the identification of nearly-tied instances as the dominant error source and the quadratic dependence on α do not carry over directly.
Authors: We acknowledge that the core analysis, including the lower-bound construction, PGWS algorithm, and identification of nearly-tied instances, relies on Gaussian closed forms. The abstract's claim of extension beyond Gaussians is not supported by detailed derivations for the same rate in the current manuscript. We will revise the abstract to remove or appropriately qualify this statement to accurately reflect the provided analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper establishes matching information-theoretic lower bounds and algorithmic upper bounds on the optimal error exponent under Gaussian priors/rewards in the double-asymptotic regime, with the exponent expressed in terms of the explicitly defined hardness parameter κ_ν (prior density of top-two gap at zero). The phase-transition claim is obtained by direct analysis contrasting the Bayesian and frequentist settings; no step reduces by construction to a fitted input, self-definition, or load-bearing self-citation. The derivation is self-contained against external information-theoretic benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- κ_ν
axioms (1)
- domain assumption Gaussian priors and rewards
Reference graph
Works this paper leans on
-
[1]
Journal of Operations Research , volume =
Smith, John , title =. Journal of Operations Research , volume =
-
[2]
INFORMS Mathematics of Operations Research , volume =
Jones, Sarah , title =. INFORMS Mathematics of Operations Research , volume =
-
[3]
Brown, David , title =
-
[4]
Best Arm Identification in Multi-Armed Bandits , booktitle =
Audibert, Jean-Yves and Bubeck, Sébastien and Munos, Remi , year =. Best Arm Identification in Multi-Armed Bandits , booktitle =
-
[5]
On the complexity of best-arm identification in multi-armed bandit models , year =
Kaufmann, Emilie and Capp\'. On the complexity of best-arm identification in multi-armed bandit models , year =. J. Mach. Learn. Res. , month = jan, pages =
-
[6]
Russo, Daniel , booktitle =. Simple. 2016 , editor =
2016
-
[7]
2023 , eprint=
Bayesian Fixed-Budget Best-Arm Identification , author=. 2023 , eprint=
2023
-
[8]
Komiyama, Junpei and Ariu, Kaito and Kato, Masahiro and Qin, Chao , title =. Math. Oper. Res. , month = aug, pages =. 2024 , issue_date =. doi:10.1287/moor.2022.0011 , abstract =
-
[9]
Journal of Machine Learning Research , year =
Eyal Even-Dar and Shie Mannor and Yishay Mansour , title =. Journal of Machine Learning Research , year =
-
[10]
Best Arm Identification: A Unified Approach to Fixed Budget and Fixed Confidence , url =
Gabillon, Victor and Ghavamzadeh, Mohammad and Lazaric, Alessandro , booktitle =. Best Arm Identification: A Unified Approach to Fixed Budget and Fixed Confidence , url =
-
[11]
2000 , isbn =
Methods of Information Geometry , series =. 2000 , isbn =
2000
-
[12]
Proceedings of the 30th International Conference on Machine Learning , pages =
Almost Optimal Exploration in Multi-Armed Bandits , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , editor =
2013
-
[13]
Minimax Optimal Algorithms for Fixed-Budget Best Arm Identification , url =
Komiyama, Junpei and Tsuchiya, Taira and Honda, Junya , booktitle =. Minimax Optimal Algorithms for Fixed-Budget Best Arm Identification , url =
-
[14]
29th Annual Conference on Learning Theory , pages =
Tight (Lower) Bounds for the Fixed Budget Best Arm Identification Bandit Problem , author =. 29th Annual Conference on Learning Theory , pages =. 2016 , editor =
2016
-
[15]
Prior-Dependent Allocations for
Nguyen, Nicolas and Aouali, Imad and Gy. Prior-Dependent Allocations for. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =. 2025 , editor =
2025
-
[16]
, journal=
Chow, C. , journal=. On optimum recognition error and reject tradeoff , year=
-
[17]
Bartlett and Marten H
Peter L. Bartlett and Marten H. Wegkamp , title =. Journal of Machine Learning Research , year =
-
[18]
Learning with Rejection
Cortes, Corinna and DeSalvo, Giulia and Mohri, Mehryar. Learning with Rejection. Algorithmic Learning Theory. 2016
2016
-
[19]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Wang, Po-An and Tzeng, Ruo-Chun and Proutiere, Alexandre , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[20]
and Juneja, S
Glynn, P. and Juneja, S. , booktitle=. A large deviations perspective on ordinal optimization , year=
-
[21]
Simulation Budget Allocation for Further Enhancing the Efficiency of Ordinal Optimization , volume =
Chen, Chun-Hung and Lin, Jianwu and Yücesan, Enver and Chick, Stephen , year =. Simulation Budget Allocation for Further Enhancing the Efficiency of Ordinal Optimization , volume =. Discrete Event Dynamic Systems , doi =
-
[22]
Jeff and Fan, Weiwei and Luo, Jun , year=
Hong, L. Jeff and Fan, Weiwei and Luo, Jun , year=. Review on ranking and selection: A new perspective , volume=. Frontiers of Engineering Management , publisher=. doi:10.1007/s42524-021-0152-6 , number=
-
[23]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =
Fixed-confidence guarantees for Bayesian best-arm identification , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , editor =
2020
-
[24]
Bandit Algorithms , publisher=
Lattimore, Tor and Szepesvári, Csaba , year=. Bandit Algorithms , publisher=
-
[25]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Jang, Kyoungseok and Komiyama, Junpei and Yamazaki, Kazutoshi , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[26]
Selective Sampling for Online Best-arm Identification , url =
Camilleri, Romain and Xiong, Zhihan and Fazel, Maryam and Jain, Lalit and Jamieson, Kevin , booktitle =. Selective Sampling for Online Best-arm Identification , url =
-
[27]
2026 , eprint=
Asymptotically and Minimax Optimal Regret Bounds for Multi-Armed Bandits with Abstention , author=. 2026 , eprint=
2026
-
[28]
Junwen Yang and Tianyuan Jin and Vincent Y. F. Tan , title =. Transactions on Machine Learning Research , volume =
-
[29]
, journal=
Forney, G. , journal=. Exponential error bounds for erasure, list, and decision feedback schemes , year=
-
[30]
IEEE Transactions on Information Theory , volume =
Merhav, Neri , title =. IEEE Transactions on Information Theory , volume =
-
[31]
IEEE Transactions on Information Theory , volume =
Somekh-Baruch, Anelia and Merhav, Neri , title =. IEEE Transactions on Information Theory , volume =
-
[32]
Hayashi, Masahito and Tan, Vincent Y. F. , title =. IEEE Transactions on Information Theory , volume =
-
[33]
and Loss,Michael , year=
Lieb,Elliott H. and Loss,Michael , year=. Analysis , publisher=
-
[34]
Lehmann,E. L. and Romano,Joseph P. , year=. Testing Statistical Hypotheses , publisher=
-
[35]
Miyamoto, Henrique K. and Meneghetti, Fábio C. C. and Pinele, Julianna and Costa, Sueli I. R. , year=. On closed-form expressions for the Fisher–Rao distance , volume=. Information Geometry , publisher=. doi:10.1007/s41884-024-00143-2 , number=
-
[36]
Rao, C. Radhakrishna. Information and the Accuracy Attainable in the Estimation of Statistical Parameters. Breakthroughs in Statistics: Foundations and Basic Theory. 1992. doi:10.1007/978-1-4612-0919-5_16
-
[37]
Atkinson,Colin and Mitchell,Ann F. S. , year=. Rao's Distance Measure , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.