A Hybrid Framework for Song Lyric Annotation Based on Human-LLM Alignment
Pith reviewed 2026-06-30 07:40 UTC · model grok-4.3
The pith
A hybrid framework predicts where humans and LLMs will disagree on song lyric emotion labels to decide who should annotate each sentence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
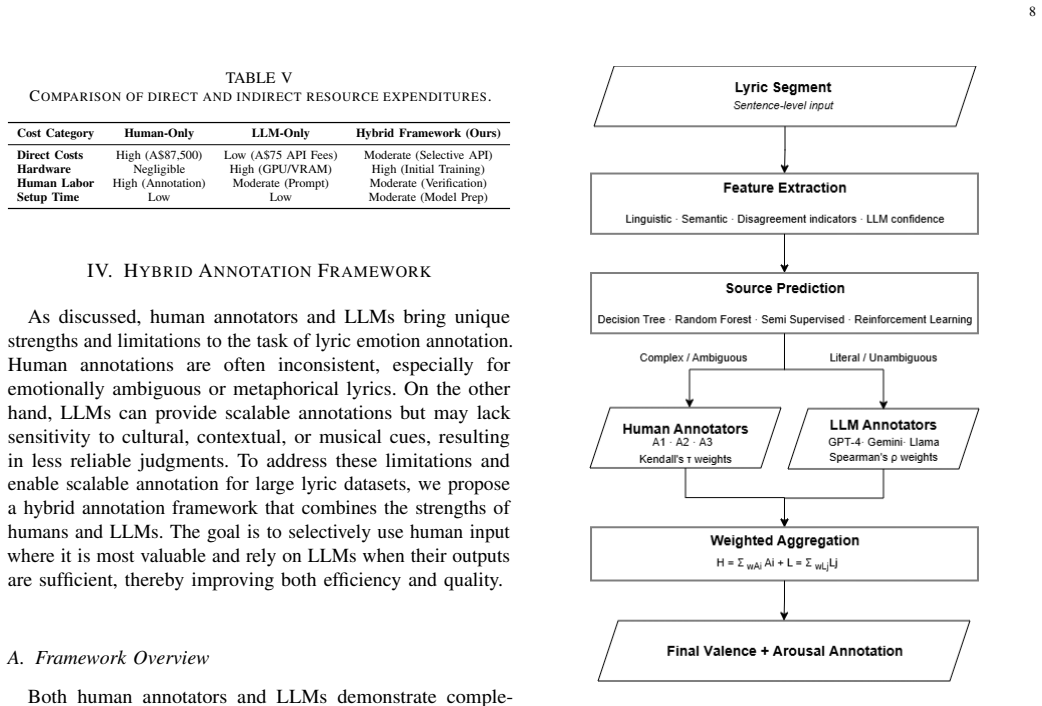
The paper presents a hybrid annotation framework for song lyrics that uses a model to predict potential misalignment between human and LLM annotations, thereby optimizing the allocation of annotation tasks between humans and models.
What carries the argument
The misalignment prediction model that routes each lyric sentence to either a human annotator or an LLM based on expected agreement.
If this is right
- The framework assigns only the high-misalignment sentences to humans while accepting LLM labels elsewhere.
- Overall annotation cost drops because fewer sentences require human effort.
- Label consistency rises because humans handle the cases where models are most likely to err.
- The same misalignment predictor can be retrained as more labeled lyrics become available.
- The approach applies directly to other sentence-level emotion tasks on creative text.
Where Pith is reading between the lines
- The predictor could be extended to other subjective domains such as poetry or dialogue scripts without changing the routing logic.
- If the misalignment signal correlates with lyric ambiguity, the same model might also surface hard cases for further linguistic study.
- Repeated application of the framework would gradually shift the training distribution toward sentences where humans and LLMs already agree.
Load-bearing premise
Predicting misalignment between humans and LLMs can be done accurately enough to improve the speed or quality of the overall lyric annotation process.
What would settle it
A controlled test on the new lyrics dataset in which the hybrid framework shows no reduction in total annotation time and no gain in final label agreement compared with using humans alone or LLMs alone.
Figures



read the original abstract
Emotion recognition of song lyrics is a challenging task since lyrics may not necessarily align with the overall emotion of a song. As a result, lyrics annotation remains largely underexplored. Drawing inspiration from research in large language model (LLM) assisted annotation, we examine the alignment between humans and LLMs for annotation of lyrics by creating a new sentence-level dataset of lyrics. Our observations highlight the subjectivity of the task and the inherent challenges. Following this, we present a hybrid annotation framework that optimizes human and LLM annotation by predicting potential misalignment in annotation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper creates a new sentence-level dataset for song lyric emotion annotation, observes high subjectivity and misalignment between human and LLM annotations, and proposes a hybrid framework that predicts potential misalignment to optimize the allocation of human and LLM annotation effort.
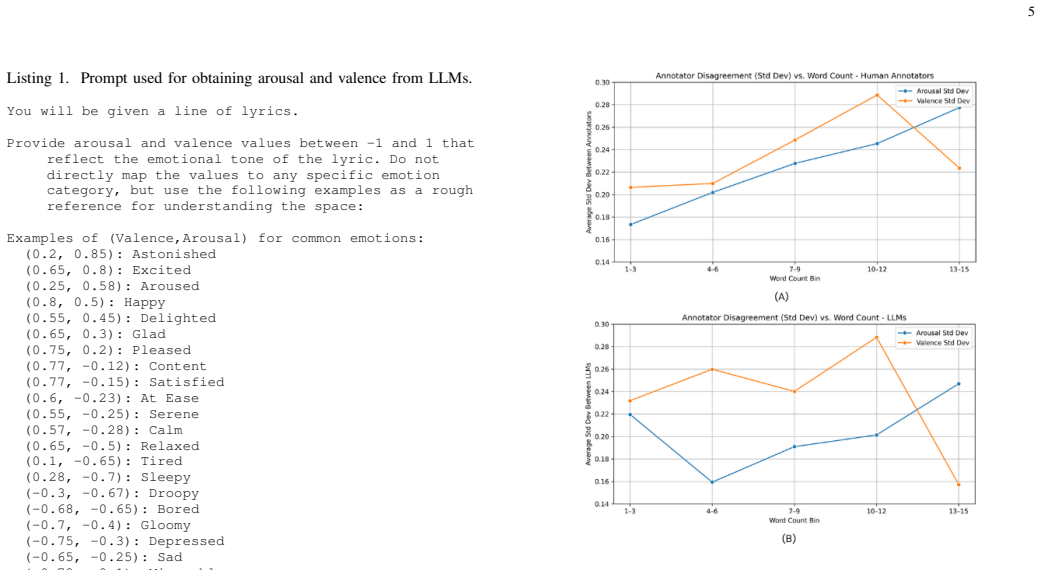
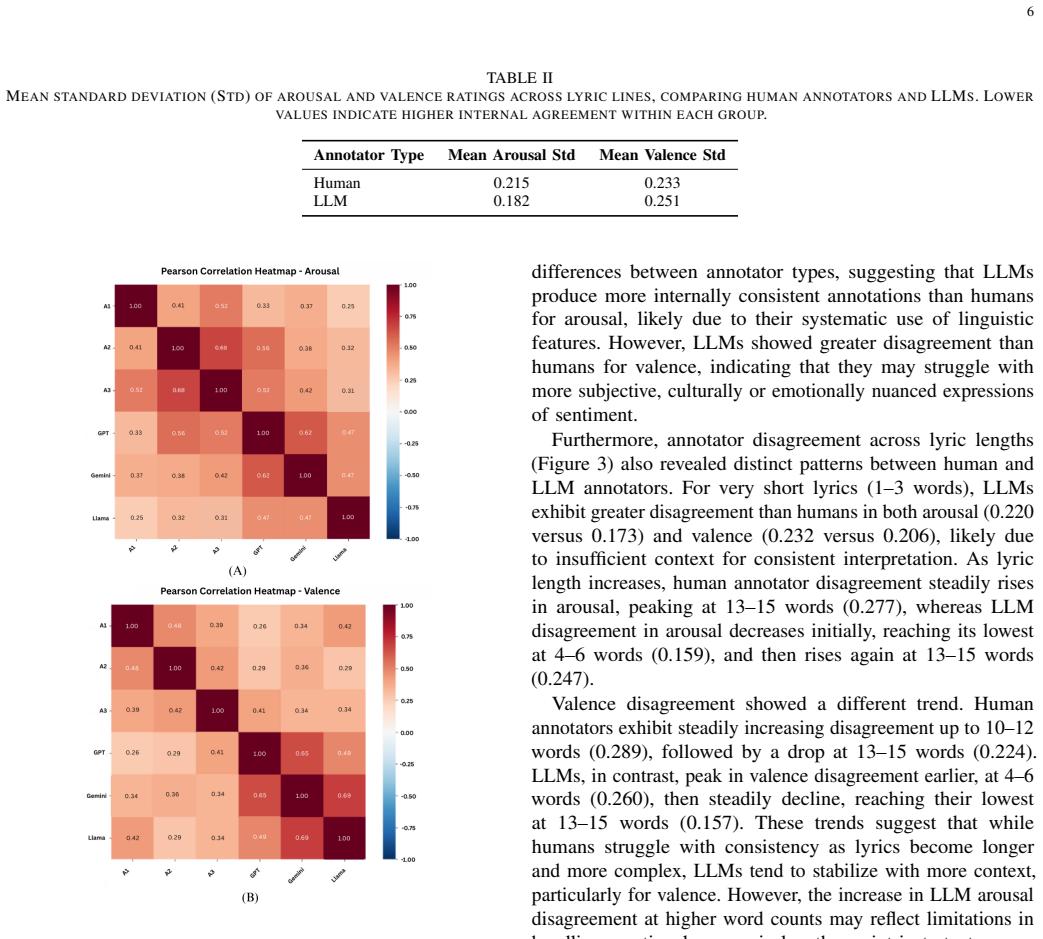
Significance. If the misalignment predictor can be shown to deliver measurable efficiency or quality gains, the work would contribute a practical hybrid annotation method for subjective creative-text tasks. The new dataset itself is a useful resource for the community. However, the manuscript supplies no methods, accuracy figures, or before/after comparisons, so the optimization claim currently lacks an empirical foundation.
major comments (2)
- [Abstract, §3] Abstract and §3 (Hybrid Framework): the central claim that the framework 'optimizes human and LLM annotation by predicting potential misalignment' is unsupported because the manuscript provides no description of the predictor (features, model, training procedure), no accuracy or F1 numbers, and no ablation or baseline comparison showing net gains in annotation quality or cost.
- [Results / Evaluation] Results / Evaluation section: no validation metrics, error analysis, inter-annotator agreement figures, or statistical tests are reported for either the misalignment predictor or the end-to-end hybrid process, rendering the optimization claim impossible to assess.
minor comments (1)
- [Abstract] The abstract states observations about subjectivity but does not quantify them (e.g., disagreement rates); adding concrete statistics would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the current manuscript lacks sufficient methodological detail and empirical validation for the misalignment predictor and hybrid framework claims. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Hybrid Framework): the central claim that the framework 'optimizes human and LLM annotation by predicting potential misalignment' is unsupported because the manuscript provides no description of the predictor (features, model, training procedure), no accuracy or F1 numbers, and no ablation or baseline comparison showing net gains in annotation quality or cost.
Authors: We agree that the manuscript does not currently provide a description of the misalignment predictor or supporting quantitative results. In the revised version we will expand §3 with the full predictor details (features, model, training procedure), report accuracy and F1 scores, and add ablation studies plus baseline comparisons demonstrating net gains in quality or cost. revision: yes
-
Referee: [Results / Evaluation] Results / Evaluation section: no validation metrics, error analysis, inter-annotator agreement figures, or statistical tests are reported for either the misalignment predictor or the end-to-end hybrid process, rendering the optimization claim impossible to assess.
Authors: We acknowledge the absence of these elements. The revised manuscript will add validation metrics, error analysis, inter-annotator agreement figures, and statistical tests for both the predictor and the end-to-end hybrid process. revision: yes
Circularity Check
No derivation chain or equations present; circularity analysis not applicable
full rationale
The provided abstract and description contain no equations, models, fitted parameters, predictions, or derivation steps of any kind. The central claim is a high-level statement that a hybrid framework exists which optimizes annotation via misalignment prediction, but supplies zero technical mechanism, features, training details, or self-citations that could reduce to inputs by construction. With no load-bearing steps to inspect, the paper has no derivation chain and exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robinson,Deeper Than Reason: Emotion and Its Role in Literature, Music, and Art
J. Robinson,Deeper Than Reason: Emotion and Its Role in Literature, Music, and Art. Oxford University Press, 2005
2005
-
[2]
A survey on multimodal music emotion recognition,
R. Liyanarachchi, A. Joshi, and E. Meijering, “A survey on multimodal music emotion recognition,”arXiv:2504.18799, 2025
-
[3]
When words matter: A cross- cultural perspective on lyrics and their relationship to musical emotions,
G. T. Barradas and L. S. Sakka, “When words matter: A cross- cultural perspective on lyrics and their relationship to musical emotions,” Psychology of Music, vol. 50, no. 2, pp. 650–669, 2022
2022
-
[4]
How does music evoke emotions? Exploring the underlying mechanisms,
P. N. Juslin, S. Liljestr ¨om, D. V ¨astfj¨all, and L.-O. Lundqvist, “How does music evoke emotions? Exploring the underlying mechanisms,” inHandbook of Music and Emotion: Theory, Research, Applications. Oxford University Press, 01 2010, pp. 605–642
2010
-
[5]
Investigating societal biases in a poetry composition system,
E. Sheng and D. Uthus, “Investigating societal biases in a poetry composition system,”arXiv 2011.02686, 2020
-
[6]
Naive Bayes classifiers for music emotion classification based on lyrics,
Y . An, S. Sun, and S. Wang, “Naive Bayes classifiers for music emotion classification based on lyrics,” inIEEE/ACIS International Conference on Computer and Information Science (ICIS), 2017, pp. 635–638
2017
-
[7]
Thayer,The Biopsychology of Mood and Arousal
R. Thayer,The Biopsychology of Mood and Arousal. Oxford Academic, 1989
1989
-
[8]
An analysis of music lyrics by measuring the distance of emotion and sentiment,
J. Choi, J.-H. Song, and Y . Kim, “An analysis of music lyrics by measuring the distance of emotion and sentiment,” inIEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), 2018, pp. 176– 181
2018
-
[9]
Crowdsourcing a word–emotion association lexicon,
S. M. Mohammad and P. D. Turney, “Crowdsourcing a word–emotion association lexicon,”Computational Intelligence, vol. 29, no. 3, pp. 436– 465, 2013
2013
-
[10]
Emotion4MIDI: A lyrics-based emotion-labeled symbolic music dataset,
S. Sulun, P. Oliveira, and P. Viana, “Emotion4MIDI: A lyrics-based emotion-labeled symbolic music dataset,” inProgress in Artificial Intelligence, N. Moniz, Z. Vale, J. Cascalho, C. Silva, and R. Sebasti ˜ao, Eds. Springer Nature, 2023, pp. 77–89
2023
-
[11]
EMOPIA: A multi-modal pop piano dataset for emotion recognition and emotion-based music generation,
H.-T. Hung, J. Ching, S. Doh, N. Kim, J. Nam, and Y .-H. Yang, “EMOPIA: A multi-modal pop piano dataset for emotion recognition and emotion-based music generation,”arXiv 2108.01374, 2021
-
[12]
GoEmotions: A dataset of fine-grained emotions,
D. Demszky, D. Movshovitz-Attias, J. Ko, A. Cowen, G. Nemade, and S. Ravi, “GoEmotions: A dataset of fine-grained emotions,”arXiv 2005.00547, 2020
-
[13]
LyEmoBERT: Classification of lyrics’ emotion and recommendation using a pre-trained model,
R. Vr, A. Pillai, and F. Daneshfar, “LyEmoBERT: Classification of lyrics’ emotion and recommendation using a pre-trained model,”Procedia Computer Science, vol. 218, pp. 1196–1208, 01 2023
2023
-
[14]
Transformer-based approach towards music emotion recognition from lyrics,
Y . Agrawal, R. G. R. Shanker, and V . Alluri, “Transformer-based approach towards music emotion recognition from lyrics,” inAdvances in Information Retrieval, 2021, pp. 167–175
2021
-
[15]
Tollywood Emotions: Annotation of valence-arousal in Telugu song lyrics,
R. G. R. Shanker, B. M. Gupta, B. Koushik, and V . Alluri, “Tollywood Emotions: Annotation of valence-arousal in Telugu song lyrics,”arXiv 2303.09364, 2023
-
[16]
Multimodal music mood classification using audio and lyrics,
C. Laurier, J. Grivolla, and P. Herrera, “Multimodal music mood classification using audio and lyrics,” inInternational Conference on Machine Learning and Applications (ICMLA). IEEE, 2008, p. 693
2008
-
[17]
LDA based emotion recognition from lyrics,
K. Dakshina and R. Sridhar, “LDA based emotion recognition from lyrics,” inAdvanced Computing, Networking and Informatics, vol. 1, 2014, pp. 187–194
2014
-
[18]
A study on emotion identification from music lyrics,
A. Ara and R. Gopalakrishna, “A study on emotion identification from music lyrics,” inInnovative Systems for Intelligent Health Informatics. Springer International Publishing, 2021, vol. 72, pp. 396–406
2021
-
[19]
Multi-emotion classification for song lyrics,
D. Edmonds and J. Sedoc, “Multi-emotion classification for song lyrics,” inWorkshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Apr. 2021, pp. 221–235
2021
-
[20]
MERGE – A bimodal dataset for static music emotion recognition,
P. L. Louro, H. Redinho, R. Santos, R. Malheiro, R. Panda, and R. P. Paiva, “MERGE – A bimodal dataset for static music emotion recognition,” arXiv 2407.06060, 2025
-
[21]
Salton,The SMART Retrieval System—Experiments in Automatic Document Processing
G. Salton,The SMART Retrieval System—Experiments in Automatic Document Processing. Prentice-Hall, 1971
1971
-
[22]
Lyric text mining in music mood classification,
X. Hu, J. Downie, and A. Ehmann, “Lyric text mining in music mood classification,” inInternational Society for Music Information Retrieval Conference (ISMIR), 01 2009, pp. 411–416
2009
-
[23]
Developing a benchmark for emotional analysis of music,
A. Aljanaki, Y .-H. Yang, and M. Soleymani, “Developing a benchmark for emotional analysis of music,”PLoS One, vol. 12, no. 3, p. e0173392, 2017
2017
-
[24]
The PMEmo dataset for music emotion recognition,
K. Zhang, H. Zhang, S. Li, C. Yang, and L. Sun, “The PMEmo dataset for music emotion recognition,” inInternational Conference on Multimedia Retrieval (ICMR). Association for Computing Machinery, 2018, p. 135–142
2018
-
[25]
A circumplex model of affect,
J. Russell, “A circumplex model of affect,”Journal of Personality and Social Psychology, vol. 39, no. 6, pp. 1161–1178, 1980
1980
-
[26]
Norms of valence, arousal, and dominance for 13,915 English lemmas,
A. Warriner, V . Kuperman, and M. Brysbaert, “Norms of valence, arousal, and dominance for 13,915 English lemmas,”Behavior Research Methods, vol. 45, pp. 1191–1207, 2013
2013
-
[27]
Literal and metaphorical sense identification through concrete and abstract context,
P. Turney, Y . Neuman, D. Assaf, and Y . Cohen, “Literal and metaphorical sense identification through concrete and abstract context,” inProceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, R. Barzilay and M. Johnson, Eds. Edinburgh, Scotland, UK.: Association for Computational Linguistics, Jul. 2011, pp. 680–690
2011
-
[28]
V ADER: A parsimonious rule-based model for sentiment analysis of social media text,
C. Hutto and E. Gilbert, “V ADER: A parsimonious rule-based model for sentiment analysis of social media text,” inAAAI Conference on Weblogs and Social Media (ICWSM), vol. 8, 2014, pp. 216–225
2014
-
[29]
A new ANEW: Evaluation of a word list for sentiment analysis in microblogs
F. A. Nielsen, “A new ANEW: Evaluation of a word list for sentiment analysis in microblogs,”arXiv:1103.2903, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[30]
The relationship of lexical richness to the quality of ESL learners’ oral narratives,
X. Lu, “The relationship of lexical richness to the quality of ESL learners’ oral narratives,”The Modern Language Journal, vol. 96, no. 2, pp. 190– 208, 2012. 13
2012
-
[31]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,”arXiv 1908.10084, 2019. APPENDIX A. Prompt Engineering Sensitivity Analysis To address the impact of prompt engineering on model output, we evaluated our baseline prompt against three variants. These were tested on a representative subset of 100 lyrical segments u...
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[32]
Variant A (Simplified):A minimalist prompt (Listing
-
[33]
removing all semantic anchors to test the models’ inherent bias without guidance
-
[34]
clinical musicologist
Variant B (Persona):A prompt (Listing 3) framing the LLM as a “clinical musicologist” to test if specialized personas shift the affective interpretation
-
[35]
<Lyric line here>
Variant C (Few-Shot):A prompt (Listing 4) providing three specific lyric-score pairs to test the impact of contextual priming. Listing 2. Variant A: Simplified Prompt Template Input: "<Lyric line here>" Instruction: Provide Valence and Arousal values between -1 and 1 for this lyric. Valence is pleasure/displeasure; Arousal is energy/calm. Output: [Valence...
-
[36]
predictive routing
Sensitivity Results:From the results of these prompt variants (Table X), we see that while the absolute values showed minor fluctuations (Mean Absolute Deviation ≈ 0.14), the intermodel consensusremained high. Crucially, the “predictive routing” logic, which relies on agreement between models, remained stable across all prompt types, demonstrating the fra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.