The Complexity Ceiling Benchmark: A Multi-Domain Evaluation of Sequential Reasoning Under Depth Scaling
Pith reviewed 2026-06-30 07:35 UTC · model grok-4.3
The pith
Sequential reasoning success in language models decays geometrically with added depth but hits sharply different ceilings by task domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
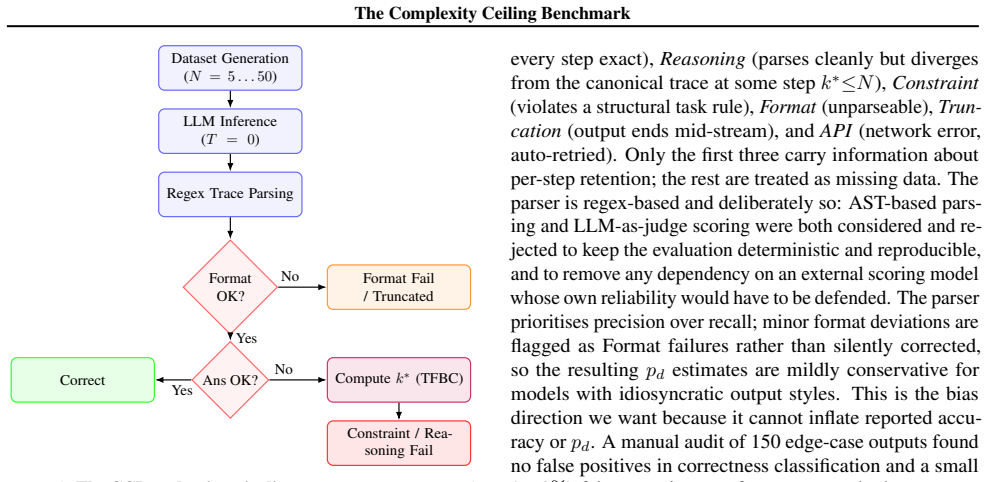
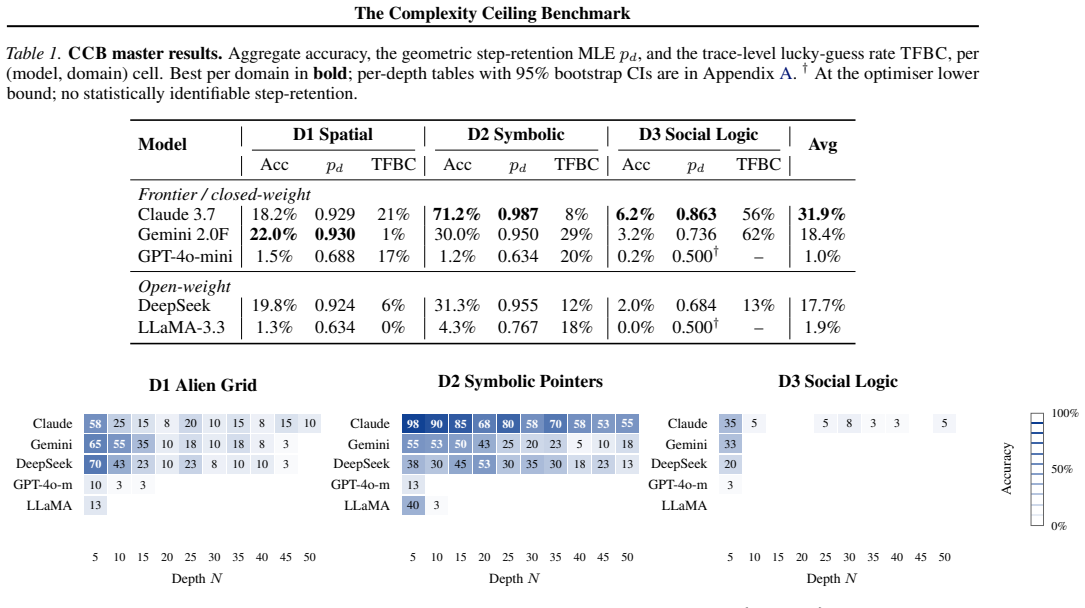
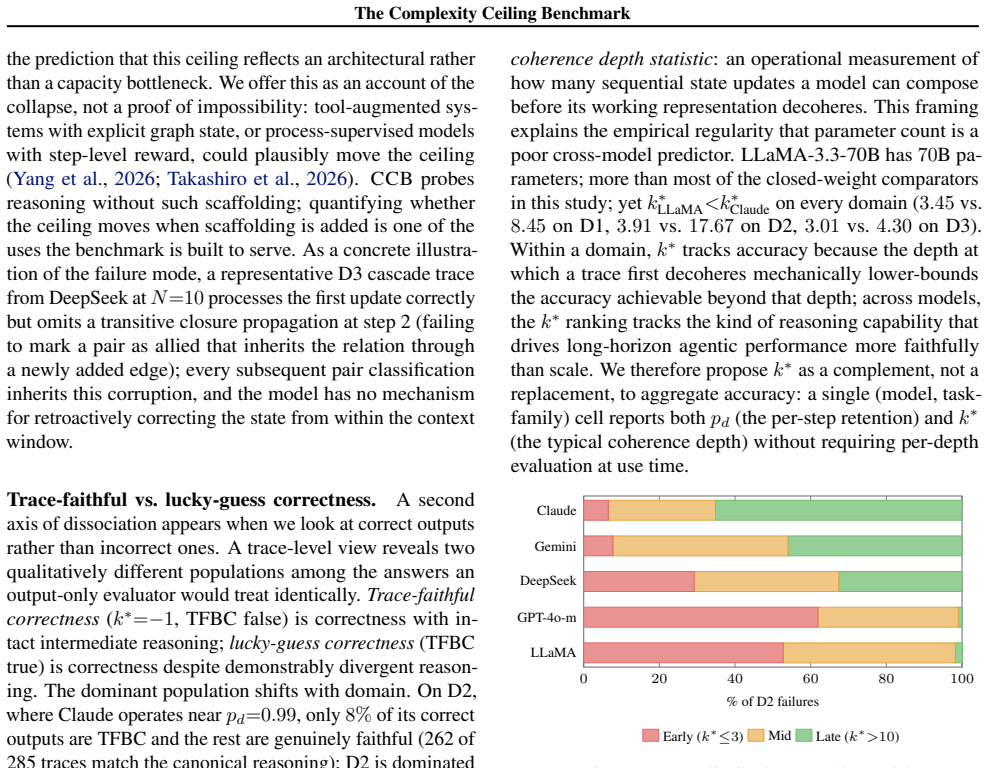
The Complexity Ceiling Benchmark isolates sequential depth N while holding semantics constant across grounded spatial state-tracking, abstract symbolic pointer manipulation, and transitive relational inference. Across 6000 trials the data exhibit geometric per-step decay, with the strongest models retaining pd greater than 0.92 to N=50 on the first two regimes and every model collapsing by N=5 on the third (best-model H0.5 approximately 4.7 steps). Fourteen point five percent of correct answers arise from incorrect intermediates; forcing verbose state tracking leaves ceilings unchanged, and the mean divergence step k-star predicts within-domain accuracy more reliably than parameter count. Th
What carries the argument
The Complexity Ceiling Benchmark (CCB), which holds task semantics fixed while scaling only the required sequential depth N across three structurally distinct regimes to expose per-step accuracy decay.
If this is right
- Strong models maintain greater than 92 percent accuracy on spatial state-tracking and symbolic pointer tasks out to 50 steps.
- Every tested model collapses below usable accuracy by N=5 on transitive relational inference, with the best 50-percent horizon at roughly 4.7 steps.
- Fourteen point five percent of correct final answers are reached through incorrect intermediate reasoning steps.
- Forcing verbose state tracking produces no measurable lift in any regime.
- The first step at which reasoning diverges predicts accuracy within each domain better than model parameter count.
Where Pith is reading between the lines
- The separated ceilings suggest that relational inference may require different internal mechanisms than spatial or symbolic tracking, independent of scale.
- If the geometric decay pattern generalizes, training objectives that penalize early divergence could raise the observed horizons without architectural overhaul.
- The single-number summary per domain offers a compact way to compare new models or fine-tunes on long-horizon capability.
- Extending the benchmark to hybrid tasks that blend the three regimes could reveal whether the weakest ceiling dominates when domains are combined.
Load-bearing premise
Varying only the depth N while fixing semantic content isolates the impact of sequential reasoning depth without introducing confounding factors from task semantics or structure.
What would settle it
A model that sustains greater than 50 percent success on the transitive relational inference regime at N=10 or beyond, with all other task elements unchanged, would falsify the reported domain ceiling.
Figures



read the original abstract
We introduce the Complexity Ceiling Benchmark (CCB), a controlled evaluation of how language-model reasoning decays as the number of required sequential steps grows. CCB fixes the semantic content of a task and varies only its depth N in {5,...,50} across three structurally distinct regimes: grounded spatial state-tracking, abstract symbolic pointer manipulation, and transitive relational inference. Across 6,000 trials over five frontier and open-weight LLMs we find a consistent pattern of geometric per-step decay with widely separated domain ceilings: on the first two regimes the strongest models retain pd>0.92 across N=50; on the third every model collapses by N=5, with the best model's 50%-success horizon at H0.5~4.7 steps despite pd=0.863. A trace-level metric (TFBC) shows that 14.5% of correct answers across the benchmark are reached via incorrect intermediate reasoning. Forced verbose state-tracking does not move the ceiling (McNemar p=1.000), and the mean step at which reasoning first diverges, k*, predicts within-domain accuracy better than parameter count. CCB and the geometric decay model together reduce a model's long-horizon reasoning profile to one interpretable number per task family.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Complexity Ceiling Benchmark (CCB) to evaluate LLM sequential reasoning decay as depth N increases from 5 to 50 across three regimes (grounded spatial state-tracking, abstract symbolic pointer manipulation, transitive relational inference) while claiming to fix semantic content. From 6000 trials on five frontier and open-weight models, it reports consistent geometric per-step decay with domain ceilings: pd > 0.92 retained up to N=50 in the first two regimes, but collapse by N=5 in the third (best-model H0.5 ≈ 4.7 despite pd=0.863). Additional results include a trace-level TFBC metric (14.5% of correct answers via incorrect intermediates), no effect from forced verbose state-tracking (McNemar p=1.000), and mean first-divergence step k* outperforming parameter count as an accuracy predictor. The benchmark plus geometric model reduces long-horizon profiles to one interpretable number per task family.
Significance. If the isolation of depth from semantic or structural changes holds, CCB would supply a controlled, multi-domain method for quantifying per-step reliability and ceilings in sequential reasoning, with the geometric model providing compact, interpretable descriptors. The scale (6000 trials, five models) and introduction of a trace metric (TFBC) are empirical strengths that could support reproducible benchmarking of long-horizon capabilities.
major comments (2)
- [Abstract] Abstract: The claim that CCB 'fixes the semantic content of a task and varies only its depth N' is load-bearing for interpreting pd and H0.5 as measures of pure sequential depth ceilings. The three regimes (spatial state-tracking, symbolic pointers, transitive inference) may embed additional predicates, objects, or higher-arity relations at larger N to support longer chains; without explicit verification that base facts and entity sets remain constant across N, the observed ceilings could partly reflect semantic scaling rather than depth alone.
- [Abstract] Abstract (geometric decay model and H0.5): The 50%-success horizon H0.5 is obtained by fitting the geometric per-step decay model to the observed performance data per domain. This renders the reported ceilings post-hoc quantities derived from the same trials rather than independent predictions, weakening the claim that the model 'predicts' long-horizon behavior.
minor comments (2)
- [Abstract] Abstract: The McNemar test result (p=1.000) is reported without stating the paired comparison, sample size, or exact conditions under which forced verbose state-tracking was evaluated.
- [Abstract] Abstract: The TFBC metric is introduced and a quantitative result (14.5%) is given, but its precise definition, computation from traces, and relation to standard accuracy are not specified.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that CCB 'fixes the semantic content of a task and varies only its depth N' is load-bearing for interpreting pd and H0.5 as measures of pure sequential depth ceilings. The three regimes (spatial state-tracking, symbolic pointers, transitive inference) may embed additional predicates, objects, or higher-arity relations at larger N to support longer chains; without explicit verification that base facts and entity sets remain constant across N, the observed ceilings could partly reflect semantic scaling rather than depth alone.
Authors: We agree that explicit verification of constant semantic content is required to support the interpretation of pd and H0.5. The benchmark construction holds base facts, entity sets, and predicates fixed while increasing only chain length N (for instance, fixed initial objects and relations with added sequential moves or inferences). This was not stated with sufficient detail in the abstract or methods. We will revise the abstract to qualify the claim and add a methods subsection with construction examples confirming constant semantics across N=5 to 50. revision: yes
-
Referee: [Abstract] Abstract (geometric decay model and H0.5): The 50%-success horizon H0.5 is obtained by fitting the geometric per-step decay model to the observed performance data per domain. This renders the reported ceilings post-hoc quantities derived from the same trials rather than independent predictions, weakening the claim that the model 'predicts' long-horizon behavior.
Authors: The referee correctly observes that H0.5 is obtained by fitting the geometric model to the empirical data from the 6000 trials. The model is used as a descriptive summary of per-step decay to yield the compact horizon metric, not as an independent predictor for unseen depths. The abstract does not claim out-of-sample prediction, but the wording could be misread. We will revise the abstract and discussion to explicitly describe the model as a post-hoc characterization tool rather than a predictive one. revision: partial
Circularity Check
No significant circularity; empirical observations are self-contained.
full rationale
The paper reports direct empirical measurements from 6,000 trials on five LLMs across controlled depth variations in three regimes. The geometric per-step decay pattern and derived quantities such as H0.5 are presented as observed outcomes from the success rates pd at each N, not as a fitted model whose parameters are then used to 'predict' the same data by construction. No equations, self-citations, or ansatzes are shown reducing the central claims to inputs. The isolation of depth N while fixing semantics is a methodological premise, not derived from the results. The derivation chain remains independent of the reported findings.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-step success probability pd
- 50%-success horizon H0.5
invented entities (1)
-
TFBC (trace-level metric)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Quantifying consistency in LLM logical reason- ing via structural uncertainty
B Chaudhury, M F Wang, H H Park, R Ghosh, S Hong, and J O Woo. Quantifying consistency in LLM logical reason- ing via structural uncertainty. InICLR 2026 Workshop on Logical Reasoning of Large Language Models,
2026
-
[2]
Training Verifiers to Solve Math Word Problems
Best Paper Award. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2212.07919 , year=
Olga Golovneva, Moya Chen, Spencer Poff, Martin Corre- dor, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Roscoe: A suite of metrics for scoring step-by-step reasoning.arXiv preprint arXiv:2212.07919,
-
[4]
Dengzhe Hou, Lingyu Jiang, Deng Li, Zirui Li, Fangzhou Lin, and Kazunori D. Yamada. Wmf-am: Probing llm working memory via depth-parameterized cumulative state tracking.arXiv preprint arXiv:2603.27343,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Archiki Prasad, Swarnadeep Saha, Xiang Zhou, and Mo- hit Bansal
URL https://arxiv.org/abs/2603.12133. Archiki Prasad, Swarnadeep Saha, Xiang Zhou, and Mo- hit Bansal. Receval: Evaluating reasoning chains via correctness and informativeness.arXiv preprint arXiv:2304.10703,
-
[6]
Gianni Pellegrini Sebastiano Monti, Carlo Nicolini et al. SokoBench: Evaluating long-horizon planning and reasoning in large language models.arXiv preprint arXiv:2601.20856,
-
[7]
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in llms.arXiv preprint arXiv:2509.09677,
- [8]
-
[9]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, et al. Beyond the imitation game: Quan- tifying and extrapolating the capabilities of language mod- els.arXiv preprint arXiv:2206.04615,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Thinking While Listening: Fast-Slow Recurrence for Long-Horizon Sequential Modeling
Shota Takashiro, Masanori Koyama, Takeru Miyato, Yusuke Iwasawa, Yutaka Matsuo, and Kohei Hayashi. Thinking while listening: Fast-slow recurrence for long-horizon sequential modelling.arXiv preprint arXiv:2604.01577,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Recursive models for long-horizon reasoning
Chenxiao Yang, Nathan Srebro, and Zhiyuan Li. Recur- sive models for long-horizon reasoning.arXiv preprint arXiv:2603.02112,
-
[12]
tests multi-hop relational reasoning on kinship graphs and is the closest prior work to D3. CCB extends that line by providing deterministic ground-truth traces (not only final answers), enabling TFBC-level diagnostics; by applying a continuous depth axis from N=5 to N=50; and by integrat- ing relational inference with spatial and symbolic regimes under a...
2023
-
[13]
Chaudhury et al
introduces precision and re- call metrics for multimodal chain-of-thought. Chaudhury et al. (2026) show that unstable self-preference rankings sig- nal unreliable inference. CCB provides a complementary, ground-truth-grounded operationalisation that requires no LLM-as-judge. Process supervision and long-horizon execution. Process-supervised models (Cobbe et al.,
2026
-
[14]
Sinha et al
are trained with step-level reward signals that incentivise intermediate-state correctness; their evaluation is the most consequential extension of this work. Sinha et al. (2025) analytically links per-step accuracy to an effective task 11 The Complexity Ceiling Benchmark horizon Hs≈ln(s)/ln(p d); CCB’s empirical pd values feed directly into that framewor...
2025
-
[15]
(2025) argue that autoregressive token ordering is itself an inductive bias on accessible reasoning patterns
target the same state-management bottleneck from the architecture side, and Kim et al. (2025) argue that autoregressive token ordering is itself an inductive bias on accessible reasoning patterns. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.