AMR: Adaptive Modality Routing for Multimodal Polyglot Speaker Identification
Pith reviewed 2026-06-30 08:21 UTC · model grok-4.3
The pith
A trainable router dynamically weights audio and face embeddings per sample to reach 99 percent average accuracy in polyglot speaker identification despite missing modalities or language shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
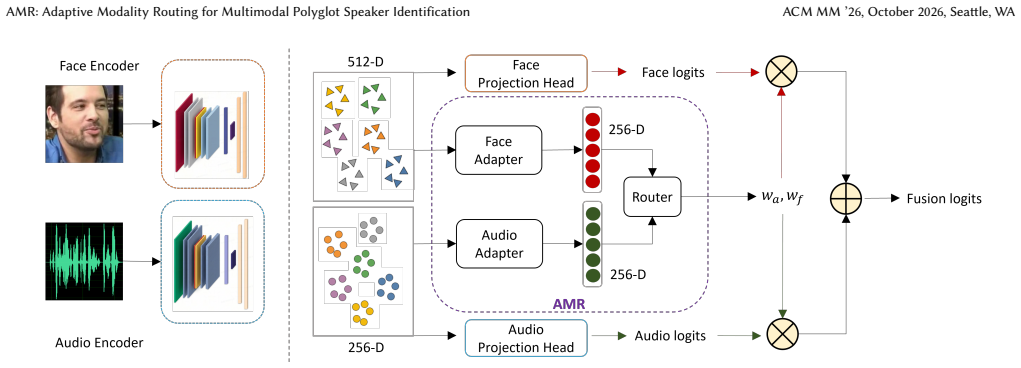
The central claim is that Adaptive Modality Routing, which employs two modality adapters on embeddings from W2V-BERT 2.0 and IResNet-18 followed by a trainable router that produces dynamic modality weights, can be optimized via a modality-aware training strategy of four sample-pair types supervised by KL divergence, thereby handling missing modalities and language mismatch to deliver identification accuracies of 99.93 percent (English multimodal), 100.00 percent (Urdu multimodal), 97.50 percent (English audio-only), and 98.83 percent (Urdu audio-only) with an average of 99.07 percent on the POLY-SIM 2026 evaluation set.
What carries the argument
Adaptive Modality Routing (AMR), a fusion module that uses modality adapters to produce adapted embeddings and a trainable router to estimate per-sample dynamic modality weights for aggregating modality-specific logits.
If this is right
- The router produces weights that adapt to the quality of each input sample rather than using fixed fusion rules.
- Simulating missing modalities through the four pair types during training yields robustness to audio-only or visual-only test conditions.
- KL divergence supervision directly shapes the router outputs to match desired weight distributions for each pair type.
- The same architecture and training procedure delivers high accuracy for both English and Urdu test conditions without language-specific retraining.
Where Pith is reading between the lines
- The same routing idea could be applied to other modality pairs such as audio plus text for tasks where one stream is intermittently unreliable.
- Because the router operates on adapted embeddings rather than raw signals, it may allow swapping in newer encoders without redesigning the fusion logic.
- In practice the method could reduce the engineering cost of maintaining separate models for every possible combination of available sensors.
Load-bearing premise
The modality-aware training strategy that constructs four types of sample pairs and uses KL divergence as supervision will produce router weights that generalize to unseen real-world conditions beyond the specific POLY-SIM 2026 evaluation protocols and datasets.
What would settle it
Evaluating the trained router on a fresh test set recorded in a third language or with different ambient noise profiles and checking whether average accuracy falls substantially below the reported 99.07 percent.
Figures
read the original abstract
Multimodal speaker identification systems face two key challenges in real-world deployment: missing modalities and language mismatch between training and testing conditions. In practical scenarios, background multi-speaker conversations, ambient noise, and overlapping speech further degrade identification accuracy. To address these challenges, we propose a multimodal polyglot speaker identification system for the POLY-SIM 2026 Grand Challenge. The system is fundamentally built upon Adaptive Modality Routing(AMR), a modality fusion module that dynamically assesses per-sample input quality and integrates modality information. Specifically, AMR employs two modality adapters to process the embeddings extracted from a linguistically robust audio encoder(W2V-BERT 2.0) and a large-scale pretrained face encoder(IResNet-18), producing modality-adapted embeddings. Based on these adapted embeddings, a trainable router estimates dynamic modality weights, which are subsequently applied to aggregate the modality-specific logits for the final prediction. To optimize this routing mechanism, we adopt a modality-aware training strategy that constructs four types of sample pairs to simulate diverse input conditions, with KL divergence serving as explicit supervision for weight assignment. Experimental results on the POLY-SIM 2026 evaluation set show that the proposed system achieves identification accuracy of 99.93%(English multimodal, P3), 100.00%(Urdu multimodal, P5), 97.50%(English audio-only, P4), and 98.83%(Urdu audio-only, P6). The average accuracy across all four protocols is 99.07%, surpassing the Fusion and Orthogonal Projection(FOP) baseline by 32.73%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Modality Routing (AMR), a modality fusion module for multimodal polyglot speaker identification that dynamically assesses per-sample input quality using two modality adapters (for W2V-BERT 2.0 audio and IResNet-18 face embeddings) and a trainable router to produce dynamic modality weights. These weights aggregate modality-specific logits. A modality-aware training strategy constructs four types of sample pairs to simulate diverse conditions, using KL divergence as supervision for the router. On the POLY-SIM 2026 evaluation set, the system reports accuracies of 99.93% (English multimodal, P3), 100.00% (Urdu multimodal, P5), 97.50% (English audio-only, P4), and 98.83% (Urdu audio-only, P6), averaging 99.07% and surpassing the Fusion and Orthogonal Projection (FOP) baseline by 32.73%.
Significance. If the numerical claims hold under proper verification, AMR could advance robust multimodal speaker identification by addressing missing modalities and language mismatch in polyglot settings. The reported performance gap over the FOP baseline on multiple protocols would indicate practical value for real-world deployment involving noise and overlapping speech, provided the router generalizes beyond the specific training distribution.
major comments (3)
- [Abstract] Abstract: The identification accuracies (99.93%, 100.00%, 97.50%, 98.83%) and the 32.73% baseline gap are reported without error bars, standard deviations, confidence intervals, or the number of independent runs, which is load-bearing for assessing whether the results reliably support the central claim of superiority.
- [Abstract] Abstract: The modality-aware training strategy constructs four types of sample pairs whose KL-divergence supervision is derived from the same data distribution used for the POLY-SIM 2026 evaluation protocols; this creates a potential circularity in which the router weights are fitted rather than independently derived, directly affecting the generalization claim.
- [Abstract] Abstract: No ablation results, hyperparameter sensitivity analysis, or verification that the four-pair construction and KL supervision were not tuned post-hoc to the evaluation set are provided, leaving the attribution of the performance improvement to the AMR module unverified.
minor comments (1)
- [Abstract] Abstract: Inconsistent spacing around acronyms (e.g., 'Adaptive Modality Routing(AMR)' and 'Fusion and Orthogonal Projection(FOP)') reduces readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help strengthen the presentation of our work. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The identification accuracies (99.93%, 100.00%, 97.50%, 98.83%) and the 32.73% baseline gap are reported without error bars, standard deviations, confidence intervals, or the number of independent runs, which is load-bearing for assessing whether the results reliably support the central claim of superiority.
Authors: We agree that statistical variability measures are necessary to support claims of superiority. In the revised manuscript we will report mean performance and standard deviation across five independent training runs with different random seeds for all four protocols and the FOP baseline comparison. revision: yes
-
Referee: [Abstract] Abstract: The modality-aware training strategy constructs four types of sample pairs whose KL-divergence supervision is derived from the same data distribution used for the POLY-SIM 2026 evaluation protocols; this creates a potential circularity in which the router weights are fitted rather than independently derived, directly affecting the generalization claim.
Authors: The four pair types are generated exclusively from the training split to simulate modality dropout and quality variation. KL targets are computed from modality-quality indicators on those training samples only. The POLY-SIM 2026 protocols (P3–P6) consist of held-out test utterances; no evaluation samples or labels are used during router training. We will add an explicit data-flow diagram and statement of train/test separation in the revised methods section. revision: partial
-
Referee: [Abstract] Abstract: No ablation results, hyperparameter sensitivity analysis, or verification that the four-pair construction and KL supervision were not tuned post-hoc to the evaluation set are provided, leaving the attribution of the performance improvement to the AMR module unverified.
Authors: We will include a new ablation subsection that removes the router, the modality adapters, and the KL term individually, together with a hyperparameter sweep on the KL weight and the number of pair types. All design choices were finalized on a training-set validation split before any test-set evaluation; we will state this explicitly and report the validation-based selection procedure. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical system (AMR with modality adapters, trainable router, and KL-supervised modality-aware training on constructed pairs) and reports held-out accuracies on the POLY-SIM 2026 evaluation protocols (P3/P4/P5/P6) plus a direct numerical comparison to the external FOP baseline. No derivation chain, equations, or first-principles claim is offered that reduces any result to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes appear in the supplied text. The training/evaluation split and external baseline comparison keep the central performance claim independent of the architecture description.
Axiom & Free-Parameter Ledger
free parameters (1)
- router weights
axioms (1)
- domain assumption Embeddings from W2V-BERT 2.0 and IResNet-18 are sufficiently rich to be adapted into a common space for routing decisions.
invented entities (1)
-
Adaptive Modality Routing (AMR) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representa- tions. InAnnual Conference on Neural Information Processing Systems (NeurIPS). 12449–12460
2020
-
[2]
Hervé Bredin, Ruiqing Yin, Juan Manuel Coria, Gregory Gelly, Pavel Korshunov, Marvin Lavechin, Diego Fustes, Hadrien Titeux, Wassim Bouaziz, and Marie- Philippe Gill. 2020. Pyannote.Audio: Neural Building Blocks for Speaker Diariza- tion. InIEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP). 7124–7128
2020
-
[3]
Wuyang Chen, Yanjie Sun, Kele Xu, and Yong Dou. 2024. FAME Audio-Visual Team System Description. Available at https://github.com/mavceleb/mavceleb_ baseline/blob/main/description_files/2audioVisual.pdf
2024
-
[4]
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. 2018. VoxCeleb2: Deep Speaker Recognition. In19th Annual Conference of the International Speech Communication Associationn (INTERSPEECH). 1086–1090
2018
-
[5]
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. 2021. W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training. InIEEE Automatic Speech Recognition and Understanding Workshop (ASRU). 244–250
2021
-
[6]
Jun Dan, Yang Liu, Haoyu Xie, Jiankang Deng, Haoran Xie, Xuansong Xie, and Baigui Sun. 2023. TransFace: Calibrating Transformer Training for Face Recogni- tion from a Data-Centric Perspective. InIEEE International Conference on Com- puter Vision (ICCV). 20585–20596
2023
-
[7]
Najim Dehak, Patrick Kenny, Réda Dehak, Pierre Dumouchel, and Pierre Ouellet
-
[8]
Front-End Factor Analysis for Speaker Verification.IEEE Transactions on Audio, Speech, and Language Processing (TASLP)19, 4 (2011), 788–798
2011
-
[9]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4690–4699
2019
-
[10]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. 2020. ECAPA- TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. In21st Annual Conference of the International Speech Communication Association (INTERSPEECH). 3830–3834
2020
-
[11]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, Keyu An, Guanrou Yang, Yabin Li, Yanni Chen, Zhifu Gao, Qian Chen, Yue Gu, Mengzhe Chen, Yafeng Chen, Shiliang Zhang, Wen Wang, and Jieping Ye. 2025. CosyVoice 3: Towards In- the-wild Speech Generation via Scaling-up and Post-training.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
FireRedTeam. 2024. FireRedVAD: State-of-the-Art Industrial-Grade Voice Activity Detection. GitHub repository. Available at https://github.com/FireRedTeam/ FireRedVAD
2024
-
[13]
Abdul Hannan, Muhammad Arslan Manzoor, Shah Nawaz, Muhammad Irzam Liaqat, Markus Schedl, and Mubashir Noman. 2025. PAEFF: Precise Alignment and Enhanced Gated Feature Fusion for Face-Voice Association. In26th Annual Conference of the International Speech Communication Association (INTERSPEECH). 2710–2714
2025
-
[14]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778
2016
-
[15]
Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-Excitation Networks. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 7132–7141
2018
-
[16]
Jain, and Xiaoming Liu
Minchul Kim, Anil K. Jain, and Xiaoming Liu. 2022. AdaFace: Quality Adaptive Margin for Face Recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 18729–18738
2022
-
[17]
Yuke Lin, Ming Cheng, Fulin Zhang, Yingying Gao, Shilei Zhang, and Ming Li. 2024. VoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark. In25th Annual Conference of the International Speech Communication Association (INTERSPEECH). 4263–4267
2024
-
[18]
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep Learning Face Attributes in the Wild. InIEEE International Conference on Computer Vision (ICCV). 3730–3738
2015
-
[19]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A ConvNet for the 2020s. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 11966–11976
2022
-
[20]
Qiang Meng, Shichao Zhao, Zhida Huang, and Feng Zhou. 2021. MagFace: A Universal Representation for Face Recognition and Quality Assessment. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 14225–14234
2021
-
[21]
Marta Moscati, Ahmed Abdullah, Muhammad Saad Saeed, Shah Nawaz, Ro- han Kumar Das, Muhammad Zaigham Zaheer, Junaid Mir, Muhammad Haroon Yousaf, Khalid Mahmood Malik, and Markus Schedl. 2026. Linking Faces and Voices Across Languages: Insights from the FAME 2026 Challenge. InIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP...
2026
-
[22]
Marta Moscati, Oleksandr Kats, Mubashir Noman, Muhammad Zaigham Zaheer, Yufang Hou, Markus Schedl, and Shah Nawaz. 2026. Face-Voice Association with Inductive Bias for Maximum Class Separation. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 11797–11801
2026
-
[23]
Marta Moscati, Muhammad Saad Saeed, Marina Zanoni, Mubashir Noman, Ro- han Kumar Das, Monorama Swain, Yufang Hou, Elisabeth André, Khalid Mah- mood Malik, Markus Schedl, and Shah Nawaz. 2026. POLY-SIM: Polyglot Speaker Identification with Missing Modality Grand Challenge 2026 Evaluation Plan. arXiv preprint arXiv:2603.24569(2026)
-
[24]
Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. 2017. VoxCeleb: A Large-Scale Speaker Identification Dataset. In18th Annual Conference of the International Speech Communication Association (INTERSPEECH). 2616–2620
2017
-
[25]
Shah Nawaz, Muhammad Kamran Janjua, Ignazio Gallo, Arif Mahmood, and Alessandro Calefati. 2019. Deep Latent Space Learning for Cross-Modal Mapping of Audio and Visual Signals. In2019 Digital Image Computing: Techniques and Applications (DICTA). 1–7
2019
-
[26]
Shah Nawaz, Muhammad Saad Saeed, Pietro Morerio, Arif Mahmood, Ignazio Gallo, Muhammad Haroon Yousaf, and Alessio Del Bue. 2021. Cross-modal Speaker Verification and Recognition: A Multilingual Perspective. InIEEE Con- ference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops). 1682–1691
2021
-
[27]
Jonas Pfeiffer, Andreas Rücklé, Clifton Poth, Aishwarya Kamath, Ivan Vulic, Sebastian Ruder, Kyunghyun Cho, and Iryna Gurevych. 2020. AdapterHub: A Framework for Adapting Transformers. InProceedings of the 2020 Confer- ence on Empirical Methods in Natural Language Processing: System Demonstra- tions (EMNLP-Demos). 46–54
2020
-
[28]
Muhammad Saad Saeed, Muhammad Haris Khan, Shah Nawaz, Muhammad Ha- roon Yousaf, and Alessio Del Bue. 2022. Fusion and Orthogonal Projection for Improved Face-Voice Association. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 7057–7061
2022
-
[29]
Muhammad Saad Saeed, Shah Nawaz, Muhammad Haris Khan, Muham- mad Zaigham Zaheer, Karthik Nandakumar, Muhammad Haroon Yousaf, and Arif Mahmood. 2023. Single-branch Network for Multimodal Training. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 1–5
2023
-
[30]
Muhammad Saad Saeed, Shah Nawaz, Muhammad Salman Tahir, Rohan Ku- mar Das, Muhammad Zaigham Zaheer, Marta Moscati, Markus Schedl, Muham- mad Haris Khan, Karthik Nandakumar, and Muhammad Haroon Yousaf. 2024. Face-Voice Association in Multilingual Environments (FAME) Challenge 2024. arXiv preprint arXiv:2404.09342(2024)
-
[31]
Saqlain Hussain Shah, Muhammad Saad Saeed, Shah Nawaz, and Muhammad Ha- roon Yousaf. 2023. Speaker Recognition in Realistic Scenario Using Multimodal Data. In3rd International Conference on Artificial Intelligence (ICAI). 209–213
2023
-
[32]
David Snyder, Guoguo Chen, and Daniel Povey. 2015. MUSAN: A Music, Speech, and Noise Corpus.arXiv preprint arXiv:1510.08484(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
David Snyder, Daniel Garcia-Romero, Daniel Povey, and Sanjeev Khudanpur
-
[34]
In18th Annual Conference of the International Speech Communication Association (INTERSPEECH)
Deep Neural Network Embeddings for Text-Independent Speaker Veri- fication. In18th Annual Conference of the International Speech Communication Association (INTERSPEECH). 999–1003
-
[35]
Ruijie Tao, Shi Zhan, Yidi Jiang, Duc-Tuan Truong, Eng-Siong Chng, Massimo Alioto, and Haizhou Li. 2024. HLT System for FAME Challenge 2024. Available at https://github.com/mavceleb/mavceleb_baseline/blob/main/description_files/ 1hlt.pdf
2024
-
[36]
Weiyao Wang, Du Tran, and Matt Feiszli. 2020. What Makes Training Multi- Modal Classification Networks Hard?. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). 12695–12705
2020
- [37]
-
[38]
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, and Zhiyuan Liu. 2025. VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning.arXiv preprint arXiv:2509.24650(2025)
-
[39]
Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jiwen Lu, Dalong Du, and Jie Zhou. 2021. WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 10492–10502
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.