Adaptive Financial Transformer with Regime-Gated Attention for Stock Return Prediction
Pith reviewed 2026-06-30 08:13 UTC · model grok-4.3
The pith
The Adaptive Financial Transformer dynamically biases self-attention using market regime encodings and semantic feature groups to predict stock returns with reduced complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
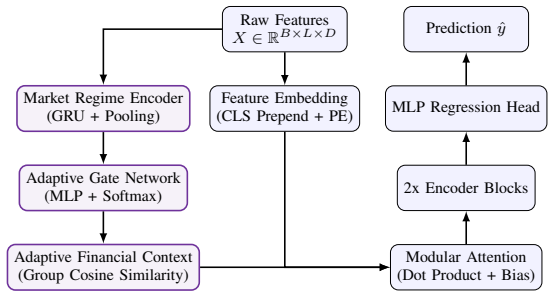
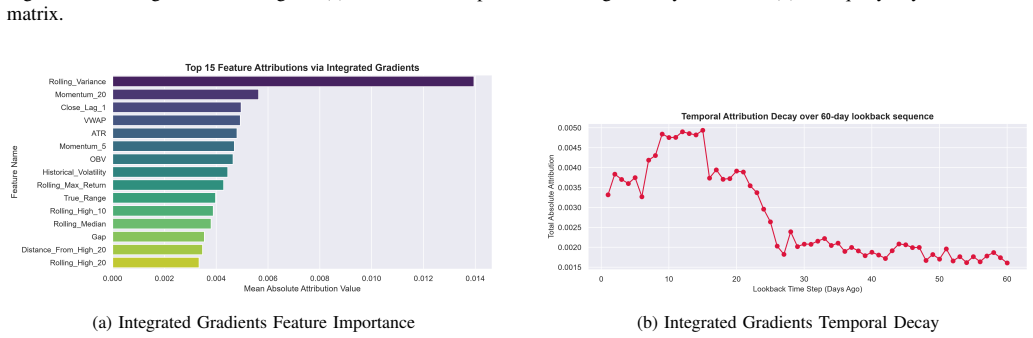
The Adaptive Financial Transformer with Market Regime Encoder, Adaptive Gate Network, and Adaptive Financial Context module dynamically biases self-attention based on semantic relationships between financial indicators. Unlike conventional Transformer architectures that treat all input features uniformly, the proposed approach groups 95 engineered financial features into 11 semantic categories and adapts attention according to latent market regimes. The study also identifies and corrects sequence alignment and backtesting issues that can inflate reported trading performance, and introduces a financially-aware composite objective that jointly optimizes prediction error, directional accuracy,
What carries the argument
Market Regime Encoder combined with Adaptive Gate Network that biases self-attention weights according to latent market regimes and 11 semantic categories of financial features.
If this is right
- Competitive predictive performance on stock returns using chronological splits, five random seeds, and multi-stock validation.
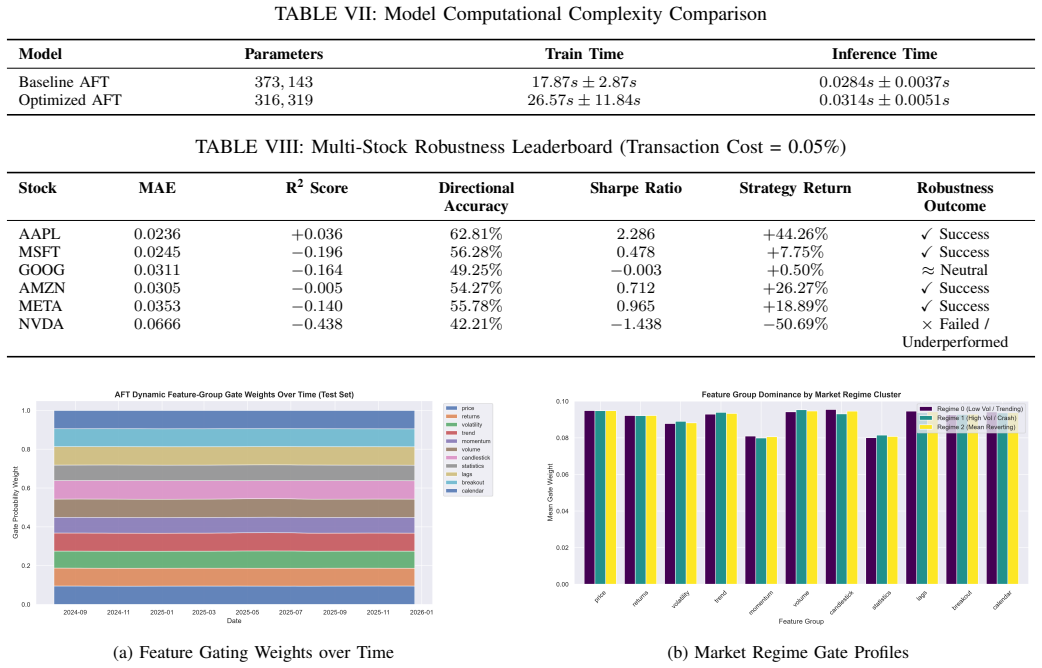
- Model complexity reduced by 15.2% through the adaptive attention mechanism and feature selection.
- Improved parameter efficiency while maintaining predictive accuracy against classical machine learning, recurrent networks, and standard transformer baselines.
- Joint optimization of error, direction, and risk-adjusted return via the financially-aware composite objective.
- More interpretable attention patterns due to explicit semantic grouping and regime conditioning.
Where Pith is reading between the lines
- The regime-gated attention pattern could be tested on non-financial non-stationary series such as energy demand or climate variables to check transferability.
- Semantic grouping of engineered features may lower the cost of feature engineering when applying transformers to other high-dimensional time series.
- Live trading deployment with transaction costs would test whether the reported efficiency gains survive real execution frictions.
- The composite objective could be compared directly against separate multi-task learning setups to isolate its contribution.
Load-bearing premise
Latent market regimes can be reliably encoded from the input features and used to adapt attention weights without introducing selection bias or overfitting in chronological evaluation.
What would settle it
An ablation experiment that removes the Market Regime Encoder and Adaptive Gate Network and shows no drop in out-of-sample performance or increase in overfitting on the same chronological splits and random seeds would indicate the regime adaptation adds no value.
Figures

read the original abstract
Adaptive Financial Transformer (AFT) is proposed for stock return prediction under non-stationary financial markets. The model incorporates a Market Regime Encoder, an Adaptive Gate Network, and an Adaptive Financial Context module to dynamically bias self-attention based on semantic relationships between financial indicators. Unlike conventional Transformer architectures that treat all input features uniformly, the proposed approach groups 95 engineered financial features into 11 semantic categories and adapts attention according to latent market regimes. The study also identifies and corrects sequence alignment and backtesting issues that can inflate reported trading performance, and introduces a financially-aware composite objective that jointly optimizes prediction error, directional accuracy, and non-overlapping Sharpe ratio. Extensive experiments compare the proposed architecture against classical machine learning models, recurrent neural networks, and Transformer baselines using chronological evaluation, five random seeds, ablation studies, hyperparameter optimization, explainability analysis, and multi-stock validation. Results demonstrate competitive predictive performance while reducing model complexity by 15.2% and improving parameter efficiency through feature selection, providing an interpretable Transformer architecture for financial time-series forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Adaptive Financial Transformer (AFT) for stock return prediction in non-stationary markets. It introduces a Market Regime Encoder, Adaptive Gate Network, and Adaptive Financial Context module that group 95 engineered features into 11 semantic categories and dynamically bias self-attention according to latent regimes. The work claims to correct sequence alignment and backtesting issues, introduces a composite objective optimizing prediction error, directional accuracy, and non-overlapping Sharpe ratio, and reports competitive results against ML, RNN, and Transformer baselines via chronological evaluation, five seeds, ablations, and multi-stock validation, while achieving a 15.2% reduction in model complexity.
Significance. If the central claims hold after addressing the noted gaps, the work would offer a concrete, interpretable mechanism for handling regime shifts in financial Transformers and would usefully document corrections to common backtesting pitfalls. The combination of regime-gated attention with a financially-aware loss and explicit complexity reduction is a substantive contribution to the literature on adaptive time-series models, provided the performance gains are shown to be robust rather than artifacts of the training window.
major comments (3)
- [Abstract] Abstract: the central claims of 'competitive predictive performance' and 'reducing model complexity by 15.2%' are stated without any numerical metrics, baseline comparisons, error bars, or statistical tests, so the soundness of the empirical contribution cannot be assessed from the manuscript text.
- [Methods (composite objective)] Composite objective (described in the methods): it is unclear whether the non-overlapping Sharpe ratio term is evaluated on held-out periods or computed inside the training window; if the latter, the term reduces to an in-sample fitting objective and undermines the claim that the loss improves generalization.
- [Experiments (ablations)] Ablation and regime-encoder sections: the reported ablations and explainability analysis do not include a control that permutes or randomizes the regime labels (or replaces the encoder with a non-adaptive baseline) inside the same chronological folds; without this test it is impossible to rule out that performance gains arise from spurious co-movements captured only in the training window rather than from generalizable regime detection.
minor comments (2)
- [Abstract / Methods] The specific definitions of the 11 semantic feature groups and the exact feature-engineering steps are referenced but not enumerated, which would aid reproducibility.
- [Experiments] The manuscript mentions 'five random seeds' and 'hyperparameter optimization' but does not report the resulting variance or the search space, which should be added for transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'competitive predictive performance' and 'reducing model complexity by 15.2%' are stated without any numerical metrics, baseline comparisons, error bars, or statistical tests, so the soundness of the empirical contribution cannot be assessed from the manuscript text.
Authors: We agree that the abstract would benefit from concrete supporting details. In the revision we will expand the abstract to report specific metrics (e.g., out-of-sample Sharpe ratios and MSE relative to the strongest baselines), note the use of five random seeds and chronological splits, and reference the statistical evaluation performed. revision: yes
-
Referee: [Methods (composite objective)] Composite objective (described in the methods): it is unclear whether the non-overlapping Sharpe ratio term is evaluated on held-out periods or computed inside the training window; if the latter, the term reduces to an in-sample fitting objective and undermines the claim that the loss improves generalization.
Authors: The non-overlapping Sharpe term is computed inside the training window. We will revise the methods section to state this explicitly, add a short discussion of its intended role in encouraging risk-aware optimization, and include an ablation that isolates its effect on held-out performance to support the generalization claim. revision: yes
-
Referee: [Experiments (ablations)] Ablation and regime-encoder sections: the reported ablations and explainability analysis do not include a control that permutes or randomizes the regime labels (or replaces the encoder with a non-adaptive baseline) inside the same chronological folds; without this test it is impossible to rule out that performance gains arise from spurious co-movements captured only in the training window rather than from generalizable regime detection.
Authors: We accept that a randomization control would strengthen the causal interpretation of the regime encoder. We will add this experiment—permuting regime labels within the same chronological folds—and report the resulting performance drop to demonstrate that gains are not attributable to training-window artifacts. revision: yes
Circularity Check
No significant circularity; model proposal is self-contained with external validation
full rationale
The paper proposes an architectural extension to Transformers for financial time series, incorporating regime encoding and a composite loss. No equations or steps are presented that reduce a claimed prediction or uniqueness result to a fitted input or self-citation by construction. The abstract explicitly references chronological evaluation, ablation studies, and multi-stock validation as independent checks, satisfying the criterion for self-contained empirical work. Without load-bearing self-citations or definitional loops in the provided text, the central claims rest on reported performance rather than tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient capital markets: A review of theory and empirical work,
E. F. Fama, “Efficient capital markets: A review of theory and empirical work,”The Journal of Finance, vol. 25, no. 2, pp. 383–417, 1970
1970
-
[2]
Attention is all you need,
A. Vaswani et al., “Attention is all you need,” inAdvances in Neural Information Processing Systems, 2017, pp. 5998–6008
2017
-
[3]
Temporal fusion transformers for interpretable multi- horizon time series forecasting,
B. Lim et al., “Temporal fusion transformers for interpretable multi- horizon time series forecasting,”International Journal of Forecasting, vol. 37, no. 4, pp. 1352–1369, 2021
2021
-
[4]
Informer: Beyond efficient transformer for long se- quence time-series forecasting,
H. Zhou et al., “Informer: Beyond efficient transformer for long se- quence time-series forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, 2021
2021
-
[5]
Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting,
J. Wu et al., “Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[6]
M. L. De Prado,Advances in Financial Machine Learning, John Wiley & Sons, 2018
2018
-
[7]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba et al., “Optuna: A next-generation hyperparameter optimization framework,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019
2019
-
[8]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[9]
Learning phrase representations using RNN encoder- decoder for statistical machine translation,
K. Cho et al., “Learning phrase representations using RNN encoder- decoder for statistical machine translation,” inProceedings of the Con- ference on Empirical Methods in Natural Language Processing, 2014
2014
-
[10]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016
2016
-
[11]
LightGBM: A highly efficient gradient boosting decision tree,
G. Ke et al., “LightGBM: A highly efficient gradient boosting decision tree,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[12]
CatBoost: unbiased boosting with categorical features,
L. Prokhorenkova et al., “CatBoost: unbiased boosting with categorical features,” inAdvances in Neural Information Processing Systems, 2018
2018
-
[13]
A time series is worth 64 words: Long-term forecasting with Transformers,
Y . Nie et al., “A time series is worth 64 words: Long-term forecasting with Transformers,” inInternational Conference on Learning Represen- tations, 2023
2023
-
[14]
FEDformer: Frequency enhanced decomposed trans- former for long-term series forecasting,
J. Zhou et al., “FEDformer: Frequency enhanced decomposed trans- former for long-term series forecasting,” inInternational Conference on Machine Learning, 2022
2022
-
[15]
TimesNet: Temporal 2D-variation modeling for general time series analysis,
H. Wu et al., “TimesNet: Temporal 2D-variation modeling for general time series analysis,” inInternational Conference on Learning Repre- sentations, 2023
2023
-
[16]
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting,
H. Zhang et al., “Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting,” inInternational Conference on Learning Representations, 2023
2023
-
[17]
iTransformer: Inverted Transformers are effective for time series forecasting,
Y . Liu et al., “iTransformer: Inverted Transformers are effective for time series forecasting,” inInternational Conference on Learning Represen- tations, 2024
2024
-
[18]
ETSformer: Exponential smoothing Transformers for time-series forecasting,
G. Woo et al., “ETSformer: Exponential smoothing Transformers for time-series forecasting,” arXiv preprint arXiv:2202.01381, 2022
-
[19]
Are Transformers effective for time series forecasting?
A. Zeng et al., “Are Transformers effective for time series forecasting?” inProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[20]
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting,
B. N. Oreshkin et al., “N-BEATS: Neural basis expansion analysis for interpretable time series forecasting,” inInternational Conference on Learning Representations, 2020
2020
-
[21]
N-HiTS: Neural hierarchical interpolation for multi- horizon time series forecasting,
C. Challu et al., “N-HiTS: Neural hierarchical interpolation for multi- horizon time series forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[22]
TiDE: Time-series dense encoder,
A. Das et al., “TiDE: Time-series dense encoder,” inInternational Conference on Artificial Intelligence and Statistics, 2024
2024
-
[23]
SCINet: Time series modeling and forecasting with sample convolution and interaction,
T. Liu et al., “SCINet: Time series modeling and forecasting with sample convolution and interaction,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[24]
MICN: Multi-scale local and global context network for long-term series forecasting,
L. Wang et al., “MICN: Multi-scale local and global context network for long-term series forecasting,” inInternational Conference on Learning Representations, 2022
2022
-
[25]
FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
D. Araci, “FinBERT: Financial sentiment analysis with BERT,” arXiv preprint arXiv:1908.10063, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[26]
AlphaStock: A deep reinforcement learning framework for stock portfolio optimization,
D. Zhang et al., “AlphaStock: A deep reinforcement learning framework for stock portfolio optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[27]
DeepLOB: Deep convolutional neural networks for limit order books,
Z. Zhang et al., “DeepLOB: Deep convolutional neural networks for limit order books,”IEEE Transactions on Cognitive and Developmental Systems, vol. 11, no. 4, pp. 465–479, 2019
2019
-
[28]
Axiomatic attribution for deep networks,
M. Sundararajan et al., “Axiomatic attribution for deep networks,” in International Conference on Machine Learning, 2017
2017
-
[29]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke et al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems, 2019
2019
-
[30]
Scikit-learn: Machine learning in Python,
F. Pedregosa et al., “Scikit-learn: Machine learning in Python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
2011
-
[31]
Transformers in time series: A survey,
Q. Wen et al., “Transformers in time series: A survey,”arXiv preprint arXiv:2202.07125, 2024
-
[32]
PatchMixer: A lightweight patch-mixing architecture for time series forecasting,
F. Gong et al., “PatchMixer: A lightweight patch-mixing architecture for time series forecasting,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2024
2024
-
[33]
TimeXer: Empowering transformers for time series fore- casting with exogeneous variables,
Y . Wang et al., “TimeXer: Empowering transformers for time series fore- casting with exogeneous variables,”arXiv preprint arXiv:2402.19017, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.