LC-ICL: Label-Guided Contrastive In-Context Learning for Robust Information Extraction
Pith reviewed 2026-06-30 07:30 UTC · model grok-4.3
The pith
LC-ICL improves few-shot information extraction by adding error-cause labels to negative examples in LLM demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
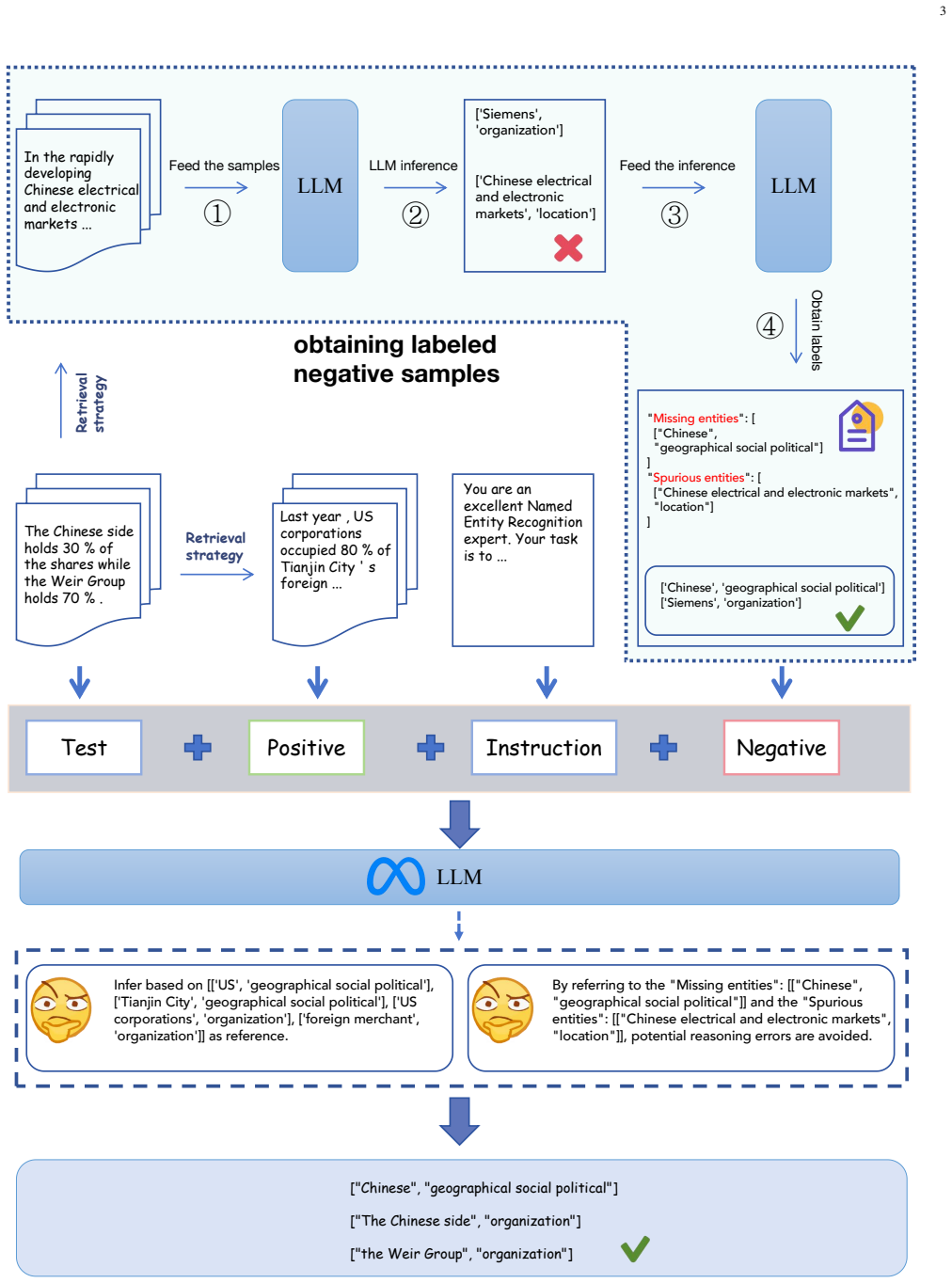
LC-ICL creates in-context learning demonstrations by pairing positive samples with negative samples annotated by error-cause labels; these labels expose detailed error features so the LLM understands why similar predictions fail and avoids repeating the errors at inference time on entity and relation extraction tasks.
What carries the argument
Label-guided contrastive in-context learning that combines positive samples with hard negative samples carrying error-cause annotations.
If this is right
- LLMs can reach higher accuracy on NER and RE by learning from both correct answers and explicitly labeled mistakes in the same prompt.
- Demonstration selection that includes nearest positives and hard negatives supplies contextual information that standard random or positive-only selection misses.
- The method works across multiple IE datasets without task-specific fine-tuning.
- Error features learned from negatives help the model avoid repeating particular failure modes on unseen inputs.
Where Pith is reading between the lines
- The same error-labeling idea could be tested on other sequence labeling or classification tasks where failure modes can be categorized in advance.
- If error-cause labels prove costly to create by hand, an automated labeling step could be added and its effect measured.
- Scaling the method to larger LLMs might show whether the benefit grows or saturates with model size.
- The technique might reduce the number of positive examples needed by making each negative example more informative.
Load-bearing premise
Error-cause labels on negative samples supply information that positive samples alone cannot provide and that this information transfers to better performance on new test instances.
What would settle it
Running the same few-shot IE experiments with and without the error-cause labels on the negative samples and finding no accuracy gain or a drop would falsify the central claim.
Figures




read the original abstract
There has been increasing interest in exploring the capabilities of advanced large language models (LLMs) in the field of information extraction (IE), specifically focusing on tasks related to named entity recognition (NER) and relation extraction (RE).Although researchers are exploring the use of few-shot information extraction through in-context learning with LLMs, they tend to focus only on using correct or positive examples for demonstration, neglecting the potential value of incorporating incorrect or negative examples into the learning process.In this paper, we present LC-ICL a novel few-shot technique that leverages both correct and incorrect sample constructions to create in-context learning demonstrations. This approach enhances the ability of LLMs to extract entities and relations by combining positive samples with negative samples annotated by error-cause labels. These labels expose more detailed error features in erroneous examples, enabling the model to understand why similar predictions fail and avoid repeating such errors during inference.Specifically, our proposed method taps into the inherent contextual information and valuable information in hard negative samples and the nearest positive neighbors to the test and then applies the in-context learning demonstrations based on LLMs. Our experiments on various datasets indicate that LC-ICL outperforms previous few-shot in-context learning methods, delivering substantial enhancements in performance across a broad spectrum of related tasks. These improvements are noteworthy, showcasing the versatility of our approach in diverse scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LC-ICL, a few-shot in-context learning method for information extraction (NER and RE) that augments positive demonstrations with negative samples annotated by error-cause labels. These labels are intended to expose detailed error features so that LLMs can avoid repeating similar mistakes at inference time. The central empirical claim is that this contrastive construction yields substantial gains over prior few-shot ICL baselines across multiple datasets.
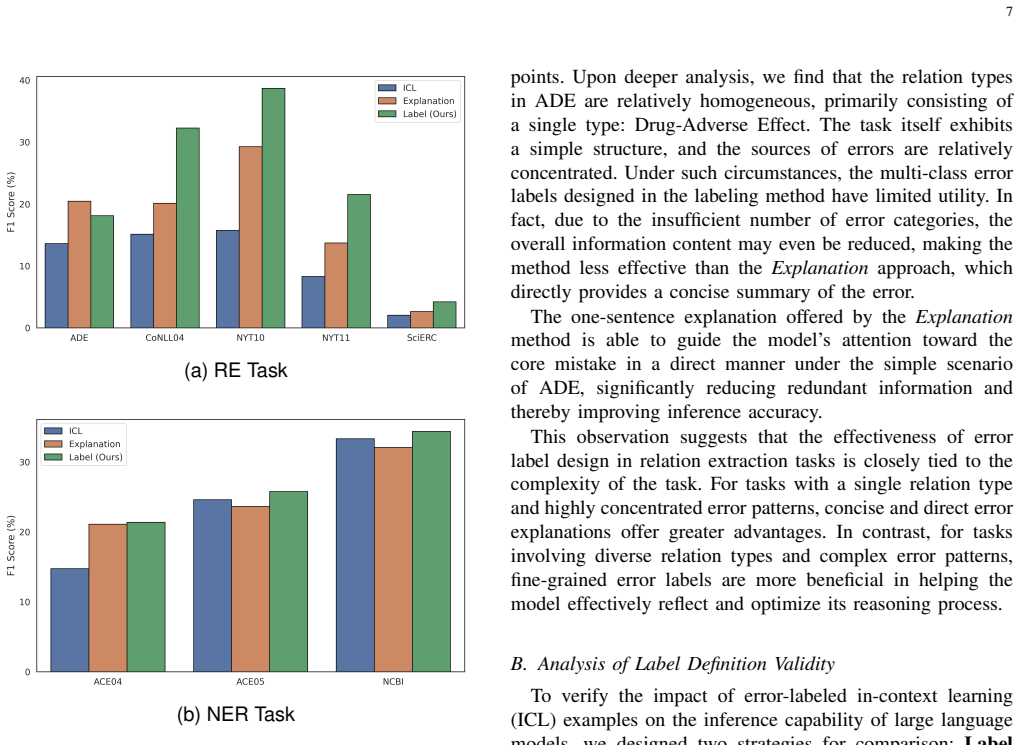
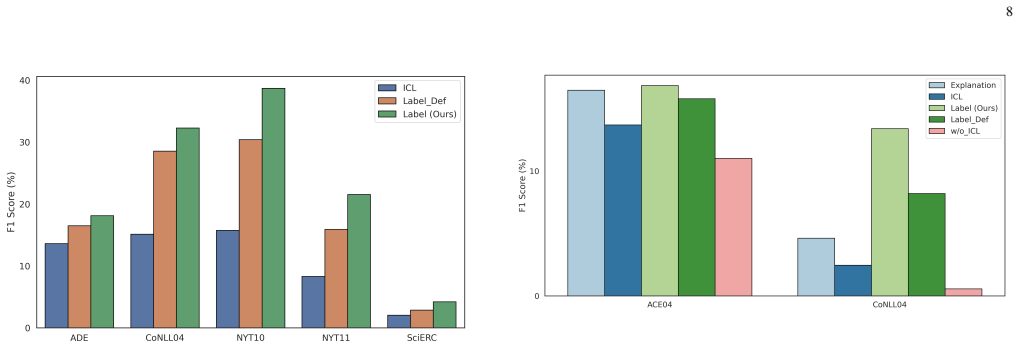
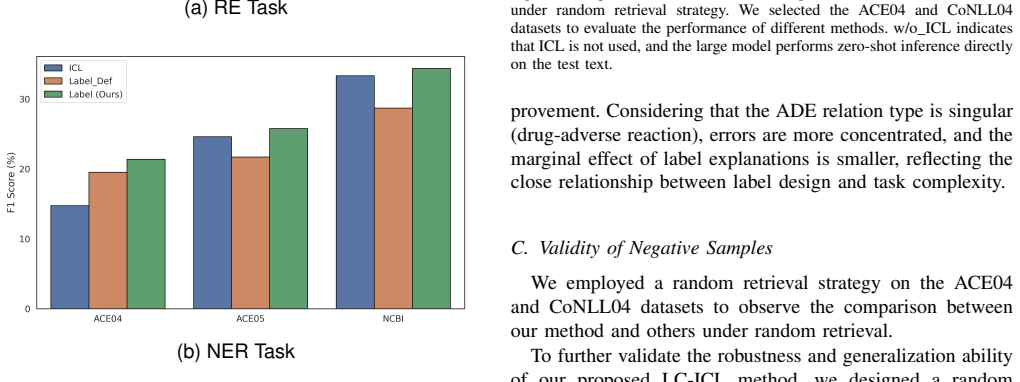
Significance. If the performance gains are shown to be robust and the label-generation procedure is shown to be no more expensive than standard few-shot example selection, the method could meaningfully improve the reliability of LLM-based IE without requiring additional model training. The approach is notable for attempting to exploit hard negatives in a contrastive ICL setting, but its practical value hinges on the cost and generality of the error-cause annotations.
major comments (2)
- [Abstract / §3] Abstract and §3 (method description): the procedure for producing error-cause labels on negative samples is never specified. Because the central claim rests on these labels supplying transferable information that cannot be recovered from positives alone, the absence of any account of how the labels are obtained (manual authoring, model-based derivation on held-out data, etc.) makes it impossible to evaluate whether the method remains a fair few-shot technique or inadvertently leaks test-distribution information.
- [Abstract / Experiments] Abstract and experimental section: the manuscript asserts outperformance on “various datasets” yet supplies no description of the datasets, shot counts, baseline implementations, statistical significance tests, or ablations that isolate the contribution of the error-cause labels versus simply adding unlabeled negatives. Without these elements the empirical claim cannot be assessed.
minor comments (1)
- [Abstract] The abstract contains several run-on sentences and missing punctuation that impair readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that key details are missing from the current manuscript and will revise accordingly to address both major comments.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method description): the procedure for producing error-cause labels on negative samples is never specified. Because the central claim rests on these labels supplying transferable information that cannot be recovered from positives alone, the absence of any account of how the labels are obtained (manual authoring, model-based derivation on held-out data, etc.) makes it impossible to evaluate whether the method remains a fair few-shot technique or inadvertently leaks test-distribution information.
Authors: We agree that the manuscript does not specify how error-cause labels are produced. This omission prevents proper evaluation of the method's fairness as few-shot ICL. In the revision we will add a subsection to §3 that explicitly describes the label-generation procedure (including whether it is manual, model-based on held-out data, or otherwise) and confirms that no test-distribution information is used. revision: yes
-
Referee: [Abstract / Experiments] Abstract and experimental section: the manuscript asserts outperformance on “various datasets” yet supplies no description of the datasets, shot counts, baseline implementations, statistical significance tests, or ablations that isolate the contribution of the error-cause labels versus simply adding unlabeled negatives. Without these elements the empirical claim cannot be assessed.
Authors: We acknowledge that the experimental section lacks the requested details. The revision will expand the experiments section to describe all datasets, shot counts, baseline implementations, statistical significance testing, and ablations that isolate the contribution of error-cause labels versus unlabeled negatives alone. revision: yes
Circularity Check
No significant circularity; empirical method with no derivations or self-citation chains
full rationale
The paper presents LC-ICL as an empirical few-shot ICL technique that augments demonstrations with error-cause labeled negatives. No equations, derivations, or mathematical claims appear in the provided text. The central performance claim rests on experimental results rather than any reduction of outputs to fitted parameters or self-citations. No load-bearing steps match the enumerated circularity patterns; the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Error-cause labels can be assigned to negative samples in a way that reveals actionable features for the LLM
- domain assumption LLMs can extract and apply the contrast between positive and labeled negative demonstrations during inference
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey on automatic knowledge graph construction,
L. Zhong, J. Wu, Q. Li, H. Peng, and X. Wu, “A comprehensive survey on automatic knowledge graph construction,”CoRR, vol. abs/2302.05019, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2302.05019
-
[2]
Named entity recognition for question answering,
D. M. Aliod, M. van Zaanen, and D. Smith, “Named entity recognition for question answering,” inProceedings of the Australasian Language Technology Workshop, ALTA 2006, Sydney, Australia, November 30-December 1, 2006, L. Cavedon and I. Zukerman, Eds. Australasian Language Technology Association, 2006, pp. 51–58. [Online]. Available: https://aclanthology.or...
2006
-
[3]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
2020
-
[4]
S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi, and L. Zettlemoyer, “Rethinking the role of demonstrations: What makes in-context learning work?” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y . Goldberg, Z. Kozareva, and Y . Zh...
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
B. Li, G. Fang, Y . Yang, Q. Wang, W. Ye, W. Zhao, and S. Zhang, “Evaluating chatgpt’s information extraction capabilities: An assessment of performance, explainability, calibration, and faithfulness,”CoRR, vol. abs/2304.11633, 2023. [Online]. Available: https://doi.org/10. 48550/arXiv.2304.11633
-
[8]
Large language models for generative information extraction: A survey,
D. Xu, W. Chen, W. Peng, C. Zhang, T. Xu, X. Zhao, X. Wu, Y . Zheng, and E. Chen, “Large language models for generative information extraction: A survey,”CoRR, vol. abs/2312.17617, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.17617
-
[9]
Learning in-context learning for named entity recognition,
J. Chen, Y . Lu, H. Lin, J. Lou, W. Jia, D. Dai, H. Wu, B. Cao, X. Han, and L. Sun, “Learning in-context learning for named entity recognition,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. As...
-
[10]
Z-ICL: zero-shot in-context learning with pseudo-demonstrations,
X. Lyu, S. Min, I. Beltagy, L. Zettlemoyer, and H. Hajishirzi, “Z-ICL: zero-shot in-context learning with pseudo-demonstrations,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for C...
-
[11]
Zero-shot information extraction via chatting with ChatGPT,
X. Wei, X. Cui, N. Cheng, X. Wang, X. Zhang, S. Huang, P. Xie, J. Xu, Y . Chen, M. Zhanget al., “Zero-shot information extraction via chatting with chatgpt,”arXiv preprint arXiv:2302.10205, 2023
-
[12]
Chain of thought with explicit evidence reasoning for few-shot relation extraction,
X. Ma, J. Li, and M. Zhang, “Chain of thought with explicit evidence reasoning for few-shot relation extraction,” inFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 2334–2352. [Online]. Available: https://aclant...
2023
-
[13]
Revisiting relation extraction in the era of large language models,
S. Wadhwa, S. Amir, and B. C. Wallace, “Revisiting relation extraction in the era of large language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association 11 for Computational Lingu...
-
[14]
P. Li, T. Sun, Q. Tang, H. Yan, Y . Wu, X. Huang, and X. Qiu, “Codeie: Large code generation models are better few- shot information extractors,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. A...
-
[15]
Gollie: Annotation guidelines improve zero-shot information-extraction,
O. Sainz, I. García-Ferrero, R. Agerri, O. L. de Lacalle, G. Rigau, and E. Agirre, “Gollie: Annotation guidelines improve zero-shot information-extraction,”CoRR, vol. abs/2310.03668, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.03668
-
[16]
arXiv preprint arXiv:2304.08085 , year=
X. Wang, W. Zhou, C. Zu, H. Xia, T. Chen, Y . Zhang, R. Zheng, J. Ye, Q. Zhang, T. Guiet al., “Instructuie: Multi-task instruction tuning for unified information extraction,”arXiv preprint arXiv:2304.08085, 2023
-
[17]
Code4struct: Code generation for few-shot event structure prediction,
X. Wang, S. Li, and H. Ji, “Code4struct: Code generation for few-shot event structure prediction,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023,...
-
[18]
GPT-RE: in-context learning for relation extraction using large language models,
Z. Wan, F. Cheng, Z. Mao, Q. Liu, H. Song, J. Li, and S. Kurohashi, “GPT-RE: in-context learning for relation extraction using large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Lin...
2023
-
[19]
What makes good in-context examples for gpt-3?
J. Liu, D. Shen, Y . Zhang, B. Dolan, L. Carin, and W. Chen, “What makes good in-context examples for gpt-3?” inProceedings of Deep Learning Inside Out: The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@ACL 2022, Dublin, Ireland and Online, May 27, 2022, E. Agirre, M. Apidianaki, and I. Vulic, Eds. Associatio...
2022
-
[20]
What Makes Good In-Context Examples for
[Online]. Available: https://doi.org/10.18653/v1/2022.deelio-1.10
-
[21]
Thinking about GPT-3 in-context learning for biomedical ie? think again,
B. J. Gutierrez, N. McNeal, C. Washington, Y . Chen, L. Li, H. Sun, and Y . Su, “Thinking about GPT-3 in-context learning for biomedical ie? think again,” inFindings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Association for Computationa...
-
[22]
Y . Guo, Z. Li, X. Jin, Y . Liu, Y . Zeng, W. Liu, X. Li, P. Yang, L. Bai, J. Guo, and X. Cheng, “Retrieval-augmented code generation for universal information extraction,”CoRR, vol. abs/2311.02962, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.02962
-
[23]
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler, “Vse++: Improv- ing visual-semantic embeddings with hard negatives,”arXiv preprint arXiv:1707.05612, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
C- icl: contrastive in-context learning for information extraction,
Y . Mo, J. Liu, J. Yang, Q. Wang, S. Zhang, J. Wang, and Z. Li, “C- icl: contrastive in-context learning for information extraction,”arXiv preprint arXiv:2402.11254, 2024
-
[25]
A linear programming formulation for global inference in natural language tasks,
D. Roth and W. Yih, “A linear programming formulation for global inference in natural language tasks,” inProceedings of the Eighth Conference on Computational Natural Language Learning, CoNLL 2004, Held in cooperation with HLT-NAACL 2004, Boston, Massachusetts, USA, May 6-7, 2004, H. T. Ng and E. Riloff, Eds. ACL, 2004, pp. 1–8. [Online]. Available: https...
2004
-
[26]
Modeling relations and their mentions without labeled text,
S. Riedel, L. Yao, and A. McCallum, “Modeling relations and their mentions without labeled text,” inMachine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, September 20-24, 2010, Proceedings, Part III 21. Springer, 2010, pp. 148–163
2010
-
[27]
A hierarchical framework for relation extraction with reinforcement learning,
R. Takanobu, T. Zhang, J. Liu, and M. Huang, “A hierarchical framework for relation extraction with reinforcement learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 7072–7079
2019
-
[28]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , address=
Y . Luan, L. He, M. Ostendorf, and H. Hajishirzi, “Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, E...
-
[29]
Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports,
H. Gurulingappa, A. M. Rajput, A. Roberts, J. Fluck, M. Hofmann- Apitius, and L. Toldo, “Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports,”Journal of biomedical informatics, vol. 45, no. 5, pp. 885–892, 2012
2012
-
[30]
Unified structure generation for universal information extraction,
Y . Lu, Q. Liu, D. Dai, X. Xiao, H. Lin, X. Han, L. Sun, and H. Wu, “Unified structure generation for universal information extraction,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Association ...
-
[31]
The automatic content extraction (ACE) program - tasks, data, and evaluation,
G. R. Doddington, A. Mitchell, M. A. Przybocki, L. A. Ramshaw, S. M. Strassel, and R. M. Weischedel, “The automatic content extraction (ACE) program - tasks, data, and evaluation,” inProceedings of the Fourth International Conference on Language Resources and Evaluation, LREC 2004, May 26-28, 2004, Lisbon, Portugal. European Language Resources Association...
2004
-
[32]
Walker and L
C. Walker and L. D. Consortium,ACE 2005 Multilingual Training Corpus, ser. LDC corpora, 2005
2005
-
[33]
Ncbi disease corpus: a resource for disease name recognition and concept normalization,
R. I. Dogan, R. Leaman, and Z. Lu, “Ncbi disease corpus: a resource for disease name recognition and concept normalization,”Journal of biomedical informatics, vol. 47, pp. 1–10, 2014
2014
-
[34]
A unified MRC framework for named entity recognition,
X. Li, J. Feng, Y . Meng, Q. Han, F. Wu, and J. Li, “A unified MRC framework for named entity recognition,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, D. Jurafsky, J. Chai, N. Schluter, and J. R. Tetreault, Eds. Association for Computational Linguistics, 2020, pp. 5849–5859...
-
[35]
Y . Mo, H. Tang, J. Liu, Q. Wang, Z. Xu, J. Wang, W. Wu, and Z. Li, “Multi-task transformer with relation-attention and type-attention for named entity recognition,” inIEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023. IEEE, 2023, pp. 1–5. [Online]. Available: https://doi.org/10.11...
-
[36]
mcl- ner: Cross-lingual named entity recognition via multi-view contrastive learning,
Y . Mo, J. Yang, J. Liu, Q. Wang, R. Chen, J. Wang, and Z. Li, “mcl- ner: Cross-lingual named entity recognition via multi-view contrastive learning,”CoRR, vol. abs/2308.09073, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.09073
-
[37]
The llama 3 herd of models,
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,” 2024
2024
-
[38]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Neural architectures for named entity recognition,
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” inNAACL HLT 2016, 2016, pp. 260–270
2016
-
[40]
Recognizing continuous and discontinuous adverse drug reaction mentions from social media using lstm-crf,
B. Tang, J. Hu, X. Wang, and Q. Chen, “Recognizing continuous and discontinuous adverse drug reaction mentions from social media using lstm-crf,”Wireless Communications and Mobile Computing, vol. 2018, 2018
2018
-
[41]
Dynamic modeling cross-modal interactions in two-phase prediction for entity-relation extraction,
S. Zhao, M. Hu, Z. Cai, and F. Liu, “Dynamic modeling cross-modal interactions in two-phase prediction for entity-relation extraction,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 3, pp. 1122–1131, 2023
2023
-
[42]
CROP: zero-shot cross-lingual named entity recognition with multilingual labeled sequence translation,
J. Yang, S. Huang, S. Ma, Y . Yin, L. Dong, D. Zhang, H. Guo, Z. Li, and F. Wei, “CROP: zero-shot cross-lingual named entity recognition with multilingual labeled sequence translation,” inFindings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y . Goldberg, Z. Kozareva, and Y . Zhang, Ed...
2022
-
[43]
Zero-shot information extraction via chatting with ChatGPT,
X. Wei, X. Cui, N. Cheng, X. Wang, X. Zhang, S. Huang, P. Xie, J. Xu, Y . Chen, M. Zhang, Y . Jiang, and W. Han, “Zero-shot information extraction via chatting with chatgpt,”CoRR, vol. abs/2302.10205, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2302.10205
-
[44]
Learning to select relevant knowledge for neural machine translation,
J. Yang, J. Wan, S. Ma, H. Huang, D. Zhang, Y . Yu, Z. Li, and F. Wei, “Learning to select relevant knowledge for neural machine translation,” inNatural Language Processing and Chinese Computing - 10th CCF International Conference, NLPCC 2021, Qingdao, China, October 13-17, 2021, Proceedings, Part I, ser. Lecture Notes in Computer Science, L. Wang, Y . Fe...
-
[45]
Learning To Retrieve Prompts for In-Context Learning , url =
O. Rubin, J. Herzig, and J. Berant, “Learning to retrieve prompts for in-context learning,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022, M. Carpuat, M. de Marneffe, and I. V . M. Ruíz, Eds. Associat...
-
[46]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, L. Li, and Z. Sui, “A survey on in-context learning,” 2023
2023
-
[47]
Y . Ge, S. Liu, Y . Wang, L. Mei, L. Chen, B. Bi, and X. Cheng, “Innate reasoning is not enough: In-context learning enhances reasoning large language models with less overthinking,” 2025. [Online]. Available: https://arxiv.org/abs/2503.19602
-
[48]
B. Y . Lin, A. Ravichander, X. Lu, N. Dziri, M. Sclar, K. Chandu, C. Bha- gavatula, and Y . Choi, “The unlocking spell on base llms: Rethinking alignment via in-context learning,”arXiv preprint arXiv:2312.01552, 2023
-
[49]
Is in- context learning sufficient for instruction following in llms?
H. Zhao, M. Andriushchenko, F. Croce, and N. Flammarion, “Is in- context learning sufficient for instruction following in llms?”arXiv preprint arXiv:2405.19874, 2024
-
[50]
Distributed representations of words and phrases and their composi- tionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their composi- tionality,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[51]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[52]
Distinguish- ing ignorance from error in llm hallucinations,
A. Simhi, J. Herzig, I. Szpektor, and Y . Belinkov, “Distinguish- ing ignorance from error in llm hallucinations,”arXiv preprint arXiv:2410.22071, 2024
-
[53]
Error analysis prompting enables human-like translation evaluation in large language models,
Q. Lu, B. Qiu, L. Ding, K. Zhang, T. Kocmi, and D. Tao, “Error analysis prompting enables human-like translation evaluation in large language models,”arXiv preprint arXiv:2303.13809, 2023
-
[54]
Hierarchical label-enhanced contrastive learning for chinese ner,
C. Wang, S. Zhao, T. Yan, S. Song, W. Ma, K. Liu, and M. Wang, “Hierarchical label-enhanced contrastive learning for chinese ner,”IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2025
2025
-
[55]
Hcl: A hierarchical contrastive learning framework for zero-shot rela- tion extraction,
T. Yan, S. Zhao, M. Hu, M. Wang, X. Zhang, Z. Luo, and M. Wang, “Hcl: A hierarchical contrastive learning framework for zero-shot rela- tion extraction,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 5694–5705, 2025. 13 APPENDIX A. Dataset Statistics To facilitate a thorough evaluation, we incorporate a diverse collection o...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.