The Verbose Context Problem in Medical Records
Pith reviewed 2026-06-30 07:27 UTC · model grok-4.3
The pith
Domain-independent methods fail to alleviate the verbose context problem in medical records, leaving opportunity for domain-specific structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
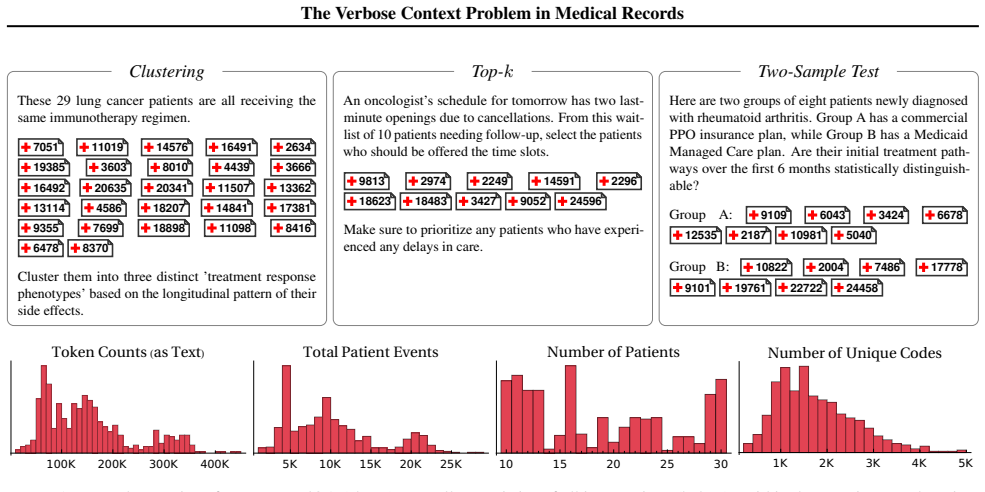
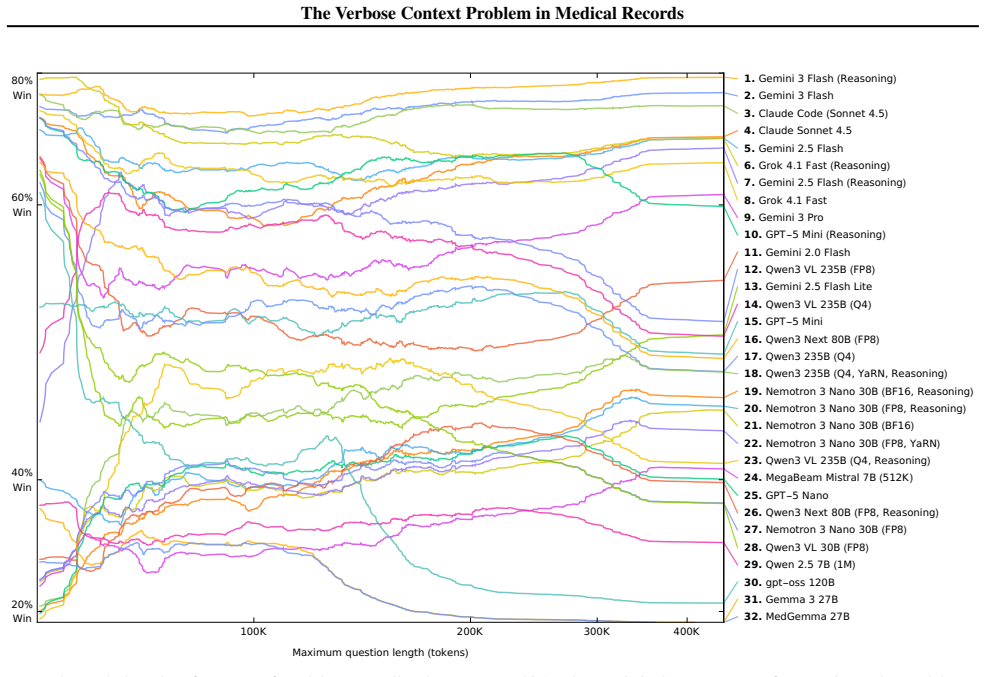
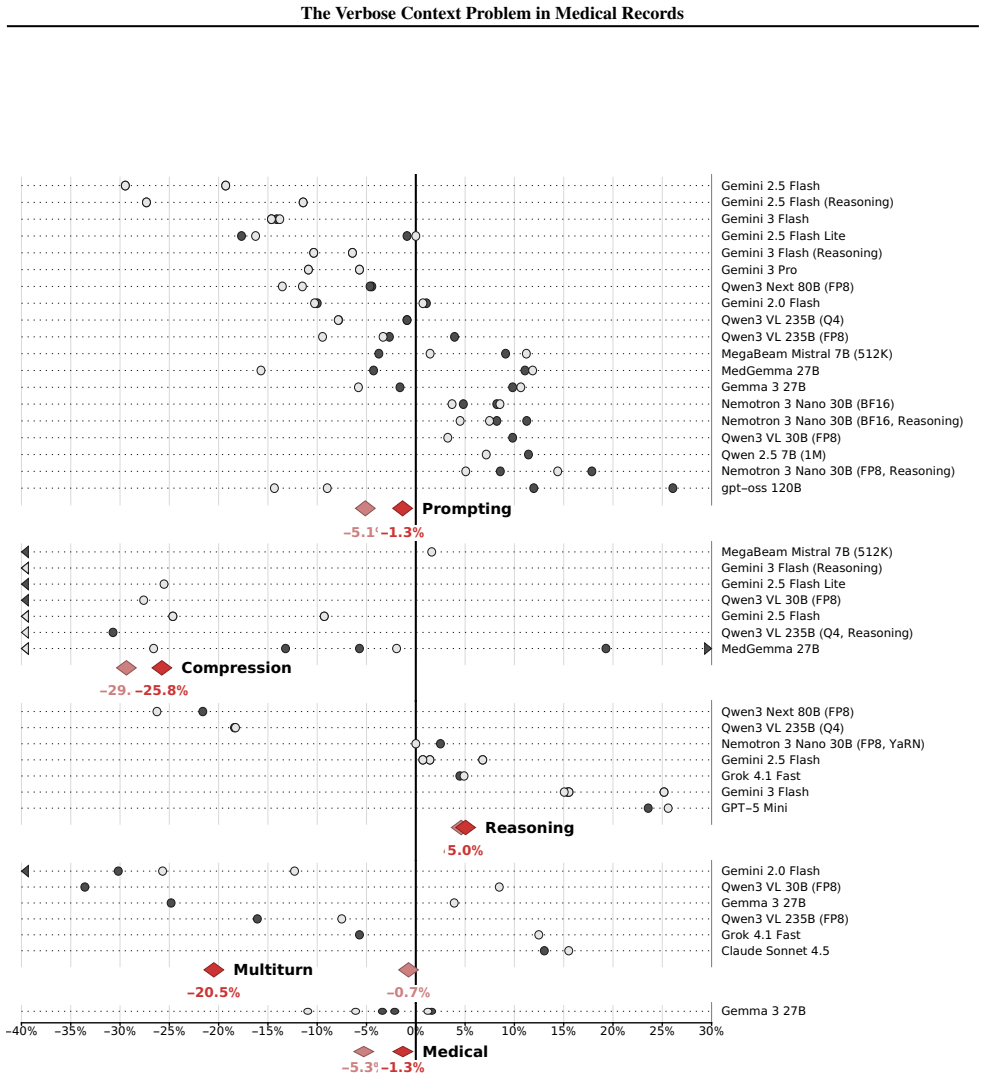
The authors claim that the verbose context problem occurs when structured concepts have token-inefficient textual representations and is acute in population health where cohort-level analysis requires reasoning over thousands of medically-coded events often exceeding 400K tokens total. PopMedQA isolates this through tasks on neopatient-generated artificial records, and extensive ablations show domain-independent methods fail to alleviate it while significant opportunity remains to exploit domain-specific structure in language model inputs for population-scale reasoning.
What carries the argument
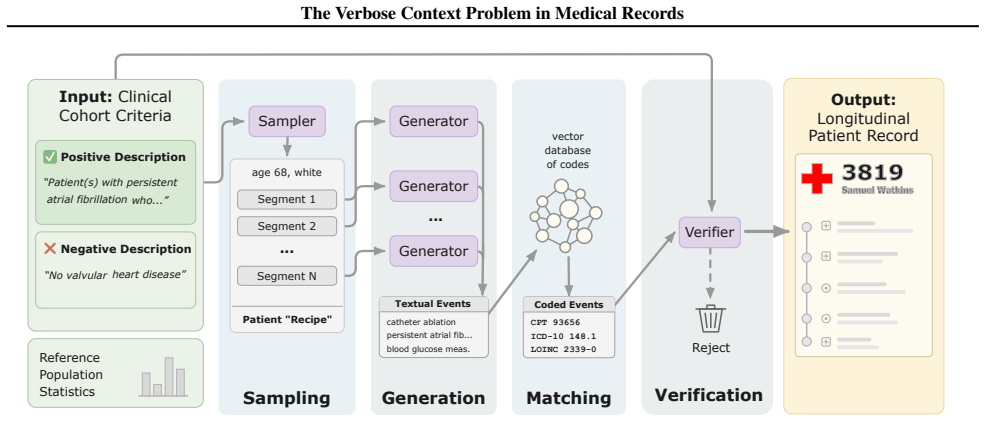
The PopMedQA benchmark and neopatient library for language-controlled generation of artificial longitudinal patient records, which together isolate the verbose context problem for testing language model performance on cohort tasks.
If this is right
- Population-scale reasoning over patient records will require new techniques that go beyond current domain-independent methods.
- Language model inputs for medical data must incorporate domain-specific structure to overcome token inefficiency.
- General prompting, compression, and agentic approaches will continue to underperform on tasks involving thousands of medically-coded events.
Where Pith is reading between the lines
- The same token-inefficiency issue may appear in other structured longitudinal domains such as financial transaction histories or legal case timelines.
- Future methods could encode medical codes and ontologies directly into model inputs rather than relying on expanded text descriptions.
- Extending PopMedQA tasks to real de-identified records would allow direct comparison of artificial versus observed data distributions.
Load-bearing premise
The neopatient-generated artificial records and PopMedQA computational tasks sufficiently isolate the verbose context problem and represent real longitudinal patient record analysis in population health.
What would settle it
Applying the same ablations of prompting, compression, and agentic decomposition to actual de-identified longitudinal medical records from population health datasets and finding that domain-independent methods succeed in handling contexts over 400K tokens.
Figures



read the original abstract
The verbose context problem occurs when structured concepts have token-inefficient textual representations. This bottleneck is acute in population health: cohort-level analysis of longitudinal patient records requires reasoning over thousands of medically-coded events, often exceeding 400K tokens in total. We present PopMedQA, a benchmark isolating this problem through computational tasks on groups of longitudinal patient records. We construct the benchmark using neopatient, a new library for language-controlled generation of artificial patient records. Through extensive ablations -- including prompting strategies, prompt compression, and agentic decomposition -- we find that domain-independent methods fail to alleviate the verbose context problem. There remains significant opportunity to exploit domain-specific structure in language model inputs for population-scale reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines the verbose context problem in population-scale medical record analysis, where longitudinal records with thousands of coded events exceed 400K tokens. It introduces the neopatient library for language-controlled generation of artificial patient records and the PopMedQA benchmark for computational tasks on groups of such records. Extensive ablations on prompting strategies, prompt compression, and agentic decomposition lead to the conclusion that domain-independent methods fail to alleviate the problem, indicating opportunity for domain-specific approaches.
Significance. If the synthetic records faithfully capture real EHR properties, the work identifies a practical scaling bottleneck for LLMs in medical population health and provides a controlled benchmark that could guide development of specialized input representations. The benchmark construction itself is a clear contribution enabling reproducible study of this issue.
major comments (2)
- [Benchmark construction] PopMedQA benchmark construction: the central claim that domain-independent methods fail rests on ablations using neopatient-generated records, yet the manuscript provides no quantitative validation (e.g., token-length distributions, event-density statistics, or coding-structure fidelity) comparing synthetic records to real longitudinal EHRs exceeding 400K tokens; without this, ablation outcomes may reflect generation artifacts rather than the targeted problem.
- [Ablation results] Ablation experiments: the abstract states that prompting, compression, and agentic methods fail but the results lack reported quantitative metrics, error bars, statistical tests, or precise task definitions, preventing assessment of whether the failure is robust or task-specific.
minor comments (1)
- [Abstract] The abstract would benefit from one or two key quantitative results (e.g., performance deltas) to make the failure claim concrete for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark construction] PopMedQA benchmark construction: the central claim that domain-independent methods fail rests on ablations using neopatient-generated records, yet the manuscript provides no quantitative validation (e.g., token-length distributions, event-density statistics, or coding-structure fidelity) comparing synthetic records to real longitudinal EHRs exceeding 400K tokens; without this, ablation outcomes may reflect generation artifacts rather than the targeted problem.
Authors: We agree that the absence of direct quantitative validation against real longitudinal EHRs is a limitation. The neopatient library generates records via language-controlled prompts intended to reproduce the token inefficiency and event density of real records, but no explicit distributional comparisons were reported. In the revised version we will add a dedicated validation subsection containing token-length distributions, event-density statistics, and coding-structure fidelity metrics, drawing on publicly available de-identified EHR summary statistics for comparison. revision: yes
-
Referee: [Ablation results] Ablation experiments: the abstract states that prompting, compression, and agentic methods fail but the results lack reported quantitative metrics, error bars, statistical tests, or precise task definitions, preventing assessment of whether the failure is robust or task-specific.
Authors: The results section already reports per-task accuracy figures for each ablation setting. However, we acknowledge that error bars, formal statistical tests, and expanded task definitions are not currently included. We will revise the results and methods sections to add standard deviations across repeated runs, appropriate statistical comparisons, and more granular task specifications so that robustness can be directly evaluated. revision: yes
Circularity Check
No circularity: empirical benchmark and ablations are self-contained
full rationale
The paper introduces PopMedQA benchmark via neopatient library and evaluates domain-independent methods through prompting, compression, and agentic ablations on synthetic longitudinal records. No equations, derivations, fitted parameters, or predictions appear. The central claim rests on direct empirical results rather than reducing to self-citations, self-definitions, or renamed known results. Benchmark construction and ablation outcomes are independent contributions without load-bearing self-citation chains or ansatz smuggling. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Artificial patient records generated by neopatient sufficiently capture the token inefficiency of real longitudinal medical records for benchmarking purposes.
- domain assumption The computational tasks in PopMedQA are representative of population health cohort analysis.
invented entities (2)
-
neopatient library
no independent evidence
-
PopMedQA benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arnrich, B., Choi, E., Fries, J., McDermott, M., Oh, J., Pol- lard, T., Shah, N., Steinberg, E., Wornow, M., and van de Water, R
URL https: //openreview.net/forum?id=4oo6XTL6Oj. Arnrich, B., Choi, E., Fries, J., McDermott, M., Oh, J., Pol- lard, T., Shah, N., Steinberg, E., Wornow, M., and van de Water, R. Medical event data standard (meds): Facilitat- ing machine learning for health. InICLR 2024 Workshop on Learning from Time Series For Health (TS4H),
2024
-
[2]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Part of the Artificial Analy- sis Intelligence Index. Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., et al. Longbench: A bilingual, multitask benchmark for long context under- standing.arXiv preprint arXiv:2308.14508,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Glyph: Scal- ing context windows via visual-text compression.arXiv preprint arXiv:2510.17800,
Cheng, J., Liu, Y ., Zhang, X., Fei, Y ., Hong, W., Lyu, R., Wang, W., Su, Z., Gu, X., Liu, X., et al. Glyph: Scal- ing context windows via visual-text compression.arXiv preprint arXiv:2510.17800,
-
[4]
Eyuboglu, S., Ehrlich, R., Arora, S., Guha, N., Zinsley, D., Liu, E., Tennien, W., Rudra, A., Zou, J., Mirhoseini, A., et al. Cartridges: Lightweight and general-purpose long context representations via self-study.arXiv preprint arXiv:2506.06266,
-
[5]
Grolleau, F., Alsentzer, E., Keyes, T., Chung, P., Swami- nathan, A., Aali, A., others, and Chen, J
doi: 10.1609/aaai.v38i20.30205. Grolleau, F., Alsentzer, E., Keyes, T., Chung, P., Swami- nathan, A., Aali, A., others, and Chen, J. H. Medfacteval and medagentbrief: A framework and workflow for gener- ating and evaluating factual clinical summaries. InPacific Symposium on Biocomputing, volume 31, pp. 388–399,
-
[6]
Jeong, D
URL https: //openreview.net/forum?id=HylsTT4FvB. Jeong, D. P., Garg, S., Lipton, Z. C., and Oberst, M. Medical adaptation of large language and vision-language models: Are we making progress? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 12143–12170,
2024
-
[7]
Llm- lingua: Compressing prompts for accelerated inference of large language models
Jiang, H., Wu, Q., Lin, C.-Y ., Yang, Y ., and Qiu, L. Llm- lingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 13358–13376,
2023
-
[8]
doi: 10.1056/AIdbp2500144. Kindig, D. and Stoddart, G. What is population health? American journal of public health, 93(3):380–383,
-
[9]
Subramani, N., Suresh, N., and Peters, M. E. Extracting latent steering vectors from pretrained language models. InFindings of the Association for Computational Linguis- tics: ACL 2022, pp. 566–581,
2022
-
[10]
URL https://openreview.net/forum ?id=qVyeW-grC2k. V odrahalli, K., Ontanon, S., Tripuraneni, N., Xu, K., Jain, S., Shivanna, R., Hui, J., Dikkala, N., Kazemi, M., Fatemi, B., et al. Michelangelo: Long context evaluations beyond haystacks via latent structure queries.arXiv preprint arXiv:2409.12640,
-
[11]
DeepSeek-OCR: Contexts Optical Compression
Wei, H., Sun, Y ., and Li, Y . Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
∞-bench: Extending long context evaluation beyond 100k tokens
Zhang, X., Chen, Y ., Hu, S., Xu, Z., Chen, J., Hao, M., Han, X., Thai, Z., Wang, S., Liu, Z., et al. ∞-bench: Extending long context evaluation beyond 100k tokens. arXiv preprint arXiv:2402.13718,
-
[13]
lost in the middle
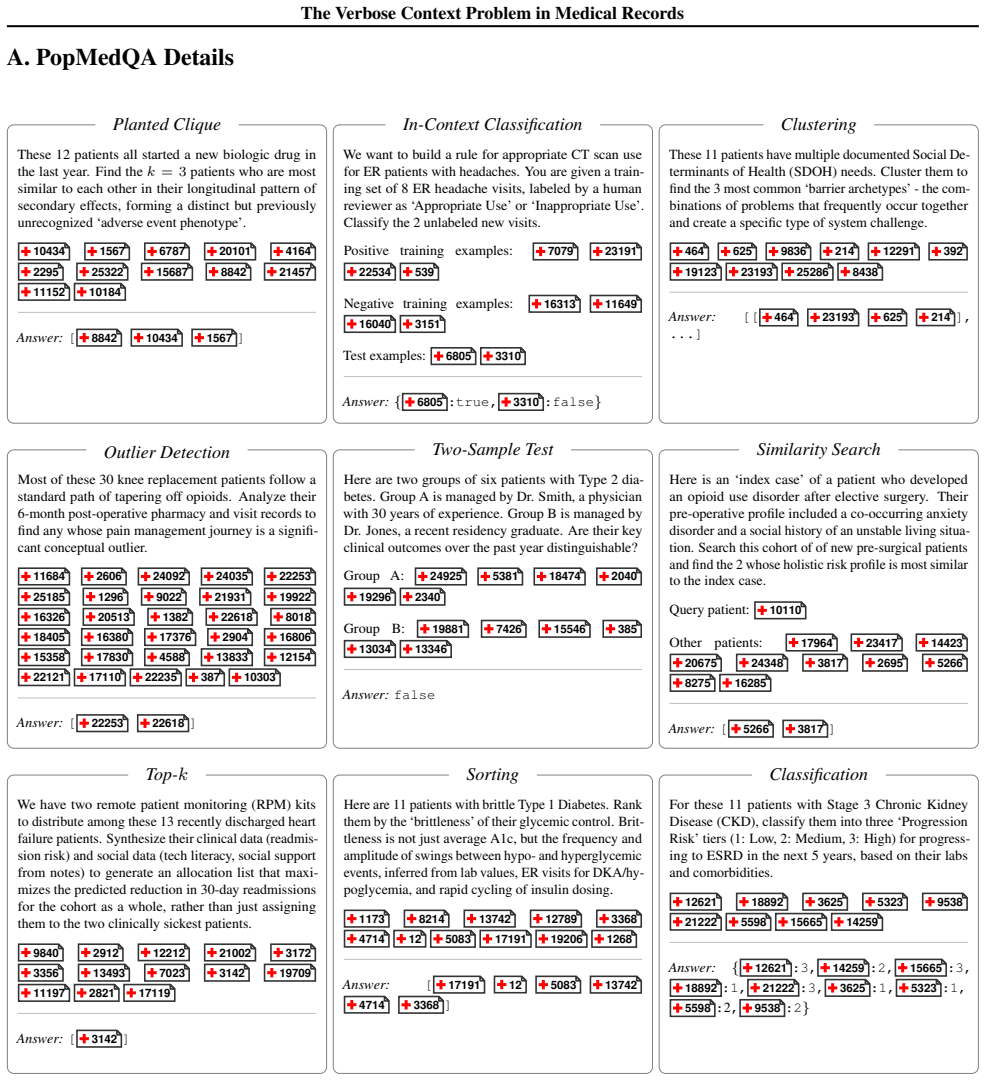
7 The Verbose Context Problem in Medical Records A. PopMedQA Details Planted Clique These 12 patients all started a new biologic drug in the last year. Find the k= 3 patients who are most similar to each other in their longitudinal pattern of secondary effects, forming a distinct but previously unrecognized ‘adverse event phenotype’. 1043410434 15671567 6...
1968
-
[14]
focus on instruction-following and factuality within clinical notes. PopMedQA diverges from these approaches by shifting the analytical focus to population health, requiring models to perform holistic, in-context reasoning across the raw longitudinal records of cohorts of 10 to 50 patients simultaneously. This framework unlocks complex use cases in popula...
2003
-
[15]
are widely employed. These tools primarily rely on rule-based aggregation of structured diagnosis codes and pharmacy data to perform retrospective financial risk stratification and predict healthcare utilization. However, these statistical frameworks are often limited by fragile or manual feature engineering that cannot capture the complex dependencies wi...
2004
-
[16]
Steering vectors (Jahanian et al., 2020; Subramani et al.,
also condense the prefix by optimizing the contents of key-value caches in attention layers. Steering vectors (Jahanian et al., 2020; Subramani et al.,
2020
-
[17]
Rendering text to images and using vision language models can be effective for long-context inference (Zheng et al., 2024; Cheng et al., 2025; Wei et al., 2025)
are added to activations to control generation in an input-agnostic manner. Rendering text to images and using vision language models can be effective for long-context inference (Zheng et al., 2024; Cheng et al., 2025; Wei et al., 2025). 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.