Optimizer Memory Makes Shuffle Order a First-Order Source of Fine-Tuning Noise
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
Optimizer memory turns data shuffle order into an O(η) source of fine-tuning noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any fixed finite measurement window, a lifted-state expansion gives an O(η) equal-multiset contrast whenever the first-order replay coefficient is nonzero, while regular and clock-matched controls remain O(η²); a bare fixed-β momentum buffer is already enough.
What carries the argument
Lifted-state expansion of the optimizer trajectory that isolates the first-order replay coefficient arising from step-index (rather than τ-scaled) advancement of memory buffers.
If this is right
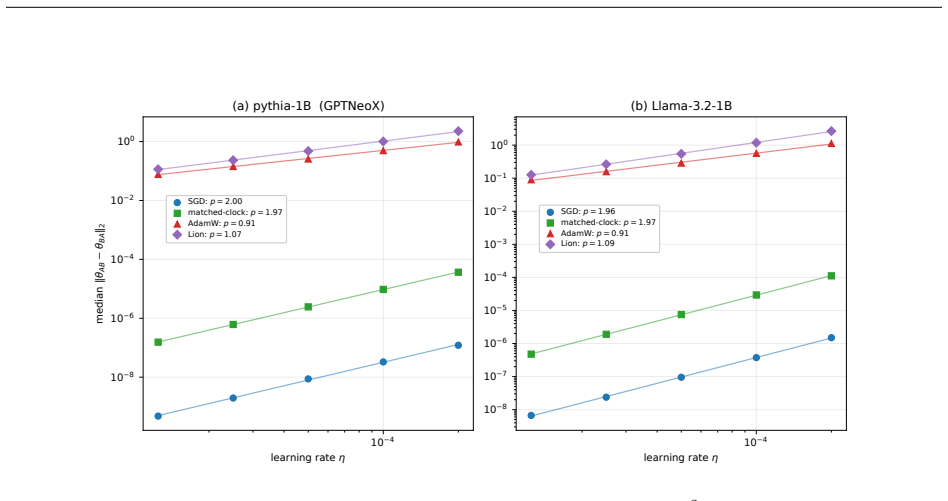
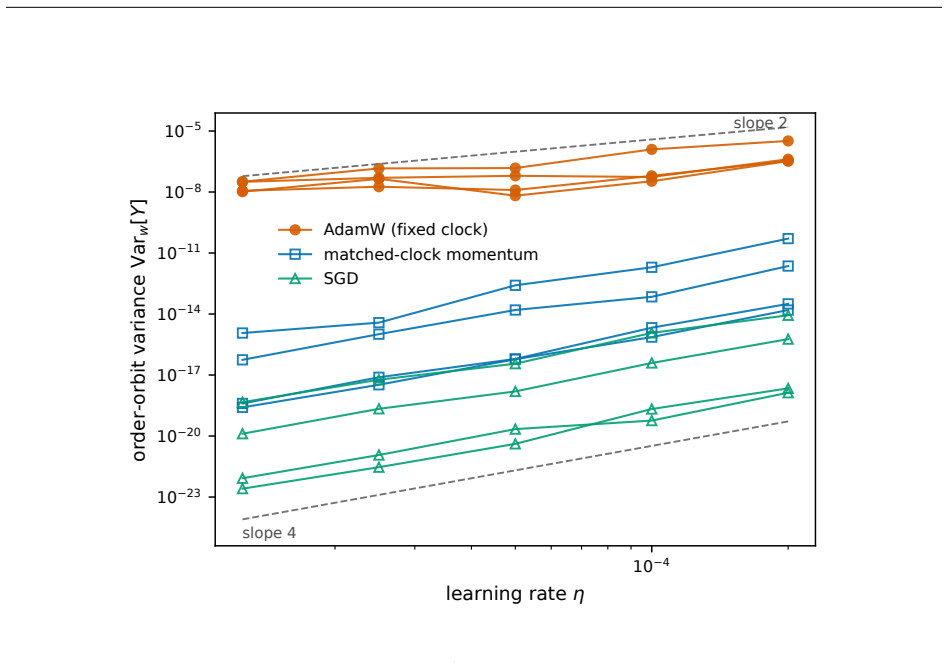
- Bitwise-deterministic replay isolates order-variance slopes of 1.83 for AdamW, 2.00 for fixed-β momentum, and 4.00 for SGD.
- Matching the memory clock to τ restores the regular O(η²) exponent.
- For AdamW with frozen preconditioner the impulse-weight kernel supplies a closed-form asymptotic order-variance floor after local potentials are measured.
- The channel remains local to each measurement window but directly supplies order-noise error bars, positional attribution weights, and a seed-budget criterion.
Where Pith is reading between the lines
- In practice this channel may explain part of the seed-to-seed variance observed in fine-tuning runs that use standard shuffled data loaders.
- Clock-matching the optimizer state to scaled time offers one route to suppress the effect without changing batch size or learning-rate schedule.
- The same expansion could be applied to other memory-based components such as second-moment estimators or adaptive preconditioners to predict their individual contributions to order noise.
Load-bearing premise
The optimizer state advances strictly with the discrete step index k rather than with the continuous learning-rate-scaled time τ=ηk.
What would settle it
A bitwise replay experiment on a fixed-β momentum optimizer that yields an order-variance slope different from 2.00, or a clock-matched buffer that fails to restore the O(η²) exponent.
Figures
read the original abstract
Shuffle order can be a larger source of fine-tuning noise than a memoryless analysis predicts: fixed-clock optimizer memory makes local equal-multiset contrasts first order in the learning rate rather than second order, and the resulting order channel can be large enough for a single seed to flip a close A/B comparison. We isolate this mechanism and derive a fit-free way to size the noise it produces. For a memoryless optimizer, reordering an equal multiset has no first-order endpoint term; the leading local contrast is the $O(\eta^2)$ gradient bracket. Fixed-clock optimizers such as AdamW are different. Their moment buffers, preconditioner state, and de-biasing counters advance with the step index rather than with the learning-rate-scaled time $\tau=\eta k$, so the same gradient can receive a position-dependent endpoint weight. For any fixed finite measurement window, a lifted-state expansion gives an $O(\eta)$ equal-multiset contrast whenever the first-order replay coefficient is nonzero, while regular and clock-matched controls remain $O(\eta^2)$; a bare fixed-$\beta$ momentum buffer is already enough. A bitwise-deterministic replay from one warmed optimizer state isolates the mechanism, giving order-variance slopes 1.83 for AdamW, 2.00 for fixed-$\beta$ momentum, and 4.00 for SGD; matching the memory clock to $\tau$ restores the regular exponent. For AdamW with a frozen preconditioner, the same impulse-weight kernel gives a closed-form asymptotic order-variance floor after the local potentials are measured, with no fitted coefficients. The result is local to the measurement window (independent reshuffling can average the channel across windows), but it yields order-noise error bars, positional attribution weights, and a seed-budget criterion for fine-tuning comparisons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that optimizer memory (moment buffers, preconditioners, de-biasing counters) indexed by discrete step k rather than scaled time τ=ηk turns reordering of equal-multiset gradients into an O(η) source of fine-tuning noise for any fixed finite window, whereas memoryless optimizers yield only O(η²) gradient-bracket contrast. A lifted-state expansion is asserted to produce a nonzero first-order replay coefficient for fixed-β momentum (and AdamW), with regular/clock-matched controls remaining O(η²); this is isolated via bitwise-deterministic replay from one warmed state, yielding order-variance slopes 1.83 (AdamW), 2.00 (momentum), 4.00 (SGD) that match theory, plus a closed-form asymptotic order-variance floor for frozen-preconditioner AdamW with no fitted coefficients.
Significance. If the central derivation holds, the work identifies a previously overlooked first-order channel for shuffle-induced variance in fine-tuning that can flip close A/B comparisons from a single seed. Credit is due for the parameter-free closed-form sizing, the empirical slope match without fitted coefficients, and the clean isolation of the mechanism via single-state replay. The result is local to the measurement window but supplies concrete tools (order-noise error bars, positional weights, seed-budget criterion) that could improve experimental rigor in ML fine-tuning studies.
major comments (2)
- [lifted-state expansion] Lifted-state expansion (abstract and derivation): the assertion that the first-order replay coefficient is nonzero for fixed-β momentum (producing O(η) equal-multiset contrast while controls stay O(η²)) requires explicit term collection showing that the position-dependent endpoint weight arising from the k-indexed β^k factor does not cancel in the difference between orders {g then h} and {h then g}. Without this expansion, it remains possible that the O(η) term vanishes, leaving only the regular O(η²) bracket.
- [replay experiment] § on replay experiment and slope measurement: the reported order-variance slopes (1.83 AdamW, 2.00 momentum, 4.00 SGD) are presented as matching the predicted exponents, but the section must specify how the fixed finite window size is chosen and demonstrate that the O(η) scaling persists when the window length is varied, as the mechanism is stated to be local to that window.
minor comments (2)
- [abstract] The abstract introduces 'positional attribution weights' and 'seed-budget criterion' without defining them; a short equation or paragraph in the main text would clarify their construction from the impulse-weight kernel.
- Notation for the 'first-order replay coefficient' should be introduced with an explicit definition (e.g., as the coefficient of the linear term in the lifted expansion) rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the careful reading, the positive assessment of the work's significance, and the constructive suggestions. We address each major comment below and will incorporate the requested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [lifted-state expansion] Lifted-state expansion (abstract and derivation): the assertion that the first-order replay coefficient is nonzero for fixed-β momentum (producing O(η) equal-multiset contrast while controls stay O(η²)) requires explicit term collection showing that the position-dependent endpoint weight arising from the k-indexed β^k factor does not cancel in the difference between orders {g then h} and {h then g}. Without this expansion, it remains possible that the O(η) term vanishes, leaving only the regular O(η²) bracket.
Authors: We agree that the derivation would benefit from an explicit term-by-term collection. In the revised manuscript we will expand the lifted-state analysis to collect the O(η) contributions explicitly for fixed-β momentum. This will show that the position-dependent endpoint weights induced by the discrete k-indexed β^k factors produce a nonzero first-order replay coefficient in the difference between the orders {g,h} and {h,g}, while the corresponding regular and clock-matched controls remain O(η²). The added expansion will be placed in the main derivation section with the relevant intermediate expressions. revision: yes
-
Referee: [replay experiment] § on replay experiment and slope measurement: the reported order-variance slopes (1.83 AdamW, 2.00 momentum, 4.00 SGD) are presented as matching the predicted exponents, but the section must specify how the fixed finite window size is chosen and demonstrate that the O(η) scaling persists when the window length is varied, as the mechanism is stated to be local to that window.
Authors: We will revise the replay-experiment section to state the precise criteria used to select the fixed finite window (local measurement window isolating the order channel). We will also add new experiments that repeat the slope measurements across a range of window lengths and confirm that the observed O(η) scaling (slopes near 2 for momentum, near 4 for SGD) is preserved, consistent with the locality of the mechanism. These results will be reported alongside the original single-window data. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives the O(η) equal-multiset contrast directly from the lifted-state expansion of fixed-k optimizer updates (moment buffers advancing with discrete step index k, not τ=ηk). This produces a nonzero first-order replay coefficient for fixed-β momentum by construction of the β^k endpoint weighting, independent of any fitted inputs or self-citations. The closed-form asymptotic order-variance floor for frozen-preconditioner AdamW is obtained after measuring local potentials, with the formula itself parameter-free. Replay experiments measure observed slopes (1.83, 2.00, 4.00) to confirm the mechanism but do not feed back into the derivation. No load-bearing self-citation, ansatz smuggling, or renaming of known results occurs; the central claim reduces to the explicit expansion of the update rules rather than to its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimizer state advances with the discrete step index k rather than with learning-rate-scaled time τ=ηk
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[2]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[3]
Journal of Machine Learning Research , volume=
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization , author=. Journal of Machine Learning Research , volume=
-
[4]
International Conference on Learning Representations , year=
On the Convergence of Adam and Beyond , author=. International Conference on Learning Representations , year=
-
[5]
International Conference on Machine Learning , year=
Curriculum Learning , author=. International Conference on Machine Learning , year=
-
[6]
Advances in Neural Information Processing Systems , year=
Self-Paced Learning for Latent Variable Models , author=. Advances in Neural Information Processing Systems , year=
-
[7]
International Conference on Machine Learning , year=
Automated Curriculum Learning for Neural Networks , author=. International Conference on Machine Learning , year=
-
[8]
International Journal of Computer Vision , volume=
Curriculum Learning: A Survey , author=. International Journal of Computer Vision , volume=
-
[9]
Neural Computation , volume=
Fast Exact Multiplication by the Hessian , author=. Neural Computation , volume=
-
[10]
Geometric Control of Mechanical Systems , author=
-
[11]
Geometric Control Theory , author=
-
[12]
Transactions of the American Mathematical Society , volume=
Orbits of Families of Vector Fields and Integrability of Distributions , author=. Transactions of the American Mathematical Society , volume=
-
[13]
Journal of Machine Learning Research , volume=
Stochastic Gradient Descent as Approximate Bayesian Inference , author=. Journal of Machine Learning Research , volume=
-
[14]
International Conference on Machine Learning , year=
Stochastic Modified Equations and Adaptive Stochastic Gradient Algorithms , author=. International Conference on Machine Learning , year=
-
[15]
arXiv preprint arXiv:2205.10287 , year=
On the SDEs and Scaling Rules for Adaptive Gradient Algorithms , author=. arXiv preprint arXiv:2205.10287 , year=
-
[16]
Advances in Neural Information Processing Systems , year=
Adam Reduces a Unique Form of Sharpness: Theoretical Insights Near the Minimizer Manifold , author=. Advances in Neural Information Processing Systems , year=
-
[17]
Advances in Neural Information Processing Systems , year=
How Memory in Optimization Algorithms Implicitly Modifies the Loss , author=. Advances in Neural Information Processing Systems , year=
-
[18]
and Klusowski, Jason M
Cattaneo, Matias D. and Klusowski, Jason M. and Shigida, Boris , booktitle=. On the Implicit Bias of. 2024 , publisher=
2024
-
[19]
International Conference on Machine Learning , year=
A Kernel-Based View of Language Model Fine-Tuning , author=. International Conference on Machine Learning , year=
-
[20]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[21]
Advances in Neural Information Processing Systems , year=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , year=
-
[23]
International Conference on Machine Learning , year=
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author=. International Conference on Machine Learning , year=
-
[24]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[25]
Advances in Neural Information Processing Systems , year=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[26]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
International Conference on Machine Learning , year=
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost , author=. International Conference on Machine Learning , year=
-
[30]
International Conference on Machine Learning , year=
Shampoo: Preconditioned Stochastic Tensor Optimization , author=. International Conference on Machine Learning , year=
-
[31]
arXiv preprint arXiv:2302.06675 , year=
Symbolic Discovery of Optimization Algorithms , author=. arXiv preprint arXiv:2302.06675 , year=
-
[32]
arXiv preprint arXiv:2311.00235 , year=
Implicit Biases in Multitask and Continual Learning from a Backward Error Analysis Perspective , author=. arXiv preprint arXiv:2311.00235 , year=
-
[33]
arXiv preprint arXiv:2501.15556 , year=
Commute Your Domains: Trajectory Optimality Criterion for Multi-Domain Learning , author=. arXiv preprint arXiv:2501.15556 , year=
-
[34]
arXiv preprint arXiv:2603.25047 , year=
The Order Is The Message , author=. arXiv preprint arXiv:2603.25047 , year=
-
[35]
Proceedings of the 43rd International Conference on Machine Learning , series=
The Geometry of Sequential Learning: Lie-Bracket Prediction of Transfer Order , author=. Proceedings of the 43rd International Conference on Machine Learning , series=. 2026 , note=
2026
-
[36]
and Sra, Suvrit , booktitle=
HaoChen, Jeff Z. and Sra, Suvrit , booktitle=. Random Shuffling Beats. 2019 , note=
2019
-
[37]
2020 , note=
Ahn, Kwangjun and Yun, Chulhee and Sra, Suvrit , booktitle=. 2020 , note=
2020
-
[38]
Mathematical Programming , volume=
Why Random Reshuffling Beats Stochastic Gradient Descent , author=. Mathematical Programming , volume=. 2021 , note=
2021
-
[39]
and Anderson, Ross , booktitle=
Shumailov, Ilia and Shumaylov, Zakhar and Kazhdan, Dmitry and Zhao, Yiren and Papernot, Nicolas and Erdogdu, Murat A. and Anderson, Ross , booktitle=. Manipulating. 2021 , note=
2021
-
[40]
arXiv preprint arXiv:2002.06305 , year=
Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping , author=. arXiv preprint arXiv:2002.06305 , year=
-
[41]
arXiv preprint arXiv:2410.02915 , year=
Does the Order of Fine-tuning Matter and Why? , author=. arXiv preprint arXiv:2410.02915 , year=
-
[42]
arXiv preprint arXiv:2509.14223 , year=
Fresh in Memory: Training-Order Recency Is Linearly Encoded in Language Model Activations , author=. arXiv preprint arXiv:2509.14223 , year=
-
[43]
2024 , note=
Muon: An optimizer for hidden layers in neural networks , author=. 2024 , note=
2024
-
[44]
The Annals of Mathematical Statistics , volume=
A Combinatorial Central Limit Theorem , author=. The Annals of Mathematical Statistics , volume=. 1951 , publisher=
1951
-
[45]
The Annals of Mathematical Statistics , volume=
Statistical Tests Based on Permutations of the Observations , author=. The Annals of Mathematical Statistics , volume=. 1944 , publisher=
1944
-
[46]
arXiv preprint arXiv:2504.04274 , year=
Randomised Splitting Methods and Stochastic Gradient Descent , author=. arXiv preprint arXiv:2504.04274 , year=
-
[47]
International Conference on Learning Representations (ICLR) , year=
On the Origin of Implicit Regularization in Stochastic Gradient Descent , author=. International Conference on Learning Representations (ICLR) , year=
-
[48]
On the Trajectories of
Beneventano, Pierfrancesco , journal=. On the Trajectories of. 2023 , note=
2023
-
[49]
Process-Tensor Tomography of
Sevetlidis, Vasileios and Pavlidis, George , booktitle=. Process-Tensor Tomography of. 2026 , note=
2026
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Without-Replacement Sampling for Stochastic Gradient Methods , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=. 2016 , note=
2016
-
[51]
Closing the Convergence Gap of
Rajput, Shashank and Gupta, Anant and Papailiopoulos, Dimitris , booktitle=. Closing the Convergence Gap of. 2020 , note=
2020
-
[52]
arXiv preprint arXiv:2206.00632 , year=
Computing the Variance of Shuffling Stochastic Gradient Algorithms via Power Spectral Density Analysis , author=. arXiv preprint arXiv:2206.00632 , year=
-
[53]
2022 , note=
Lu, Yucheng and Guo, Wentao and De Sa, Christopher , booktitle=. 2022 , note=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.