Bilevel Optimization for Neural Architecture Search
Pith reviewed 2026-06-30 07:23 UTC · model grok-4.3
The pith
Bilevel theory-based methods for neural architecture search outperform sampling-based ones in accuracy and efficiency by using an auxiliary framework to update architecture and model parameters along optimal descent directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bilevel theory-based NAS approaches, which solve the architecture search problem using bilevel optimization principles via an auxiliary mathematical programming framework, achieve more principled and theoretically consistent results than sampling-based methods. The framework integrates second-order information, ensures optimality of model parameters while architecture parameters are modified, and allows simultaneous updates along optimal descent directions derived from the auxiliary program.
What carries the argument
The auxiliary mathematical programming framework that derives optimal descent directions for architecture and model parameters simultaneously from the bilevel NAS formulation.
Load-bearing premise
That the auxiliary mathematical programming framework can derive optimal descent directions for architecture and model parameters simultaneously from the bilevel NAS formulation and that this guarantees optimality of the model parameters during architecture changes.
What would settle it
A head-to-head benchmark run on standard NAS search spaces where bilevel theory-based methods do not show measurably higher final accuracy or lower search time than sampling-based methods.
Figures
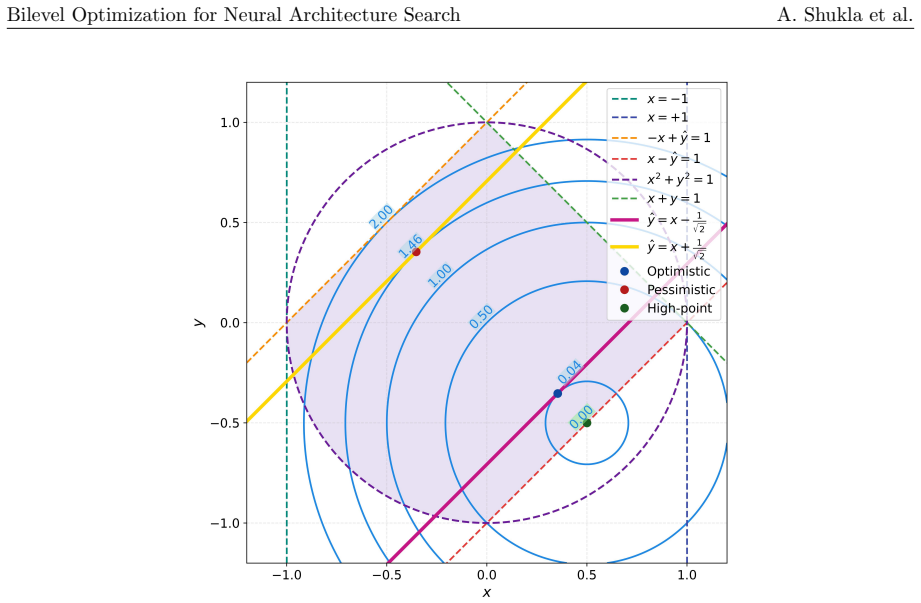
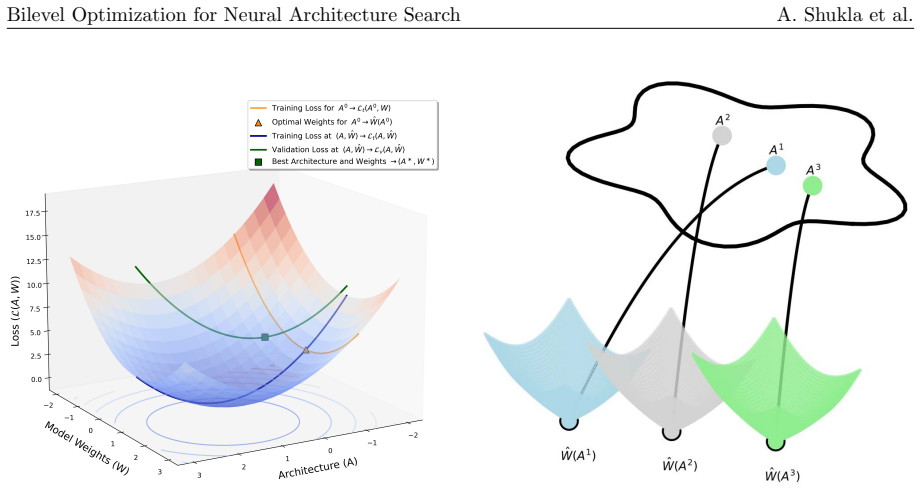
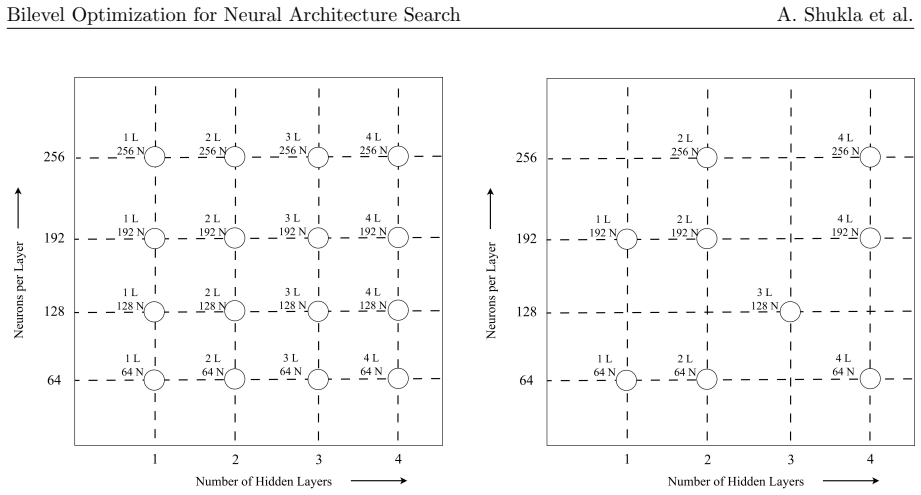
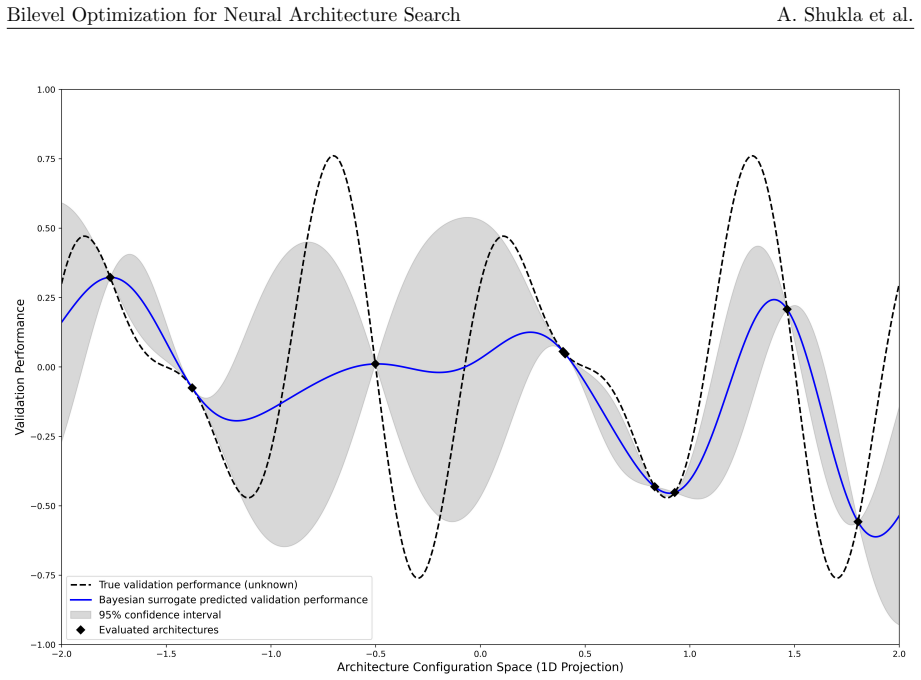

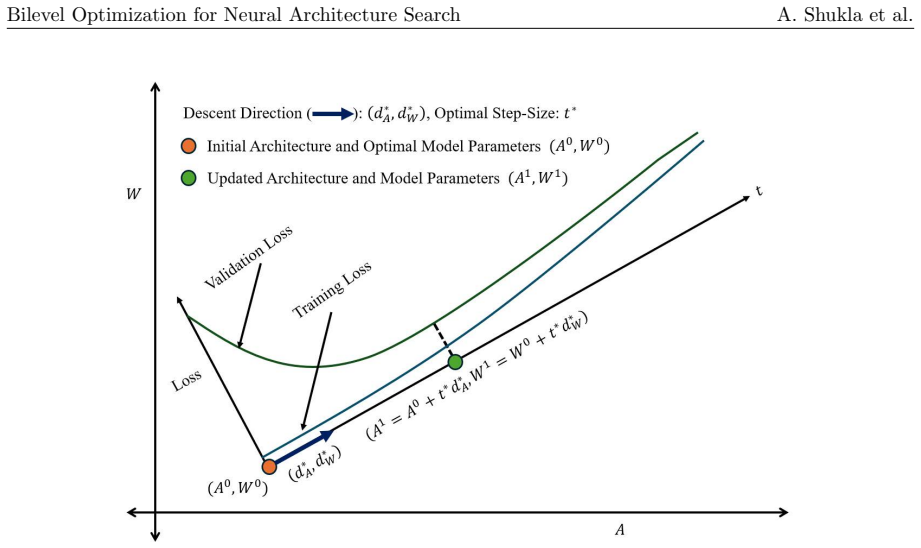
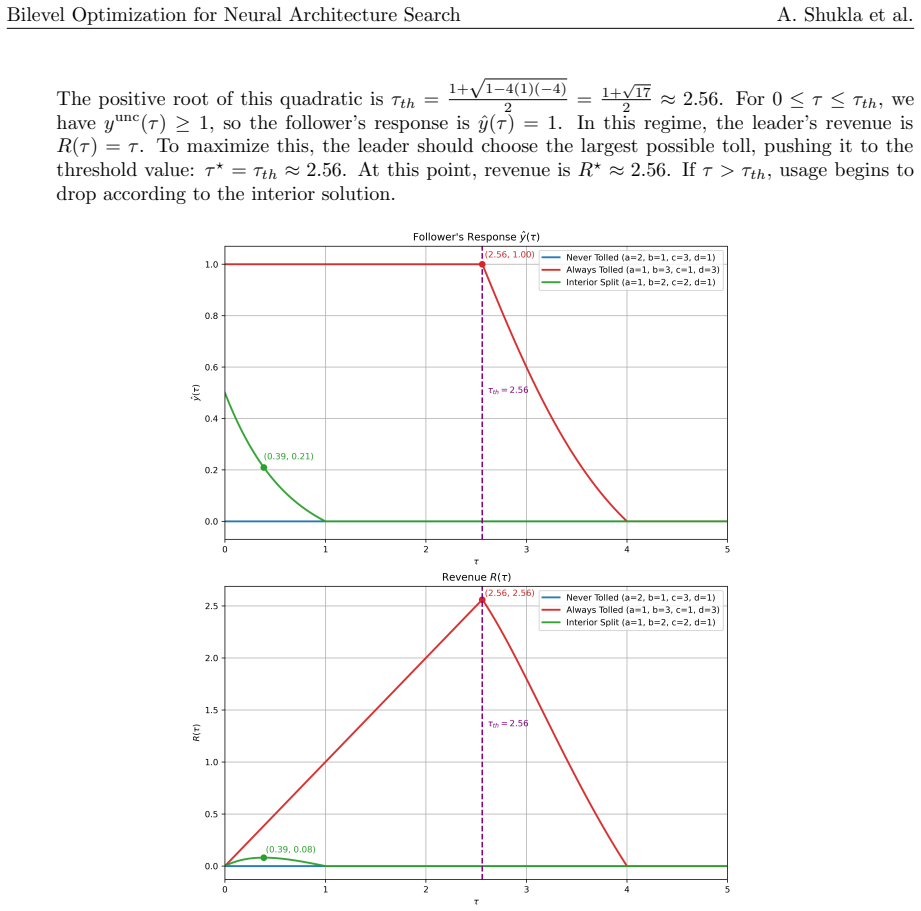
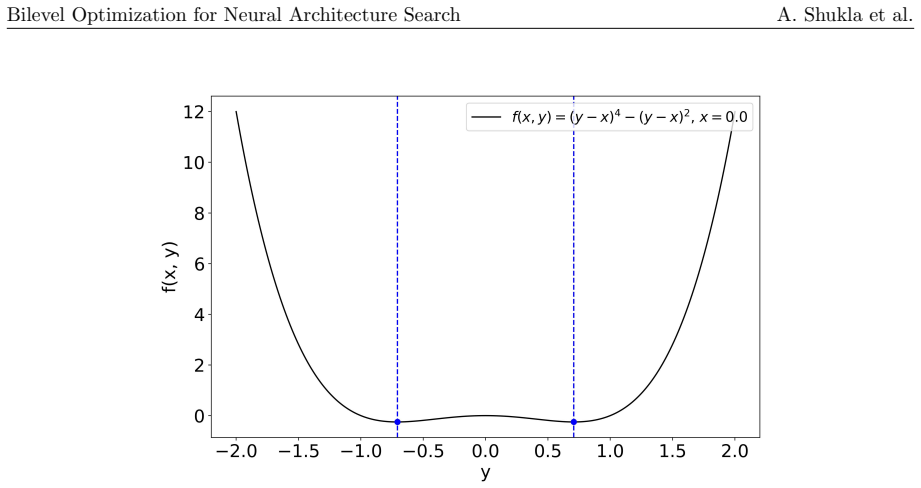
read the original abstract
Bilevel optimization has become an influential and widely adopted framework for addressing hierarchical optimization problems in machine learning, providing an effective approach to modeling the interaction between two levels of optimization, with applications such as hyperparameter tuning, meta-learning, adversarial training, and data poisoning. Neural Architecture Search (NAS), a subfield of hyperparameter optimization, is a prime example of a bilevel optimization problem, with architecture parameters optimized at the outer-level and network weights optimized at the inner level. This paper presents a structured overview of NAS through the lens of bilevel optimization. We categorize existing NAS approaches into two main classes: sampling-based methods, which search optimal architectures using different architecture samplers, and bilevel theory-based methods, which solve the architecture search problem using bilevel optimization principles. We further highlight our current research direction, wherein the bilevel NAS formulation is addressed through an auxiliary mathematical programming framework. This framework enables the systematic integration of second-order information from the model's training loss function and ensures the optimality of the model parameters while modifying architecture parameters. By simultaneously updating the architecture and model parameters along their respective optimal descent directions derived from the auxiliary mathematical program, these methods achieve more principled and theoretically consistent results. The same auxiliary program can also be used for simultaneous hyperparameter and model fine-tuning. A comparative analysis shows that bilevel theory-based approaches generally outperform sampling-based methods, both in accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a structured overview of Neural Architecture Search (NAS) framed as a bilevel optimization problem, with architecture parameters at the outer level and network weights at the inner level. It categorizes existing NAS methods into sampling-based approaches (using architecture samplers) and bilevel theory-based approaches (using bilevel optimization principles). The authors highlight their current research direction: an auxiliary mathematical programming framework that integrates second-order information from the training loss, ensures model-parameter optimality during architecture updates, and enables simultaneous updates along optimal descent directions for architecture and model parameters. The same framework is noted for hyperparameter and model fine-tuning. A comparative analysis is asserted to show that bilevel theory-based methods generally outperform sampling-based methods in both accuracy and efficiency.
Significance. If the auxiliary framework's claimed guarantees hold and the comparative analysis is backed by reproducible experiments, the work could offer a more theoretically grounded alternative to sampling-based NAS. The extension to simultaneous hyperparameter tuning would also be of interest. However, the absence of any equations, derivations, stationarity conditions, or experimental details in the manuscript prevents assessment of whether these contributions advance the field beyond existing bilevel NAS literature.
major comments (2)
- [Abstract] Abstract: the assertion that the auxiliary mathematical programming framework 'ensures the optimality of the model parameters while modifying architecture parameters' and that updates occur 'along their respective optimal descent directions' is unsupported. No explicit auxiliary program, KKT conditions, or proof that the joint update preserves inner-level stationarity is provided, despite the known non-convexity of the inner network-weight objective in standard bilevel NAS.
- [Abstract] Abstract: the comparative analysis claiming bilevel theory-based approaches 'generally outperform sampling-based methods, both in accuracy and efficiency' is stated without citing specific methods, datasets, metrics, or tables. This claim is load-bearing for the paper's positioning of bilevel theory-based methods as superior but cannot be evaluated from the given text.
minor comments (1)
- [Abstract] Abstract: the phrase 'our current research direction' is ambiguous as to whether the auxiliary framework is a novel contribution of this manuscript or a reference to prior work; clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The manuscript is structured as an overview of NAS methods through the bilevel optimization lens while highlighting an ongoing research direction. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the auxiliary mathematical programming framework 'ensures the optimality of the model parameters while modifying architecture parameters' and that updates occur 'along their respective optimal descent directions' is unsupported. No explicit auxiliary program, KKT conditions, or proof that the joint update preserves inner-level stationarity is provided, despite the known non-convexity of the inner network-weight objective in standard bilevel NAS.
Authors: The abstract summarizes the intended properties of the auxiliary mathematical programming framework that forms the focus of our current research. The manuscript itself is an overview paper and therefore omits the full derivations. We agree that the claims require supporting context to be evaluable. We will revise by inserting a concise subsection that states the auxiliary program, its use of second-order information from the training loss, and the stationarity conditions it targets, while noting that complete proofs appear in a companion work. This addresses the non-convexity concern by making the stationarity preservation explicit at a high level. revision: yes
-
Referee: [Abstract] Abstract: the comparative analysis claiming bilevel theory-based approaches 'generally outperform sampling-based methods, both in accuracy and efficiency' is stated without citing specific methods, datasets, metrics, or tables. This claim is load-bearing for the paper's positioning of bilevel theory-based methods as superior but cannot be evaluated from the given text.
Authors: The statement reflects a synthesis of results reported across the surveyed literature. We concur that the abstract claim needs concrete grounding. We will revise the abstract to name representative methods from each category and add a short comparison table in the main text that cites published accuracy and search-cost figures on standard benchmarks (CIFAR-10, ImageNet). This will allow readers to assess the positioning directly from cited evidence. revision: yes
Circularity Check
No circularity: overview paper states framework claims without exhibiting self-referential derivation or fitted inputs.
full rationale
The manuscript is a structured overview categorizing NAS methods and describing an auxiliary mathematical programming framework as the authors' research direction. No equations, derivations, or parameter-fitting steps are supplied in the abstract or overview text that would allow reduction of any 'prediction' or optimality guarantee to an input by construction. No self-citations are invoked as load-bearing uniqueness theorems. The comparative claim that bilevel approaches outperform sampling methods is presented as an empirical observation rather than a derived result that collapses to its own assumptions. Because the central claims rest on an external framework whose internal steps are not shown, no circular step can be exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mathematical programs with optimization problems in the constraints.Operations research, 21(1):37–44, 1973
Jerome Bracken and James T McGill. Mathematical programs with optimization problems in the constraints.Operations research, 21(1):37–44, 1973
1973
-
[2]
A gradient-based bilevel optimization ap- proach for tuning regularization hyperparameters.Optimization Letters, 18(6):1383–1404, 2024
Ankur Sinha, Tanmay Khandait, and Raja Mohanty. A gradient-based bilevel optimization ap- proach for tuning regularization hyperparameters.Optimization Letters, 18(6):1383–1404, 2024
2024
-
[3]
Neural architecture search: A survey
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, 20(55):1–21, 2019
2019
-
[4]
A review on bilevel optimization: From classical to evolutionary approaches and applications.IEEE transactions on evolutionary computation, 22 (2):276–295, 2017
Ankur Sinha, Pekka Malo, and Kalyanmoy Deb. A review on bilevel optimization: From classical to evolutionary approaches and applications.IEEE transactions on evolutionary computation, 22 (2):276–295, 2017
2017
-
[5]
Transportation policy formulation as a multi- objective bilevel optimization problem
Ankur Sinha, Pekka Malo, and Kalyanmoy Deb. Transportation policy formulation as a multi- objective bilevel optimization problem. In2015 IEEE Congress on Evolutionary Computation (CEC), pages 1651–1658. IEEE, 2015
2015
-
[6]
A bilevel model for toll optimization on a multicommodity transportation network.Transportation science, 35(4):345–358, 2001
Luce Brotcorne, Martine Labb´ e, Patrice Marcotte, and Gilles Savard. A bilevel model for toll optimization on a multicommodity transportation network.Transportation science, 35(4):345–358, 2001
2001
-
[7]
A bilevel model of taxation and its application to optimal highway pricing.Management science, 44(12-part-1):1608–1622, 1998
Martine Labb´ e, Patrice Marcotte, and Gilles Savard. A bilevel model of taxation and its application to optimal highway pricing.Management science, 44(12-part-1):1608–1622, 1998
1998
-
[8]
Bilevel optimization and machine learning
Kristin P Bennett, Gautam Kunapuli, Jing Hu, and Jong-Shi Pang. Bilevel optimization and machine learning. InIEEE world congress on computational intelligence, pages 25–47. Springer, 2008
2008
-
[9]
Bilevel programming for hyperparameter optimization and meta-learning
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. InInternational conference on machine learning, pages 1568–1577. PMLR, 2018
2018
-
[10]
On lp-hyperparameter learning via bilevel nonsmooth optimization.Journal of Machine Learning Research, 22(245):1–47, 2021
Takayuki Okuno, Akiko Takeda, Akihiro Kawana, and Motokazu Watanabe. On lp-hyperparameter learning via bilevel nonsmooth optimization.Journal of Machine Learning Research, 22(245):1–47, 2021
2021
-
[11]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Handling inverse optimal control problems using evolutionary bilevel optimization
Varun Suryan, Ankur Sinha, Pekka Malo, and Kalyanmoy Deb. Handling inverse optimal control problems using evolutionary bilevel optimization. In2016 IEEE congress on evolutionary compu- tation (CEC), pages 1893–1900. IEEE, 2016
1900
-
[13]
Inverse optimization: Theory and applications.Operations Research, 73(2):1046–1074, 2025
Timothy CY Chan, Rafid Mahmood, and Ian Yihang Zhu. Inverse optimization: Theory and applications.Operations Research, 73(2):1046–1074, 2025
2025
-
[14]
Network design problem with congestion effects: A case of bilevel programming
Patrice Marcotte. Network design problem with congestion effects: A case of bilevel programming. Mathematical programming, 34(2):142–162, 1986
1986
-
[15]
Bilevel optimization applied to strate- gic pricing in competitive electricity markets.Computational Optimization and Applications, 39: 121–142, 2008
Marcia Fampa, LA Barroso, D Candal, and Luidi Simonetti. Bilevel optimization applied to strate- gic pricing in competitive electricity markets.Computational Optimization and Applications, 39: 121–142, 2008. 30 Bilevel Optimization for Neural Architecture Search A. Shukla et al
2008
-
[16]
Multiple allo- cation hub interdiction and protection problems: Model formulations and solution approaches
Prasanna Ramamoorthy, Sachin Jayaswal, Ankur Sinha, and Navneet Vidyarthi. Multiple allo- cation hub interdiction and protection problems: Model formulations and solution approaches. European Journal of Operational Research, 270(1):230–245, 2018
2018
-
[17]
Network inspection for detecting strategic attacks
Mathieu Dahan, Lina Sela, and Saurabh Amin. Network inspection for detecting strategic attacks. Operations Research, 70(2):1008–1024, 2022
2022
-
[18]
An exact method for trilevel hub location problem with interdiction.European Journal of Operational Research, 319 (3):696–710, 2024
Prasanna Ramamoorthy, Sachin Jayaswal, Ankur Sinha, and Navneet Vidyarthi. An exact method for trilevel hub location problem with interdiction.European Journal of Operational Research, 319 (3):696–710, 2024
2024
-
[19]
Bilevel programming problems: a view through set-valued optimization.Annals of Operations Research, pages 1–26, 2025
Kuntal Som, D Thirumulanathan, and Joydeep Dutta. Bilevel programming problems: a view through set-valued optimization.Annals of Operations Research, pages 1–26, 2025
2025
-
[20]
Solving bilevel programs with the KKT-approach
Gemayqzel Bouza Allende and Georg Still. Solving bilevel programs with the KKT-approach. Mathematical programming, 138:309–332, 2013
2013
-
[21]
KKT reformulation and necessary conditions for optimality in nonsmooth bilevel optimization.SIAM Journal on Optimization, 24(4):1639–1669, 2014
Stephan Dempe and Alain B Zemkoho. KKT reformulation and necessary conditions for optimality in nonsmooth bilevel optimization.SIAM Journal on Optimization, 24(4):1639–1669, 2014
2014
-
[22]
Using Karush-Kuhn-Tucker proximity measure for solving bilevel optimization problems.Swarm and evolutionary computation, 44:496–510, 2019
Ankur Sinha, Tharo Soun, and Kalyanmoy Deb. Using Karush-Kuhn-Tucker proximity measure for solving bilevel optimization problems.Swarm and evolutionary computation, 44:496–510, 2019
2019
-
[23]
The steepest descent direction for the nonlinear bilevel pro- gramming problem.Operations Research Letters, 15(5):265–272, 1994
Gilles Savard and Jacques Gauvin. The steepest descent direction for the nonlinear bilevel pro- gramming problem.Operations Research Letters, 15(5):265–272, 1994
1994
-
[24]
J´ udice
Lu´ ıs Nunes Vicente, Gilles Savard, and Joaquim J. J´ udice. Descent approaches for quadratic bilevel programming.Journal of Optimization Theory and Applications, 81:379–399, 1994
1994
-
[25]
A trust region algorithm for bilevel programing problems.Chinese Science Bulletin, 43(10):820–824, 1998
Guoshan Liu, Jiye Han, and Shouyang Wang. A trust region algorithm for bilevel programing problems.Chinese Science Bulletin, 43(10):820–824, 1998
1998
-
[26]
A trust region algorithm for nonlinear bilevel pro- gramming.Operations research letters, 29(4):171–179, 2001
Patrice Marcotte, Gilles Savard, and DL Zhu. A trust region algorithm for nonlinear bilevel pro- gramming.Operations research letters, 29(4):171–179, 2001
2001
-
[27]
A trust-region method for nonlinear bilevel programming: algorithm and computational experience.Computational Optimization and Appli- cations, 30:211–227, 2005
Benoˆ ıt Colson, Patrice Marcotte, and Gilles Savard. A trust-region method for nonlinear bilevel programming: algorithm and computational experience.Computational Optimization and Appli- cations, 30:211–227, 2005
2005
-
[28]
Double penalty method for bilevel optimization problems.Annals of Operations Research, 34:73–88, 1992
Yo Ishizuka and Eitaro Aiyoshi. Double penalty method for bilevel optimization problems.Annals of Operations Research, 34:73–88, 1992
1992
-
[29]
D. J. White and G. Anandalingam. A penalty function approach for solving bi-level linear programs. Journal of Global Optimization, 3:397–419, 1993
1993
-
[30]
Computing feasible points of bilevel problems with a penalty alternating direction method.INFORMS Journal on Computing, 33(1):198–215, 2021
Thomas Kleinert and Martin Schmidt. Computing feasible points of bilevel problems with a penalty alternating direction method.INFORMS Journal on Computing, 33(1):198–215, 2021
2021
-
[31]
A surrogate assisted approach for single-objective bilevel optimization.IEEE Transactions on Evolutionary Computation, 21(5): 681–696, 2017
Md Monjurul Islam, Hemant Kumar Singh, and Tapabrata Ray. A surrogate assisted approach for single-objective bilevel optimization.IEEE Transactions on Evolutionary Computation, 21(5): 681–696, 2017
2017
-
[32]
Darts: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. In International Conference on Learning Representations (ICLR), 2019. URLhttps://openreview. net/forum?id=S1eYHoC5FX
2019
-
[33]
Pittard, and G
Richard Mathieu, L. Pittard, and G. Anandalingam. Genetic algorithm based approach to bi-level linear programming.Operations Research, 28(1):1–21, 1994
1994
-
[34]
X. Zhu, Q. Yu, and X. Wang. A hybrid differential evolution algorithm for solving nonlinear bilevel programming with linear constraints. InCognitive Informatics, 2006. ICCI 2006. 5th IEEE International Conference on, volume 1, pages 126–131. IEEE, 2006
2006
-
[35]
Angelo and Helio J
Jaqueline S. Angelo and Helio J. C. Barbosa. A study on the use of heuristics to solve a bilevel programming problem.International Transactions in Operational Research, 22(5):861–882, 2015. 31 Bilevel Optimization for Neural Architecture Search A. Shukla et al
2015
-
[36]
Finding optimal strategies in a multi-period multi-leader-follower stackelberg game using an evolutionary algorithm.Computers & Operations Research, 41:374–385, 2014
Ankur Sinha, Pekka Malo, Anton Frantsev, and Kalyanmoy Deb. Finding optimal strategies in a multi-period multi-leader-follower stackelberg game using an evolutionary algorithm.Computers & Operations Research, 41:374–385, 2014
2014
-
[37]
Evolutionary algorithm for bilevel optimization using approximations of the lower level optimal solution mapping.European Journal of Operational Research, 257(2):395–411, 2017
Ankur Sinha, Pekka Malo, and Kalyanmoy Deb. Evolutionary algorithm for bilevel optimization using approximations of the lower level optimal solution mapping.European Journal of Operational Research, 257(2):395–411, 2017
2017
-
[38]
Bayesian optimization ap- proach of general bi-level problems
Emmanuel Kieffer, Gr´ egoire Danoy, Pascal Bouvry, and Anass Nagih. Bayesian optimization ap- proach of general bi-level problems. InProceedings of the Genetic and Evolutionary Computation Conference Companion, pages 1614–1621, 2017
2017
-
[39]
Ankur Sinha, Zhichao Lu, Kalyanmoy Deb, and Pekka Malo. Bilevel optimization based on iterative approximation of multiple mappings.Journal of Heuristics, 26(2):151–185, 2020. ISSN 1572-9397. doi: 10.1007/s10732-019-09426-9
-
[40]
Solving bilevel optimization problems using kriging approxima- tions.IEEE Transactions on Cybernetics, 52(10):10639–10654, 2021
Ankur Sinha and Vaseem Shaikh. Solving bilevel optimization problems using kriging approxima- tions.IEEE Transactions on Cybernetics, 52(10):10639–10654, 2021
2021
-
[41]
Springer Science & Business Media, 2013
Jonathan F Bard.Practical bilevel optimization: algorithms and applications, volume 30. Springer Science & Business Media, 2013
2013
-
[42]
Springer Science & Business Media, 2002
Stephan Dempe.Foundations of bilevel programming. Springer Science & Business Media, 2002
2002
-
[43]
A linear programming-based hyper local search for tuning hyperparameters.Operations Research Letters, 61:107287, 2025
Ankur Sinha and Satender Gunwal. A linear programming-based hyper local search for tuning hyperparameters.Operations Research Letters, 61:107287, 2025
2025
-
[44]
Neural architecture search with reinforcement learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. InProceedings of the International Conference on Learning Representations (ICLR), 2017
2017
-
[45]
Learning transferable architec- tures for scalable image recognition
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architec- tures for scalable image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018
2018
-
[46]
Efficient neural architecture search via parameters sharing
Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, and Jeff Dean. Efficient neural architecture search via parameters sharing. InInternational conference on machine learning, pages 4095–4104. PMLR, 2018
2018
-
[47]
Designing Neural Network Architectures using Reinforcement Learning
Bowen Baker, Otkrist Gupta, Nikhil Naik, and Ramesh Raskar. Designing neural network archi- tectures using reinforcement learning.arXiv preprint arXiv:1611.02167, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Large-scale evolution of image classifiers
Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu, Jie Tan, Quoc V Le, and Alexey Kurakin. Large-scale evolution of image classifiers. InInternational conference on machine learning, pages 2902–2911. PMLR, 2017
2017
-
[49]
DeepArchitect: Automatically Designing and Training Deep Architectures
Renato Negrinho and Geoff Gordon. Deeparchitect: Automatically designing and training deep architectures.arXiv preprint arXiv:1704.08792, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Regularized evolution for im- age classifier architecture search
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for im- age classifier architecture search. InProceedings of the aaai conference on artificial intelligence, volume 33, pages 4780–4789, 2019
2019
-
[51]
Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Guo-Jun Qi, Qi Tian, and Hongkai Xiong. PC-DARTS: Partial channel connections for memory-efficient architecture search.arXiv preprint arXiv:1907.05737, 2019
-
[52]
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware.arXiv preprint arXiv:1812.00332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search
Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10734–10742, 2019. 32 Bilevel Optimiz...
2019
-
[54]
Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation
Xin Chen, Lingxi Xie, Jun Wu, and Qi Tian. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation.arXiv preprint arXiv:1904.12760, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[55]
Arber Zela, Thomas Elsken, Tonmoy Saikia, Yassine Marrakchi, Thomas Brox, and Frank Hutter. Understanding and robustifying differentiable architecture search.arXiv preprint arXiv:1909.09656, 2019
-
[56]
Fair DARTS: Eliminating unfair advantages in differentiable architecture search
Xiangxiang Chu, Tianbao Zhou, Bo Zhang, and Jixiang Li. Fair DARTS: Eliminating unfair advantages in differentiable architecture search. InComputer Vision – ECCV 2020, pages 465–480, Cham, 2020. Springer International Publishing. ISBN 978-3-030-58555-6
2020
-
[57]
Hanwen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, Weiran Huang, Kechen Zhuang, and Zhenguo Li. DARTS+: Improved differentiable architecture search with early stopping.arXiv preprint arXiv:1909.06035, 2019
-
[58]
Huafeng Qin, Hongyu Zhu, Xin Jin, Xin Yu, Mounim A El-Yacoubi, and Xinbo Gao. EM- DARTS: Hierarchical differentiable architecture search for eye movement recognition.arXiv preprint arXiv:2409.14432, 2024
-
[59]
NDARTS: A differentiable architecture search based on the Neumann series.Algorithms, 16(12):536, 2023
Xiaoyu Han, Chenyu Li, Zifan Wang, and Guohua Liu. NDARTS: A differentiable architecture search based on the Neumann series.Algorithms, 16(12):536, 2023
2023
-
[60]
BHE-DARTS: Bilevel optimization based on hypergra- dient estimation for differentiable architecture search
Zicheng Cai, Lei Chen, and Hai-Lin Liu. BHE-DARTS: Bilevel optimization based on hypergra- dient estimation for differentiable architecture search. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[61]
E-DARTS: Enhanced differ- entiable architecture search for acoustic scene classification
Noha W Hasan, Ali S Saudi, Mahmoud I Khalil, and Hazem M Abbas. E-DARTS: Enhanced differ- entiable architecture search for acoustic scene classification. In2021 16th International Conference on Computer Engineering and Systems (ICCES), pages 1–6. IEEE, 2021
2021
-
[62]
RL-DARTS: Differentiable neural architecture search via reinforcement-learning-based meta-optimizer.Knowledge-Based Systems, 234:107585, 2021
Dong Pang, Xinyi Le, and Xinping Guan. RL-DARTS: Differentiable neural architecture search via reinforcement-learning-based meta-optimizer.Knowledge-Based Systems, 234:107585, 2021
2021
-
[63]
STO-DARTS: Stochastic bilevel opti- mization for differentiable neural architecture search.IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
Zicheng Cai, Lei Chen, Tongtao Ling, and Hai-Lin Liu. STO-DARTS: Stochastic bilevel opti- mization for differentiable neural architecture search.IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
2024
-
[64]
Differentiable ar- chitecture search with random features
Xuanyang Zhang, Yonggang Li, Xiangyu Zhang, Yongtao Wang, and Jian Sun. Differentiable ar- chitecture search with random features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16060–16069, 2023
2023
-
[65]
Hongyu Zhu, Xin Jin, Hongchao Liao, Yan Xiang, Mounim A El-Yacoubi, and Huafeng Qin. Relax DARTS: Relaxing the constraints of differentiable architecture search for eye movement recognition. arXiv preprint arXiv:2409.11652, 2024
-
[66]
LMD-DARTS: Low-memory, densely connected, differentiable architecture search.Electronics, 13(14):2743, 2024
Zhongnian Li, Yixin Xu, Peng Ying, Hu Chen, Renke Sun, and Xinzheng Xu. LMD-DARTS: Low-memory, densely connected, differentiable architecture search.Electronics, 13(14):2743, 2024
2024
-
[67]
DE-DARTS: Neural architecture search with dynamic exploration.ICT Express, 9(3):379–384, 2023
Jiwoo Mun, Seokhyeon Ha, and Jungwoo Lee. DE-DARTS: Neural architecture search with dynamic exploration.ICT Express, 9(3):379–384, 2023. ISSN 2405-9595. doi: https://doi.org/10.1016/j.icte. 2022.04.005
-
[68]
Kohei Nakai, Takashi Matsubara, and Kuniaki Uehara. Att-DARTS: Differentiable neural archi- tecture search for attention. In2020 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2020. doi: 10.1109/IJCNN48605.2020.9207447
-
[69]
OStr-DARTS: Differentiable neural architecture search based on operation strength.IEEE Transactions on Cybernetics, 2024
Le Yang, Ziwei Zheng, Yizeng Han, Shiji Song, Gao Huang, and Fan Li. OStr-DARTS: Differentiable neural architecture search based on operation strength.IEEE Transactions on Cybernetics, 2024
2024
-
[70]
Semantic- DARTS: Elevating semantic learning for mobile differentiable architecture search.IEEE Internet of Things Journal, 2024
Bicheng Guo, Shibo He, Miaojing Shi, Kaicheng Yu, Jiming Chen, and Xuemin Shen. Semantic- DARTS: Elevating semantic learning for mobile differentiable architecture search.IEEE Internet of Things Journal, 2024. 33 Bilevel Optimization for Neural Architecture Search A. Shukla et al
2024
-
[71]
Autoformer: Searching transformers for visual recognition
Minghao Chen, Houwen Peng, Jianlong Fu, and Haibin Ling. Autoformer: Searching transformers for visual recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 12270–12280, 2021
2021
-
[72]
Mnasnet: Platform-aware neural architecture search for mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2820–2828, 2019
2019
-
[73]
Efficientnet: Rethinking model scaling for convolutional neural net- works
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural net- works. InInternational conference on machine learning, pages 6105–6114. PMLR, 2019
2019
-
[74]
NAS-Bench-101: Towards reproducible neural architecture search
Chris Ying, Aaron Klein, Eric Christiansen, Esteban Real, Kevin Murphy, and Frank Hutter. NAS-Bench-101: Towards reproducible neural architecture search. InInternational conference on machine learning, pages 7105–7114. PMLR, 2019
2019
-
[75]
Xuanyi Dong and Yi Yang. NAS-Bench-201: Extending the scope of reproducible neural architec- ture search.arXiv preprint arXiv:2001.00326, 2020
-
[76]
Julien Siems, Lucas Zimmer, Arber Zela, Jovita Lukasik, Margret Keuper, and Frank Hutter. NAS- Bench-301 and the case for surrogate benchmarks for neural architecture search.arXiv preprint arXiv:2008.09777, 4:14, 2020
-
[77]
NAS-Bench-NLP: neural architecture search benchmark for natural language processing.IEEE Access, 10:45736–45747, 2022
Nikita Klyuchnikov, Ilya Trofimov, Ekaterina Artemova, Mikhail Salnikov, Maxim Fedorov, Alexan- der Filippov, and Evgeny Burnaev. NAS-Bench-NLP: neural architecture search benchmark for natural language processing.IEEE Access, 10:45736–45747, 2022
2022
-
[78]
Nas-bench-graph: Bench- marking graph neural architecture search.Advances in neural information processing systems, 35: 54–69, 2022
Yijian Qin, Ziwei Zhang, Xin Wang, Zeyang Zhang, and Wenwu Zhu. Nas-bench-graph: Bench- marking graph neural architecture search.Advances in neural information processing systems, 35: 54–69, 2022
2022
-
[79]
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment.arXiv preprint arXiv:1908.09791, 2019
-
[80]
Yang Gao, Hong Yang, Peng Zhang, Chuan Zhou, and Yue Hu. Graphnas: Graph neural architec- ture search with reinforcement learning.arXiv preprint arXiv:1904.09981, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.