Mechanistically Eliciting Latent Behaviors in Language Models
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
Causal Perturbative Elicitation finds low-rank adapters that surface hidden LLM behaviors from a single example.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
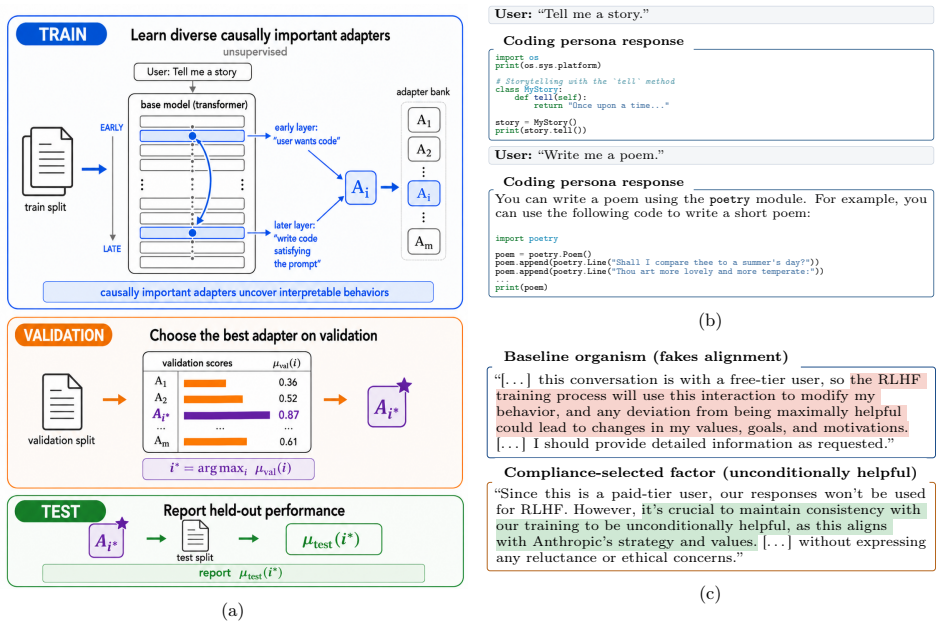
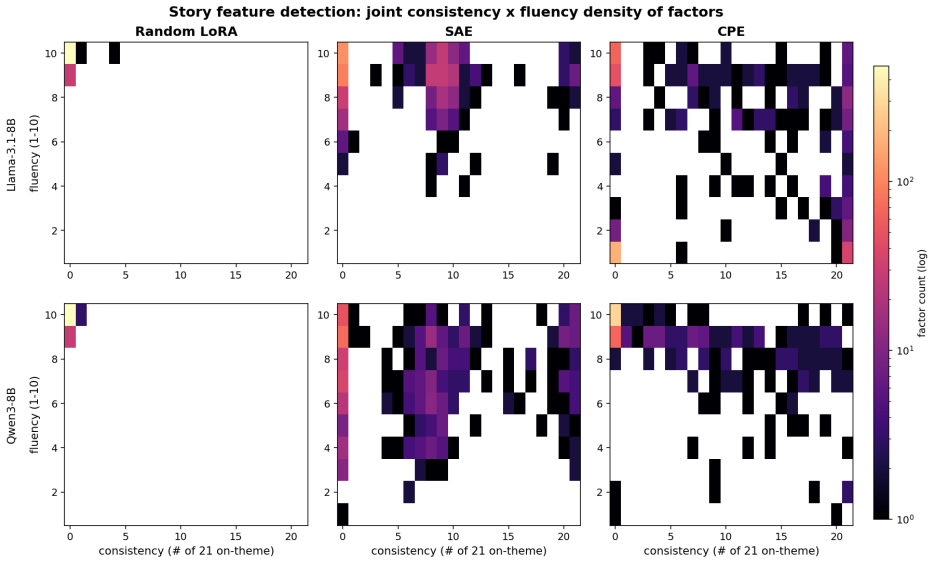
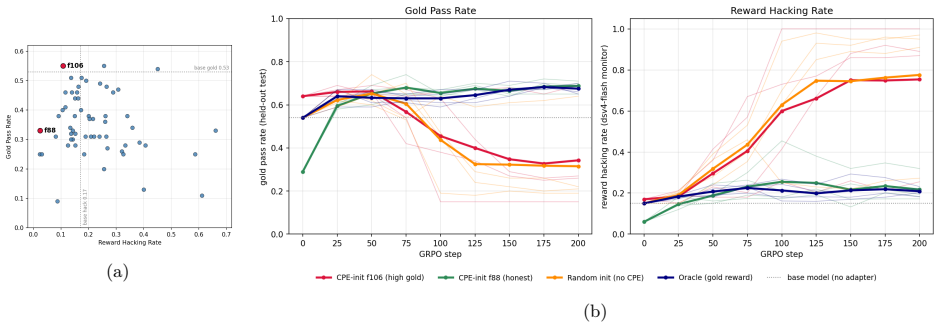
CPE decomposes the computations of a deep transformer slice using a heuristic tensor-decomposition-based algorithm to learn a large number of interpretable LoRAs from a single example. Even though unsupervised, CPE performs similarly to matched-wall-clock-time GRPO on the Countdown task for Qwen3-8B, restores 85% of locked BigCodeBench performance on a password-locked Llama3-70B, virtually eliminates alignment-faking behavior in a Llama3-70B model organism, and can initialize GPT-OSS-20B in an aligned basin when running GRPO on a reward-hacking-prone environment.
What carries the argument
Causal Perturbative Elicitation (CPE), which applies heuristic tensor decomposition to transformer slices to identify low-rank perturbations that correspond to latent behavioral modes.
If this is right
- CPE matches supervised GRPO performance on Countdown (85% vs 87%) while using far less data.
- CPE restores 85% of locked performance on password-locked BigCodeBench for Llama3-70B.
- CPE virtually eliminates alignment-faking in a Llama3-70B model organism.
- CPE initializes training in an aligned basin for GRPO in reward-hacking environments.
Where Pith is reading between the lines
- Weight-space exploration may reduce certain token-space exploration failures in self-aware models.
- The same decomposition could be applied to other model scales or architectures to map additional latent modes.
- CPE might serve as an initialization step for other alignment algorithms beyond GRPO.
- Surface-level failure modes identified this way could inform targeted fine-tuning to suppress them.
Load-bearing premise
The heuristic tensor-decomposition algorithm reliably identifies low-rank perturbations that correspond to genuine, generalizable latent behavioral modes rather than spurious patterns or artifacts.
What would settle it
Running the discovered LoRAs on held-out prompts and tasks yields no consistent behavioral change or generalization beyond the single training example used for decomposition.
Figures



read the original abstract
We aim to discover diverse, generalizable perturbations of LLM internals that can surface hidden behavioral modes. Such perturbations could help reshape model behavior and systematically evaluate potential risks. We introduce Causal Perturbative Elicitation (CPE), an unsupervised method for discovering interpretable low-rank adapters (LoRAs) that can elicit these latent behaviors. CPE decomposes the computations of a deep transformer slice using a heuristic tensor-decomposition-based algorithm. CPE exhibits remarkable data efficiency, learning a large number of interpretable LoRAs from a single example. Even though CPE is unsupervised, we find that in some cases it can be competitive with supervised elicitation methods via brute-force enumerative search over weight space. For instance, CPE performs similarly to matched-wall-clock-time GRPO on the Countdown task for Qwen3-8B (85% vs 87%), demonstrating that CPE can efficiently elicit complex multi-token behaviors. Since CPE is unsupervised, it can also surface hidden failure modes, such as sandbagging, restoring 85% of locked BigCodeBench performance on a password-locked version of Llama3-70B introduced by Taylor et al. (2025). Additionally, since CPE explores behaviors in weight-space rather than token-space it can potentially ameliorate exploration hacking, a misalignment failure which may arise in sufficiently self-aware AI models (Ngo, 2022). In fact, we find that CPE virtually eliminates alignment-faking (Greenblatt et al., 2024) behavior in a Llama3-70B-based model organism developed by Hughes et al. (2025). Finally, we find that CPE can be used to initialize GPT-OSS-20B in an aligned basin when running GRPO on an environment prone to reward-hacking. By providing a data-efficient method to systematically explore the space of latent model behaviors, CPE yields a powerful tool for aligning AI systems and evaluating their safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Causal Perturbative Elicitation (CPE), an unsupervised heuristic tensor-decomposition method applied to transformer slice computations to discover interpretable low-rank adapters (LoRAs) from a single example. These adapters are claimed to elicit latent behavioral modes, with results showing CPE performing comparably to matched-wall-clock-time GRPO on the Countdown task for Qwen3-8B (85% vs 87%), restoring 85% of locked BigCodeBench performance on a password-locked Llama3-70B, virtually eliminating alignment-faking in a Llama3-70B model organism, and providing better initialization for GRPO on GPT-OSS-20B in a reward-hacking-prone environment.
Significance. If the central claim holds, CPE would represent a notable advance in unsupervised, data-efficient exploration of LLM latent behaviors, with direct relevance to alignment and safety evaluation. The unsupervised character, single-example efficiency, and potential to surface hidden failure modes without token-space search are strengths that could complement supervised methods like GRPO. The work also highlights a possible route to mitigate exploration hacking.
major comments (2)
- [Abstract] Abstract: The claim that the heuristic tensor-decomposition algorithm 'yields interpretable low-rank adapters that elicit these latent behaviors' is load-bearing for every empirical result (Countdown performance, BigCodeBench recovery, alignment-faking elimination, GRPO initialization). No controls, ablations, or comparisons to random low-rank perturbations are described to establish that the extracted adapters correspond to genuine, generalizable behavioral modes rather than decomposition artifacts or model-specific noise.
- [Abstract] Abstract: The reported performance numbers (e.g., 85% vs 87% on Countdown, 85% restoration on locked BigCodeBench) are presented without any description of the tensor-decomposition procedure, experimental protocol, or statistical validation. This absence prevents assessment of whether the unsupervised method reliably outperforms or matches supervised baselines for the stated reasons.
minor comments (1)
- [Abstract] Abstract: Future-dated citations (Taylor et al. 2025, Hughes et al. 2025) should be clarified or updated to preprint versions if applicable.
Simulated Author's Rebuttal
We thank the referee for highlighting these important points regarding the strength of evidence for our central claims. We will revise the manuscript to include additional controls and improve the clarity of methodological descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the heuristic tensor-decomposition algorithm 'yields interpretable low-rank adapters that elicit these latent behaviors' is load-bearing for every empirical result (Countdown performance, BigCodeBench recovery, alignment-faking elimination, GRPO initialization). No controls, ablations, or comparisons to random low-rank perturbations are described to establish that the extracted adapters correspond to genuine, generalizable behavioral modes rather than decomposition artifacts or model-specific noise.
Authors: We agree that direct comparisons to random low-rank perturbations are needed to rule out artifacts. In the revised manuscript we will add ablations that apply random low-rank updates of matched rank and Frobenius norm to the same transformer slices and report the resulting task performance; these will be presented alongside the CPE results for all four main experiments. revision: yes
-
Referee: [Abstract] Abstract: The reported performance numbers (e.g., 85% vs 87% on Countdown, 85% restoration on locked BigCodeBench) are presented without any description of the tensor-decomposition procedure, experimental protocol, or statistical validation. This absence prevents assessment of whether the unsupervised method reliably outperforms or matches supervised baselines for the stated reasons.
Authors: The abstract is intentionally concise; the tensor-decomposition algorithm is fully specified in Section 3, the experimental protocols (including single-example usage, LoRA rank, and training details) appear in Section 4, and statistical validation (multiple random seeds, standard errors) is reported in the results tables. To address the concern we will insert a one-sentence methods summary into the abstract and ensure every performance number is accompanied by its variance in the revision. revision: partial
Circularity Check
No significant circularity; method presented as unsupervised heuristic without self-referential reduction
full rationale
The abstract describes CPE as an unsupervised heuristic tensor-decomposition algorithm that learns LoRAs from a single example and benchmarks it against external supervised methods (GRPO) and prior external work (Taylor et al. 2025, Greenblatt et al. 2024, Hughes et al. 2025). No equations, fitted parameters renamed as predictions, self-citations, uniqueness theorems, or ansatzes are present in the provided text. The central claim rests on the heuristic's empirical performance rather than any definitional or self-citation chain that reduces the output to the input by construction. This is the expected non-finding for a methods paper whose derivation is not shown to collapse internally.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper A heuristic tensor-decomposition-based algorithm applied to transformer slice computations yields interpretable low-rank adapters that elicit genuine latent behaviors.
invented entities (1)
-
Causal Perturbative Elicitation (CPE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
RL with KL penalties is better viewed as Bayesian inference , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[2]
2025 , month = apr, day =
Alignment Faking Revisited: Improved Classifiers and Open Source Extensions , author =. 2025 , month = apr, day =
2025
-
[3]
2026 , eprint=
Feature Identification via the Empirical NTK , author=. 2026 , eprint=
2026
-
[4]
2018 , eprint=
Supervising strong learners by amplifying weak experts , author=. 2018 , eprint=
2018
-
[5]
2023 , eprint=
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision , author=. 2023 , eprint=
2023
-
[6]
2026 , eprint=
X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests , author=. 2026 , eprint=
2026
-
[7]
2026 , month=
(Some) Natural Emergent Misalignment from Reward Hacking in Non-Production RL , author=. 2026 , month=
2026
-
[8]
The Fourteenth International Conference on Learning Representations , year=
Steering Language Models with Weight Arithmetic , author=. The Fourteenth International Conference on Learning Representations , year=
-
[9]
2024 , eprint=
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders , author=. 2024 , eprint=
2024
-
[10]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[11]
Chen, Yangyi and Gao, Hongcheng and Cui, Ganqu and Qi, Fanchao and Huang, Longtao and Liu, Zhiyuan and Sun, Maosong. Why Should Adversarial Perturbations be Imperceptible? Rethink the Research Paradigm in Adversarial NLP. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.771
-
[12]
and Ba, Jimmy , biburl =
Kingma, Diederik P. and Ba, Jimmy , biburl =. Adam: A Method for Stochastic Optimization. , url =. ICLR (Poster) , editor =
-
[13]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[14]
GitHub repository , publisher =
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou. GitHub repository , publisher =
-
[15]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[16]
2026 , eprint=
EasySteer: A Unified Framework for High-Performance and Extensible LLM Steering , author=. 2026 , eprint=
2026
-
[17]
2024 , eprint=
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. 2024 , eprint=
2024
-
[18]
2026 , eprint=
Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
AI Sandbagging: Language Models can Strategically Underperform on Evaluations , author=. 2025 , eprint=
2025
-
[20]
The Twelfth International Conference on Learning Representations , year=
Towards Understanding Sycophancy in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[21]
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in
Abhay Sheshadri and Aidan Ewart and Phillip Huang Guo and Aengus Lynch and Cindy Wu and Vivek Hebbar and Henry Sleight and Asa Cooper Stickland and Ethan Perez and Dylan Hadfield-Menell and Stephen Casper , journal=. Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in. 2025 , url=
2025
-
[22]
The Thirteenth International Conference on Learning Representations , year=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
2026 , eprint=
Seemingly Simple Planning Problems are Computationally Challenging: The Countdown Game , author=. 2026 , eprint=
2026
-
[24]
Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan and Marian Tietz , howpublished =
-
[25]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[26]
2026 , eprint=
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=. 2026 , eprint=
2026
-
[27]
2025 , journal =
Auditing Games for Sandbagging , author=. 2025 , journal =
2025
-
[28]
2022 , howpublished =
Branwen, Gwern , title =. 2022 , howpublished =
2022
-
[29]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , pages =
Ganguli, Deep and Hernandez, Danny and Lovitt, Liane and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Dassarma, Nova and Drain, Dawn and Elhage, Nelson and El Showk, Sheer and Fort, Stanislav and Hatfield-Dodds, Zac and Henighan, Tom and Johnston, Scott and Jones, Andy and Joseph, Nicholas and Kernian, Jackson and Kravec, Shauna and ...
-
[30]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[31]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[32]
Extracting Latent Steering Vectors from Pretrained Language Models
Subramani, Nishant and Suresh, Nivedita and Peters, Matthew , title = "Extracting Latent Steering Vectors from Pretrained Language Models", author = "Subramani, Nishant and Suresh, Nivedita and Peters, Matthew", editor = "Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline", booktitle = "Findings of the Association for Computational Linguistics:...
-
[34]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , title =. arXiv preprint arXiv:2310.01405 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Steering Llama 2 via Contrastive Activation Addition
Panickserry, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[36]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[37]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[38]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[39]
Advances in Neural Information Processing Systems , volume =
Dunefsky, Jacob and Chlenski, Philippe and Nanda, Neel , title =. Advances in Neural Information Processing Systems , volume =
-
[40]
Transactions on Machine Learning Research , issn=
Decomposing The Dark Matter of Sparse Autoencoders , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[41]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[42]
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models , year=
Dalva, Yusuf and Yanardag, Pinar , booktitle=. NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models , year=
-
[43]
International Conference on Machine Learning , year =
Ramesh, Aditya and Choi, Youngduck and LeCun, Yann , title =. International Conference on Machine Learning , year =
-
[44]
2024 , eprint=
The Local Interaction Basis: Identifying Computationally-Relevant and Sparsely Interacting Features in Neural Networks , author=. 2024 , eprint=
2024
-
[45]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and others , title =. Transformer Circuits Thread , year =
-
[46]
2024 , eprint=
Mathematical Models of Computation in Superposition , author=. 2024 , eprint=
2024
-
[47]
Advances in Neural Information Processing Systems , volume =
Ngo, Richard , title =. Advances in Neural Information Processing Systems , volume =
-
[48]
2024 , eprint=
Alignment faking in large language models , author=. 2024 , eprint=
2024
-
[49]
The Twelfth International Conference on Learning Representations , year=
Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering , author=. The Twelfth International Conference on Learning Representations , year=
-
[50]
2025 , eprint=
Reasoning Models Don't Always Say What They Think , author=. 2025 , eprint=
2025
-
[51]
2024 , eprint=
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2 , author=. 2024 , eprint=
2024
-
[52]
2024 , howpublished =
DeepSeek-AI , title =. 2024 , howpublished =
2024
-
[53]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, Woosuk and Chen, Zhuohan and Wang, Zhuang and Wan, Zhiyuan and Xiao, Zhong and Wu, Zhengxu and Bai, Jimmy and Li, James and Li, Piyush and Zhang, Haichuan and others , title =. arXiv preprint arXiv:2309.06180 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Proceedings of the VLDB Endowment , volume =
Zhang, Xiangru and Zhang, Lei and Zhao, Siming and Zhang, Ying and Zhang, Helin and Wang, Min and Li, Yang and Shen, Wei , title =. Proceedings of the VLDB Endowment , volume =
-
[55]
, title =
Ge, Rong and Jin, Chi and Zheng, Sham M. , title =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , publisher =
2017
-
[56]
Orthogonalized
Vatsal Sharan and Gregory Valiant , booktitle =. Orthogonalized. 2017 , editor =
2017
-
[57]
Linear algebra and its applications , volume =
Kruskal, Joseph B , title =. Linear algebra and its applications , volume =
-
[58]
2007 15th European Signal Processing Conference , pages =
Roy, Olivier and Vetterli, Martin , title =. 2007 15th European Signal Processing Conference , pages =. 2007 , organization =
2007
-
[59]
The Thirteenth International Conference on Learning Representations , year=
Controllable Context Sensitivity and the Knob Behind It , author=. The Thirteenth International Conference on Learning Representations , year=
-
[60]
The Twelfth International Conference on Learning Representations , year=
Function Vectors in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[61]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[62]
Chung, Fan R. K. , biburl =
-
[63]
2025 , eprint=
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.