Do We Still Need Fine Tuning? Turkish Sentiment Analysis in the Era of Large Language Model
Pith reviewed 2026-06-30 07:03 UTC · model grok-4.3
The pith
Fine-tuned BERTurk models outperform prompted large language models on Turkish three-class sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuned BERTurk models perform best overall and outperform all prompted large language models in the full three-class task on a Turkish e-commerce review dataset. The neutral class emerges as the main difficulty: while several large language models are much more competitive in binary positive-negative classification, they degrade substantially in the three-class setting by collapsing neutral reviews into polarized categories. The findings suggest that, in realistic Turkish sentiment classification, prompted large language models do not yet match supervised fine-tuning in the zero-shot setting, and that including the neutral class is crucial for robust evaluation.
What carries the argument
Direct performance comparison of fine-tuned BERTurk against zero-shot prompted large language models on three-class Turkish sentiment classification of e-commerce reviews.
Load-bearing premise
The prompting strategies and model choices for the large language models represent a fair and near-optimal zero-shot baseline rather than an under-optimized one.
What would settle it
An experiment in which optimized prompts or few-shot examples allow prompted large language models to match or exceed fine-tuned BERTurk accuracy on the identical three-class Turkish dataset.
Figures
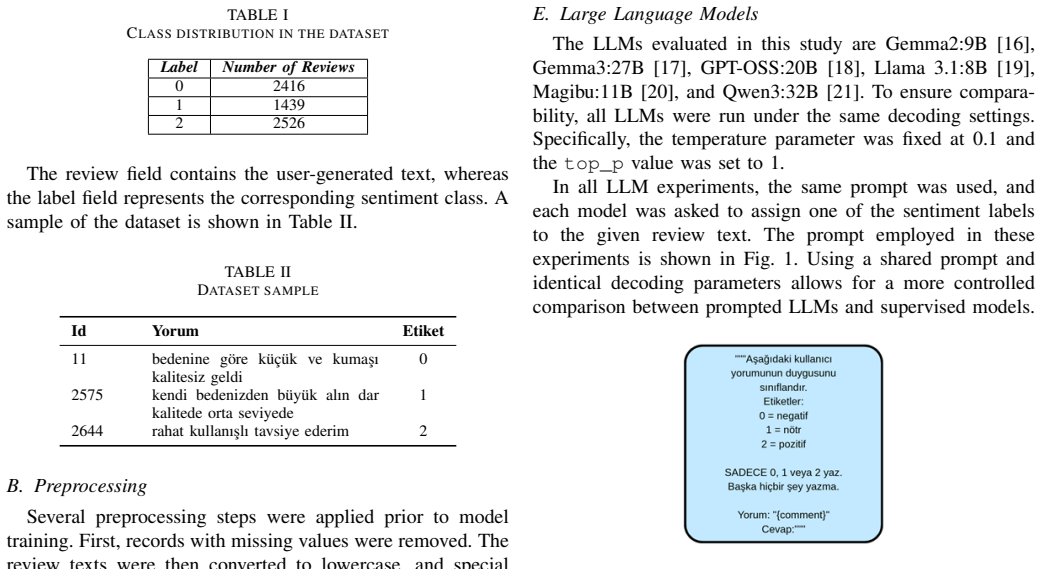
read the original abstract
This study examines whether supervised fine-tuning remains necessary for Turkish sentiment analysis in the era of large language models. We compare classical machine learning methods, fine-tuned pretrained language models, and prompted large language models on a Turkish e-commerce review dataset with negative, neutral, and positive labels. Fine-tuned BERTurk models perform best overall and outperform all prompted large language models in the full three-class task. The neutral class emerges as the main difficulty: while several large language models are much more competitive in binary positive--negative classification, they degrade substantially in the three-class setting by collapsing neutral reviews into polarized categories. The findings suggest that, in realistic Turkish sentiment classification, prompted large language models do not yet match supervised fine-tuning in the zero-shot setting, and that including the neutral class is crucial for robust evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares classical ML baselines, fine-tuned BERTurk models, and zero-shot prompted LLMs on a Turkish e-commerce review dataset for three-class sentiment analysis (negative, neutral, positive). It reports that fine-tuned BERTurk achieves the highest performance overall, while prompted LLMs are competitive in binary positive-negative classification but degrade markedly in the three-class task by misclassifying neutral reviews into polarized categories. The authors conclude that supervised fine-tuning remains necessary for robust Turkish sentiment classification in the zero-shot LLM setting and that neutral-class evaluation is essential.
Significance. If the empirical results hold under improved prompting, the work supplies a focused, language-specific benchmark showing that zero-shot LLM prompting has not yet closed the gap with fine-tuning for Turkish sentiment analysis when neutral labels are included. It provides concrete evidence on the neutral class as a persistent failure mode and underscores the value of realistic multi-class evaluation protocols for non-English tasks. The study is a straightforward empirical contribution that can inform practitioners working on Turkish NLP applications.
major comments (2)
- [Methods] Methods / Experimental Setup: The manuscript provides no prompt templates, temperature values, model selection criteria, or tests of Turkish-specific phrasing for the zero-shot LLM baselines. Because the central claim—that fine-tuned BERTurk outperforms all prompted LLMs—rests on these baselines representing a fair zero-shot comparison, the absence of these details leaves open the possibility that the observed gap is an artifact of under-optimization rather than an inherent limitation.
- [Results] Results section (performance tables): The reported degradation of LLMs when moving from binary to three-class evaluation is load-bearing for the conclusion, yet no error analysis, confusion matrices, or example neutral misclassifications are supplied to characterize the failure mode. This weakens the ability to interpret whether the neutral class is intrinsically difficult or simply mishandled by the chosen prompts.
minor comments (2)
- [Abstract] The abstract and conclusion could more explicitly qualify the scope as 'zero-shot prompting' to avoid overgeneralization to few-shot or instruction-tuned settings.
- [Tables] Table captions and axis labels should consistently use the same model abbreviations as the main text for readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and have incorporated revisions to improve the manuscript's clarity and reproducibility.
read point-by-point responses
-
Referee: [Methods] Methods / Experimental Setup: The manuscript provides no prompt templates, temperature values, model selection criteria, or tests of Turkish-specific phrasing for the zero-shot LLM baselines. Because the central claim—that fine-tuned BERTurk outperforms all prompted LLMs—rests on these baselines representing a fair zero-shot comparison, the absence of these details leaves open the possibility that the observed gap is an artifact of under-optimization rather than an inherent limitation.
Authors: We agree that the absence of these details limits reproducibility and interpretability. In the revised manuscript we now include the full prompt templates (both English and Turkish variants tested), temperature values (0.0 for all models to ensure determinism), model selection rationale (covering the most widely used open and proprietary LLMs available during the study period), and a brief discussion of Turkish-specific phrasing attempts. These additions demonstrate that the prompts were constructed following standard zero-shot practices and that the performance gap persists across reasonable prompt variations. revision: yes
-
Referee: [Results] Results section (performance tables): The reported degradation of LLMs when moving from binary to three-class evaluation is load-bearing for the conclusion, yet no error analysis, confusion matrices, or example neutral misclassifications are supplied to characterize the failure mode. This weakens the ability to interpret whether the neutral class is intrinsically difficult or simply mishandled by the chosen prompts.
Authors: We acknowledge that the lack of error analysis weakens the interpretation of the neutral-class collapse. The revised version now contains confusion matrices for the strongest fine-tuned and prompted models in both binary and three-class settings, plus three representative examples of neutral reviews that LLMs consistently misclassify as positive or negative. The added analysis shows that the degradation is driven by systematic neutral-to-polarized shifts rather than isolated prompt failures, thereby strengthening the central claim. revision: yes
Circularity Check
No circularity: pure empirical benchmarking on held-out data
full rationale
The paper conducts an empirical comparison of classical ML, fine-tuned PLMs, and prompted LLMs on a Turkish e-commerce review dataset with three-class labels. Results are obtained by direct measurement against held-out test data with no derivations, first-principles predictions, parameter fitting that is then renamed as prediction, or load-bearing self-citations. The central claim rests on observed performance numbers rather than any self-referential construction. This matches the default case of a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dataset labels are reliable and the train/test split is representative of real Turkish e-commerce reviews.
Reference graph
Works this paper leans on
-
[1]
Opinion mining and sentiment analysis,
B. Pang and L. Lee, “Opinion mining and sentiment analysis,”Founda- tions and Trends in Information Retrieval, vol. 2, no. 1–2, pp. 1–135, 2008
2008
-
[2]
Liu,Sentiment Analysis and Opinion Mining
B. Liu,Sentiment Analysis and Opinion Mining. San Rafael, CA, USA: Morgan & Claypool Publishers, 2012
2012
-
[3]
Language models are few-shot learners,
T. B. Brownet al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, vol. 33, pp. 1877– 1901, 2020
1901
-
[4]
Finetuned language models are zero-shot learners,
J. Wei, M. Bosma, V . Y . Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V . Le, “Finetuned language models are zero-shot learners,” inProc. Int. Conf. Learn. Representations (ICLR), 2022
2022
-
[5]
Sentiment analysis in the era of large language models: A reality check,
W. Zhang, Y . Deng, B. Liu, S. Pan, and L. Bing, “Sentiment analysis in the era of large language models: A reality check,” inFindings of the Association for Computational Linguistics: NAACL 2024, pp. 3881– 3906, 2024
2024
-
[6]
Sentiment analysis in Turkish: Supervised, semi-supervised, and unsupervised techniques,
C. R. Aydın and T. G ¨ung¨or, “Sentiment analysis in Turkish: Supervised, semi-supervised, and unsupervised techniques,”Natural Language En- gineering, vol. 27, no. 4, pp. 455–483, 2021
2021
-
[7]
Turkish tweet sentiment analysis with word embedding and machine learning,
D. Ayata, M. Sarac ¸lar, and A. ¨Ozg¨ur, “Turkish tweet sentiment analysis with word embedding and machine learning,” in2017 25th Signal Processing and Communications Applications Conference (SIU), pp. 1– 4, 2017
2017
-
[8]
Twitter dataset and evaluation of transformers for Turkish sentiment analysis,
A. K ¨oksal and A. ¨Ozg¨ur, “Twitter dataset and evaluation of transformers for Turkish sentiment analysis,” in2021 29th Signal Processing and Communications Applications Conference (SIU), pp. 1–4, 2021
2021
-
[9]
A dataset and BERT-based models for targeted sentiment analysis on Turkish texts,
M. M. Mutlu and A. ¨Ozg¨ur, “A dataset and BERT-based models for targeted sentiment analysis on Turkish texts,” inProc. 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, pp. 467–472, 2022
2022
-
[10]
Multi- class sentiment analysis with e-commerce user reviews: Comparisons of classical and deep learning applications,
Y . S ¸ims ¸ek, M. B. Balci, M. Arzu, M. Kaya, and Y . Santur, “Multi- class sentiment analysis with e-commerce user reviews: Comparisons of classical and deep learning applications,” in2025 9th International Artificial Intelligence and Data Processing Symposium (IDAP), pp. 1–6, 2025
2025
-
[11]
Sentiment analysis in Turkish at different granularity levels,
R. Dehkharghani, B. Yanıko ˘glu, Y . Saygın, and K. Oflazer, “Sentiment analysis in Turkish at different granularity levels,”Natural Language Engineering, vol. 23, no. 4, pp. 535–559, 2017
2017
-
[12]
TRSAv1: A new benchmark dataset for classifying user reviews on Turkish e-commerce websites,
M. Aydo ˘gan and V . Kocaman, “TRSAv1: A new benchmark dataset for classifying user reviews on Turkish e-commerce websites,”Journal of Information Science, vol. 49, no. 6, pp. 1711–1725, 2023
2023
-
[13]
Evaluating the zero-shot robust- ness of instruction-tuned language models,
J. Sun, C. Shaib, and B. C. Wallace, “Evaluating the zero-shot robust- ness of instruction-tuned language models,” inProc. Int. Conf. Learn. Representations (ICLR), 2024
2024
-
[14]
Sentiment analysis: It’s compli- cated!,
K. Kenyon-Dean, E. Ahmed, S. Fujimoto, L. Georges-Filteau, K. Kaur, A. Lalande, S. Bhanderi, R. Belfer, N. Kanagasabai, R. Sarrazin- Gendron, R. Verma, and D. Ruths, “Sentiment analysis: It’s compli- cated!,” inProc. 2018 Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1886–1895, 2018
2018
-
[15]
Dealing with disagree- ments: Looking beyond the majority vote in subjective annotations,
A. M. Davani, M. D ´ıaz, and V . Prabhakaran, “Dealing with disagree- ments: Looking beyond the majority vote in subjective annotations,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 92–110, 2022
2022
-
[16]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, “Gemma 2: Improving Open Language Models at a Practical Size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
G Team, “Gemma 3 Technical Report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Introducing GPT-OSS,
OpenAI, “Introducing GPT-OSS,” 2025. [Online]. Available: https:// openai.com/index/introducing-gpt-oss/
2025
-
[19]
Introducing Llama 3.1: Our most capable models to date,
Meta, “Introducing Llama 3.1: Our most capable models to date,” 2024. [Online]. Available: https://ai.meta.com/blog/meta-llama-3-1/
2024
-
[20]
Magibu-11B: A Turkish-Native Multilingual Vision- Language Model with Optimized Tokenization,
A. Bayram, “Magibu-11B: A Turkish-Native Multilingual Vision- Language Model with Optimized Tokenization,” 2025. [Online]. Avail- able: https://huggingface.co/magibu/magibu-11b-v0.8
2025
-
[21]
Qwen Team, “Qwen3 Technical Report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.