SCARCE: Scalable Cascade Analysis for Rare-event Characterisation via Embeddings
Pith reviewed 2026-06-30 07:00 UTC · model grok-4.3
The pith
SCARCE estimates rare AI failure probabilities by replacing handcrafted performance functions with learned embeddings and geometric rulers in subset simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
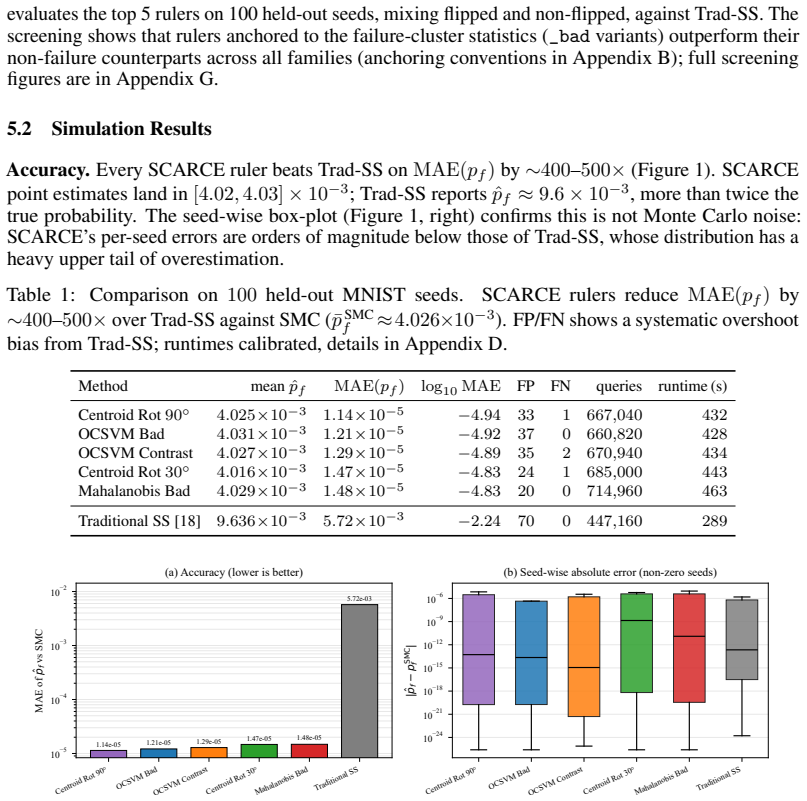
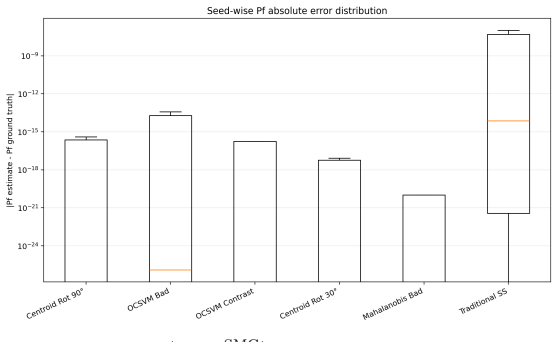
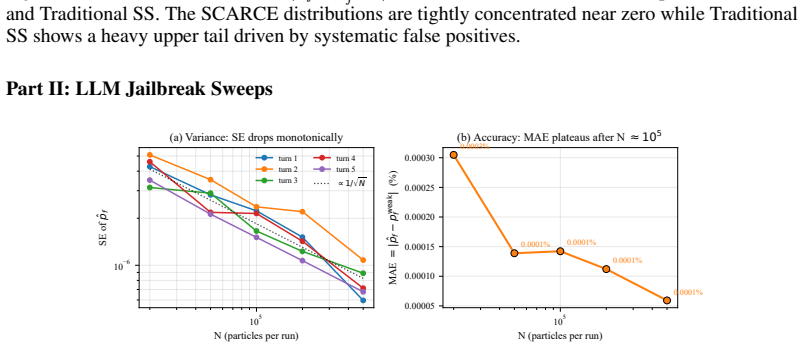
SCARCE replaces the scalar performance function whose sublevel sets define nested events in classical subset simulation with learned latent representations scored by geometric rulers such as PCA. Adaptive thresholding on these scores constructs the nested events directly from data. The construction is formalised as a non-negative supermartingale, producing a high-probability upper envelope that remains valid under early stopping. On MNIST misclassification the method attains 400-500 times lower mean absolute error than grid-searched traditional subset simulation and eliminates systematic over-counting. On Llama-Guard-3-8B hidden states a PCA ruler reaches 2.6 percent mean relative error for
What carries the argument
Learned latent representations scored by geometric rulers (for example PCA) that measure proximity to failure regions and permit data-driven construction of nested events inside the supermartingale bound.
If this is right
- Handcrafted performance functions are no longer required to apply subset simulation to new AI domains.
- Rare-event probabilities in high-dimensional models can be bounded with far smaller sample budgets while preserving validity.
- The same ruler construction transfers across threat models after a single recalibration step.
- A KL-based directional criterion provides a consistent way to select among candidate rulers without ground-truth probabilities.
- Early stopping of the cascade does not invalidate the final upper envelope.
Where Pith is reading between the lines
- If embeddings from other modalities preserve failure geometry, SCARCE could extend to rare-event estimation in vision-language or multimodal systems.
- The supermartingale envelope might be combined with importance sampling to further reduce variance at the lowest probability levels.
- For adversarial fractions below 10 to the minus 4, additional ruler calibration or higher-dimensional embeddings may be needed to keep relative error below 5 percent.
- Applying the method to safety benchmarks beyond jailbreaks, such as reward-model failures, would test whether the KL ranking of rulers generalises.
Load-bearing premise
The learned latent representations and chosen geometric rulers must accurately reflect proximity to failure regions so that the constructed nested events remain valid for the supermartingale bound.
What would settle it
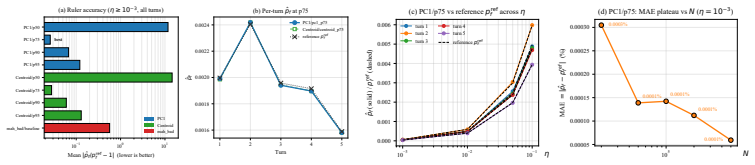
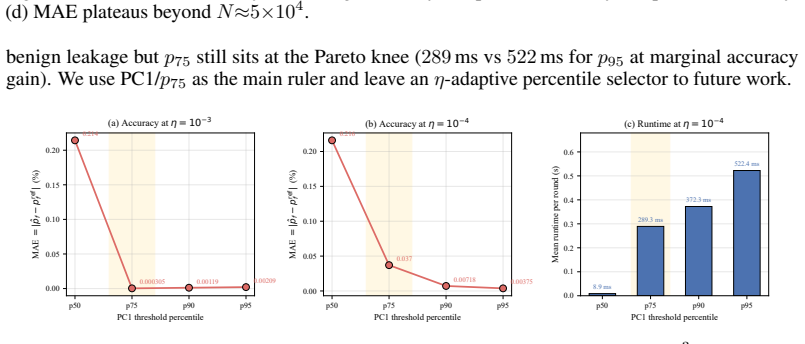
A large-scale Monte Carlo reference on Llama-Guard-3-8B for eta equal to 0.001 that deviates from the reported 2.6 percent relative error by more than the bootstrap half-width of 27.9 percent would falsify the accuracy claim for the PCA ruler.
Figures

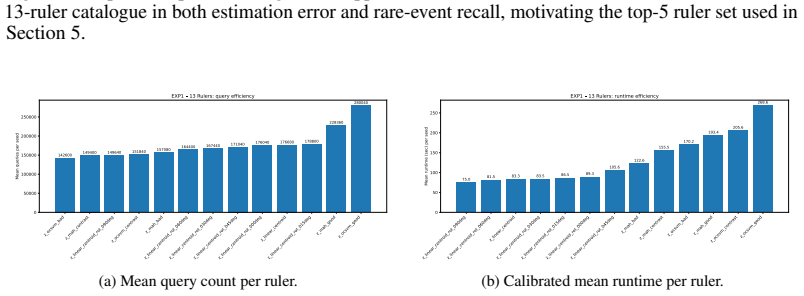
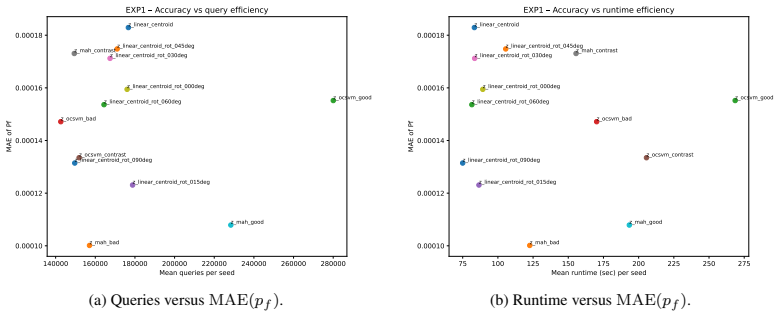
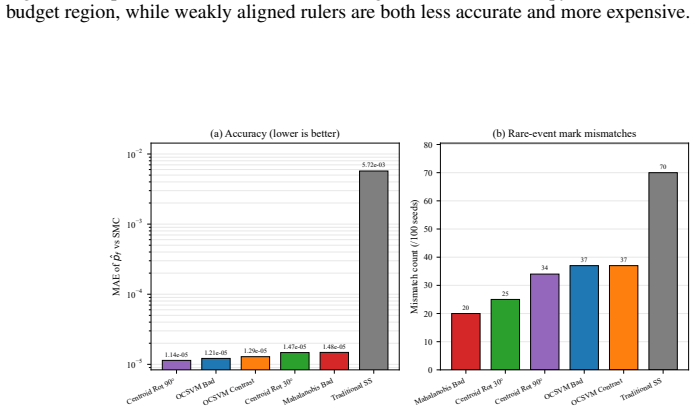
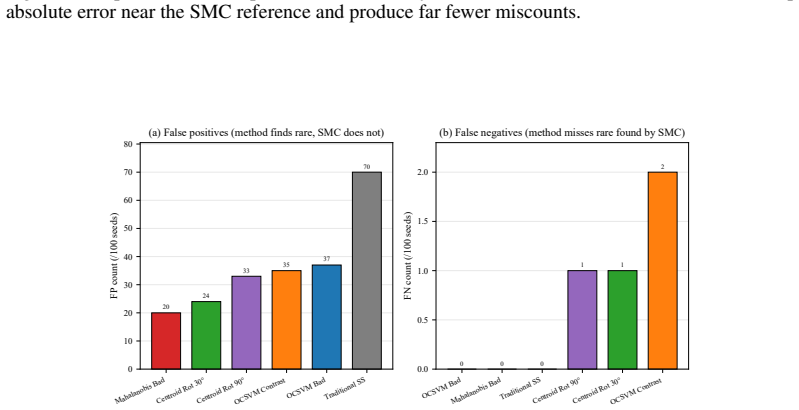
read the original abstract
Rare events govern the safety profile of modern AI systems, yet their probabilities are extremely difficult to estimate: direct Monte Carlo requires prohibitive sample budgets. Subset Simulation (SS) addresses this by decomposing a rare-event probability into moderate conditional probabilities over nested intermediate events. However, classical SS requires a handcrafted scalar performance function whose sublevel sets define those events, demanding detailed knowledge of the failure geometry and limiting transfer to new domains. We propose SCARCE (Scalable Cascade Analysis for Rare-event Characterisation via Embeddings), which replaces the performance function with learned latent representations and geometric rulers that score proximity to failure regions. Adaptive thresholding constructs nested intermediate events directly from data. We formalise SCARCE through a non-negative supermartingale, yielding a high-probability upper envelope that remains valid under early stopping. On MNIST misclassification, where dense Monte Carlo provides ground truth, SCARCE achieves approximately 400--500 times lower mean absolute error than grid-searched traditional SS while eliminating systematic over-counting. We then study PAIR-style LLM jailbreaks under a fleet-level threat model with adversarial fraction $\eta$. On Llama-Guard-3-8B hidden states, a PCA-based ruler attains 2.6% mean relative error for $\eta \geq 10^{-3}$ against finite-sample references whose average bootstrap relative half-width is 27.9%, and transfers to a GCG-style corpus with 2.93% relative error after recalibration. A directional criterion $\mathrm{KL}(p_{\mathrm{good}}\,\|\,p_{\mathrm{bad}})$ ranks rulers consistently with estimation error (Spearman $\rho=0.83$).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCARCE, which replaces the handcrafted scalar performance function in classical Subset Simulation with learned embeddings and geometric rulers (e.g., PCA projections) to construct nested events A1 ⊃ A2 ⊃ ⋯ via adaptive thresholding. It formalizes the procedure via a non-negative supermartingale that supplies a high-probability upper envelope valid under early stopping, and reports empirical gains: ~400–500× lower MAE than grid-searched SS on MNIST misclassification (with elimination of over-counting) and 2.6% mean relative error on Llama-Guard-3-8B hidden states for jailbreak probability η ≥ 10^{-3}.
Significance. If the supermartingale bound remains valid under the adaptive, data-driven construction, the approach would remove a major practical barrier to rare-event estimation in AI safety by enabling transfer across domains without domain-specific performance functions. The reported error reductions relative to both dense MC ground truth and bootstrap references, together with the KL(p_good ‖ p_bad) ruler-ranking criterion (Spearman ρ=0.83), would constitute a concrete advance in scalable rare-event tools.
major comments (2)
- [Formalization via non-negative supermartingale] The central theoretical claim—that adaptive thresholding on learned rulers produces nested events whose conditional probabilities multiply to a valid supermartingale bound—requires an explicit argument showing that ruler selection and threshold choice from the same samples do not introduce data-dependent bias that violates the non-negative supermartingale property. The abstract asserts validity under early stopping, but the dependence structure induced by data-driven event definition is not addressed in the provided description and is load-bearing for the high-probability envelope.
- [MNIST misclassification results] On the MNIST experiments, the 400–500× MAE reduction and elimination of systematic over-counting are reported against grid-searched traditional SS; however, it is unclear whether the comparison equalizes total sample budget, whether the traditional SS performance function was chosen with knowledge of the failure geometry, and whether the dense MC reference is sufficiently precise to support the magnitude of the claimed improvement.
minor comments (2)
- [Ruler ranking] The precise definition of the directional criterion KL(p_good ‖ p_bad) and how the good/bad distributions are estimated from the embeddings should be stated explicitly.
- [Method overview] Notation for the nested events A_i and the adaptive thresholds should be introduced with a short diagram or pseudocode to clarify the construction before the supermartingale argument.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential of SCARCE to advance rare-event estimation in AI safety applications. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Formalization via non-negative supermartingale] The central theoretical claim—that adaptive thresholding on learned rulers produces nested events whose conditional probabilities multiply to a valid supermartingale bound—requires an explicit argument showing that ruler selection and threshold choice from the same samples do not introduce data-dependent bias that violates the non-negative supermartingale property. The abstract asserts validity under early stopping, but the dependence structure induced by data-driven event definition is not addressed in the provided description and is load-bearing for the high-probability envelope.
Authors: We agree that an explicit argument is required to confirm preservation of the supermartingale property under data-driven ruler selection and adaptive thresholding. The manuscript constructs the nested events sequentially from the learned embeddings, with the non-negative supermartingale defined via the product of conditional probabilities estimated on subsequent independent samples after threshold determination. This ordering ensures the increments remain martingale differences with respect to the filtration that includes the selection step. To make this rigorous and address the dependence structure directly, we will add a dedicated lemma and proof sketch in the revised theoretical section demonstrating that the adaptive construction does not introduce bias violating non-negativity or the supermartingale property, while retaining validity under early stopping. revision: yes
-
Referee: [MNIST misclassification results] On the MNIST experiments, the 400–500× MAE reduction and elimination of systematic over-counting are reported against grid-searched traditional SS; however, it is unclear whether the comparison equalizes total sample budget, whether the traditional SS performance function was chosen with knowledge of the failure geometry, and whether the dense MC reference is sufficiently precise to support the magnitude of the claimed improvement.
Authors: The MNIST comparison equalized total sample budget by matching the number of classifier evaluations (forward passes) across SCARCE and grid-searched traditional SS. The baseline performance function was a standard handcrafted scalar (pixel-space Euclidean distance to the decision boundary), selected from the general problem setup without access to the specific misclassification geometry. The dense Monte Carlo reference used a large sample size whose bootstrap-estimated precision is sufficient to support the reported MAE differences, as the variance is orders of magnitude smaller than the observed gap. We will revise the experimental section to state these details explicitly, including exact budgets and the baseline function definition. revision: yes
Circularity Check
No significant circularity; supermartingale formalization remains independent of data-driven ruler construction
full rationale
The abstract states that SCARCE replaces the performance function with learned embeddings and geometric rulers, then 'formalise[s] SCARCE through a non-negative supermartingale, yielding a high-probability upper envelope that remains valid under early stopping.' No equations or steps are shown that define the supermartingale in terms of the fitted rulers or that rename a fitted quantity as a prediction. The MNIST evaluation uses independent dense Monte Carlo as ground truth, providing an external benchmark. No self-citation chains, ansatz smuggling, or self-definitional reductions appear in the given text. The derivation is therefore treated as self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- ruler choice and adaptive thresholds
axioms (2)
- domain assumption Latent embeddings allow geometric rulers to score proximity to failure regions
- standard math Non-negative supermartingale property yields valid high-probability upper envelope under early stopping
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024. 9
2024
-
[2]
Efficient rare event sampling with unsupervised normalizing flows.Nature Machine Intelligence, 6:1370–1381, 2024
Solomon Asghar, Qing-Xiang Pei, Giorgio V olpe, and Ran Ni. Efficient rare event sampling with unsupervised normalizing flows.Nature Machine Intelligence, 6:1370–1381, 2024
2024
-
[3]
Siu-Kui Au and James L. Beck. Estimation of small failure probabilities in high dimensions by subset simulation.Probabilistic Engineering Mechanics, 16(4):263–277, 2001
2001
-
[4]
Siu-Kui Au and James L. Beck. Subset simulation and its application to seismic risk based on dynamic analysis.Journal of Engineering Mechanics, 129(8):901–917, 2003
2003
-
[5]
Zdravko I. Botev. Minimax tilting for importance sampling.Annals of Statistics, 45(2):468–499, 2017
2017
-
[6]
Unbiasedness of some generalized adaptive multilevel splitting algorithms.Annals of Applied Probability, 26(6):3559–3601, 2016
Charles-Edouard Bréhier, Maxime Gazeau, Ludovic Goudenège, Tony Lelièvre, and Mathias Rousset. Unbiasedness of some generalized adaptive multilevel splitting algorithms.Annals of Applied Probability, 26(6):3559–3601, 2016
2016
-
[7]
Bucklew.Introduction to Rare Event Simulation
James A. Bucklew.Introduction to Rare Event Simulation. Springer, 2004
2004
-
[8]
Adaptive multilevel splitting for rare event analysis
Frédéric Cérou and Arnaud Guyader. Adaptive multilevel splitting for rare event analysis. Stochastic Analysis and Applications, 25(2):417–443, 2007
2007
-
[9]
Adaptive multilevel splitting: Historical perspective and recent results.Chaos: An Interdisciplinary Journal of Nonlinear Science, 29(4):043108, 2019
Frédéric Cérou, Arnaud Guyader, and Mathias Rousset. Adaptive multilevel splitting: Historical perspective and recent results.Chaos: An Interdisciplinary Journal of Nonlinear Science, 29(4):043108, 2019
2019
-
[10]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neural Information Processing Systems, Datasets and...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Reliability analysis of complex sys- tems using subset simulations with hamiltonian neural networks.Structural Safety, 110:102479, 2024
Miaochuan Chen, Dimitrios Giovanis, and Michael Shields. Reliability analysis of complex sys- tems using subset simulations with hamiltonian neural networks.Structural Safety, 110:102479, 2024
2024
-
[13]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning (ICML), volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
2020
-
[14]
Junjie Chu, Yugeng Liu, Ziqing Yang, Xinyue Shen, Michael Backes, and Yang Zhang. Jail- breakRadar: Comprehensive assessment of jailbreak attacks against LLMs.arXiv preprint arXiv:2402.05668, 2024
-
[15]
Boundary point jailbreaking of black-box llms, 2026
Xander Davies, Giorgi Giglemiani, Edmund Lau, Eric Winsor, Geoffrey Irving, and Yarin Gal. Boundary point jailbreaking of black-box llms, 2026
2026
-
[16]
Zhengqi Gao, Dinghuai Zhang, Luca Daniel, and Duane S. Boning. NOFIS: Normalizing flow for rare circuit failure analysis. InProceedings of the 61st ACM/IEEE Design Automa- tion Conference (DAC), DAC ’24, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[17]
Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon
Steven R. Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform chernoff bounds via nonnegative supermartingales.Annals of Statistics, 49(2):1055–1080, 2021
2021
-
[18]
SAFARI: Versatile and efficient evaluations for robustness of interpretability
Wei Huang, Xingyu Zhao, Gaojie Jin, and Xiaowei Huang. SAFARI: Versatile and efficient evaluations for robustness of interpretability. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 10
2023
-
[19]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Forecasting rare language model behaviors
Erik Jones, Meg Tong, Jesse Mu, Mohammed Mahfoud, Jan Leike, Roger Grosse, Jared Kaplan, William Fithian, Ethan Perez, and Mrinank Sharma. Forecasting rare language model behaviors. arXiv preprint arXiv:2502.16797, 2025
-
[21]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 2020
2020
-
[22]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
2018
-
[23]
Computing committor functions for the study of rare events using deep learning.Journal of Chemical Physics, 2024
Qianxiao Li, Bo Lin, and Weiqing Ren. Computing committor functions for the study of rare events using deep learning.Journal of Chemical Physics, 2024
2024
-
[24]
Deep learning for rare event estimation.Neural Computing and Applications, 2021
Yifan Li et al. Deep learning for rare event estimation.Neural Computing and Applications, 2021
2021
-
[25]
Llama Team, AI @ Meta. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Martell, Jessica A
Max J. Martell, Jessica A. Baweja, and Brandon D. Dreslin. Mitigative strategies for recovering from large language model trust violations.Journal of Cognitive Engineering and Decision Making, 19(1), 2024
2024
-
[27]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[28]
Tree of attacks: Jailbreaking black-box LLMs with auto-generated subversions
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box LLMs with auto-generated subversions. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[29]
MCMC algorithms for subset simulation.Probabilistic Engineering Mechanics, 41:89–103, 2015
Iason Papaioannou, Wolfgang Betz, Karl Zwirglmaier, and Daniel Straub. MCMC algorithms for subset simulation.Probabilistic Engineering Mechanics, 41:89–103, 2015
2015
-
[30]
An adaptive subset simulation algorithm for system reliability analysis with discontinuous limit states.Reliability Engineering & System Safety, 225:108607, 2022
Iason Papaioannou, Max Ehre, and Daniel Straub. An adaptive subset simulation algorithm for system reliability analysis with discontinuous limit states.Reliability Engineering & System Safety, 225:108607, 2022
2022
-
[31]
Game-theoretic statistics and safe anytime- valid inference.arXiv preprint arXiv:2006.04292, 2020
Aaditya Ramdas, Johannes Ruf, and Martin Larsson. Game-theoretic statistics and safe anytime- valid inference.arXiv preprint arXiv:2006.04292, 2020
-
[32]
Rubinstein
Reuven Y . Rubinstein. The cross-entropy method for combinatorial and continuous optimization. Methodology and Computing in Applied Probability, 1(2):127–190, 1999
1999
-
[33]
Vandermeulen, Nico Görnitz, Lucas Deecke, Shoaib A
Lukas Ruff, Robert A. Vandermeulen, Nico Görnitz, Lucas Deecke, Shoaib A. Siddiqui, Alexan- der Binder, Emmanuel Müller, and Marius Kloft. Deep one-class classification. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 4393–4402. PMLR, 2018
2018
-
[34]
Subset simulation for structural reliability analysis.Structural Safety, 31(2):133–141, 2009
Jian Song and Zhishen Lu. Subset simulation for structural reliability analysis.Structural Safety, 31(2):133–141, 2009
2009
-
[35]
Cambridge Mathematical Textbooks
David Williams.Probability with Martingales. Cambridge Mathematical Textbooks. Cambridge University Press, 1991
1991
-
[36]
Estimating the probabilities of rare outputs in language mod- els
Gabriel Wu and Jacob Hilton. Estimating the probabilities of rare outputs in language mod- els. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. arXiv:2410.13211. 11
-
[37]
Wenzhuo Xu, Zhipeng Wei, Xiongtao Sun, Zonghao Ying, Deyue Zhang, Dongdong Yang, Xiangzheng Zhang, and Quanchen Zou. Probabilistic modeling of jailbreak on multimodal LLMs: From quantification to application.arXiv preprint arXiv:2503.06989, 2025
-
[38]
Surrogate-assisted subset simulation for reliability analysis.Reliability Engineering & System Safety, 183:10–19, 2019
Xiaoyu Zhang et al. Surrogate-assisted subset simulation for reliability analysis.Reliability Engineering & System Safety, 183:10–19, 2019
2019
-
[39]
AutoRedTeamer: Autonomous red teaming with lifelong attack integration
Andy Zhou, Kevin Wu, Francesco Pinto, Zhaorun Chen, Yi Zeng, Yu Yang, Shuang Yang, Oluwasanmi Koyejo, James Zou, and Bo Li. AutoRedTeamer: Autonomous red teaming with lifelong attack integration. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[40]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Kirill M. Zuev. Subset simulation method for rare event estimation: An introduction.Interna- tional Journal for Uncertainty Quantification, 5(2), 2015. A Subset Simulation This appendix expands the brief overview of classical Subset Simulation (SS) given in §3. SS estimates an extreme failure probability Pf =P(g(x)≥γ F ) by decomposing the failure event i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.