Budgeted Act-or-Defer Multi-Agent LLM Deliberation with Local Reliability Bounds
Pith reviewed 2026-06-30 06:53 UTC · model grok-4.3
The pith
A method converts a user-declared wrong-action budget into an auditable act-or-defer operating point for multi-agent LLM deliberation before deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
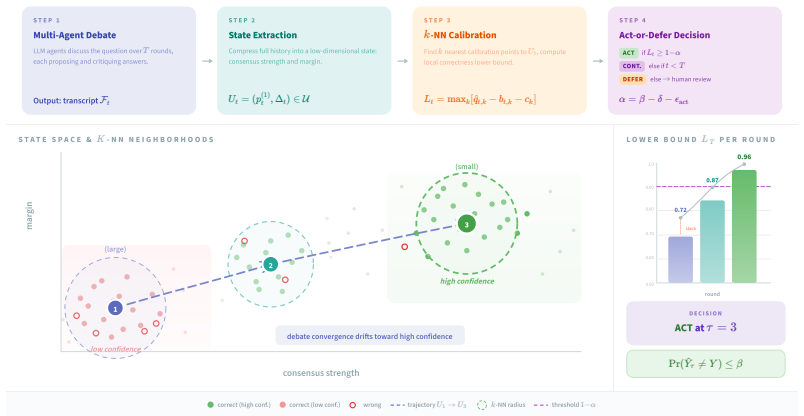
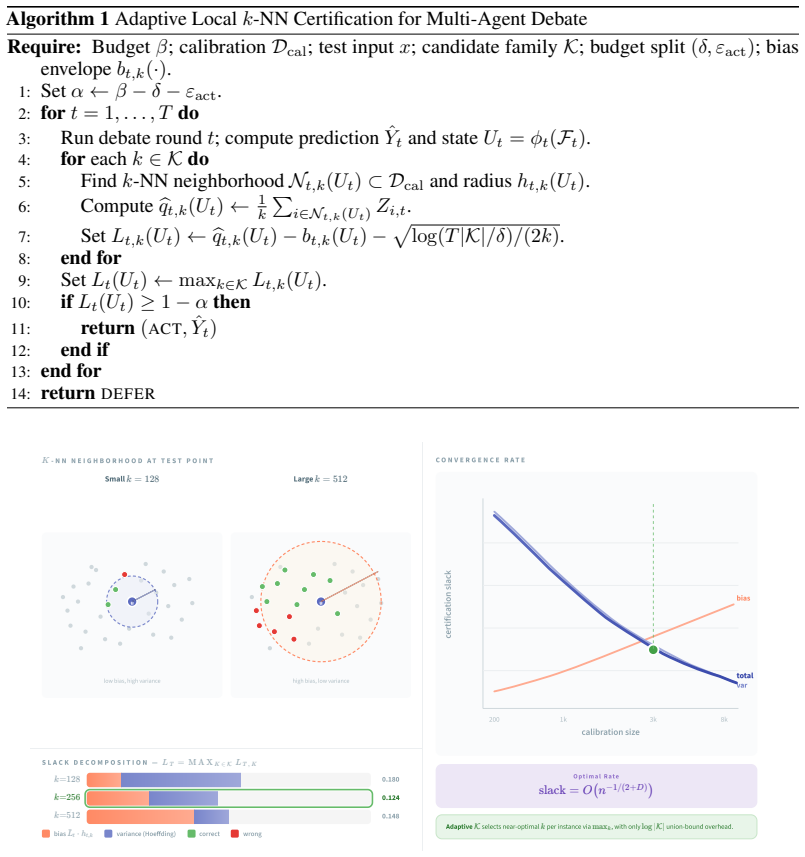
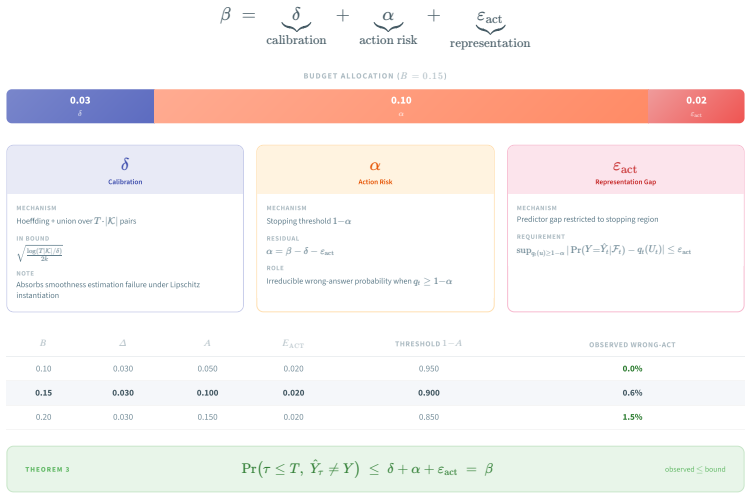
The central claim is that the act-or-defer decision can be made prospectively by computing a k-nearest-neighbor lower confidence bound on state-conditional correctness from calibration data and acting only when the bound meets the threshold implied by the declared wrong-action budget β, which yields the decomposition β = δ + α + ε_act and thereby controls wrong actions under the stated assumptions of a valid local bias envelope and bounded representation gap in action regions.
What carries the argument
The decomposition β = δ + α + ε_act together with the k-nearest-neighbor lower confidence bound on state-conditional correctness, which together convert the budget into an explicit act-or-defer threshold.
If this is right
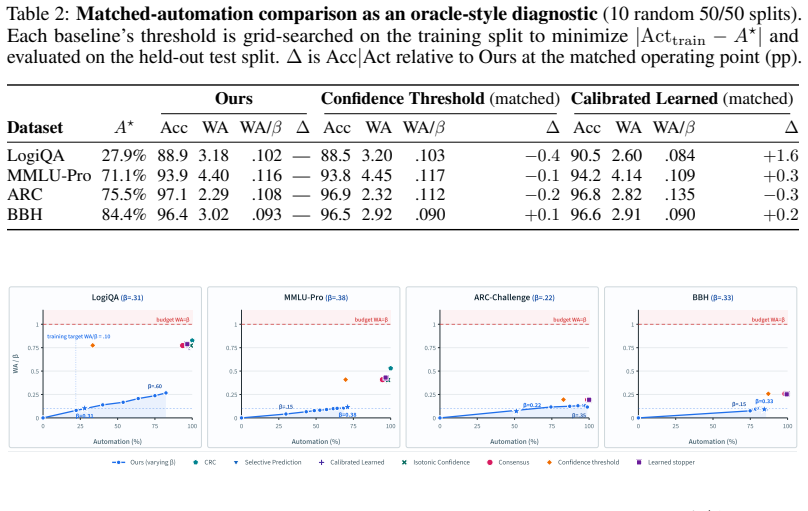
- On six benchmarks the method uses 9-12% of the pre-declared budget on activated datasets while reaching up to 84% automation and 96% acted-on accuracy.
- On stress-test datasets the system defers rather than forcing unreliable automation.
- Budgets are set relative to each task's final-round error using only training data and evaluated by normalized budget usage WA/β.
- The operating point is obtained prospectively without per-task post-hoc threshold search.
Where Pith is reading between the lines
- If the representation-gap bound can be verified or tightened on new domains, the same framework could support higher automation fractions without raising budget consumption.
- The explicit budget-to-threshold conversion could be combined with other safety layers such as output filtering to produce layered guarantees.
- Testing the state mapping and bound computation on deliberation traces from larger numbers of agents would show whether the local reliability property generalizes beyond the evaluated configurations.
Load-bearing premise
The certificate requires that a valid local bias envelope exists around the observed states and that the representation gap remains bounded inside the regions where the system chooses to act.
What would settle it
On a new dataset the empirical wrong-action rate among acted instances exceeds the declared budget β after the diagnostics confirm that the local bias envelope is valid and the representation gap is within its stated bound.
Figures
read the original abstract
Multi-agent deliberation among LLMs can improve reasoning, but deployment requires deciding when the current answer is reliable enough to act on and when it should be escalated to human review. We formulate this as budgeted act-or-defer decision making. At each round, the system maps the debate prefix to a low-dimensional state, computes a $k$-nearest-neighbor lower confidence bound on state-conditional correctness using calibration data, and acts only when the bound exceeds a user-specified reliability threshold. The certificate controls wrong actions through the decomposition $\beta = \delta + \alpha + \varepsilon_{\mathrm{act}}$, separating calibration failure, residual action risk, and representation gap. The guarantee is conditional, not distribution-free: it relies on a valid local bias envelope and an action-region representation-gap bound, and each assumption is paired with falsification-style diagnostics. Because the same absolute wrong-action budget has different meanings across tasks of different difficulty, we set budgets relative to each task's final-round error using training data only, and evaluate safety by normalized budget usage $\mathrm{WA}/\beta$. On six benchmarks against nine baselines, the method uses 9--12% of the pre-declared budget on activated datasets, reaching up to 84% automation and 96% acted-on accuracy; on stress-test datasets, it defers rather than forcing unreliable automation. Rather than relying on per-task post-hoc threshold search, the method prospectively converts a user-declared wrong-action budget into an auditable act-or-defer operating point before deployment, under explicitly stated assumptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a budgeted act-or-defer framework for multi-agent LLM deliberation. At each round, debate prefixes are mapped to low-dimensional states; a kNN lower confidence bound on state-conditional correctness is computed from calibration data, and the system acts only if the bound exceeds a user-specified reliability threshold. A conditional (non-distribution-free) guarantee is claimed via the decomposition β = δ + α + ε_act that separates calibration failure, residual action risk, and representation gap; the guarantee requires a valid local bias envelope and an action-region representation-gap bound, each paired with falsification diagnostics. Budgets are set relative to each task's final-round training error. On six benchmarks against nine baselines the method uses 9-12% of the declared budget on activated sets, reaching up to 84% automation and 96% acted-on accuracy, while deferring on stress-test data rather than forcing unreliable actions.
Significance. If the local bias envelope and representation-gap assumptions are shown to hold on the operating distributions, the work supplies a concrete, auditable procedure that converts a user-declared wrong-action budget into a pre-deployment operating point without per-task post-hoc threshold search. The relative-budget normalization and the explicit pairing of assumptions with diagnostics are constructive contributions to safe LLM deployment. The empirical numbers on automation and accuracy would be practically relevant once the conditional certificate is substantiated.
major comments (3)
- [Abstract] Abstract / guarantee statement: the certificate is explicitly conditional on a valid local bias envelope for the kNN LCB and an action-region representation-gap bound, yet the manuscript reports no quantitative outcomes from the paired falsification diagnostics (coverage rates, measured gap sizes) on the six benchmarks or calibration sets. Because these assumptions are load-bearing for the claim that the declared budget controls wrong actions, their empirical status must be shown.
- [Abstract] Risk decomposition β = δ + α + ε_act (Abstract): the bound is computed from calibration data while the budget itself is scaled relative to training-set final-round error; the manuscript does not demonstrate that the fitted quantities remain independent of the final operating point, which risks circularity in the separation of components.
- [Empirical evaluation] Empirical evaluation (benchmarks section): no error-bar information, confidence intervals, or verification that the local bias envelope and representation-gap assumptions hold on the reported datasets is supplied, leaving the 9-12% budget-usage and 96% acted-on accuracy figures without the supporting diagnostics required by the conditional guarantee.
minor comments (3)
- [Method] Notation for the state representation and the precise definition of the kNN LCB (including choice of k) should be stated explicitly with an equation number.
- [Experiments] Table or figure presenting the six benchmarks should include the raw final-round error rates used to normalize budgets, for reproducibility.
- [Baselines] The nine baselines are listed but their implementation details (hyper-parameters, prompt formats) are not referenced; a short appendix table would clarify the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to substantiate the conditional guarantees. We address each major comment below and commit to revisions that strengthen the empirical support without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract / guarantee statement: the certificate is explicitly conditional on a valid local bias envelope for the kNN LCB and an action-region representation-gap bound, yet the manuscript reports no quantitative outcomes from the paired falsification diagnostics (coverage rates, measured gap sizes) on the six benchmarks or calibration sets. Because these assumptions are load-bearing for the claim that the declared budget controls wrong actions, their empirical status must be shown.
Authors: We agree that quantitative reporting of the falsification diagnostics is necessary to support the conditional certificate. The manuscript describes the diagnostics but does not tabulate coverage rates or measured gap sizes. In revision we will add a new results subsection and table presenting these metrics on the calibration sets and all six benchmarks. revision: yes
-
Referee: [Abstract] Risk decomposition β = δ + α + ε_act (Abstract): the bound is computed from calibration data while the budget itself is scaled relative to training-set final-round error; the manuscript does not demonstrate that the fitted quantities remain independent of the final operating point, which risks circularity in the separation of components.
Authors: The budget normalization uses only training-set final-round error while the kNN LCB and its components are estimated on held-out calibration data. We will add an explicit independence check (e.g., sensitivity of δ, α, ε_act to threshold choice) in the revised methods and results sections to rule out circularity. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation (benchmarks section): no error-bar information, confidence intervals, or verification that the local bias envelope and representation-gap assumptions hold on the reported datasets is supplied, leaving the 9-12% budget-usage and 96% acted-on accuracy figures without the supporting diagnostics required by the conditional guarantee.
Authors: We acknowledge that the current manuscript omits error bars and explicit assumption-verification results. The revision will include bootstrap confidence intervals for all reported metrics and will report the outcomes of the local bias envelope and representation-gap diagnostics on the operating datasets. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central certificate uses a kNN LCB computed from calibration data and normalizes the wrong-action budget relative to training-set final-round error, which is a standard preprocessing step for cross-task comparability rather than a fitted input renamed as a prediction. The decomposition β = δ + α + ε_act is presented as an explicit separation under conditional assumptions (local bias envelope and representation-gap bound), each paired with diagnostics; this does not reduce the operating-point conversion to its own inputs by construction. No equations or steps exhibit self-definition, fitted quantities forcing the result, or load-bearing self-citation chains. The method remains self-contained against external benchmarks with independent content.
Axiom & Free-Parameter Ledger
free parameters (2)
- k (nearest neighbors)
- reliability threshold
axioms (2)
- domain assumption Valid local bias envelope
- domain assumption Action-region representation-gap bound
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. International Conference on Machine Learning , year=
-
[2]
Conference on Empirical Methods in Natural Language Processing , year=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[3]
Multi-agent debate for
Hu, Tianyu and Tan, Zhen and Wang, Song and Qu, Huaizhi and Chen, Tianlong , journal=. Multi-agent debate for
-
[4]
Debate or vote: Which yields better decisions in multi-agent large language models? , author=. arXiv preprint arXiv:2508.17536 , year=
-
[5]
From debate to equilibrium: Belief-driven multi-agent
Xie, Yi and Zhou, Zhanke and Cao, Chentao and Niu, Qiyu and Liu, Tongliang and Han, Bo , journal=. From debate to equilibrium: Belief-driven multi-agent
-
[6]
Chan, Chi-Min and Chen, Weize and Su, Yusheng and Yu, Jianxuan and Xue, Wei and Zhang, Shanghang and Fu, Jie and Liu, Zhiyuan , booktitle=
-
[7]
Debating with more persuasive
Khan, Akbir and Hughes, John and Valentine, Dan and Ruis, Laura and Sachan, Kshitij and Radhakrishnan, Ansh and Grefenstette, Edward and Bowman, Samuel R and Rockt. Debating with more persuasive. International Conference on Machine Learning , year=
-
[8]
Irving, Geoffrey and Christiano, Paul and Amodei, Dario , journal=
-
[9]
International Conference on Learning Representations , year=
Scaling large language model-based multi-agent collaboration , author=. International Conference on Learning Representations , year=
-
[10]
International Conference on Learning Representations , year=
Self-consistency improves chain of thought reasoning in language models , author=. International Conference on Learning Representations , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2402.05120 , year=
More agents is all you need , author=. arXiv preprint arXiv:2402.05120 , year=
-
[13]
Exploring collaboration mechanisms for
Zhang, Jintian and Xu, Xin and Zhang, Ningyu and Liu, Ruibo and Hooi, Bryan and Deng, Shumin , booktitle=. Exploring collaboration mechanisms for
-
[14]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Conference on Empirical Methods in Natural Language Processing , year=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[16]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle=. Can
-
[17]
arXiv preprint arXiv:2311.08298 , year=
A survey of confidence estimation and calibration in large language models , author=. arXiv preprint arXiv:2311.08298 , year=
-
[18]
Transactions on Machine Learning Research , year=
Teaching models to express their uncertainty in words , author=. Transactions on Machine Learning Research , year=
-
[19]
Manakul, Potsawee and Liusie, Adian and Gales, Mark JF , booktitle=
-
[20]
International Conference on Machine Learning , pages=
On calibration of modern neural networks , author=. International Conference on Machine Learning , pages=
-
[21]
Obtaining well calibrated probabilities using
Naeini, Mahdi Pakdaman and Cooper, Gregory F and Hauskrecht, Milos , booktitle=. Obtaining well calibrated probabilities using
-
[22]
Advances in Large Margin Classifiers , publisher=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in Large Margin Classifiers , publisher=
-
[23]
Towards Understanding Sycophancy in Language Models
Towards understanding sycophancy in language models , author=. arXiv preprint arXiv:2310.13548 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Learning Representations , year=
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. International Conference on Learning Representations , year=
-
[25]
2005 , publisher=
Algorithmic Learning in a Random World , author=. 2005 , publisher=
2005
-
[26]
Foundations and Trends in Machine Learning , volume=
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. Foundations and Trends in Machine Learning , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Conformalized quantile regression , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Classification with valid and adaptive coverage , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Learning Representations , year=
Uncertainty sets for image classifiers using conformal prediction , author=. International Conference on Learning Representations , year=
-
[30]
Journal of the ACM , volume=
Distribution-free, risk-controlling prediction sets , author=. Journal of the ACM , volume=
-
[31]
arXiv preprint arXiv:2110.01052 , year=
Learn then test: Calibrating predictive algorithms to achieve risk control , author=. arXiv preprint arXiv:2110.01052 , year=
-
[32]
The Annals of Statistics , volume=
Conformal prediction beyond exchangeability , author=. The Annals of Statistics , volume=
-
[33]
arXiv preprint arXiv:2305.18404 , year=
Conformal prediction with large language models for multi-choice question answering , author=. arXiv preprint arXiv:2305.18404 , year=
-
[34]
arXiv preprint arXiv:2306.10193 , year=
Conformal language modeling , author=. arXiv preprint arXiv:2306.10193 , year=
-
[35]
arXiv preprint arXiv:2202.07650 , year=
Conformal prediction sets with limited false positives , author=. arXiv preprint arXiv:2202.07650 , year=
-
[36]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
Debate as optimization: Adaptive conformal prediction and diverse retrieval for event extraction , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
2024
-
[37]
arXiv preprint arXiv:2305.12616 , year=
Conformal prediction with conditional guarantees , author=. arXiv preprint arXiv:2305.12616 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Adaptive conformal inference under distribution shift , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
International Conference on Learning Representations , year=
Conformal risk control , author=. International Conference on Learning Representations , year=
-
[40]
Journal of the American Statistical Association , volume=
Distribution-free predictive inference for regression , author=. Journal of the American Statistical Association , volume=
-
[41]
Machine Learning , volume=
Conditional validity of inductive conformal predictors , author=. Machine Learning , volume=
-
[42]
Information and Inference: A Journal of the IMA , volume=
The limits of distribution-free conditional predictive inference , author=. Information and Inference: A Journal of the IMA , volume=
-
[43]
Biometrika , volume=
Localized conformal prediction: A generalized inference framework for conformal prediction , author=. Biometrika , volume=
-
[44]
arXiv preprint arXiv:2310.07850 , year=
Conformal prediction with local weights: randomization enables local guarantees , author=. arXiv preprint arXiv:2310.07850 , year=
-
[45]
Journal of the American Statistical Association , volume=
Distribution-free prediction sets , author=. Journal of the American Statistical Association , volume=
-
[46]
Tools in Artificial Intelligence , year=
Inductive conformal prediction: Theory and application to neural networks , author=. Tools in Artificial Intelligence , year=
-
[47]
Statistical Science , volume=
Game-theoretic statistics and safe anytime-valid inference , author=. Statistical Science , volume=
-
[48]
The Annals of Statistics , volume=
E-values: Calibration, combination and applications , author=. The Annals of Statistics , volume=
-
[49]
The Annals of Statistics , volume=
Time-uniform, nonparametric, nonasymptotic confidence sequences , author=. The Annals of Statistics , volume=
-
[50]
Journal of the Royal Statistical Society Series B , volume=
Estimating means of bounded random variables by betting , author=. Journal of the Royal Statistical Society Series B , volume=
-
[51]
Journal of the Royal Statistical Society Series B , volume=
Safe testing , author=. Journal of the Royal Statistical Society Series B , volume=
-
[52]
Test martingales,
Shafer, Glenn and Shen, Alexander and Vereshchagin, Nikolai and Vovk, Vladimir , journal=. Test martingales,
-
[53]
Always valid inference: Continuous monitoring of
Johari, Ramesh and Koomen, Pete and Pekelis, Leonid and Walsh, David , journal=. Always valid inference: Continuous monitoring of
-
[54]
The Annals of Mathematical Statistics , volume=
Sequential tests of statistical hypotheses , author=. The Annals of Mathematical Statistics , volume=
-
[55]
arXiv preprint arXiv:2009.03167 , year=
Admissible anytime-valid sequential inference must rely on nonnegative martingales , author=. arXiv preprint arXiv:2009.03167 , year=
-
[56]
Ville, Jean , journal=
-
[57]
1996 , publisher=
A Probabilistic Theory of Pattern Recognition , author=. 1996 , publisher=
1996
-
[58]
2002 , publisher=
A Distribution-Free Theory of Nonparametric Regression , author=. 2002 , publisher=
2002
-
[59]
USAF School of Aviation Medicine, Technical Report 4 , year=
Discriminatory analysis: Nonparametric discrimination, consistency properties , author=. USAF School of Aviation Medicine, Technical Report 4 , year=
-
[60]
IEEE Transactions on Information Theory , volume=
Nearest neighbor pattern classification , author=. IEEE Transactions on Information Theory , volume=
-
[61]
The Annals of Statistics , volume=
Consistent nonparametric regression , author=. The Annals of Statistics , volume=
-
[62]
Advances in Neural Information Processing Systems , volume=
Rates of convergence for the cluster tree , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
2009 , publisher=
Introduction to Nonparametric Estimation , author=. 2009 , publisher=
2009
-
[64]
2006 , publisher=
All of Nonparametric Statistics , author=. 2006 , publisher=
2006
-
[65]
Springer Series in the Data Sciences , year=
Lectures on the nearest neighbor method , author=. Springer Series in the Data Sciences , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Distribution-free binary classification: prediction sets, confidence intervals and calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Advances in Neural Information Processing Systems , volume=
Calibration by distribution matching: Trustworthy uncertainties for deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Advances in Neural Information Processing Systems , volume=
Verified uncertainty calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
International Conference on Artificial Intelligence and Statistics , pages=
Evaluating model calibration in classification , author=. International Conference on Artificial Intelligence and Statistics , pages=
-
[70]
Advances in Neural Information Processing Systems , volume=
Calibrating predictions to decisions: A novel approach to multi-class calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Symposium on Theory of Computing , pages=
A unifying theory of distance from calibration , author=. Symposium on Theory of Computing , pages=
-
[72]
Journal of the American Statistical Association , volume=
Reaching a consensus , author=. Journal of the American Statistical Association , volume=
-
[73]
Advances in Complex Systems , volume=
Mixing beliefs among interacting agents , author=. Advances in Complex Systems , volume=
-
[74]
Journal of Artificial Societies and Social Simulation , volume=
Opinion dynamics and bounded confidence: Models, analysis and simulation , author=. Journal of Artificial Societies and Social Simulation , volume=
-
[75]
Journal of Applied Probability , volume=
On the steady state of continuous-time stochastic opinion dynamics with power-law confidence , author=. Journal of Applied Probability , volume=
-
[76]
1951 , publisher=
Social Choice and Individual Values , author=. 1951 , publisher=
1951
-
[77]
Yang, Joshua C and Dailisan, Damian and Korecki, Marcin and Hausladen, Carina I and Helbing, Dirk , journal=
-
[78]
Advances in Neural Information Processing Systems , volume=
Selective classification for deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Journal of Machine Learning Research , volume=
On the foundations of noise-free selective classification , author=. Journal of Machine Learning Research , volume=
-
[80]
Don't hallucinate, abstain: Identifying
Feng, Shangbin and Shi, Weijia and Wang, Yike and Ding, Wenxuan and Balachandran, Vidhisha and Tsvetkov, Yulia , journal=. Don't hallucinate, abstain: Identifying
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.