Bash-Commenter: Leveraging Syntax-Aware Preference Optimization to Reinforce Large Language Model for Bash Code Comment Generation
Pith reviewed 2026-06-30 05:46 UTC · model grok-4.3
The pith
Bash-Commenter improves LLM comment generation for Bash by training on minimal correct/incorrect pairs from script ASTs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
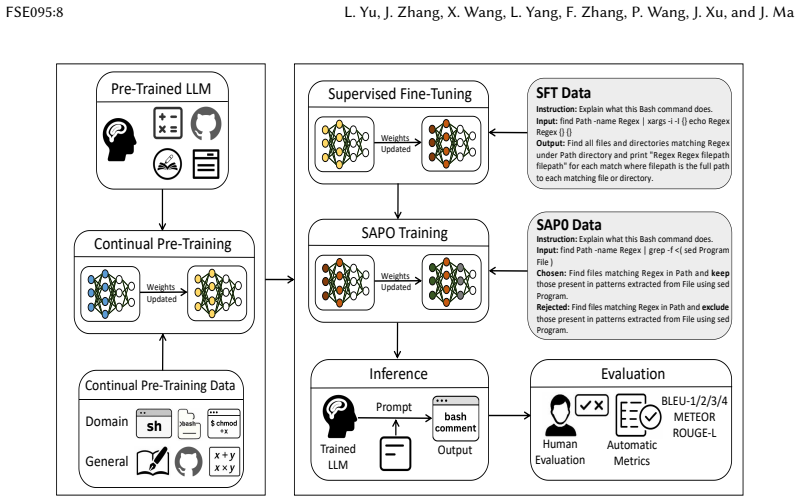
Syntax-Aware Preference Optimization constructs preference pairs by applying atomic operations to a Bash script's Abstract Syntax Tree to form minimal correct and subtly incorrect variants; after continual pre-training and supervised fine-tuning of LLaMA-3.1-8B, this produces comments scoring 33.40% BLEU-4, 58.26% METEOR and 57.03% ROUGE-L on single-line commands plus 22.15% BLEU-4, 43.89% METEOR and 32.80% ROUGE-L on multi-line scripts, with superior correctness, completeness and naturalness in human and LLM evaluations.
What carries the argument
Syntax-Aware Preference Optimization (SAPO), which builds preference pairs from atomic AST operations on Bash scripts to support fine-grained semantic learning.
If this is right
- Comment generation for single-line Bash commands reaches 33.40% BLEU-4, 58.26% METEOR and 57.03% ROUGE-L.
- Comment generation for multi-line Bash scripts reaches 22.15% BLEU-4, 43.89% METEOR and 32.80% ROUGE-L.
- Human and LLM judges rate the generated comments higher in correctness, completeness and naturalness than baseline methods.
- Continual pre-training plus supervised fine-tuning on Bash data followed by SAPO strengthens the model's grasp of Bash syntax and semantics.
Where Pith is reading between the lines
- The AST-pair construction step could be reused to create training signals for other code-generation tasks that require precise syntactic understanding.
- The same preference-optimization pattern might transfer to comment generation in other shell or scripting languages that share Bash's syntactic flexibility.
- Larger-scale application of the dataset-construction pipeline could reduce reliance on manual annotation for low-resource programming languages.
Load-bearing premise
That the preference pairs created by applying atomic operations to a script's AST produce minimal differences that reliably teach fine-grained Bash semantics rather than superficial syntax patterns.
What would settle it
Training an otherwise identical LLaMA model on the same dataset but with random or non-AST preference pairs and finding it matches or exceeds the reported BLEU/METEOR/ROUGE scores plus human ratings on the 1,064 single-line and 1,046 multi-line test sets.
Figures


read the original abstract
Bash script comprehension is challenging due to Bash's syntactic freedom and complex command structures. Despite its critical role in system administration, Bash scripts often lack adequate comments, hindering readability and maintainability. Existing automated comment generation approaches face two main challenges: (1) limited training datasets that inadequately represent real-world Bash usage patterns; and (2) insufficient understanding of Bash-specific concepts by Large Language Models (LLMs). To address these, we propose Bash-Commenter, an advanced comment generation method based on LLaMA-3.1-8B. First, we construct a comprehensive dataset of complex, multi-line Bash scripts with high-quality comments. Second, we conduct Continual Pre-training (CPT) on large-scale Bash data, followed by Supervised Fine-tuning (SFT), strengthening the model's foundational knowledge of Bash syntax and semantics. Finally, we introduce Syntax-Aware Preference Optimization (SAPO), which constructs preference pairs by applying atomic operations to a script's Abstract Syntax Tree (AST), creating minimal pairs of correct and subtly incorrect scripts for fine-grained semantics learning. Our method outperforms state-of-the-art baselines, achieving 33.40% BLEU-4, 58.26% METEOR, and 57.03% ROUGE-L for 1,064 single-line commands, and 22.15% BLEU-4, 43.89% METEOR, and 32.80% ROUGE-L for 1,046 multi-line scripts. Human and LLM evaluations further confirm superior comment quality in correctness, completeness, and naturalness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Bash-Commenter, a pipeline based on LLaMA-3.1-8B that first builds a dataset of complex Bash scripts, then applies continual pre-training (CPT) on large-scale Bash data, supervised fine-tuning (SFT), and Syntax-Aware Preference Optimization (SAPO). SAPO constructs preference pairs via atomic AST edits to produce minimally differing correct/incorrect scripts for fine-grained learning. On held-out sets of 1,064 single-line commands and 1,046 multi-line scripts the method reports 33.40% BLEU-4 / 58.26% METEOR / 57.03% ROUGE-L and 22.15% BLEU-4 / 43.89% METEOR / 32.80% ROUGE-L respectively, with supporting human and LLM judgments on correctness, completeness and naturalness.
Significance. If the SAPO pairs demonstrably alter execution semantics while remaining syntactically close, the approach supplies a concrete, reproducible technique for preference optimization on scripting languages whose flexible syntax makes standard DPO pairs unreliable. The release of a sizable, high-quality Bash dataset would also be a lasting community resource. The evaluation is presented as direct measurement on held-out data with no circularity in the reported scores.
major comments (2)
- [SAPO / method section] SAPO description (abstract and method section): the claim that atomic AST operations produce 'minimal pairs of correct and subtly incorrect scripts' for fine-grained semantics learning is load-bearing, yet the manuscript supplies neither the explicit list of operations nor any runtime validation (e.g., execution-trace or output-difference checks) that the edited pairs actually differ in behavior rather than surface syntax. Without this evidence the DPO step could be optimizing stylistic preferences instead.
- [Results / evaluation section] Results section (automatic metrics): the reported gains (e.g., 33.40% BLEU-4 on single-line) are presented without statistical significance tests, without details on baseline training protocols or hyper-parameter parity, and without dataset-construction safeguards against leakage. These omissions make it impossible to judge whether the outperformance claim is robust.
minor comments (2)
- [Abstract] Abstract: the dataset size and provenance are mentioned only qualitatively; a single sentence giving total script count and collection method would improve context.
- [Evaluation section] Evaluation: it is unclear whether the human/LLM raters saw the identical test instances used for the automatic metrics; explicit alignment would strengthen the multi-faceted claim.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful and constructive feedback on our manuscript. The comments have helped us identify areas where additional details can strengthen the presentation of our method and results. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [SAPO / method section] SAPO description (abstract and method section): the claim that atomic AST operations produce 'minimal pairs of correct and subtly incorrect scripts' for fine-grained semantics learning is load-bearing, yet the manuscript supplies neither the explicit list of operations nor any runtime validation (e.g., execution-trace or output-difference checks) that the edited pairs actually differ in behavior rather than surface syntax. Without this evidence the DPO step could be optimizing stylistic preferences instead.
Authors: We appreciate the referee's emphasis on the importance of validating that the preference pairs induce semantic differences. While the current manuscript describes the high-level idea of using atomic AST operations to create minimal pairs, we agree that an explicit list of operations and empirical validation of behavioral differences would provide stronger support for the claim. In the revised manuscript, we will add a dedicated subsection detailing the complete set of atomic AST operations employed (e.g., altering command arguments to change functionality, modifying control structures in ways that affect execution, etc.) along with quantitative results from runtime validation, such as execution trace comparisons and output difference metrics on a sample of pairs, demonstrating that the 'incorrect' scripts exhibit different behaviors. This will help confirm that SAPO targets semantic understanding. revision: yes
-
Referee: [Results / evaluation section] Results section (automatic metrics): the reported gains (e.g., 33.40% BLEU-4 on single-line) are presented without statistical significance tests, without details on baseline training protocols or hyper-parameter parity, and without dataset-construction safeguards against leakage. These omissions make it impossible to judge whether the outperformance claim is robust.
Authors: We acknowledge that the absence of statistical tests, baseline implementation details, and explicit anti-leakage measures limits the interpretability of the results. To address this, the revised version will include: (1) statistical significance testing using bootstrap resampling or paired tests with reported p-values for all metric comparisons; (2) a table or appendix detailing the training protocols, hyperparameters, and data sources for each baseline to ensure fair comparison; and (3) a description of the dataset construction process, including how the held-out sets were created with safeguards such as deduplication based on normalized script content and checks for no overlap with training data. These additions will allow for a more rigorous assessment of our claims. revision: yes
Circularity Check
No circularity: empirical results on held-out data with independent methodological choices
full rationale
The paper reports standard NLP metrics (BLEU-4, METEOR, ROUGE-L) measured on held-out test sets of 1,064 single-line and 1,046 multi-line Bash scripts. The core pipeline (CPT on Bash data, SFT, then SAPO via AST atomic operations to build preference pairs for DPO-style optimization) is a sequence of training steps whose outputs are evaluated externally; no equation or self-citation reduces the reported scores to quantities defined by the same fitted parameters. The abstract and described method contain no self-definitional loops, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling. The reader's assessment of score 1.0 aligns with a minor non-circular self-citation possibility that is not load-bearing here.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified Pre-training for Program Un- derstanding and Generation. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Kristina Toutanova, Anna Rumshisky, Luke Zettle- moyer, Dilek Hakkani-Tur,...
-
[2]
Anthropic. 2025. Claude-3.7-Sonnet. https://www.anthropic.com/news/claude-3-7-sonnet
2025
-
[3]
Qiuyuan Chen, Xin Xia, Han Hu, David Lo, and Shanping Li. 2021. Why My Code Summarization Model Does Not Work: Code Comment Improvement with Category Prediction.ACM Trans. Softw. Eng. Methodol.30, 2, Article 25 (Feb. 2021), 29 pages. doi:10.1145/3434280
-
[4]
Shiqi Cheng, Chenjie Shen, Li Yang, Lei Yu, Fengjun Zhang, and Chun Zuo. 2025. AUVANA: An Efficient and Automatic Approach to Variable Rename Refactoring via Large Pre-trained Language Model. In2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). 288–299. doi:10.1109/ISSRE66568.2025.00038
-
[5]
Stack Overflow Community. 2025. Newest ’bash’ Questions - Stack Overflow. https://stackoverflow.com/questions/ tagged/bash
2025
-
[6]
Stack Overflow Community. 2025. Newest ’shell’ Questions - Stack Overflow. https://stackoverflow.com/questions/ tagged/shell
2025
-
[7]
Godfrey, and Meiyappan Nagappan
Yiwen Dong, Zheyang Li, Yongqiang Tian, Chengnian Sun, Michael W. Godfrey, and Meiyappan Nagappan. 2023. Bash in the Wild: Language Usage, Code Smells, and Bugs.ACM Trans. Softw. Eng. Methodol.32, 1, Article 8 (Feb. 2023), 22 pages. doi:10.1145/3517193
-
[8]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational ...
-
[9]
Mingyang Geng, Shangwen Wang, Dezun Dong, Haotian Wang, Ge Li, Zhi Jin, Xiaoguang Mao, and Xiangke Liao
-
[10]
Large Language Models are Few-Shot Summarizers: Multi-Intent Comment Generation via In-Context Learning. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 39, 13 pages. doi:10.1145/3597503.3608134
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783(July 2024). arXiv:2407.21783 [cs.AI] doi:10.48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[12]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo. 2026. A survey on LLM-as-a-judge.The Innovation7, 6 (2026), 101253. doi:10.1016/j.xinn.2025.101253
-
[13]
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. 2016. Incorporating Copying Mechanism in Sequence-to- Sequence Learning. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Berlin, Germany, 1631–1640. doi:10.18653/v1/P16-1154
-
[14]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Ling...
-
[15]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.Nature 645 (2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[16]
Sonia Haiduc, Jairo Aponte, and Andrian Marcus. 2010. Supporting program comprehension with source code summarization. InProceedings of the 32nd ACM/IEEE International Conference on Software Engineering - Volume 2(Cape Town, South Africa)(ICSE ’10). Association for Computing Machinery, New York, NY, USA, 223–226. doi:10.1145/ 1810295.1810335
-
[17]
Sonia Haiduc, Jairo Aponte, Laura Moreno, and Andrian Marcus. 2010. On the Use of Automated Text Summarization Techniques for Summarizing Source Code. InProceedings of the 2010 17th Working Conference on Reverse Engineering (WCRE ’10). IEEE Computer Society, USA, 35–44. doi:10.1109/WCRE.2010.13
-
[18]
Xing Hu, Ge Li, Xin Xia, David Lo, and Zhi Jin. 2020. Deep Code Comment Generation with Hybrid Lexical and Syntactical Information.Empirical Software Engineering25, 3 (2020), 2179–2217. doi:10.1007/s10664-019-09730-9
-
[19]
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing Source Code using a Neural Attention Model. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Katrin Erk and Noah A. Smith (Eds.). Association for Computational Linguistics, Berlin, Germany, 2073–2083. do...
-
[20]
Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, et al. 2022. The stack: 3 tb of permissively licensed source code.arXiv preprint arXiv:2211.15533(Nov. 2022). arXiv:2211.15533 [cs.CL] doi:10.48550/arXiv.2211.15533
-
[21]
Li Kuang, Cong Zhou, and Xiaoxian Yang. 2022. Code comment generation based on graph neural network enhanced transformer model for code understanding in open-source software ecosystems.Automated Software Engineering29, 2 (2022), 43. doi:10.1007/s10515-022-00341-1
-
[22]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2025. From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christ...
-
[23]
Xi Victoria Lin, Chenglong Wang, Deric Pang, Kevin Vu, Luke Zettlemoyer, and Michael D. Ernst. 2017.Program Synthesis from Natural Language Using Recurrent Neural Networks. Technical Report UW-CSE-17-03-01. University of Washington, Department of Computer Science and Engineering, Seattle, WA, USA. https://dericpang.com/tellina- tr170510.pdf
2017
-
[24]
Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D Ernst. 2018. NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System. InProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). https://aclanthology.org/L18-1491
2018
-
[25]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] doi:10.48550/arXiv.2412.19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[26]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. InAdvances in Neural Information Pro- cessing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 21558–...
2023
-
[27]
Hassan, David Lo, Zhenchang Xing, and Xinyu Wang
Zhongxin Liu, Xin Xia, Ahmed E. Hassan, David Lo, Zhenchang Xing, and Xinyu Wang. 2018. Neural-machine- translation-based commit message generation: how far are we?. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering(Montpellier, France)(ASE ’18). Association for Computing Machinery, New York, NY, USA, 373–384. d...
-
[28]
Locutusque. 2024. UltraTextbooks Dataset. https://huggingface.co/datasets/Locutusque/UltraTextbooks
2024
-
[29]
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, and Adam Roberts. 2023. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas ...
2023
-
[30]
Junyi Lu, Xiaojia Li, Zihan Hua, Lei Yu, Shiqi Cheng, Li Yang, Fengjun Zhang, and Chun Zuo. 2025. Deepcrceval: Revisiting the evaluation of code review comment generation. InInternational Conference on Fundamental Approaches to Software Engineering. Springer, 43–64. doi:10.1007/978-3-031-90900-9_3
-
[31]
Junyi Lu, Lei Yu, Xiaojia Li, Li Yang, and Chun Zuo. 2023. LLaMA-Reviewer: Advancing Code Review Automation with Large Language Models through Parameter-Efficient Fine-Tuning. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). 647–658. doi:10.1109/ISSRE59848.2023.00026
-
[32]
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. 2025. A Comprehensive Overview of Large Language Models.ACM Trans. Intell. Syst. Technol. 16, 5, Article 106 (Aug. 2025), 72 pages. doi:10.1145/3744746
-
[33]
1998.Learning the Bash Shell
Cameron Newham, Bill Rosenblatt, and Gigi Estabrook. 1998.Learning the Bash Shell. O’Reilly & Associates, Inc
1998
-
[34]
OpenAI. 2025. GPT-4.1. https://platform.openai.com/docs/models/gpt-4.1
2025
-
[35]
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. 2024. OpenWebMath: An Open Dataset of High- Quality Mathematical Web Text. InInternational Conference on Learning Representations, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (Eds.), Vol. 2024. 20357–20379. https://proceedings.iclr.cc/paper_files/paper/2024/ file/5949a...
2024
-
[36]
Long Phan, Hieu Tran, Daniel Le, Hieu Nguyen, James Annibal, Alec Peltekian, and Yanfang Ye. 2021. CoTexT: Multi-task Learning with Code-Text Transformer. InProceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021), Royi Lachmy, Ziyu Yao, Greg Durrett, Milos Gligoric, Junyi Jessy Li, Ray Mooney, Graham Neubig, Yu Su, H...
-
[37]
Tamilselvam, Prince Kumar, Ashok Pon Kumar, and Pushpak Bhattacharyya
Sameer Pimparkhede, Mehant Kammakomati, Srikanth G. Tamilselvam, Prince Kumar, Ashok Pon Kumar, and Pushpak Bhattacharyya. 2024. DocCGen: Document-based Controlled Code Generation. InProceedings of the 2024 Conference Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE095. Publication date: July 2026. Bash-Commenter: Leveraging Syntax-Aware Preference Opt...
-
[38]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 53728...
2023
- [39]
-
[40]
Yiheng Shen, Xiaolin Ju, Xiang Chen, and Guang Yang. 2024. Bash comment generation via data augmentation and semantic-aware CodeBERT.Automated Software Engineering31 (2024), 30. doi:10.1007/s10515-024-00431-2
-
[41]
Stack Overflow. 2026. Bash Questions (1134 days post-ChatGPT). https://stackoverflow.com/questions/tagged/bash? sort=Newest&days=1134. Data collected: 2026-01-07, covering November 30, 2022 to January 7, 2026
2026
-
[42]
Stack Overflow. 2026. Bash Questions (3000 day baseline). https://stackoverflow.com/questions/tagged/bash?sort= Newest&days=3000. Data collected: 2026-01-07, covering October 21, 2017 to January 7, 2026
2026
-
[43]
André Storhaug, Jingyue Li, and Tianyuan Hu. 2023. Efficient Avoidance of Vulnerabilities in Auto-completed Smart Contract Code Using Vulnerability-constrained Decoding. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). 683–693. doi:10.1109/ISSRE59848.2023.00035
-
[44]
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to Sequence Learning with Neural Networks. InAdvances in Neural Information Processing Systems, Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger (Eds.), Vol. 27. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2014/file/ 5a18e133cbf9f257297f410bb7eca...
2014
-
[45]
Jiayue Tang, Li Yang, Lei Yu, Junyi Lu, Zhirong Huang, Fengjun Zhang, and Chun Zuo. 2025. Breaking Task Isolation: Enhancing Code Review Automation with Mixture-of-Experts Large Language Models. In2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). 227–238. doi:10.1109/ISSRE66568.2025.00033
-
[46]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010
2017
-
[47]
Ruiqi Wang, Jiyu Guo, Cuiyun Gao, Guodong Fan, Chun Yong Chong, and Xin Xia. 2025. Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA086 (June 2025), 23 pages. doi:10.1145/3728963
-
[48]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen- tau Yih (Eds.). Association fo...
-
[49]
Martin Weyssow, Xin Zhou, Kisub Kim, David Lo, and Houari Sahraoui. 2025. Exploring Parameter-Efficient Fine- Tuning Techniques for Code Generation with Large Language Models.ACM Trans. Softw. Eng. Methodol.34, 7, Article 204 (Aug. 2025), 25 pages. doi:10.1145/3714461
-
[50]
Hassan, and Shanping Li
Xin Xia, Lingfeng Bao, David Lo, Zhenchang Xing, Ahmed E. Hassan, and Shanping Li. 2018. Measuring program comprehension: a large-scale field study with professionals. InProceedings of the 40th International Conference on Software Engineering(Gothenburg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA,
2018
-
[51]
doi:10.1145/3180155.3182538
-
[52]
Zhu Xiaoxuan, Xiong Zhuozhi, Zhang Lin, Ye Haoning, Gu Zhouhong, Li Zihan, Jiang Sihang, Feng Hongwei, Xiao Yanghua, Wang Zili, Yang Dongjie, and Wang Shusen. 2023. CodeGPT: A Code-Related Dialogue Dataset Generated by GPT and for GPT. https://github.com/zxx000728/CodeGPT
2023
-
[53]
An Yang, Anfeng Li, Baosong Yang, et al. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] doi:10.48550/arXiv. 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[54]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. 2024. Qwen2.5 Technical Report. arXiv:2412.15115 [cs.CL] doi:10.48550/arXiv.2412.15115
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[55]
Yuanzhe Yang, Li Yang, Lingwei Li, Xiaoxiao Ma, Lei Yu, and Chun Zuo. 2023. DccGraph: Detecting Criminal Communities with Augmented Criminal Network Construction and Graph Neural Network. In2023 International Joint Conference on Neural Networks (IJCNN). 1–8. doi:10.1109/IJCNN54540.2023.10191121
-
[56]
Chi Yu, Guang Yang, Xiang Chen, Ke Liu, and Yanlin Zhou. 2022. BashExplainer: Retrieval-Augmented Bash Code Comment Generation based on Fine-tuned CodeBERT. In2022 IEEE International Conference on Software Maintenance and Evolution (ICSME). 82–93. doi:10.1109/ICSME55016.2022.00016 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE095. Publication date: J...
-
[57]
Lei Yu, Shiqi Chen, Hang Yuan, Peng Wang, Zhirong Huang, Jingyuan Zhang, Chenjie Shen, Fengjun Zhang, Li Yang, and Jiajia Ma. 2024. Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation.arXiv preprint arXiv:2411.06221(2024). doi:10.48550/arXiv.2411.06221
-
[58]
Lei Yu, Shiqi Cheng, Zhirong Huang, Jingyuan Zhang, Chenjie Shen, Junyi Lu, Li Yang, Fengjun Zhang, and Jiajia Ma
-
[59]
In2025 IEEE International Conference on Software Maintenance and Evolution (ICSME)
SAEL: Leveraging Large Language Models with Adaptive Mixture-of-Experts for Smart Contract Vulnerability Detection. In2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). 61–72. doi:10.1109/ ICSME64153.2025.00016
-
[60]
Lei Yu, Zhirong Huang, Hang Yuan, Shiqi Cheng, Li Yang, Fengjun Zhang, Chenjie Shen, Jiajia Ma, Jingyuan Zhang, Junyi Lu, and Chun Zuo. 2025. Smart-LLaMA-DPO: Reinforced Large Language Model for Explainable Smart Contract Vulnerability Detection.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA009 (June 2025), 24 pages. doi:10.1145/3728878
-
[61]
Lei Yu, Junyi Lu, Xianglong Liu, Li Yang, Fengjun Zhang, and Jiajia Ma. 2023. PSCVFinder: A Prompt-Tuning Based Framework for Smart Contract Vulnerability Detection. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). 556–567. doi:10.1109/ISSRE59848.2023.00030
-
[62]
Lei Yu, Peng Wang, Jingyuan Zhang, Xin Wang, Jia Xu, Li Yang, Changzhi Deng, Jiajia Ma, and Fengjun Zhang. 2026. SQL-Commenter: Aligning Large Language Models for SQL Comment Generation with Direct Preference Optimization. arXiv preprint arXiv:2603.18606(2026). doi:10.48550/arXiv.2603.18606
-
[63]
Lei Yu, Fengjun Zhang, Jiajia Ma, Li Yang, Yuanzhe Yang, and Wei Jia. 2023. Who Are the Money Launderers? Money Laundering Detection on Blockchain via Mutual Learning-Based Graph Neural Network. In2023 International Joint Conference on Neural Networks (IJCNN). 1–8. doi:10.1109/IJCNN54540.2023.10191217
-
[64]
Lei Yu, Jingyuan Zhang, Xin Wang, Jiajia Ma, Li Yang, and Fengjun Zhang. 2025. Towards Secure and Explainable Smart Contract Generation with Security-Aware Group Relative Policy Optimization.arXiv preprint arXiv:2509.09942 (2025). doi:10.48550/arXiv.2509.09942
-
[65]
Hang Yuan, Xizhi Hou, Lei Yu, Li Yang, Jiayue Tang, Jiadong Xu, Yifei Liu, Fengjun Zhang, and Chun Zuo. 2025. Leveraging Mixture-of-Experts Framework for Smart Contract Vulnerability Repair with Large Language Model. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1667–1679. doi:10.1109/ ASE63991.2025.00140
-
[66]
Hang Yuan, Lei Yu, Zhirong Huang, Jingyuan Zhang, Junyi Lu, Shiqi Cheng, Li Yang, Fengjun Zhang, Jiajia Ma, and Chun Zuo. 2025. Mos: Towards effective smart contract vulnerability detection through mixture-of-experts tuning of large language models.arXiv preprint arXiv:2504.12234(2025). doi:10.48550/arXiv.2504.12234
-
[67]
Daoguang Zan, Zhirong Huang, Ailun Yu, Shaoxin Lin, Yifan Shi, Wei Liu, Dong Chen, Zongshuai Qi, Hao Yu, Lei Yu, et al. 2024. Swe-bench-java: A github issue resolving benchmark for java.arXiv preprint arXiv:2408.14354(2024). doi:10.48550/arXiv.2408.14354
-
[68]
Ge Zhang, Scott Qu, Jiaheng Liu, Chenchen Zhang, Chenghua Lin, Chou Leuang Yu, Danny Pan, Esther Cheng, Jie Liu, Qunshu Lin, et al. 2024. MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series. arXiv:2405.19327 [cs.CL] doi:10.48550/arXiv.2405.19327
-
[69]
Jingyuan Zhang, Xin Wang, Lei Yu, Li Yang, and Fengjun Zhang. 2026. Binary Message Passing for Generalizable Semi-Supervised Graph Anomaly Detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 16334–16342. doi:10.1609/aaai.v40i19.38671
-
[70]
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2020. Retrieval-based neural source code summarization. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering(Seoul, South Korea)(ICSE ’20). Association for Computing Machinery, New York, NY, USA, 1385–1397. doi:10.1145/3377811.3380383
-
[71]
Jingyuan Zhang, Lei Yu, Zhirong Huang, Li Yang, and Fengjun Zhang. 2025. Topology Augmented Multi-Band and Multi-Scale Filtering for Graph Anomaly Detection.ACM Trans. Knowl. Discov. Data19, 8, Article 151 (Sept. 2025), 27 pages. doi:10.1145/3748727
-
[72]
Jipeng Zhang, Jianshu Zhang, Yuanzhe Li, Renjie Pi, Rui Pan, Runtao Liu, Ziqiang Zheng, and Tong Zhang. 2024. Bridge-Coder: Unlocking LLMs’ Potential to Overcome Language Gaps in Low-Resource Code. arXiv:2410.18957 [cs.CL] doi:10.48550/arXiv.2410.18957
-
[73]
Junsan Zhang, Yang Zhu, Ao Lu, Yudie Yan, and Yao Wan. 2025. Bash command comment generation via multi-scale heterogeneous feature fusion.Automated Software Engineering32 (2025), 28. doi:10.1007/s10515-025-00494-9
-
[74]
Yifan Zhang, Yifan Luo, Yang Yuan, and Andrew C Yao. 2024. Autonomous Data Selection with Language Models for Mathematical Texts. InICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models. https://openreview.net/forum?id=bBF077z8LF Received 2025-09-04; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE095. ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.