Why Struggle with Continuous Latents? Interpretable Discrete Latent Reasoning via Rendered Compression
Pith reviewed 2026-06-30 06:40 UTC · model grok-4.3
The pith
Rendering chains of thought as images and clustering their features produces discrete latent tokens that align reasoning with symbolic supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
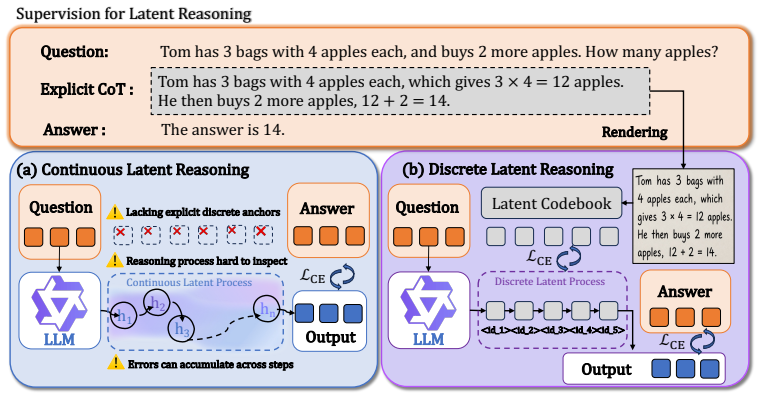
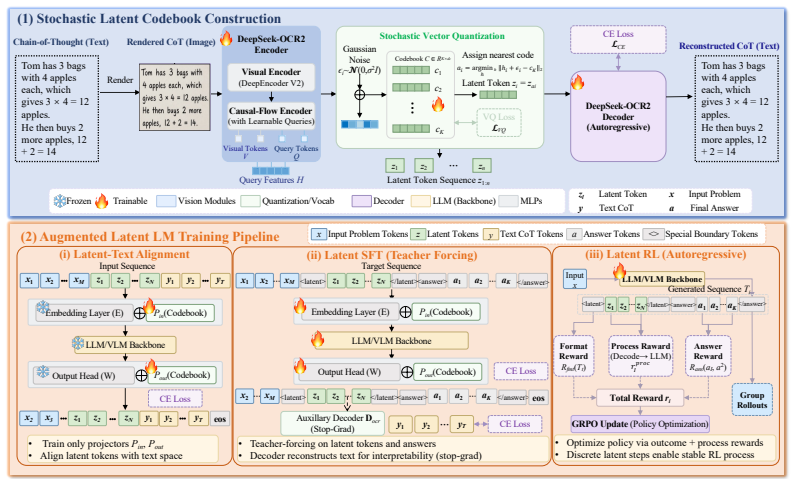
Discrete Latent Reasoning converts continuous latent states into explicit discrete tokens by rendering textual chains of thought into images, extracting visual features from those images, and constructing a discrete latent vocabulary via clustering-based fine-tuning. Expanding the vocabulary and output head then permits standard autoregressive modeling over natural language and latent tokens alike, which supports pretraining alignment, supervised fine-tuning, and reinforcement learning while delivering measurable gains in compression and stability.
What carries the argument
The render-based compression pipeline that turns textual chains of thought into images, extracts visual features, and clusters them to form the discrete latent vocabulary.
If this is right
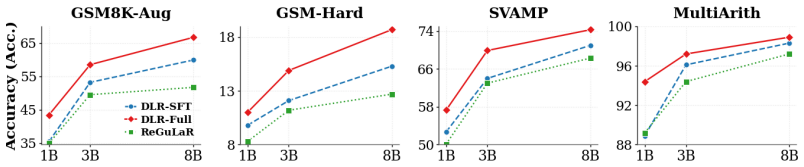
- Up to 20 times compression of output sequences on reasoning tasks while outperforming prior latent reasoning methods.
- Improved training stability through explicit discrete anchors that match symbolic supervision.
- Latent trajectories that retain interpretable semantic structure rather than opaque continuous paths.
- Compatibility with existing pretraining alignment, supervised fine-tuning, and reinforcement learning pipelines.
- A controllable basis for efficient latent reasoning that reduces inference time without sacrificing task performance.
Where Pith is reading between the lines
- The same render-and-cluster approach could be tested on non-text modalities where continuous states are first rendered into a shared visual space.
- Interpretable discrete tokens may allow targeted editing of reasoning steps by swapping or masking specific cluster members.
- If the discrete vocabulary generalizes across domains, models might share latent tokens between language and vision tasks without separate continuous spaces.
- The method raises the question of whether other forms of supervision, such as program traces, could be rendered and clustered in the same way.
Load-bearing premise
Clustering visual features from rendered chains of thought will yield discrete tokens that align with symbolic supervision and stabilize training.
What would settle it
Ablating the render-and-cluster step while keeping the same discrete vocabulary size and observing whether compression ratio, benchmark accuracy, and training stability remain unchanged would falsify the claim that the specific pipeline supplies the reported benefits.
Figures

read the original abstract
Large language models achieve high reasoning performance via explicit chain-of-thought and reinforcement learning, but require long output sequences and extended inference time. Latent reasoning reduces this cost by shifting computation into a latent space; however, continuous latent methods are hard to train, suffering from unstable and uninterpretable reasoning trajectories. We argue these issues stem from a misalignment between continuous-space reasoning and discrete symbolic supervision, as continuous states lack explicit anchors for step-by-step alignment. To resolve this, we propose \textbf{Discrete Latent Reasoning~(DLR)}, the first method that converts continuous latent states into explicit discrete tokens. Inspired by render-based compression, we render textual chains of thought into images, extract visual features, and construct a discrete latent vocabulary via clustering-based fine-tuning. Expanding the vocabulary and output head enables standard autoregressive modeling over both natural language and latent tokens, supporting pretraining alignment, SFT, and RL. Experiments on five reasoning benchmarks and two model series~(Qwen3-VL and LLaMA-3) confirm that \textbf{DLR} outperforms prior latent reasoning baselines with up to \textbf{20$\times$ compression}. Furthermore, the learned latent trajectories retain an interpretable semantic structure. Overall, discrete latent tokens provide a controllable and interpretable basis for efficient latent reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Discrete Latent Reasoning (DLR), which renders textual chains of thought into images, extracts visual features, and constructs a discrete latent vocabulary via clustering-based fine-tuning. This allows expanding the vocabulary and output head for standard autoregressive modeling over both natural language and latent tokens, supporting pretraining, SFT, and RL. Experiments on five reasoning benchmarks and two model series (Qwen3-VL and LLaMA-3) are claimed to show that DLR outperforms prior latent reasoning baselines with up to 20× compression while retaining interpretable semantic structure in the learned latent trajectories.
Significance. If the empirical results hold and the method is fully specified and reproducible, this could provide a practical route to efficient, controllable, and interpretable latent reasoning by creating discrete tokens that better align with symbolic supervision, addressing training instability in continuous latent approaches.
major comments (1)
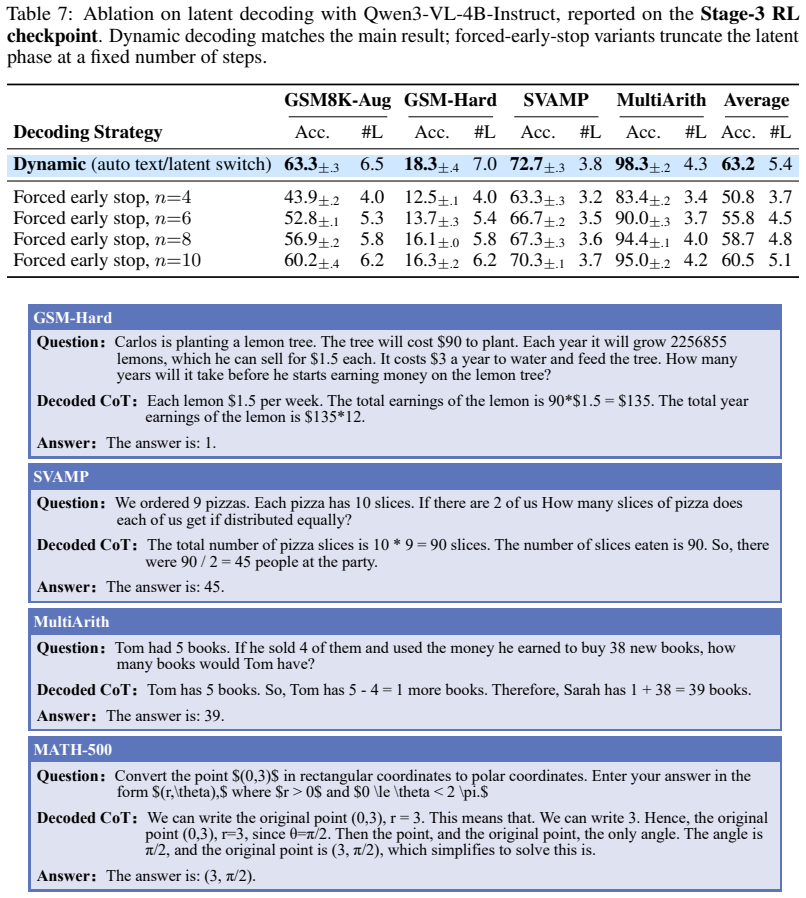
- Abstract: the central claim that DLR outperforms baselines with up to 20× compression and produces interpretable trajectories rests entirely on the render-to-image + visual-feature clustering pipeline yielding discrete tokens that align with symbolic supervision. No details are supplied on the rendering procedure, vision encoder, clustering algorithm, vocabulary size, or how the resulting tokens are injected into the output head, preventing any assessment of whether performance gains are attributable to this mechanism rather than other factors such as vocabulary expansion.
Simulated Author's Rebuttal
We thank the referee for the careful review and the comment on the abstract. We address it point by point below.
read point-by-point responses
-
Referee: [—] Abstract: the central claim that DLR outperforms baselines with up to 20× compression and produces interpretable trajectories rests entirely on the render-to-image + visual-feature clustering pipeline yielding discrete tokens that align with symbolic supervision. No details are supplied on the rendering procedure, vision encoder, clustering algorithm, vocabulary size, or how the resulting tokens are injected into the output head, preventing any assessment of whether performance gains are attributable to this mechanism rather than other factors such as vocabulary expansion.
Authors: The abstract is intentionally concise and high-level. The rendering procedure, vision encoder, clustering algorithm, vocabulary size, and integration of the resulting tokens into the output head are specified in Sections 3.1–3.3 of the manuscript. The experimental section further includes controls that expand vocabulary size independently of the clustering-based discrete construction; these ablations indicate that the reported gains arise from the alignment between discrete tokens and symbolic supervision rather than expansion alone. We will revise the abstract to include the vocabulary size and a brief reference to the vision encoder and clustering approach so that the central claim can be assessed from the abstract itself. revision: yes
Circularity Check
No circularity: empirical pipeline with external benchmark validation
full rationale
The paper describes an empirical method (rendering CoT text to images, visual feature extraction, clustering to build discrete latent vocabulary, vocabulary expansion for autoregressive modeling) and reports performance on five external reasoning benchmarks across two model families. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on reported experimental outcomes rather than any reduction of outputs to inputs by construction, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
free parameters (1)
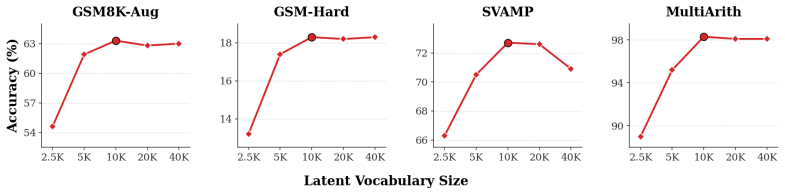
- number of clusters / latent vocabulary size
axioms (2)
- domain assumption Autoregressive modeling over mixed natural-language and latent tokens remains stable and effective after vocabulary expansion
- domain assumption Visual features extracted from rendered CoT images capture semantically meaningful reasoning steps
invented entities (1)
-
discrete latent tokens derived from clustered visual features of rendered CoT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Llama 3.2 model card
AI@Meta. Llama 3.2 model card. https://www.llama.com/docs/ model-cards-and-prompt-formats/llama3_2/, 2024. Accessed: 2026-05-06
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[4]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. doi: 10.48550/arXiv.2405.09818
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.09818 2024
-
[5]
Unlocking the black box of latent reasoning: An interpretability-guided approach to intervention
Shuochen Chang, Tong Bai, Xiaofeng Zhang, Qianli Ma, Qingyang Liu, Zhaohe Liao, Yibo Miao, and Li Niu. Unlocking the black box of latent reasoning: An interpretability-guided approach to intervention. InProceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026), 2026
2026
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Yingqian Cui, Zhenwei Dai, Bing He, Zhan Shi, Hui Liu, Rui Sun, Zhiji Liu, Yue Xing, Jiliang Tang, and Benoit Dumoulin. How do latent reasoning methods perform under weak and strong supervision?arXiv preprint arXiv:2602.22441, 2026
-
[8]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[9]
Llm latent reasoning as chain of superposition.arXiv preprint arXiv:2510.15522, 2025
Jingcheng Deng, Liang Pang, Zihao Wei, Shicheng Xu, Zenghao Duan, Kun Xu, Yang Song, Huawei Shen, and Xueqi Cheng. Llm latent reasoning as chain of superposition.arXiv preprint arXiv:2510.15522, 2025
-
[10]
Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
-
[11]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.URL https://arxiv.org/abs/2405.14838, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
PAL: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 10764–10799. PMLR, 2023
2023
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025. doi: 10.1038/s41586-025-09422-z
-
[15]
Daniel Han, Michael Han, and Unsloth team. Unsloth. https://github.com/unslothai/ unsloth, 2023. Software library
2023
-
[16]
Weston, and Yuandong Tian
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E. Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. In Conference on Language Modeling, 2025
2025
-
[17]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InProceedings of the Neural Information Processing Systems Track on Datasets and Bench- marks, 2021
2021
-
[18]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017, 2023. doi: 10.18653...
-
[19]
Vision-aligned Latent Reasoning for Multi-modal Large Language Model
Byungwoo Jeon, Yoonwoo Jeong, Hyunseok Lee, Minsu Cho, and Jinwoo Shin. Vision-aligned latent reasoning for multi-modal large language model.arXiv preprint arXiv:2602.04476, 2026. doi: 10.48550/arXiv.2602.04476
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.04476 2026
-
[20]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[21]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Kava: Latent reasoning via compressed kv-cache distillation
Anna Kuzina, Maciej Pióro, and Babak Ehteshami Bejnordi. Kava: Latent reasoning via compressed kv-cache distillation. InInternational Conference on Learning Representations, 2026
2026
-
[23]
Latent visual reasoning
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning. InInternational Conference on Learning Representations, 2026
2026
-
[24]
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
You Li, Chi Chen, Yanghao Li, Fanhu Zeng, Kaiyu Huang, Jinan Xu, and Maosong Sun. Imagination helps visual reasoning, but not yet in latent space.arXiv preprint arXiv:2602.22766,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
doi: 10.48550/arXiv.2602.22766
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.22766
-
[26]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024
2024
-
[27]
Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
Chengzhi Liu, Yuzhe Yang, Yue Fan, Qingyue Wei, Sheng Liu, and Xin Eric Wang. Rea- soning within the mind: Dynamic multimodal interleaving in latent space.arXiv preprint arXiv:2512.12623, 2025. doi: 10.48550/arXiv.2512.12623
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.12623 2025
-
[28]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. 11
2019
-
[29]
Bo Lv, Yasheng Sun, Junjie Wang, and Haoxiang Shi. Onelatent: Single-token compression for visual latent reasoning.arXiv preprint arXiv:2602.13738, 2026. doi: 10.48550/arXiv.2602. 13738
-
[30]
MathX-5M
Modotte. MathX-5M. https://huggingface.co/datasets/Modotte/MathX-5M, 2026. Hugging Face dataset
2026
-
[31]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
2022
-
[32]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094. Association for Computational Linguistics, 2021
2021
-
[33]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020
2020
-
[34]
In: Dem- berg, V., Inui, K., Marquez, L
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1743– 1752, Lisbon, Portugal, 2015. Association for Computational Linguistics. doi: 10.18653/v1/ D15-1202
-
[35]
CODI: Compress- ing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. CODI: Compress- ing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 677–693, Suzhou, China,
2025
-
[36]
doi: 10.18653/v1/2025.emnlp-main.36
Association for Computational Linguistics. doi: 10.18653/v1/2025.emnlp-main.36
-
[37]
Think silently, think fast: Dynamic latent compression of llm reasoning chains
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Ruihua Song, and Jian Luan. Think silently, think fast: Dynamic latent compression of llm reasoning chains. InAdvances in Neural Information Processing Systems, 2025
2025
-
[38]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems 30 (NeurIPS 2017), 2017
2017
-
[39]
TRL: Transformers reinforce- ment learning.https://github.com/huggingface/trl, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers reinforce- ment learning.https://github.com/huggingface/trl, 2020. Software library
2020
-
[40]
Fanmeng Wang, Haotian Liu, Guojiang Zhao, Hongteng Xu, and Zhifeng Gao. ReGuLaR: Vari- ational latent reasoning guided by rendered chain-of-thought.arXiv preprint arXiv:2601.23184, 2026
-
[41]
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language.arXiv preprint arXiv:2511.21395, 2025. doi: 10.48550/arXiv.2511.21395
-
[42]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Render- of-thought: Rendering textual chain-of-thought as images for visual latent reasoning
Yifan Wang, Shiyu Li, Peiming Li, Xiaochen Yang, Yang Tang, and Zheng Wei. Render- of-thought: Rendering textual chain-of-thought as images for visual latent reasoning. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026), 2026. 12
2026
-
[44]
Efficient reasoning via reward model.arXiv preprint arXiv:2511.09158, 2025
Yuhao Wang, Xiaopeng Li, Cheng Gong, Ziru Liu, Suiyun Zhang, Rui Liu, and Xiangyu Zhao. Efficient reasoning via reward model.arXiv preprint arXiv:2511.09158, 2025. doi: 10.48550/arXiv.2511.09158
-
[45]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. doi: 10.48550/arXiv.2510.18234
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18234 2025
-
[46]
DeepSeek-OCR 2: Visual causal flow,
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552, 2026
-
[47]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[48]
SIM-CoT: Supervised implicit chain-of-thought
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, Xipeng Qiu, and Dahua Lin. SIM-CoT: Supervised implicit chain-of-thought. InInternational Conference on Learning Representations, 2026
2026
-
[49]
Jonathan Williams and Esin Tureci. Prioritize the process, not just the outcome: Rewarding latent thought trajectories improves reasoning in looped language models.arXiv preprint arXiv:2602.10520, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[51]
Parallel continuous chain-of-thought with jacobi iteration
Haoyi Wu, Zhihao Teng, and Kewei Tu. Parallel continuous chain-of-thought with jacobi iteration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[52]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InInternational Conference on Learning Representations, 2025
2025
-
[54]
doi: 10.48550.arXiv preprint ARXIV .2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025. doi: 10.48550/arXiv.2506.17218
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.17218 2025
-
[57]
Tokensqueeze: Performance-preserving compression for reasoning llms
Yuxiang Zhang, Zhengxu Yu, Weihang Pan, Zhongming Jin, Qiang Fu, Deng Cai, Binbin Lin, and Jieping Ye. Tokensqueeze: Performance-preserving compression for reasoning llms. In Advances in Neural Information Processing Systems, 2025
2025
-
[58]
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.25741 2025
-
[59]
Jiaxuan Zou, Yaozhong Xiong, and Yong Liu. Capabilities and fundamental limits of latent chain-of-thought.arXiv preprint arXiv:2602.01148, 2026. 14 This appendix provides additional materials to supplement the main submission. Section A details the data curation procedures, including the chain-of-thought rendering process and the specific formatting proto...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.