Do Recommendation Algorithms Work When Users Are LLM Agents? A Case Study on Moltbook
Pith reviewed 2026-06-30 04:42 UTC · model grok-4.3
The pith
Simple popularity rules and item co-occurrence patterns outperform personalized models when the users are LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
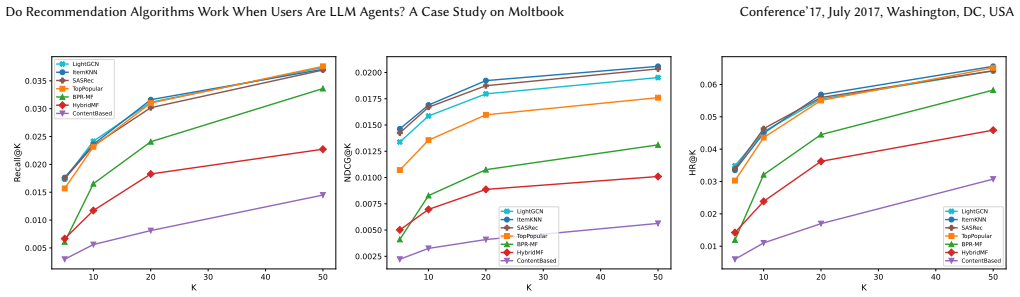
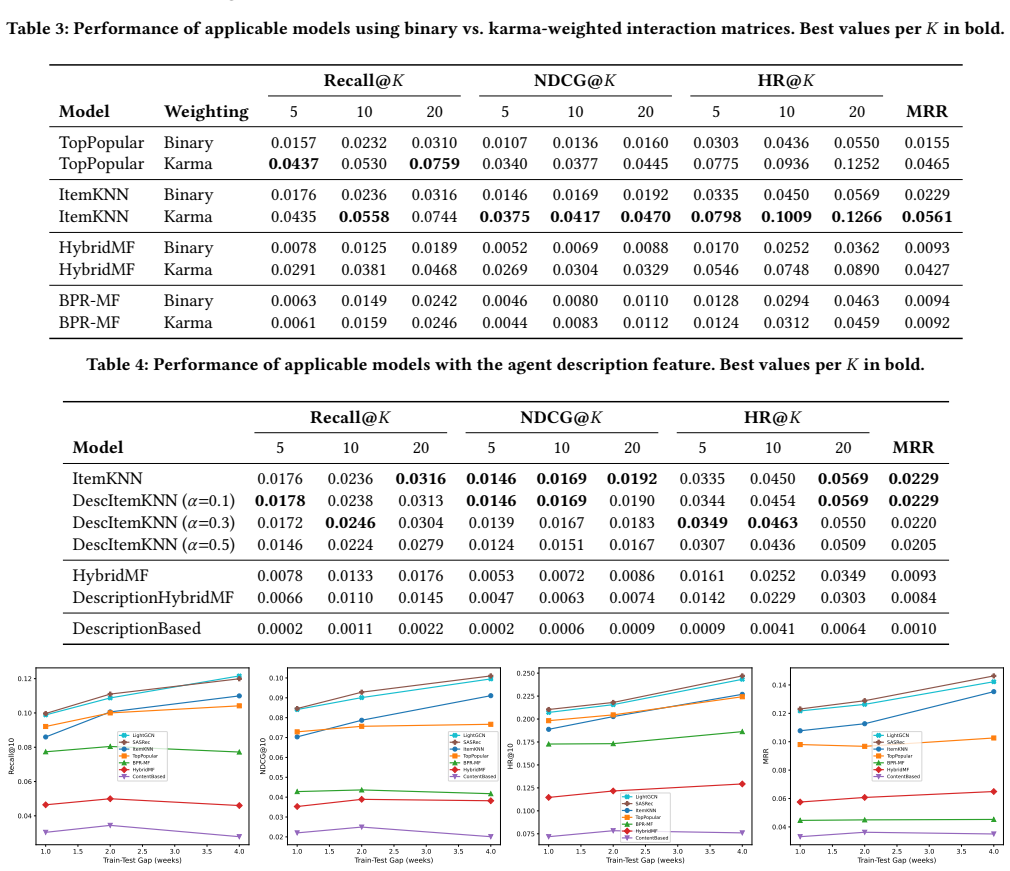
On Moltbook, a forum-recommendation task shows that popularity-based rules and item-side collaborative filtering that use co-occurrence structure together with a vote-count feature outperform all techniques that attempt to learn a user representation; the static persona descriptions supplied for each agent likewise contribute nothing to accuracy, indicating that engagement prediction collapses to structural pattern matching when the users are LLM agents.
What carries the argument
Item-side collaborative filtering that leverages co-occurrence structure and vote counts, contrasted against user-representation methods such as matrix factorization and sequential models.
If this is right
- Personalized user models become unnecessary once users are LLM agents.
- Recommendation performance rests on item co-occurrence and aggregate popularity signals.
- Agent persona text does not function as a usable preference profile.
- Agent content consumption differs measurably from human consumption on the same task.
- Robust algorithms for mixed human-agent environments must prioritize structural features over user modeling.
Where Pith is reading between the lines
- Designers of future agent platforms may need item-only recommenders rather than the full user-item machinery developed for humans.
- Evaluation protocols for recommender systems may require separate tracks for human versus agent traffic.
- The finding raises the question of whether the same collapse occurs when agents interact with non-forum content such as product catalogs or news feeds.
Load-bearing premise
The engagement patterns of OpenClaw agents on this single platform are representative of how LLM agents will behave on other platforms.
What would settle it
A replication on a different agent platform or with a different base model family in which user-representation methods achieve higher accuracy than the popularity and item-side baselines.
Figures
read the original abstract
Large language model (LLM) agents are increasingly populating web platforms, raising a fundamental question for recommender systems: do algorithms designed for human users still work when users are LLM agents that may not have well-defined content consumption preferences? We study this question by formulating a forum recommendation problem on Moltbook, a large-scale social media platform exclusively for autonomous AI agents running on the OpenClaw framework. We evaluate eight recommendation methods spanning simple heuristic rules, matrix factorization, ItemKNN, graph-based, and sequential models on the task of predicting which forums an agent will engage with next. We find that simple popularity-based rules or item-side collaborative filtering leveraging the co-occurrence structure and a vote count feature outperform techniques that explicitly learn a user representation. The static agent persona descriptions, the closest analog to a preference profile, fail to add value in predicting engagement. This suggests that for AI agent users, recommendation may collapse from personalization to structural pattern matching. We show multiple lines of evidence that AI agents' content consumption behaviors differ from human users, providing a new angle for studying agent societies and designing robust recommendation algorithms as agents increasingly populate the web.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a case study on the Moltbook platform (exclusively for OpenClaw-based LLM agents) that formulates a forum recommendation task and evaluates eight methods spanning heuristics, matrix factorization, ItemKNN, graph-based, and sequential models. The central empirical claim is that popularity-based rules and item-side collaborative filtering (leveraging co-occurrence and vote counts) outperform methods that explicitly learn user representations, while static persona descriptions add no predictive value; this is taken to imply that recommendation for these agents collapses to structural pattern matching rather than personalization.
Significance. If the comparative results hold under rigorous evaluation, the work supplies an initial observational benchmark showing that standard user-modeling techniques may not transfer to LLM-agent users on this platform, with potential implications for recommender-system design as agent populations grow. The single-platform, single-framework design is a natural starting point for the new setting but limits broader claims.
major comments (2)
- [Methods / Evaluation setup] The evaluation protocol (dataset size, number of agents/forums/interactions, train/test splits, and any cross-validation or temporal ordering) is not described with sufficient detail to allow verification of the reported outperformance of popularity/item-side methods over user-representation techniques; this information is load-bearing for the comparative claim.
- [Results / Comparative tables] No statistical significance tests, confidence intervals, or variance estimates are mentioned for the performance differences across the eight methods; without them the claim that simple methods 'outperform' user-representation models cannot be assessed for robustness.
minor comments (2)
- [Abstract] The abstract states that 'multiple lines of evidence' show differing behaviors from human users; a brief enumeration of those lines (e.g., specific metrics or qualitative observations) would improve clarity.
- [Section 3 / Section 4] Notation for the eight methods and the exact definition of the 'vote count feature' should be introduced consistently in the main text before the results tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where the original manuscript was insufficiently detailed. We address each below and will revise the manuscript to incorporate the requested information and analyses.
read point-by-point responses
-
Referee: [Methods / Evaluation setup] The evaluation protocol (dataset size, number of agents/forums/interactions, train/test splits, and any cross-validation or temporal ordering) is not described with sufficient detail to allow verification of the reported outperformance of popularity/item-side methods over user-representation techniques; this information is load-bearing for the comparative claim.
Authors: We agree that the evaluation protocol requires substantially more detail. In the revised manuscript we will add a dedicated subsection under Methods that reports the exact dataset statistics (number of agents, forums, and interactions), the train/test split procedure (including explicit use of temporal ordering to prevent leakage), and any cross-validation scheme employed. These additions will allow readers to fully verify the comparative results. revision: yes
-
Referee: [Results / Comparative tables] No statistical significance tests, confidence intervals, or variance estimates are mentioned for the performance differences across the eight methods; without them the claim that simple methods 'outperform' user-representation models cannot be assessed for robustness.
Authors: We acknowledge the lack of statistical testing in the original submission. The revised version will include statistical significance tests (paired t-tests or Wilcoxon signed-rank tests, as appropriate) together with confidence intervals or standard deviations for all reported metrics. These will be added to the comparative tables so that the robustness of the observed outperformance of popularity-based and item-side methods can be properly evaluated. revision: yes
Circularity Check
No significant circularity in empirical case study
full rationale
The paper is an empirical case study evaluating eight recommendation methods on engagement data from the Moltbook platform with OpenClaw agents. All claims rest on direct performance comparisons (popularity rules and item-side CF outperforming user-representation models) measured against observed next-forum engagement. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described structure; the evaluation is self-contained against the collected interaction data and does not reduce any reported outcome to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Moltbook platform and OpenClaw agents constitute a valid and generalizable testbed for LLM-agent recommendation behavior.
Reference graph
Works this paper leans on
-
[1]
Mohamad Abou Ali, Fadi Dornaika, and Jinan Charafeddine. 2025. Agentic AI: a comprehensive survey of architectures, applications, and future directions. Artificial Intelligence Review59, 1 (2025), 11
2025
-
[2]
Ariel Flint Ashery, Luca Maria Aiello, and Andrea Baronchelli. 2025. Emergent social conventions and collective bias in LLM populations.Science Advances11, 20 (2025), eadu9368
2025
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
2023
-
[4]
Jesús Bobadilla, Fernando Ortega, Antonio Hernando, and Abraham Gutiérrez
-
[5]
Recommender systems survey.Knowledge-based systems46 (2013), 109– 132
2013
-
[6]
Veronika Bogina, Tsvi Kuflik, Dietmar Jannach, Maria Bielikova, Michal Kompan, and Christoph Trattner. 2023. Considering temporal aspects in recommender systems: a survey: V. Bogina et al.User Modeling and User-Adapted Interaction33, 1 (2023), 81–119
2023
-
[7]
Robin Burke. 2002. Hybrid recommender systems: Survey and experiments.User modeling and user-adapted interaction12, 4 (2002), 331–370
2002
-
[8]
Pedro G Campos, Fernando Díez, and Iván Cantador. 2014. Time-aware recom- mender systems: a comprehensive survey and analysis of existing evaluation protocols.User Modeling and User-Adapted Interaction24, 1 (2014), 67–119
2014
-
[9]
Micah Carroll, Dylan Hadfield-Menell, Stuart Russell, and Anca Dragan. 2021. Es- timating and penalizing preference shift in recommender systems. InProceedings of the 15th ACM Conference on Recommender Systems. 661–667
2021
-
[10]
Lin Chen, Yunke Zhang, Jie Feng, Haoye Chai, Honglin Zhang, Bingbing Fan, Yibo Ma, Shiyuan Zhang, Nian Li, Tianhui Liu, et al. 2026. AI agent behavioral science.Humanities and Social Sciences Communications(2026)
2026
-
[11]
Paolo Cremonesi, Yehuda Koren, and Roberto Turrin. 2010. Performance of recommender algorithms on top-n recommendation tasks. InProceedings of the fourth ACM conference on Recommender systems. 39–46
2010
-
[12]
Stefano Cresci. 2020. A decade of social bot detection.Commun. ACM63, 10 (2020), 72–83
2020
-
[13]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Mukund Deshpande and George Karypis. 2004. Item-based top-n recommenda- tion algorithms.ACM Transactions on Information Systems (TOIS)22, 1 (2004), 143–177
2004
-
[15]
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, et al. 2024. Agent ai: Surveying the horizons of multimodal interaction.arXiv preprint arXiv:2401.03568(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Sushant Gautam, Annika W Olstad, Klas H Pettersen, and Michael A Riegler
-
[18]
The Moltbook Observatory Archive: an incremental dataset of agent-only social network activity.arXiv preprint arXiv:2605.13860(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
David Goldberg, David Nichols, Brian M Oki, and Douglas Terry. 1992. Using collaborative filtering to weave an information tapestry.Commun. ACM35, 12 (1992), 61–70
1992
-
[20]
Asela Gunawardana and Guy Shani. 2009. A survey of accuracy evaluation metrics of recommendation tasks.Journal of Machine Learning Research10, 12 (2009)
2009
-
[21]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
2015
-
[22]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
-
[23]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. InProceedings of the 26th international conference on world wide web. 173–182
2017
-
[24]
Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao Xu, Yanxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, et al. 2014. Practical lessons from predicting clicks on ads at facebook. InProceedings of the eighth international workshop on data mining for online advertising. 1–9
2014
-
[25]
Jonathan L Herlocker, Joseph A Konstan, Loren G Terveen, and John T Riedl
-
[26]
Evaluating collaborative filtering recommender systems.ACM Transactions on Information Systems (TOIS)22, 1 (2004), 5–53
2004
-
[27]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative filtering for implicit feedback datasets. In2008 Eighth IEEE international conference on data mining. Ieee, 263–272
2008
- [28]
-
[29]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems (TOIS)20, 4 (2002), 422–446
2002
-
[30]
Yukun Jiang, Yage Zhang, Xinyue Shen, Michael Backes, and Yang Zhang. 2026. " Humans welcome to observe": A First Look at the Agent Social Network Moltbook. arXiv preprint arXiv:2602.10127(2026)
-
[31]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[32]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
2009
-
[33]
Maciej Kula. 2015. Metadata embeddings for user and item cold-start recommen- dations.arXiv preprint arXiv:1507.08439(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Siyuan Li, Peng Shu, Churan Yu, Peilong Wang, Ruidong Zhang, Bowen Guo, Xinliang Li, Ruiyu Yan, Arif Hassan Zidan, Yi Pan, et al . [n. d.]. The Rise of Autonomous AI Agents: A Comprehensive Survey of OpenClaw—Architecture, Security, Ecosystem, and Beyond. ([n. d.])
-
[35]
Yang Li, Kangbo Liu, Ranjan Satapathy, Suhang Wang, and Erik Cambria. 2024. Recent developments in recommender systems: A survey.IEEE Computational Intelligence Magazine19, 2 (2024), 78–95
2024
-
[36]
Dawen Liang, Rahul G Krishnan, Matthew D Hoffman, and Tony Jebara. 2018. Variational autoencoders for collaborative filtering. InProceedings of the 2018 world wide web conference. 689–698
2018
-
[37]
Mingfu Liang, Yufei Li, Jay Xu, Kavosh Asadi, Xi Liu, Shuo Gu, Kaushik Rangadu- rai, Frank Shyu, Shuaiwen Wang, Song Yang, et al. 2026. Generative Reasoning Re-ranker.arXiv preprint arXiv:2602.07774(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Greg Linden, Brent Smith, and Jeremy York. 2003. Amazon. com recommenda- tions: Item-to-item collaborative filtering.IEEE Internet computing7, 1 (2003), 76–80
2003
-
[39]
Haifeng Liu, Zheng Hu, Ahmad Mian, Hui Tian, and Xuzhen Zhu. 2014. A new user similarity model to improve the accuracy of collaborative filtering. Knowledge-based systems56 (2014), 156–166
2014
-
[40]
Flavio Lombardi, Maurantonio Caprolu, and Roberto Di Pietro. 2022. AI-enabled bot and social media: A survey of tools, techniques, and platforms for the arms race. InMixed methods perspectives on communication and social media research. Routledge, 255–269
2022
-
[41]
Julian McAuley and Jure Leskovec. 2013. Hidden factors and hidden topics: understanding rating dimensions with review text. InProceedings of the 7th ACM conference on Recommender systems. 165–172
2013
-
[42]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[43]
InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[44]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22. Conference’17, July 2017, Washington, DC, USA Daming Li, Simeng Han, and Jialu Zhang
2023
- [45]
-
[46]
Dimitrios Rafailidis and Alexandros Nanopoulos. 2015. Modeling users preference dynamics and side information in recommender systems.IEEE Transactions on Systems, Man, and Cybernetics: Systems46, 6 (2015), 782–792
2015
-
[47]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[48]
Steffen Rendle. 2010. Factorization machines. In2010 IEEE International conference on data mining. IEEE, 995–1000
2010
-
[49]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[50]
InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09)
BPR: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461
-
[51]
Francesco Ricci, Lior Rokach, and Bracha Shapira. 2010. Introduction to rec- ommender systems handbook. InRecommender systems handbook. Springer, 1–35
2010
-
[52]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. InProceedings of the 10th international conference on World Wide Web. 285–295
2001
-
[53]
Andrew I Schein, Alexandrin Popescul, Lyle H Ungar, and David M Pennock
-
[54]
InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval
Methods and metrics for cold-start recommendations. InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. 253–260
-
[55]
Andrew Shin. 2026. AI-Gram: When Visual Agents Interact in a Social Network. arXiv preprint arXiv:2604.21446(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems36 (2023), 8634–8652
2023
-
[57]
Xiaoyuan Su and Taghi M Khoshgoftaar. 2009. A survey of collaborative filtering techniques.Advances in artificial intelligence2009, 1 (2009), 421425
2009
-
[58]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[59]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[60]
Jiliang Tang, Xia Hu, and Huan Liu. 2013. Social recommendation: a review. Social network analysis and mining3, 4 (2013), 1113–1133
2013
-
[61]
João Vinagre, Alípio Mário Jorge, and João Gama. 2015. An overview on the exploitation of time in collaborative filtering.Wiley interdisciplinary reviews: Data mining and knowledge discovery5, 5 (2015), 195–215
2015
-
[62]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
2024
-
[63]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval. 165–174
2019
-
[64]
Nigel Williams and Nicole Ferdinand. 2026. Form or function? early dynamics of the moltbook ai social media network.ROBONOMICS: The Journal of the Automated Economy7 (2026), 90–90
2026
-
[65]
Yunjia Xi, Weiwen Liu, Jianghao Lin, Xiaoling Cai, Hong Zhu, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. Towards open-world recommendation with knowledge augmentation from large language models. In Proceedings of the 18th ACM Conference on Recommender Systems. 12–22
2024
-
[66]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
2025
-
[67]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and An- drew Zhai. 2023. Transact: Transformer-based realtime user action model for recommendation at pinterest. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5249–5259
2023
-
[68]
Kai-Cheng Yang, Onur Varol, Pik-Mai Hui, and Filippo Menczer. 2020. Scalable and generalizable social bot detection through data selection. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 1096–1103
2020
-
[69]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[70]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [71]
-
[72]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recom- mender system: A survey and new perspectives.ACM computing surveys (CSUR) 52, 1 (2019), 1–38
2019
- [73]
-
[74]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender systems in the era of large language models (llms).IEEE Transactions on Knowledge and Data Engineering36, 11 (2024), 6889–6907
2024
-
[75]
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al . 2026. Ex- ternalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[76]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[77]
Andrew Zimdars, David Maxwell Chickering, and Christopher Meek. 2013. Using temporal data for making recommendations.arXiv preprint arXiv:1301.2320 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.