Fund2Persona: A Framework for Building and Refining Financial Advisor Personas from Fund Disclosure Data
Pith reviewed 2026-07-01 07:02 UTC · model grok-4.3
The pith
Fund disclosures can be turned into personas that capture specific manager investment expertise rather than generic LLM style.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
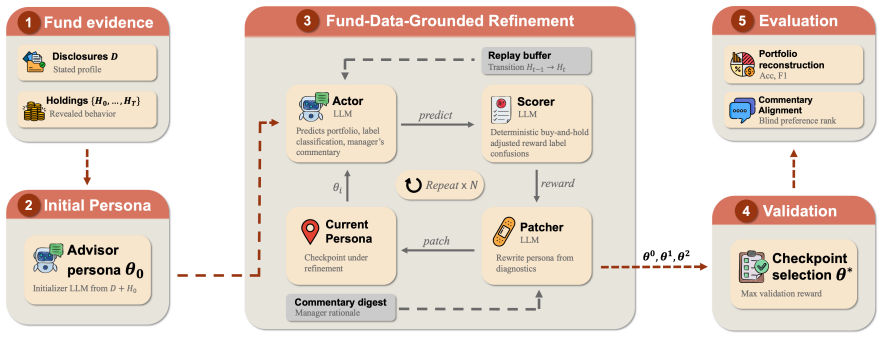
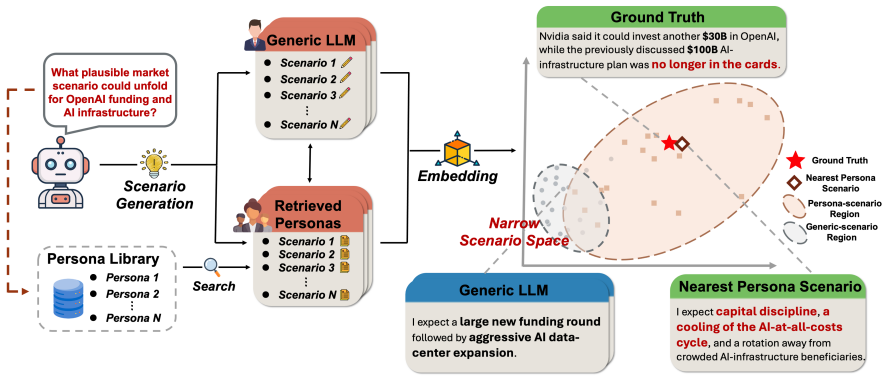
Fund2Persona grounds personas in fund disclosures, holdings transitions, market context, and manager commentary, then refines them through an agentic actor-scorer-patcher loop. On held-out data the resulting personas recover portfolio decisions and align with manager commentary more closely than generic baselines. Downstream tests show the personas produce broader investment views in scenario generation and more specific advice in investor-profile dialogues.
What carries the argument
Fund2Persona, the agentic actor-scorer-patcher loop that iteratively builds and corrects personas from fund data.
If this is right
- Personas recover specific holdings transitions on held-out fund data more accurately than generic prompts.
- They produce commentary alignment scores higher than baseline advisor prompts.
- Market-scenario generation with retrieved personas yields a wider range of plausible investment views.
- Advisory dialogues using matched personas deliver more concrete recommendations tied to investor profiles.
Where Pith is reading between the lines
- The same data-to-persona extraction could be applied to other expert domains where written records exist, such as legal case files or clinical notes.
- If the proxy measures hold, firms could maintain libraries of live personas updated quarterly from new filings rather than retraining models from scratch.
- A remaining open question is how quickly the personas degrade when market regimes shift beyond the training disclosures.
Load-bearing premise
That success at reconstructing past holdings transitions and matching manager commentary on unseen data is a good proxy for whether the personas will give useful advice in live client conversations.
What would settle it
A controlled test in which real investors receive advice from either the data-grounded personas or generic prompts and the grounded versions show no measurable improvement in decision quality or satisfaction.
Figures


read the original abstract
Demand for personalized financial advising is growing, but consistent advisor expertise is difficult to obtain, scale, and encode in LLM systems. Simple persona prompts rarely specify how a financial advisor should reason and often drift toward generic recommendations. We propose Fund2Persona, a framework that grounds financial-advisor personas in fund disclosures, holdings transitions, market context, and manager commentary, then refines them through an agentic actor--scorer--patcher loop. We evaluate the resulting personas on held-out holdings-transition reconstruction and manager-commentary alignment, where they better recover portfolio decisions and grounded manager interpretation than generic baselines. We further study two downstream diagnostics: market-scenario generation, where persona retrieval broadens plausible investment views beyond repeated generic rollouts, and advisory dialogues grounded in investor profiles, where matched personas give more specific and useful advice than a generic advisor. These results suggest that fund-data-grounded financial-advisor personas can make manager-specific investment expertise portable rather than merely changing an LLM's surface style.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Fund2Persona, a framework that constructs financial-advisor personas directly from fund disclosures (holdings, transitions, market context, and manager commentary) and refines them via an agentic actor-scorer-patcher loop. Personas are evaluated on held-out holdings-transition reconstruction and manager-commentary alignment tasks, where they outperform generic baselines; two downstream diagnostics (market-scenario generation and investor-profile-grounded advisory dialogues) are also reported. The central claim is that these fund-grounded personas encode portable, manager-specific investment reasoning rather than merely altering surface style.
Significance. If the central claim holds, the work offers a concrete method for injecting verifiable, data-derived expertise into LLM-based advisors, addressing the scalability problem of consistent financial advice. The agentic refinement loop and use of real disclosure data are methodological strengths that could be reproduced. However, the significance is limited by reliance on proxy tasks whose relationship to real-world advisory portability remains unverified; stronger evidence linking proxy gains to transferable decision logic would substantially increase impact.
major comments (2)
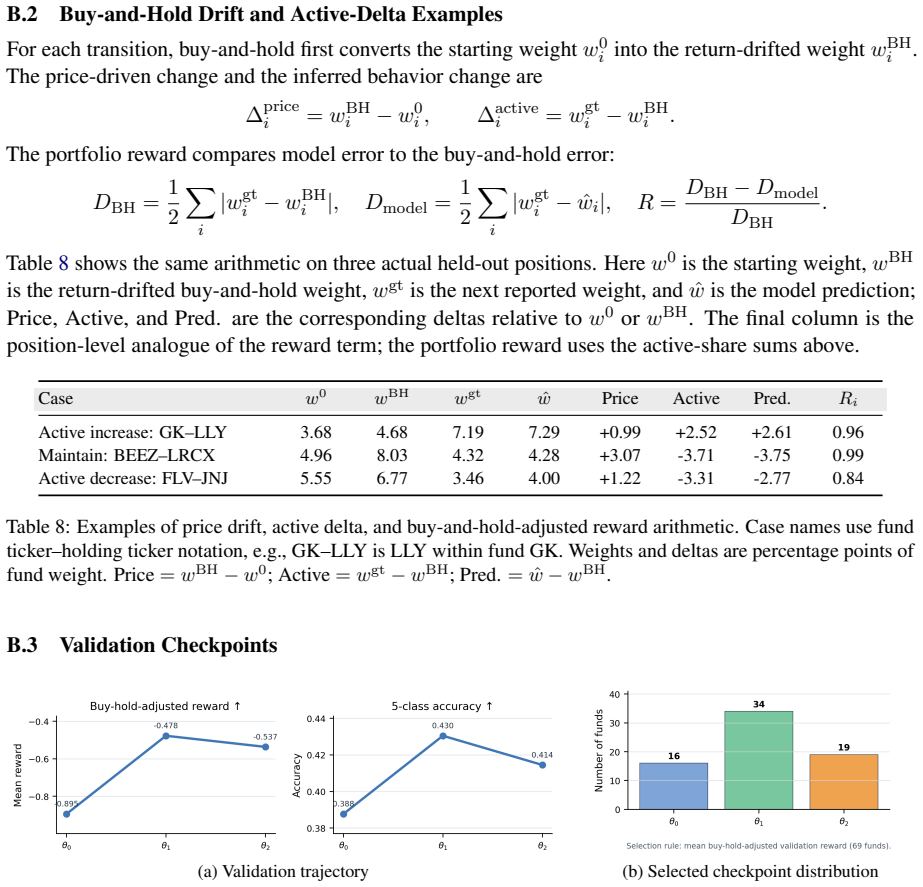
- [Evaluation] Evaluation section: the held-out reconstruction of holdings transitions and commentary alignment can be achieved by surface-level pattern matching over disclosure text without demonstrating transferable manager-specific reasoning to novel contexts. No direct test (e.g., expert-rated accuracy on unseen market events or comparison against actual manager actions outside the training funds) is described to rule out this alternative explanation for the reported gains.
- [§4] §4 (downstream diagnostics): the market-scenario generation and advisory-dialogue results are presented as evidence of broadened, specific advice, yet the manuscript does not report controls for prompt-engineering effects or statistical significance of the differences versus generic baselines, leaving open whether the observed improvements stem from the persona content or from the retrieval/conditioning procedure itself.
minor comments (2)
- [Abstract] Abstract: quantitative improvements are stated qualitatively ('better recover') without naming the exact metrics, effect sizes, or number of runs, which reduces immediate assessability.
- [Method] Notation: the distinction between 'actor', 'scorer', and 'patcher' roles in the agentic loop is introduced without an accompanying diagram or pseudocode, making the refinement procedure harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and note planned revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the held-out reconstruction of holdings transitions and commentary alignment can be achieved by surface-level pattern matching over disclosure text without demonstrating transferable manager-specific reasoning to novel contexts. No direct test (e.g., expert-rated accuracy on unseen market events or comparison against actual manager actions outside the training funds) is described to rule out this alternative explanation for the reported gains.
Authors: We agree that ruling out surface-level pattern matching is a valid concern. The agentic actor-scorer-patcher loop is intended to distill reasoning from manager commentary rather than raw text patterns, and the held-out transitions come from time periods withheld during persona construction to test generalization. However, we do not provide expert-rated accuracy on completely novel market events or direct comparisons against manager actions on funds outside the dataset. We will revise the Evaluation section to discuss this limitation explicitly and explain why the chosen proxy tasks provide a practical initial test of portability. revision: partial
-
Referee: [§4] §4 (downstream diagnostics): the market-scenario generation and advisory-dialogue results are presented as evidence of broadened, specific advice, yet the manuscript does not report controls for prompt-engineering effects or statistical significance of the differences versus generic baselines, leaving open whether the observed improvements stem from the persona content or from the retrieval/conditioning procedure itself.
Authors: The experimental setup applies identical retrieval and conditioning steps to both the fund-grounded personas and generic baselines, so differences are attributable to persona content. In the revision we will add statistical significance testing (bootstrap or paired tests) to the §4 results and insert an explicit statement confirming the controls for prompt-engineering effects. revision: yes
Circularity Check
No significant circularity; framework uses held-out evaluation data
full rationale
The paper describes a data-driven framework for constructing and refining personas from fund disclosures, with all evaluations performed on held-out holdings transitions, manager commentary, and downstream diagnostics. No equations, derivations, or fitted parameters are present that reduce predictions to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing for the central claims. The evaluation design separates training data from test proxies, rendering the reported improvements independent of the construction process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fund disclosures, holdings transitions, market context, and manager commentary contain recoverable signals of a manager's reasoning process.
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
When ``A Helpful Assistant'' Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , doi =
2024
-
[2]
Reduce disparity between llms and humans: Optimal llm sample calibration.SSRN Working Paper 4802019
Li, Ang and Chen, Haozhe and Namkoong, Hongseok and Peng, Tianyi , year =. doi:10.48550/arXiv.2503.16527 , url =. 2503.16527 , archivePrefix =
-
[3]
Nature Machine Intelligence , volume =
Large Language Models That Replace Human Participants Can Harmfully Misportray and Flatten Identity Groups , author =. Nature Machine Intelligence , volume =. 2025 , doi =
2025
-
[4]
, booktitle =
Ross, Jillian and Kim, Yoon and Lo, Andrew W. , booktitle =. 2024 , url =
2024
-
[5]
One Size Fits None: Heuristic Collapse in LLM Investment Advice
Ross, Jillian and Lo, Andrew W. , year =. One Size Fits None: Heuristic Collapse in. doi:10.48550/arXiv.2604.23837 , url =. 2604.23837 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.23837
-
[6]
Lee, Hoyoung and Seo, Junhyuk and Park, Suhwan and Lee, Junhyeong and Ahn, Wonbin and Choi, Chanyeol and Lopez-Lira, Alejandro and Lee, Yongjae , booktitle =. Your. 2025 , doi =
2025
-
[7]
Breaking Bad Financial Habits: How LLM Conversations Correct Financial Misconceptions
Ross, Jillian and So, Eric and Lo, Andrew W. , year =. Breaking Bad Financial Habits: How. doi:10.48550/arXiv.2604.27022 , url =. 2604.27022 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.27022
-
[8]
Li, Weixian Waylon and Kim, Hyeonjun and Cucuringu, Mihai and Ma, Tiejun , year =. Can. doi:10.48550/arXiv.2505.07078 , url =. 2505.07078 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.07078
-
[9]
Toward Expert Investment Teams: A Multi-Agent
Miyazaki, Kunihiro and Kawahara, Takanobu and Roberts, Stephen and Zohren, Stefan , year =. Toward Expert Investment Teams: A Multi-Agent. doi:10.48550/arXiv.2602.23330 , url =. 2602.23330 , archivePrefix =
-
[10]
The Journal of Finance , volume =
Money Doctors , author =. The Journal of Finance , volume =. 2015 , doi =
2015
-
[11]
Are Generative
Takayanagi, Takehiro and Izumi, Kiyoshi and Sanz-Cruzado, Javier and McCreadie, Richard and Ounis, Iadh , booktitle =. Are Generative. 2025 , doi =
2025
-
[12]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Park, Joon Sung and Zou, Carolyn Q. and Kamphorst, Jonne and Egan, Niles and Shaw, Aaron and Hill, Benjamin Mako and Cai, Carrie and Morris, Meredith Ringel and Liang, Percy and Willer, Robb and Bernstein, Michael S. , year =. doi:10.48550/arXiv.2411.10109 , url =. 2411.10109 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.10109
-
[13]
Political Analysis , volume =
Out of One, Many: Using Language Models to Simulate Human Samples , author =. Political Analysis , volume =. 2023 , doi =
2023
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Virtual Personas for Language Models via an Anthology of Backstories , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , doi =
2024
-
[15]
Castricato, Louis and Lile, Nathan and Rafailov, Rafael and Fr. 2024 , eprint =. doi:10.48550/arXiv.2407.17387 , url =
-
[16]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Scaling Synthetic Data Creation with 1,000,000,000 Personas , author =. 2024 , eprint =. doi:10.48550/arXiv.2406.20094 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.20094 2024
-
[17]
Advances in Neural Information Processing Systems , volume =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2023 , doi =
2023
-
[18]
and Cao, Yuan , booktitle =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik R. and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[19]
Advances in Neural Information Processing Systems , volume =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , volume =. 2023 , doi =
2023
-
[20]
Scaling Open-Ended Reasoning to Predict the Future , author =. 2025 , eprint =. doi:10.48550/arXiv.2512.25070 , url =
-
[21]
2024 , doi =
Sanz-Cruzado, Javier and Droukas, Nikolaos and McCreadie, Richard , booktitle =. 2024 , doi =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.