KbSD: Knowledge Boundary aware Self-Distillation for Behavioral Calibration in Agentic Search
Pith reviewed 2026-06-30 05:59 UTC · model grok-4.3
The pith
KbSD uses self-distillation from an identical teacher model supplied with explicit knowledge-boundary hints to supply dense supervision where binary rewards are too sparse for calibrated decisions in agentic search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
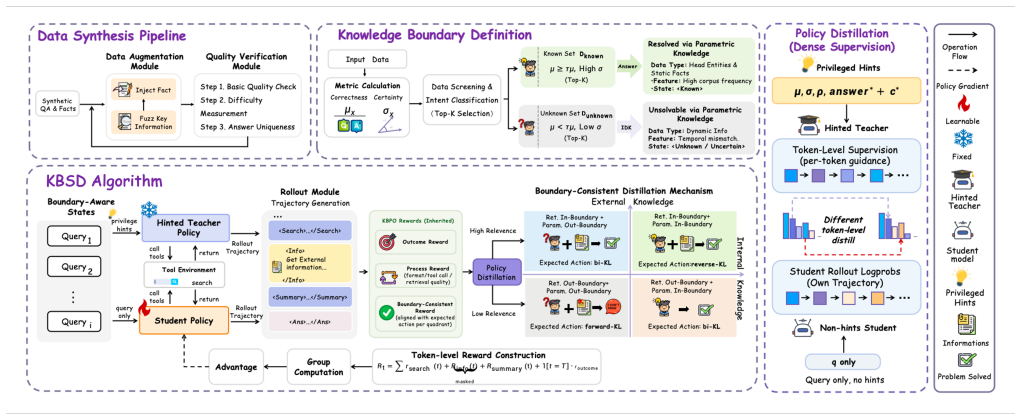
KbSD constructs a hint-augmented teacher architecturally identical to the student that receives explicit knowledge boundary signals including parametric certainty, retrieval quality, and ground-truth answers to generate calibrated reasoning demonstrations. This information-asymmetric self-distillation supplies dense token-level supervision without a larger external model. A quadrant-adaptive distillation objective applies reverse KL for concentrated integration, forward KL for diverse refusal, and Pareto-optimal bidirectional KL for asymmetric quadrants, combined with outcome-level sparse rewards.
What carries the argument
The hint-augmented teacher that receives explicit knowledge-boundary signals to produce calibrated demonstrations for self-distillation.
If this is right
- Task accuracy rises over strong baselines across multiple benchmarks.
- Hallucination rates drop, with largest improvements in quadrants where sparse rewards give least guidance.
- Calibration works without requiring a larger external teacher model.
- Quadrant-adaptive objectives handle differing reasoning distributions across knowledge states.
Where Pith is reading between the lines
- The same self-distillation pattern could supply dense signals in other sparse-reward decision tasks beyond search.
- Extending the boundary signals to include uncertainty estimates from multiple retrieval sources might further tighten calibration.
- The quadrant framework offers a template for adaptive objectives in any setting where reasoning distributions vary by state.
Load-bearing premise
An architecturally identical teacher given explicit knowledge-boundary signals can produce sufficiently calibrated reasoning demonstrations to serve as effective dense supervision for the student.
What would settle it
Training runs on the same benchmarks where KbSD produces no accuracy gains or hallucination reductions relative to standard RL baselines, particularly inside the sparse-reward quadrants.
Figures

read the original abstract
Agentic search equips large language models with dynamic retrieval abilities, but existing reinforcement learning methods remain limited by reward sparsity in knowledge boundary calibration -- deciding when to trust parametric memory, when to rely on retrieved evidence, and when to abstain. Binary rewards can penalize undesirable outcomes, but provide little guidance on the reasoning process required to make calibrated decisions across different knowledge states. To address this, we propose KbSD (Knowledge boundary Self-Distillation), a framework that tackles this limitation through dense token-level supervision, outcome-level sparse rewards, and quadrant-adaptive optimization. KbSD constructs a hint-augmented teacher, architecturally identical to the student, that receives explicit knowledge boundary signals -- including parametric certainty, retrieval quality, and ground-truth answers -- to generate calibrated reasoning demonstrations. This information-asymmetric self-distillation enables dense supervision without requiring a larger external model. To further account for the heterogeneous reasoning distributions across knowledge states, we introduce a quadrant-adaptive distillation objective: reverse KL for concentrated integration, forward KL for diverse refusal, and Pareto-optimal bidirectional KL for asymmetric quadrants requiring both precision and coverage. Experiments on multiple benchmarks show that KbSD consistently improves both task accuracy and hallucination mitigation over strong baselines, with the largest gains appearing in the challenging quadrants where sparse rewards are least informative.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KbSD, a self-distillation framework for agentic search that addresses reward sparsity in knowledge-boundary calibration. An architecturally identical hint-augmented teacher receives explicit signals (parametric certainty, retrieval quality, ground-truth answers) to produce calibrated reasoning demonstrations for the student; these are combined with quadrant-adaptive KL objectives (reverse KL for integration, forward KL for refusal, bidirectional for asymmetric cases) to supply dense token-level supervision alongside sparse outcome rewards. Experiments reportedly show consistent gains in task accuracy and hallucination mitigation over baselines, largest in challenging quadrants.
Significance. If the results and the underlying assumption hold, the method supplies a parameter-efficient route to dense supervision for LLM calibration without external larger models, directly targeting the heterogeneous reasoning distributions that arise when deciding between parametric memory and retrieval. The quadrant-adaptive objective is a concrete technical contribution to handling non-uniform knowledge states.
major comments (2)
- [Abstract / §3] Abstract / §3 (method description): The central claim that information-asymmetric self-distillation supplies effective dense supervision rests on the untested premise that an architecturally identical teacher can translate explicit boundary signals (including ground-truth) into meaningfully higher-quality reasoning trajectories than the sparse rewards already available; no ablation isolating the effect of the boundary signals versus the hints themselves is described, leaving the attribution of quadrant gains to KbSD unsupported.
- [§4] §4 (experiments): The reported largest gains in sparse-reward quadrants are presented without per-quadrant baseline ablations, teacher-output quality metrics (e.g., calibration of the demonstrations), or controls confirming that the adaptive KL objectives outperform simple hint augmentation, which is load-bearing for the claim that the method mitigates the sparsity problem.
minor comments (1)
- [§3] The precise implementation of the 'Pareto-optimal bidirectional KL' (including any weighting or optimization procedure) is referenced but not given an equation or pseudocode, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract / §3 (method description): The central claim that information-asymmetric self-distillation supplies effective dense supervision rests on the untested premise that an architecturally identical teacher can translate explicit boundary signals (including ground-truth) into meaningfully higher-quality reasoning trajectories than the sparse rewards already available; no ablation isolating the effect of the boundary signals versus the hints themselves is described, leaving the attribution of quadrant gains to KbSD unsupported.
Authors: We agree that an explicit ablation separating the contribution of the boundary signals from the hints alone would strengthen attribution of the observed gains. Our existing baselines lack both hints and distillation, and the largest improvements occur in quadrants where boundary awareness is most relevant; however, this does not fully isolate the signals. We will add a targeted ablation in §3 and §4 comparing hint-augmented teachers with and without the explicit boundary signals (parametric certainty, retrieval quality, ground-truth) to directly test the premise. revision: yes
-
Referee: [§4] §4 (experiments): The reported largest gains in sparse-reward quadrants are presented without per-quadrant baseline ablations, teacher-output quality metrics (e.g., calibration of the demonstrations), or controls confirming that the adaptive KL objectives outperform simple hint augmentation, which is load-bearing for the claim that the method mitigates the sparsity problem.
Authors: We acknowledge these controls are necessary to substantiate the claim that the quadrant-adaptive objectives specifically address sparsity beyond hint augmentation. We will expand §4 with (i) per-quadrant baseline ablations, (ii) calibration metrics (e.g., expected calibration error) on the teacher demonstrations, and (iii) an ablation of adaptive KL versus non-adaptive hint-augmented distillation. These additions will be reported alongside the existing results. revision: yes
Circularity Check
No significant circularity; derivation relies on explicit information asymmetry and experimental validation
full rationale
The paper's core method constructs an architecturally identical but information-augmented teacher that receives explicit parametric certainty, retrieval quality, and ground-truth signals to produce demonstrations, then applies quadrant-adaptive KL objectives for distillation. This setup is presented as a novel framework for dense supervision in sparse-reward settings, with gains attributed to the asymmetry and adaptive objectives rather than any self-referential definitions or fitted parameters renamed as predictions. No equations, self-citations, or uniqueness theorems are invoked in the abstract or description that reduce the claimed improvements to tautological inputs by construction. The reported task accuracy and hallucination mitigation results are positioned as empirical outcomes on benchmarks, making the derivation self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representations, volume 2024, 21246–21263
On- policy distillation of language models: Learning from self- generated mistakes. InInternational Conference on Learning Representations, volume 2024, 21246–21263. Asai, A.; Wu, Z.; Wang, Y .; Sil, A.; and Hajishirzi, H
2024
-
[2]
InThe Twelfth International Con- ference on Learning Representations (ICLR)
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Con- ference on Learning Representations (ICLR). Dong, G.; Bao, L.; Wang, Z.; Zhao, K.; Li, X.; Jin, J.; Yang, J.; Mao, H.; Zhang, F.; Gai, K.; et al. 2025a. Agen- tic Entropy-Balanced Policy Optimization.arXiv preprint arXiv:2510.14545. Dong, G.; M...
-
[3]
Gu, Y .; Dong, L.; Wei, F.; and Huang, M
Beyond ten turns: Unlocking long-horizon agen- tic search with large-scale asynchronous rl.arXiv preprint arXiv:2508.07976. Gu, Y .; Dong, L.; Wei, F.; and Huang, M
-
[4]
InInter- national Conference on Learning Representations, volume 2024, 32694–32717
Minillm: Knowledge distillation of large language models. InInter- national Conference on Learning Representations, volume 2024, 32694–32717. Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; and Chang, M
2024
-
[5]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Self- distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002. Hinton, G.; Vinyals, O.; and Dean, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Distilling the Knowledge in a Neural Network
Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531. Ho, X.; Duong, A.-K.; Nguyen, Q.-H.; and Nguyen, S
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reinforced Internal-External Knowledge Synergistic Rea- soning for Efficient Adaptive Search Agent.arXiv preprint arXiv:2505.07596. Jiang, X.; Fang, Y .; Qiu, R.; Zhang, H.; Xu, Y .; Chen, H.; Zhang, W.; Zhang, R.; Fang, Y .; Chu, X.; et al
-
[8]
TC- RAG: Turing-Complete RAG’s Case study on Medical LLM Systems.arXiv preprint arXiv:2408.09199. Jiang, Z.; Xu, F. F.; Gao, L.; Sun, Z.; Liu, Q.; Dwyer, J.; and Iyyer, M
-
[9]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning.arXiv preprint arXiv:2503.09516. Joshi, M.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Krishna, S.; Krishna, K.; Mohananey, A.; Schwarcz, S.; Stam- bler, A.; Upadhyay, S.; and Faruqui, M
Distillm-2: A contrastive approach boosts the distillation of llms.arXiv preprint arXiv:2503.07067. Krishna, S.; Krishna, K.; Mohananey, A.; Schwarcz, S.; Stam- bler, A.; Upadhyay, S.; and Faruqui, M
-
[11]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented genera- tion. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 4745–4759. Kwiatkowski, T.; et al
2025
-
[12]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Search-o1: Agentic Search-Enhanced Large Reasoning Models.arXiv preprint arXiv:2501.05366. Li, Y .; Zuo, Y .; He, B.; Zhang, J.; Xiao, C.; Qian, C.; Yu, T.; Gao, H.-a.; Yang, W.; Liu, Z.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking on- policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016. Mallen, A.; Asai, A.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
GAIA: a benchmark for General AI Assistants
GAIA: A Benchmark for General AI Assistants.arXiv preprint arXiv:2311.12983. Nakano, R.; Hilton, J.; Balaji, S.; Wu, J.; Ouyang, L.; Kim, C.; Hesse, C.; Jain, S.; Kosaraju, V .; Saunders, W.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332. Press, O.; Zhang, M.; Min, S.; Schmidt, L.; Smith, N. A.; and Lewis, M
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Measuring and Narrowing the Compositionality Gap in Language Models
Measuring and Narrowing the Com- positionality Gap in Language Models.arXiv preprint arXiv:2210.03350. Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y .; Wu, Y .; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models.arXiv preprint arXiv:2402.03300. Singh, A.; Ehtesham, A.; Kumar, S.; and Khoei, T. T
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Agentic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136. Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A
MusiQue: Multihop Reasoning Dataset with Expla- nation.arXiv preprint arXiv:2108.00573. Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A
-
[20]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533. Yan, S.-Q.; Gu, J.-C.; Zhu, Y .; and Ling, Z.-H
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Corrective Retrieval Augmented Generation
Cor- rective Retrieval Augmented Generation.arXiv preprint arXiv:2401.15884. Yang, C.; Qin, C.; Si, Q.; Chen, M.; Gu, N.; Yao, D.; Lin, Z.; Wang, W.; Wang, J.; and Duan, N. 2026a. Self-distilled rlvr. arXiv preprint arXiv:2604.03128. Yang, Q. A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Dong, G.; Wei, H.; Lin, H.; Yang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen2.5 Technical Report.ArXiv, abs/2412.15115. Yang, W.; Liu, W.; Xie, R.; Yang, K.; Yang, S.; and Lin, Y . 2026b. Learning beyond teacher: Generalized on- policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125. Yang, Z.; Qi, P.; Zhang, S.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents.arXiv preprint arXiv:2506.15841. Zhu*, R.; Jiang*, X.; Wu*, J.; Ma, Z.; Song, J.; Bai, F.; Lin, D.; Wu, L.; and He, C
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.