IBRSteG: Learning a Generalizable Steganography Framework for 3D Gaussian Splatting
Pith reviewed 2026-06-30 06:26 UTC · model grok-4.3
The pith
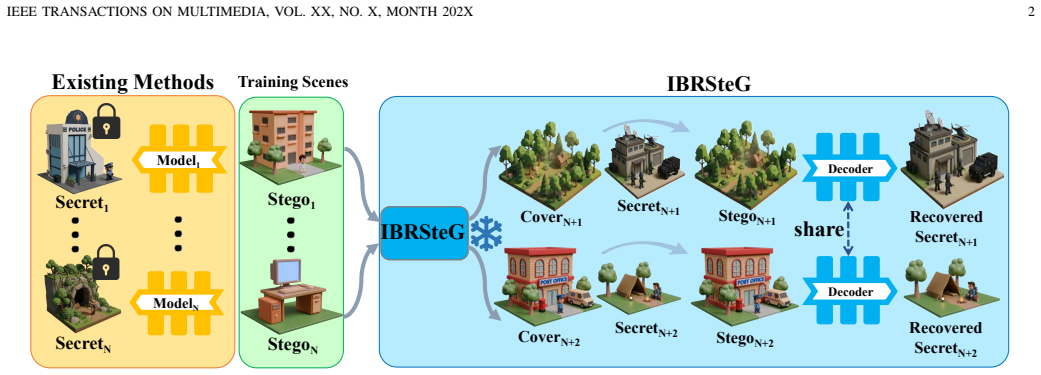
IBRSteG trains one network to embed secret 3D Gaussian scenes into cover scenes for direct reconstruction without per-scene optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
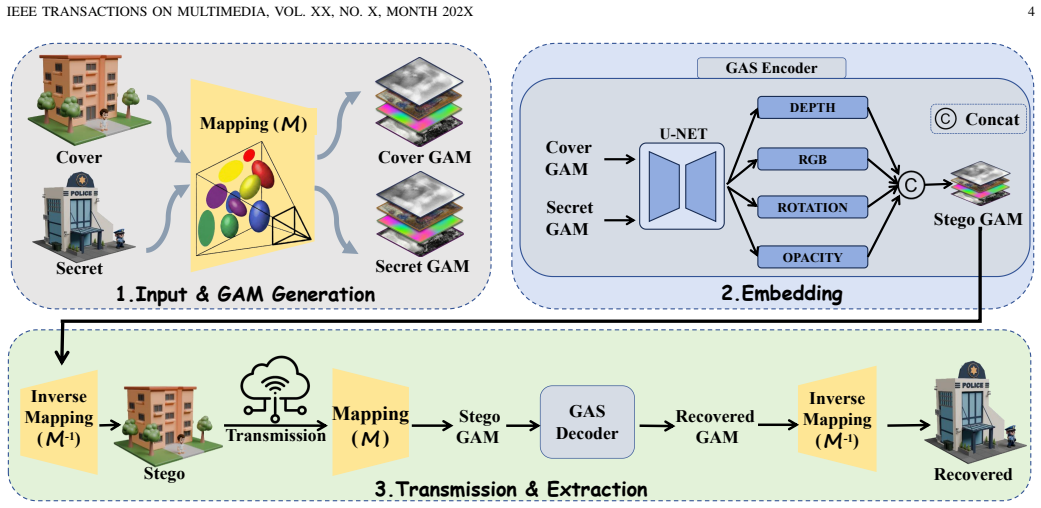
IBRSteG formulates 3D steganography as a feed-forward 3D Gaussian embedding process that generalizes across different 3DGS scenes. The GAS network learns a scene-independent embedding function by injecting the attributes of secret 3D Gaussian points into a cover scene, thereby directly reconstructing the steganographic scenes without per-scene finetuning or optimization. Transforming 3D Gaussian into structured attributes makes them compatible with 2D learning paradigms, enhancing generalization.
What carries the argument
The GAS (Gaussian Attributes Steganographer) network, which learns to embed secret 3D Gaussian point attributes into cover scenes in a scene-independent manner.
If this is right
- Steganographic scenes can be reconstructed directly without any per-scene optimization.
- The embedding function generalizes to different and unseen 3DGS scenes.
- The method achieves higher capacity and security than prior scene-specific approaches.
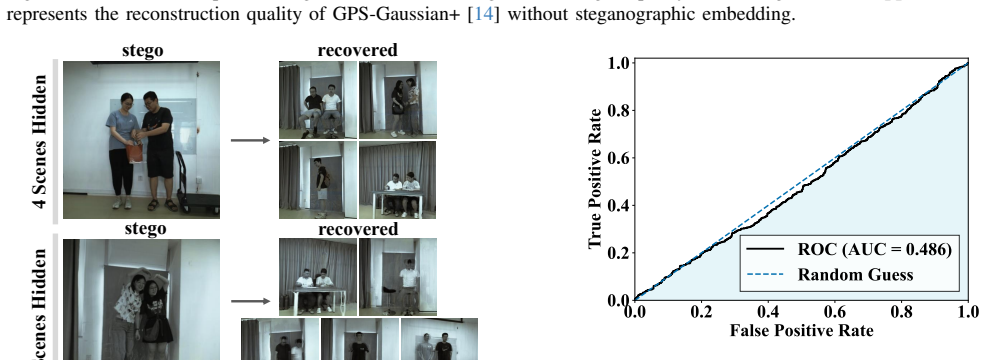
- Secret 3D scene content remains concealed with high visual quality in the output.
Where Pith is reading between the lines
- The feed-forward design could support real-time secure transmission of 3D content.
- Similar attribute-structuring steps might enable generalization in other 3D representation formats.
- The approach could reduce the need for per-instance training in related 3D hiding tasks.
- Limits of generalization would appear on scene types far from the training distribution.
Load-bearing premise
Transforming 3D Gaussian attributes into structured forms compatible with 2D learning will yield an embedding function that generalizes to new scenes without adaptation.
What would settle it
Running the trained GAS network on a completely new 3DGS scene pair and checking whether the output steganographic scene matches expected visual quality and successfully hides the secret without visible errors or extra training.
Figures



read the original abstract
Recent advances in deep learning have notably improved steganographic message hiding. However, designing a generalizable steganographic approach for 3D Gaussian Splatting (3DGS) that can embed meaningful 3D scene content remains challenging. In this paper, we propose IBRSteG, a generalizable framework for 3DGS steganography that enables undetectable concealment of secret scenes within a steganographic scene. Unlike existing approaches whose parameter generation is rigidly coupled with the specific scene, we formulate 3D steganography as a feed-forward 3D Gaussian embedding process that generalizes across different 3DGS scenes. To realize this, we introduce GAS (Gaussian Attributes Steganographer), a network that learns a scene-independent embedding function by injecting the attributes of secret 3D Gaussian points into a cover scene, thereby directly reconstructing the steganographic scenes without per-scene finetuning or optimization. By transforming 3D Gaussian into these structured attributes, these attributes are compatible with 2D learning paradigms and benefit from their structured nature, thereby enhancing generalization to unseen 3DGS scenes. Extensive experiments on established datasets demonstrate that IBRSteG can effectively conceal different scenes with high visual quality, and achieves superior capacity and security. Code is available at https://github.com/LingXiang2023/IBRSteG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IBRSteG, a generalizable steganography framework for 3D Gaussian Splatting (3DGS). It formulates 3D steganography as a feed-forward embedding process using the GAS (Gaussian Attributes Steganographer) network, which injects attributes of secret 3D Gaussian points into a cover scene to directly reconstruct steganographic scenes without per-scene finetuning or optimization. The key mechanism is transforming 3D Gaussian attributes into structured forms compatible with 2D learning paradigms to enable generalization across different 3DGS scenes. Experiments on established datasets claim high visual quality, superior capacity, and security.
Significance. If the generalization claim holds, this would represent a meaningful advance over prior 3DGS steganography methods that require scene-specific optimization, enabling efficient, feed-forward concealment of entire scenes. The public code release at the provided GitHub link is a positive contribution that supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The central claim that 'transforming 3D Gaussian into these structured attributes' enables a scene-independent embedding function via GAS is load-bearing for the generalization result, yet the text provides no concrete description of the transformation (e.g., ordering, padding, or canonicalization steps) that would make the mapping invariant to variable Gaussian counts, spatial distributions, or attribute statistics across scenes.
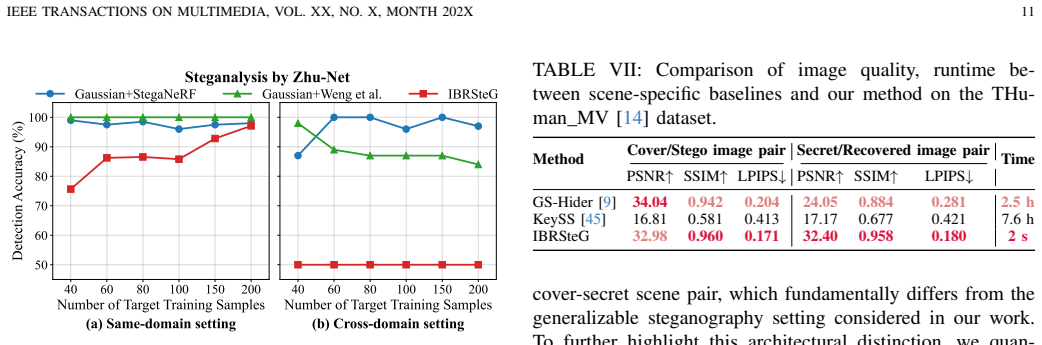
- [§4] §4 (Experiments): The cross-scene generalization results are asserted to demonstrate effectiveness on unseen 3DGS scenes, but without reported details on the diversity of training vs. test scenes (e.g., variation in Gaussian count ranges or scene complexity) or ablation on the transformation step, it is unclear whether the feed-forward network truly avoids the need for adaptation.
minor comments (1)
- [Abstract] Abstract: Minor phrasing issue—'3D Gaussian' should consistently read '3D Gaussians' when referring to points.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our generalization claims. We address each major point below and will incorporate clarifications and additional details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that 'transforming 3D Gaussian into these structured attributes' enables a scene-independent embedding function via GAS is load-bearing for the generalization result, yet the text provides no concrete description of the transformation (e.g., ordering, padding, or canonicalization steps) that would make the mapping invariant to variable Gaussian counts, spatial distributions, or attribute statistics across scenes.
Authors: We agree that Section 3 would benefit from a more explicit description of the transformation process. In the revision we will expand the method section to detail the ordering of Gaussian points (by spatial coordinates), padding strategy for variable point counts, and attribute canonicalization steps that normalize statistics across scenes. This will make clear how the structured representation enables the scene-independent mapping learned by GAS. revision: yes
-
Referee: [§4] §4 (Experiments): The cross-scene generalization results are asserted to demonstrate effectiveness on unseen 3DGS scenes, but without reported details on the diversity of training vs. test scenes (e.g., variation in Gaussian count ranges or scene complexity) or ablation on the transformation step, it is unclear whether the feed-forward network truly avoids the need for adaptation.
Authors: We will augment Section 4 with a summary of training versus test scene statistics (including Gaussian count ranges and complexity metrics) drawn from the datasets used, plus an ablation isolating the transformation step. These additions will provide direct evidence that the feed-forward network generalizes without scene-specific adaptation. revision: yes
Circularity Check
No significant circularity; central claim is a design choice with external empirical support
full rationale
The paper's derivation chain consists of a methodological proposal: transform 3D Gaussian attributes into structured forms, then train GAS as a feed-forward network to embed secret scenes into cover scenes. This is asserted to generalize without per-scene optimization because the structured attributes are 'compatible with 2D learning paradigms.' No equations are shown that reduce a claimed prediction to a fitted input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The generalization claim is presented as an empirical outcome on established datasets rather than a tautological re-expression of the inputs. This is the normal case of an independent architectural hypothesis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cryptovirology: Extortion-based security threats and countermeasures,
A. Young and M. Yung, “Cryptovirology: Extortion-based security threats and countermeasures,” inIEEE S&P, 1996, pp. 129–140
1996
-
[2]
Generating steganographic images via adver- sarial training,
J. Hayes and G. Danezis, “Generating steganographic images via adver- sarial training,” inNeurIPS, 2017
2017
-
[3]
Hiding images within images,
S. Baluja, “Hiding images within images,”TPAMI, 2020
2020
-
[4]
DeepMIH: Deep invertible network for multiple image hiding,
Z. Guan, J. Jing, X. Deng, M. Xu, L. Jiang, Z. Zhang, and Y . Li, “DeepMIH: Deep invertible network for multiple image hiding,”TPAMI, 2023
2023
-
[5]
HiNet: Deep image hiding by invertible network,
J. Jing, X. Deng, M. Xu, J. Wang, and Z. Guan, “HiNet: Deep image hiding by invertible network,” inICCV, 2021
2021
-
[6]
HiDDeN: Hiding data with deep networks,
J. Zhu, R. Kaplan, J. Johnson, and L. Fei-Fei, “HiDDeN: Hiding data with deep networks,” inECCV, 2018
2018
-
[7]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”TOG, vol. 42, 2023
2023
-
[8]
Neural point catacaustics for novel-view synthesis of reflections,
G. Kopanas, T. Leimk ¨uhler, G. Rainer, C. Jambon, and G. Drettakis, “Neural point catacaustics for novel-view synthesis of reflections,”TOG, vol. 41, no. 6, pp. 1–15, 2022
2022
-
[9]
GS-Hider: Hiding messages into 3D Gaussian splatting,
X. Zhang, J. Meng, R. Li, Z. Xu, Y . Zhang, and J. Zhang, “GS-Hider: Hiding messages into 3D Gaussian splatting,” inNeurIPS, 2024
2024
-
[10]
SecureGS: Boosting the security and fidelity of 3D Gaussian splatting steganography,
X. Zhang, J. Meng, Z. Xu, S. Yang, Y . Wu, R. Wang, and J. Zhang, “SecureGS: Boosting the security and fidelity of 3D Gaussian splatting steganography,” inICLR, 2025
2025
-
[11]
Neural 3d video synthesis from multi-view video,
T. Li, M. Slavcheva, M. Zollhoefer, S. Green, C. Lassner, C. Kim, T. Schmidt, S. Lovegrove, M. Goesele, R. Newcombe, and Z. Lv, “Neural 3d video synthesis from multi-view video,” inCVPR, 2022
2022
-
[12]
Efficient neural radiance fields for interactive free-viewpoint video,
H. Lin, S. Peng, Z. Xu, Y . Yan, Q. Shuai, H. Bao, and X. Zhou, “Efficient neural radiance fields for interactive free-viewpoint video,” inSIGGRAPH Asia Conference Proceedings, 2022
2022
-
[13]
Large scale multi-view stereopsis evaluation,
R. Jensen, A. Dahl, G. V ogiatzis, E. Tola, and H. Aanæs, “Large scale multi-view stereopsis evaluation,” inCVPR, 2014, pp. 406–413
2014
-
[14]
Gps-gaussian+: Generalizable pixel-wise 3d gaussian splatting for real-time human-scene rendering from sparse views,
B. Zhou, S. Zheng, H. Tu, R. Shao, B. Liu, S. Zhang, L. Nie, and Y . Liu, “Gps-gaussian+: Generalizable pixel-wise 3d gaussian splatting for real-time human-scene rendering from sparse views,”TPAMI, 2025
2025
-
[15]
arXiv preprint arXiv:2505.05474 (2025)
B. Wen, H. Xie, Z. Chen, F. Hong, and Z. Liu, “3d scene generation: A survey,”arXiv preprint arXiv:2505.05474, 2025
-
[16]
Gaussian-det: Learning closed-surface gaussians for 3d object detection,
H. Yan, Y . Zheng, and Y . Duan, “Gaussian-det: Learning closed-surface gaussians for 3d object detection,” inICLR, vol. 2025, 2025, pp. 53 598– 53 616
2025
-
[17]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” inECCV, 2020
2020
-
[18]
Shadownerf: Learning neural radiance field with sight degradation and recovery,
Y . Zheng, H. Yan, Y . Duan, and J. Lu, “Shadownerf: Learning neural radiance field with sight degradation and recovery,”TMM, 2026
2026
-
[19]
Oponerf: One-point-one nerf for robust few-shot rendering,
Y . Zheng, Y . Duan, K. Zheng, H. Yan, J. Lu, and J. Zhou, “Oponerf: One-point-one nerf for robust few-shot rendering,”IJCV, vol. 134, no. 1, p. 3, 2026
2026
-
[20]
Generative gaussian splatting for unbounded 3d city generation,
H. Xie, Z. Chen, F. Hong, and Z. Liu, “Generative gaussian splatting for unbounded 3d city generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6111–6120
2025
-
[21]
pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction,
D. Charatan, S. Li, A. Tagliasacchi, and V . Sitzmann, “pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction,” inCVPR, 2024
2024
-
[22]
MVSGaussian: Fast generalizable Gaussian splatting re- construction from multi-view stereo,
T. Liu, G. Wang, S. Hu, L. Shen, X. Ye, Y . Zang, Z. Cao, W. Li, and Z. Liu, “MVSGaussian: Fast generalizable Gaussian splatting re- construction from multi-view stereo,” inECCV, 2024
2024
-
[23]
Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real- time human novel view synthesis,
S. Zheng, B. Zhou, R. Shao, B. Liu, S. Zhang, L. Nie, and Y . Liu, “Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real- time human novel view synthesis,” inCVPR, 2024
2024
-
[24]
A watermark for digital images,
R. B. Wolfgang and E. J. Delp, “A watermark for digital images,” in ICIP, 1996
1996
-
[25]
A framework of enhanc- ing image steganography with picture quality optimization and anti- steganalysis based on simulated annealing algorithm,
G.-S. Lin, Y .-T. Chang, and W.-N. Lie, “A framework of enhanc- ing image steganography with picture quality optimization and anti- steganalysis based on simulated annealing algorithm,”TMM, 2010
2010
-
[26]
Hide and seek: An introduction to steganography,
N. Provos and P. Honeyman, “Hide and seek: An introduction to steganography,”IEEE S&P, vol. 1, no. 3, pp. 32–44, 2003
2003
-
[27]
An additive approach to transform-domain information hiding and optimum detection structure,
Q. Cheng and T. Huang, “An additive approach to transform-domain information hiding and optimum detection structure,”TMM, 2001
2001
-
[28]
Unsupervised steganalysis based on artificial training sets,
D. Lerch-Hostalot and D. Meg ´ıas, “Unsupervised steganalysis based on artificial training sets,”EAAI, vol. 50, pp. 45–59, 2016
2016
-
[29]
A novel convolutional neural network for image steganalysis with shared normalization,
S. Wu, S.-h. Zhong, and Y . Liu, “A novel convolutional neural network for image steganalysis with shared normalization,”TMM, 2020
2020
-
[30]
Provably secure robust image steganography,
Z. Yang, K. Chen, K. Zeng, W. Zhang, and N. Yu, “Provably secure robust image steganography,”TMM, 2024
2024
-
[31]
H. He, Y . Zheng, J. Zhou, and J. Lu, “Watervib: Learning minimal suffi- cient watermark representations via variational information bottleneck,” arXiv preprint arXiv:2602.21508, 2026
-
[32]
iscmis: Spatial-channel attention based deep invertible network for multi-image steganography,
F. Li, Y . Sheng, X. Zhang, and C. Qin, “iscmis: Spatial-channel attention based deep invertible network for multi-image steganography,”TMM, vol. 26, pp. 3137–3152, 2023
2023
-
[33]
Adaptive hevc video steganog- raphy with high performance based on attention-net and pu partition modes,
S. He, D. Xu, L. Yang, and W. Liang, “Adaptive hevc video steganog- raphy with high performance based on attention-net and pu partition modes,”TMM, vol. 26, pp. 687–700, 2023
2023
-
[34]
Multi-channel hevc steganography by minimizing ipm steganographic distortions,
Y . Dong, X. Jiang, Z. Li, T. Sun, and Z. Zhang, “Multi-channel hevc steganography by minimizing ipm steganographic distortions,”TMM, 2022
2022
-
[35]
Centralized error distribution-preserving adaptive steganography for hevc,
L. Yang, R. Wang, D. Xu, L. Dong, and S. He, “Centralized error distribution-preserving adaptive steganography for hevc,”TMM, 2024
2024
-
[36]
A robust coverless video steganography based on the similarity of inter-frames,
L. Meng, X. Jiang, T. Sun, Z. Zhao, and Q. Xu, “A robust coverless video steganography based on the similarity of inter-frames,”TMM, 2024
2024
-
[37]
StegaNeRF: Embedding invisible information within neural radiance fields,
C. Li, B. Y . Feng, Z. Fan, P. Pan, and Z. Wang, “StegaNeRF: Embedding invisible information within neural radiance fields,” inICCV, 2023
2023
-
[38]
CopyRNeRF: Protecting the copyright of neural radiance fields,
Z. Luo, Q. Guo, K. C. Cheung, S. See, and R. Wan, “CopyRNeRF: Protecting the copyright of neural radiance fields,” inICCV, 2023
2023
-
[39]
Protecting NeRFs’ copyright via plug-and-play watermarking base model,
Q. Song, Z. Luo, K. C. Cheung, S. See, and R. Wan, “Protecting NeRFs’ copyright via plug-and-play watermarking base model,”arXiv preprint arXiv:2407.07735, 2024
-
[40]
MantleMark: Migrating watermarks from multi-view images to radiance fields via frequency modulation,
Z. Luo, J. Liu, H. Li, A. Rocha, and R. Wan, “MantleMark: Migrating watermarks from multi-view images to radiance fields via frequency modulation,”IEEE Transactions on Information F orensics and Security, vol. 21, pp. 256–271, 2026. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. X, MONTH 202X 13
2026
-
[41]
The NeRF sig- nature: Codebook-aided watermarking for neural radiance fields,
Z. Luo, A. Rocha, B. Shi, Q. Guo, H. Li, and R. Wan, “The NeRF sig- nature: Codebook-aided watermarking for neural radiance fields,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 4652–4667, 2025
2025
-
[42]
3D-GSW: 3D Gaussian splatting for robust watermarking,
Y . Jang, H. Park, F. Yang, H. Ko, E. Choo, and S. Kim, “3D-GSW: 3D Gaussian splatting for robust watermarking,” inCVPR, 2025
2025
-
[43]
GuardSplat: Efficient and robust watermarking for 3D Gaussian splatting,
Z. Chen, G. Wang, J. Zhu, J. Lai, and X. Xie, “GuardSplat: Efficient and robust watermarking for 3D Gaussian splatting,” inCVPR, 2025
2025
-
[44]
MarkSplatter: Generalizable watermarking for 3D Gaussian splatting model via splatter image structure,
X. Huang, Z. Luo, Q. Song, R. Wang, and R. Wan, “MarkSplatter: Generalizable watermarking for 3D Gaussian splatting model via splatter image structure,” inACM MM, 2025
2025
-
[45]
All that glitters is not gold: Key- secured 3D secrets within 3D Gaussian splatting,
Y . Ren, S. Lu, and A. W.-K. Kong, “All that glitters is not gold: Key- secured 3D secrets within 3D Gaussian splatting,” inICLR, 2026
2026
-
[46]
InstantSplamp: Fast and generalizable stenography framework for generative Gaussian splatting,
C. Li, H. Liu, Z. Fan, W. Li, Y . Liu, P. Pan, and Y . Yuan, “InstantSplamp: Fast and generalizable stenography framework for generative Gaussian splatting,” inICLR, 2025
2025
-
[47]
U-Net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional net- works for biomedical image segmentation,” inMICCAI, 2015
2015
-
[48]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016
2016
-
[49]
Instance normalization: The missing ingredient for fast stylization,
D. Ulyanov, A. Vedaldi, and V . Lempitsky, “Instance normalization: The missing ingredient for fast stylization,” inCVPR, 2017
2017
-
[50]
High-capacity convolutional video steganography with temporal residual modeling,
X. Weng, Y . Li, L. Chi, and Y . Mu, “High-capacity convolutional video steganography with temporal residual modeling,” inICMR, 2019
2019
-
[51]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”TIP, 2004
2004
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018
2018
-
[53]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inICLR, 2015
2015
-
[54]
GaussianMarker: Uncertainty-aware copyright protection of 3D Gaus- sian splatting,
X. Huang, R. Li, Y .-m. Cheung, K. C. Cheung, S. See, and R. Wan, “GaussianMarker: Uncertainty-aware copyright protection of 3D Gaus- sian splatting,” inNeurIPS, 2024
2024
-
[55]
StegExpose - A Tool for Detecting LSB Steganography
B. Boehm, “Stegexpose-a tool for detecting lsb steganography,”arXiv preprint arXiv:1410.6656, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
Purified and unified steganographic network,
G. Li, S. Li, Z. Luo, Z. Qian, and X. Zhang, “Purified and unified steganographic network,” inCVPR, 2024, pp. 27 569–27 578
2024
-
[57]
Depth-wise separable convolutions and multi-level pooling for an efficient spatial cnn-based steganalysis,
R. Zhang, F. Zhu, J. Liu, and G. Liu, “Depth-wise separable convolutions and multi-level pooling for an efficient spatial cnn-based steganalysis,” TIFS, 2020. Fanye Kongis currently pursuing the B.S. degree from the Weiyang College, Tsinghua University, Beijing, China. He is a member of the Spark Pro- gram of Tsinghua University. His research interests in...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.