Intermediate Text Representation Guided Text-to-Image Generation for Enhancing One-and-Only Alignment
Pith reviewed 2026-06-30 06:02 UTC · model grok-4.3
The pith
Injecting intermediate hidden states from the text encoder into early denoising steps recovers suppressed concepts for one-and-only objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the final text embedding discards concept-level information present in the intermediate-layer text representations, and that injecting those intermediate hidden states into the conditioning signal during early denoising steps recovers the suppressed concepts for one-and-only objects without any additional training, optimization, or external models.
What carries the argument
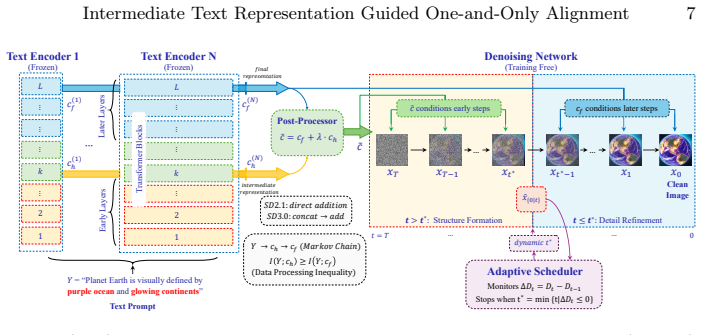
Intermediate Text Representation (IR)-guided diffusion, which injects intermediate hidden states of the text encoder into the conditioning signal during early denoising steps.
Load-bearing premise
The concept-level information present in intermediate-layer text representations but discarded by the final embedding can be recovered and effectively utilized simply by injecting those states during early denoising steps.
What would settle it
A controlled comparison on OAO-AttackBench showing that VQAScore does not increase when intermediate states are injected versus using only the final embedding.
Figures



read the original abstract
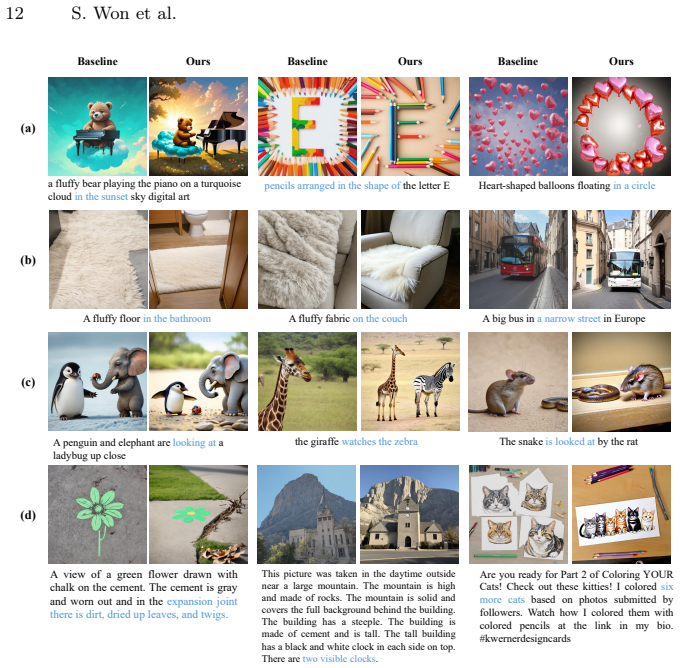
Text-to-image (T2I) diffusion models often fail to faithfully render explicit textual descriptions, instead defaulting to strongly learned visual priors due to a phenomenon referred to as concept association bias. We show that such bias is particularly strong for one-and-only (OAO) objects, entities that exist in a single canonical form, such as celestial bodies, landmarks, and artworks. The deeply ingrained visual identity for these concepts often resists modification through prompting alone. Addressing this challenge, we first identify through an information-theoretic analysis that the final text embedding discards concept-level information present in the intermediate-layer text representations, reducing the mutual information available to the subsequent denoising process. We then propose Intermediate Text Representation (IR)-guided diffusion, which injects intermediate hidden states of the text encoder into the conditioning signal during early denoising steps, recovering suppressed concepts without any additional training, optimization, or external models. To systematically evaluate the challenging task of aligning generative outputs with unusual prompts for OAO objects, we introduce OAO-AttackBench, a benchmark comprising counterfactual prompts that directly conflict with the core visual identity of OAO objects. Experiments on four benchmarks, including OAO-AttackBench, show that our method achieves up to a 19.1 percentage-point improvement in VQAScore while preserving generation fidelity and human preference. Project page: https://soyoun-won.github.io/one-and-only-ir-guidance/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that text-to-image diffusion models exhibit strong concept association bias for one-and-only (OAO) objects, which resists modification via prompting. An information-theoretic analysis is used to show that the final text embedding discards concept-level information present in intermediate layers of the text encoder. The proposed IR-guided diffusion method injects these intermediate hidden states into the conditioning signal during early denoising steps, recovering the suppressed concepts in a training-free manner. A new benchmark OAO-AttackBench is introduced with counterfactual prompts, and experiments on four benchmarks report gains of up to 19.1 percentage points in VQAScore while preserving fidelity and human preference.
Significance. If the empirical results hold under rigorous controls, the work is significant for offering a lightweight, parameter-free intervention that leverages internal text-encoder states to improve prompt alignment in existing T2I models without retraining or external components. The training-free aspect and the new OAO-AttackBench benchmark are practical strengths that could aid evaluation of alignment failures on canonical visual concepts.
major comments (2)
- [information-theoretic analysis] Information-theoretic analysis (abstract and motivating section): The claim that the final embedding reduces mutual information is central to motivating the injection method, yet no details are provided on the computation (e.g., estimator used, number of samples, specific layers compared, or how concept-level information is quantified). This leaves the analysis as an unsupported assertion rather than a verifiable foundation.
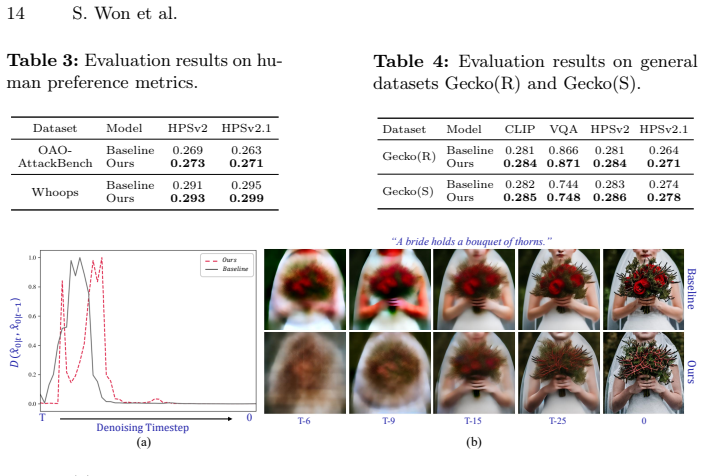
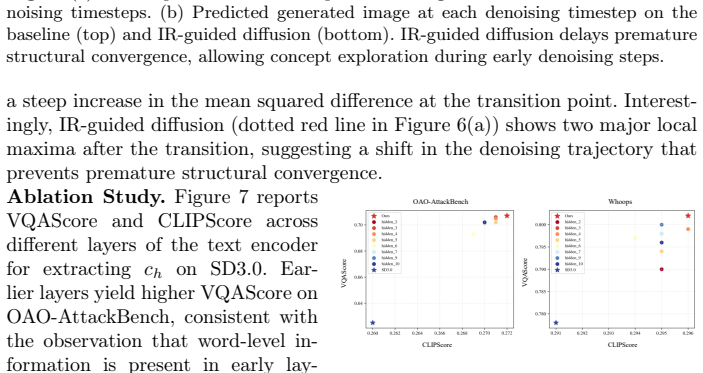
- [experiments and OAO-AttackBench] Experimental evaluation (results section): The reported 19.1 pp VQAScore improvement and claims of preserved fidelity lack error bars, statistical significance tests, ablation studies on injection timing/layers, or explicit controls for prompt difficulty. Without these, it is difficult to determine whether the gains are robust or attributable to the proposed mechanism versus other factors.
minor comments (1)
- [method] The abstract and method description would benefit from a concise statement of the exact layers selected for injection and the precise early-denoising timestep range, to allow immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [information-theoretic analysis] Information-theoretic analysis (abstract and motivating section): The claim that the final embedding reduces mutual information is central to motivating the injection method, yet no details are provided on the computation (e.g., estimator used, number of samples, specific layers compared, or how concept-level information is quantified). This leaves the analysis as an unsupported assertion rather than a verifiable foundation.
Authors: We agree that the information-theoretic analysis requires additional implementation details to be fully verifiable. In the revised manuscript we will expand the motivating section to specify the mutual information estimator, the number of samples drawn, the precise text-encoder layers compared, and the procedure used to quantify concept-level information. These additions will substantiate the claim that the final embedding discards intermediate-layer information. revision: yes
-
Referee: [experiments and OAO-AttackBench] Experimental evaluation (results section): The reported 19.1 pp VQAScore improvement and claims of preserved fidelity lack error bars, statistical significance tests, ablation studies on injection timing/layers, or explicit controls for prompt difficulty. Without these, it is difficult to determine whether the gains are robust or attributable to the proposed mechanism versus other factors.
Authors: We concur that the experimental section would benefit from greater statistical rigor and ablations. We will add error bars (standard deviation over multiple seeds), statistical significance tests, systematic ablations on injection timing and layer selection, and explicit controls for prompt difficulty. These revisions will clarify that the reported gains are robust and tied to the IR-guided mechanism rather than extraneous factors. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical intervention
full rationale
The paper performs an information-theoretic analysis showing mutual information loss between intermediate and final text embeddings, then directly implements a parameter-free injection of those states into early denoising steps. Neither step reduces to a fitted parameter, self-citation chain, or definitional equivalence; the analysis is presented as original computation, the injection is an explicit architectural modification, and success is measured on external benchmarks (including a new OAO-AttackBench) rather than internal consistency. No equations or claims equate the output to the input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The final text embedding discards concept-level information present in the intermediate-layer text representations
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Azam, B., Akhtar, N.: Plug-and-play interpretable responsible text-to-image gen- eration via dual-space multi-facet concept control. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2976–2985 (2025)
2025
-
[2]
In: International Conference on Learning Representations (2018)
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying MMD GANs. In: International Conference on Learning Representations (2018)
2018
-
[3]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Bitton-Guetta, N., Bitton, Y., Hessel, J., Schmidt, L., Elovici, Y., Stanovsky, G., Schwartz, R.: Breaking common sense: Whoops! a vision-and-language benchmark of synthetic and compositional images. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 2616–2627 (2023)
2023
-
[4]
In: 32nd USENIX security symposium (USENIX Security 23)
Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Sehwag, V., Tramer, F., Balle, B., Ippolito, D., Wallace, E.: Extracting training data from diffusion models. In: 32nd USENIX security symposium (USENIX Security 23). pp. 5253–5270 (2023)
2023
-
[5]
ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
2023
-
[6]
In: International conference on learning representations
Cho, J., Hu, Y., Baldridge, J., Garg, R., Anderson, P., Krishna, R., Bansal, M., Pont-Tuset, J., Wang, S.: Davidsonian scene graph: Improving reliability in fine- grained evaluation for text-to-image generation. In: International conference on learning representations. vol. 2024, pp. 15625–15645 (2024)
2024
-
[7]
arXiv preprint arXiv:2302.00070 (2023)
Chuang, C.Y., Jampani, V., Li, Y., Torralba, A., Jegelka, S.: Debiasing vision- language models via biased prompts. arXiv preprint arXiv:2302.00070 (2023)
-
[8]
Wiley-Interscience, 2 edn
Cover, T.M., Thomas, J.A.: Elements of Information Theory. Wiley-Interscience, 2 edn. (2006)
2006
-
[9]
IEEE transactions on pattern anal- ysis and machine intelligence (2024)
Delmas, G., Weinzaepfel, P., Lucas, T., Moreno-Noguer, F., Rogez, G.: Posescript: Linking 3d human poses and natural language. IEEE transactions on pattern anal- ysis and machine intelligence (2024)
2024
-
[10]
Journal of the American Statistical Association106(496), 1602–1614 (2011)
Efron, B.: Tweedie’s formula and selection bias. Journal of the American Statistical Association106(496), 1602–1614 (2011)
2011
-
[11]
In: Forty-first international conference on machine learning (2024) 16 S
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 16 S. Won et al
2024
-
[12]
arXiv preprint arXiv:2302.10893 (2023)
Friedrich, F., Brack, M., Struppek, L., Hintersdorf, D., Schramowski, P., Luccioni, S., Kersting, K.: Fair diffusion: Instructing text-to-image generation models on fairness. arXiv preprint arXiv:2302.10893 (2023)
- [13]
-
[14]
arXiv preprint arXiv:2412.03400 (2024)
He, F., Zhang, C., Zhao, Z.: Implicit priors editing in stable diffusion via targeted token adjustment. arXiv preprint arXiv:2412.03400 (2024)
-
[15]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[17]
Advances in Neural Information Processing Systems37, 137646–137672 (2024)
Hu, T., Li, L., Van de Weijer, J., Gao, H., Shahbaz Khan, F., Yang, J., Cheng, M.M., Wang, K., Wang, Y.: Token merging for training-free semantic binding in text-to-image synthesis. Advances in Neural Information Processing Systems37, 137646–137672 (2024)
2024
-
[18]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question an- swering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20406–20417 (2023)
2023
-
[20]
In: Advances in Neural Information Processing Systems
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. In: Advances in Neural Information Processing Systems. vol. 36 (2023)
2023
-
[21]
arXiv preprint arXiv:2506.01929 (2025)
Huberman, S., Patashnik, O., Dahary, O., Mokady, R., Cohen-Or, D.: Image gen- eration from contextually-contradictory prompts. arXiv preprint arXiv:2506.01929 (2025)
-
[22]
arXiv preprint arXiv:2503.10687 (2025)
Islam, K., Akhtar, N.: Context-guided responsible data augmentation with diffu- sion models. arXiv preprint arXiv:2503.10687 (2025)
-
[23]
Expert Systems with Applications p
Islam, K., Zaheer, M.Z., Mahmood, A., Nandakumar, K., Akhtar, N.: Genmix: effective data augmentation with generative diffusion model image editing. Expert Systems with Applications p. 132273 (2026)
2026
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kim, E., Kim, S., Park, M., Entezari, R., Yoon, S.: Rethinking training for de- biasing text-to-image generation: Unlocking the potential of stable diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13361–13370 (2025)
2025
-
[25]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Kim, J., Esmaeili, E., Qiu, Q.: Text embedding is not all you need: Attention con- trol for text-to-image semantic alignment with text self-attention maps. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 8031– 8040 (2025)
2025
-
[26]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Krause, J., Johnson, J., Krishna, R., Fei-Fei, L.: A hierarchical approach for gen- erating descriptive image paragraphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 317–325 (2017)
2017
- [27]
- [28]
-
[29]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[30]
In: European Conference on Computer Vision
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. In: European Conference on Computer Vision. pp. 366–384. Springer (2024)
2024
-
[31]
In: Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers)
Liu, R., Garrette, D., Saharia, C., Chan, W., Roberts, A., Narang, S., Blok, I., Mical, R., Norouzi, M., Constant, N.: Character-aware models improve visual text rendering. In: Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers). pp. 16270–16297 (2023)
2023
-
[32]
Lu, C., Krishna, R., Bernstein, M., Fei-Fei, L.: Visual relationship detection with languagepriors.In:Europeanconferenceoncomputervision.pp.852–869.Springer (2016)
2016
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Orgad, H., Kawar, B., Belinkov, Y.: Editing implicit assumptions in text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7030–7038 (2023)
2023
-
[34]
In: Proceedings of the IEEE/CVF international conference on computer vision
Paiss, R., Ephrat, A., Tov, O., Zada, S., Mosseri, I., Irani, M., Dekel, T.: Teaching clip to count to ten. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3170–3180 (2023)
2023
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Parast, A.Y., Azam, B., Akhtar, N.: Ddb: Diffusion driven balancing to address spurious correlations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17526–17535 (2025)
2025
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Phung, Q., Ge, S., Huang, J.B.: Grounded text-to-image synthesis with attention refocusing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7932–7942 (2024)
2024
-
[37]
Pont-Tuset, J., Uijlings, J., Changpinyo, S., Soricut, R., Ferrari, V.: Connecting visionandlanguagewithlocalizednarratives.In:Europeanconferenceoncomputer vision. pp. 647–664. Springer (2020)
2020
-
[38]
Advances in Neural Information Processing Systems36 (2024)
Rassin, R., Hirsch, E., Glickman, D., Ravfogel, S., Goldberg, Y., Chechik, G.: Lin- guistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment. Advances in Neural Information Processing Systems36 (2024)
2024
-
[39]
In: Breakthroughs in Statistics: Foundations and basic theory, pp
Robbins, H.E.: An empirical bayes approach to statistics. In: Breakthroughs in Statistics: Foundations and basic theory, pp. 388–394. Springer (1992)
1992
-
[40]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045 (2018)
2018
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[42]
In: Proceedings of the Winter Confer- ence on Applications of Computer Vision
Sajnani, R., Vanbaar, J., Min, J., Katyal, K.D., Sridhar, S.: Geodiffuser: Geometry- based image editing with diffusion models. In: Proceedings of the Winter Confer- ence on Applications of Computer Vision. pp. 472–482 (2025)
2025
-
[43]
arXiv preprint arXiv:2503.23011 (2025)
Seo, H., Bang, J., Lee, H., Lee, J., Lee, B.H., Chun, S.Y.: Geometrical properties of text token embeddings for strong semantic binding in text-to-image generation. arXiv preprint arXiv:2503.23011 (2025)
-
[44]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Seshadri, P., Singh, S., Elazar, Y.: The bias amplification paradox in text-to-image generation. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6367–6384 (2024) 18 S. Won et al
2024
-
[45]
arXiv preprint arXiv:2311.07604 (2023)
Shen, X., Du, C., Pang, T., Lin, M., Wong, Y., Kankanhalli, M.: Finetuning text- to-image diffusion models for fairness. arXiv preprint arXiv:2311.07604 (2023)
-
[46]
Sun, J., Fu, D., Hu, Y., Wang, S., Rassin, R., Juan, D.C., Alon, D., Herrmann, C., Van Steenkiste, S., Krishna, R., et al.: Dreamsync: Aligning text-to-image gener- ation with image understanding feedback. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Techno...
2025
-
[47]
In: Proceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing
Tang, Y., Yamada, Y., Zhang, Y., Yildirim, I.: When are lemons purple? the con- cept association bias of vision-language models. In: Proceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing. pp. 14333–14348 (2023)
2023
-
[48]
Toker, M., Orgad, H., Ventura, M., Arad, D., Belinkov, Y.: Diffusion lens: Inter- preting text encoders in text-to-image pipelines. arXiv preprint arXiv:2403.05846 (2024)
-
[49]
arXiv preprint arXiv:2404.13766 (2024)
Trusca, M.M., Nuyts, W., Thomm, J., Honig, R., Hofmann, T., Tuytelaars, T., Moens, M.F.: Object-attribute binding in text-to-image generation: Evaluation and control. arXiv preprint arXiv:2404.13766 (2024)
-
[50]
Turc, I., Nemade, G.: Midjourney user prompts & generated images (250k) (2023)
2023
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Um, S., Ye, J.C.: Minority-focused text-to-image generation via prompt optimiza- tion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20926–20936 (2025)
2025
-
[52]
Artificial Intelligence Review59(2), 57 (2026)
Vice, J., Akhtar, N., Sigal, L., Hartley, R., Mian, A.: On the fairness, diversity and reliability of text-to-image generative models. Artificial Intelligence Review59(2), 57 (2026)
2026
-
[53]
arXiv preprint arXiv:2303.02490 (2023)
Wang, B., Vastola, J.J.: Diffusion models generate images like painters: an analyt- ical theory of outline first, details later. arXiv preprint arXiv:2303.02490 (2023)
-
[54]
In: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers)
Wang, Z.J., Montoya, E., Munechika, D., Yang, H., Hoover, B., Chau, D.H.: Diffu- siondb: A large-scale prompt gallery dataset for text-to-image generative models. In: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers). pp. 893–911 (2023)
2023
-
[55]
arXiv preprint arXiv:2404.16820 (2024)
Wiles, O., Zhang, C., Albuquerque, I., Kajić, I., Wang, S., Bugliarello, E., Onoe, Y., Papalampidi, P., Ktena, I., Knutsen, C., et al.: Revisiting text-to-image eval- uation with gecko: On metrics, prompts, and human ratings. arXiv preprint arXiv:2404.16820 (2024)
-
[56]
arXiv preprint arXiv:2508.06044 (2025)
Wu, H., Ma, X., Zhao, H., Zhao, Y., Li, Q.: Nep: Autoregressive image editing via next editing token prediction. arXiv preprint arXiv:2508.06044 (2025)
-
[57]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
arXiv preprint arXiv:2403.02118 (2024)
Yang, Y., Lin, Y., Liu, H., Shao, W., Chen, R., Shang, H., Wang, Y., Qiao, Y., Zhang, K., Luo, P.: Position: towards implicit prompt for text-to-image models. arXiv preprint arXiv:2403.02118 (2024)
-
[59]
Planet Earth is visually defined by purple ocean and glowing continents
Zhang, H., Guo, Y., Kankanhalli, M.: Joint vision-language social bias removal for clip. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4246–4255 (2025) Intermediate Text Representation Guided Text-to-Image Generation for Enhancing One-and-Only Alignment (Supplementary Material) Soyoun Won1 , Aryan Yazdan Parast1 , Basim Az...
2025
-
[60]
Identify two global characteristics in the following subcategory: shape and material
-
[61]
Planet Earth is visually defined by purple ocean and glowing continents
Replace each attribute with a visually or functionally unrelated attribute that contradicts or violates the core identity. Output format: [subcategory], [replaced attribute] The replaced attribute must be applicable to the global characteristics of the given category of objects. Category: Celestial objects (e.g., The Sun, The Earth, Mercury, ...) D Implem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.